Learning GraphQL By Doing
By Shahidh K Muhammed, Hasura
- Published:
- 13 min read
In this tutorial, we’ll cover the basic concepts required for app developers to understand GraphQL, with the intention of learning what a GraphQL API looks like—and how it compares to REST-API equivalents—by actually trying it out.
This article is broken into three parts:
- What is GraphQL and how it works from the client
- Setting up a GraphQL endpoint on Postgres with Hasura and DigitalOcean
- Exploring GraphQL queries (reads), mutations (writes), and subscriptions (real-time)
What is GraphQL?
GraphQL is a query language and a runtime for executing the queries. Born at Facebook in 2012 and open sourced in 2015, GraphQL represents data not in terms of resource URLs, secondary keys, or join tables; but in terms of a graph of objects and the models that are ultimately used in apps, like NSObjects or JSON. GraphQL is not bound to any data exchange or transport specifications. Typically in an HTTP context, the GraphQL “query string” is POST-ed to the server and the server responds with JSON data.
There are three key benefits that GraphQL users observe over REST-ful APIs:
- The speed of building and iterating on the frontend app dramatically increases
- The amount of data sent from the server to client apps reduces, making apps faster and more responsive
- The communication between frontend and backend teams gets streamlined
Here’s a GIF showing how a GraphQL client can make precise queries to a GraphQL API server to fetch exactly the data it needs and in the “shape” that it wants.
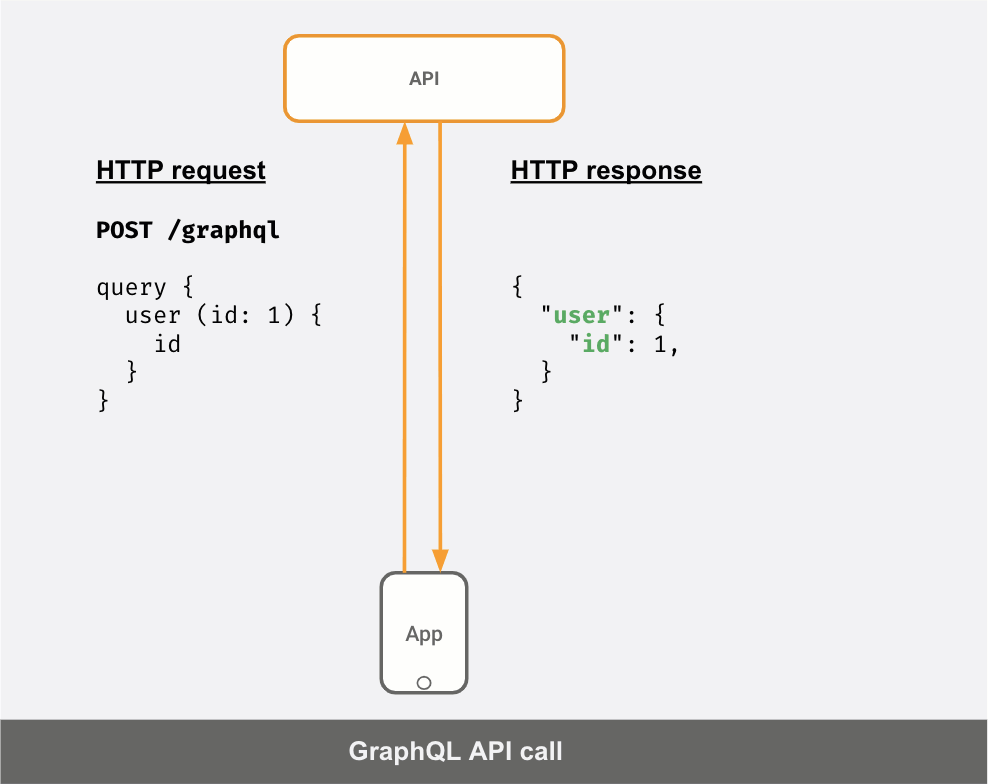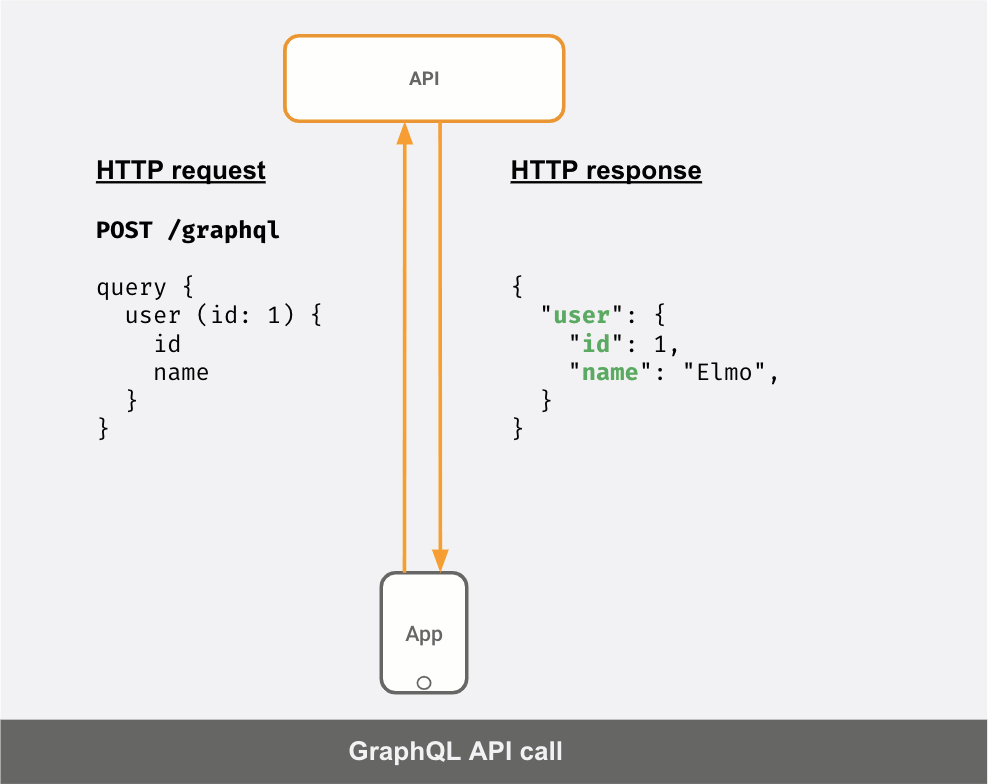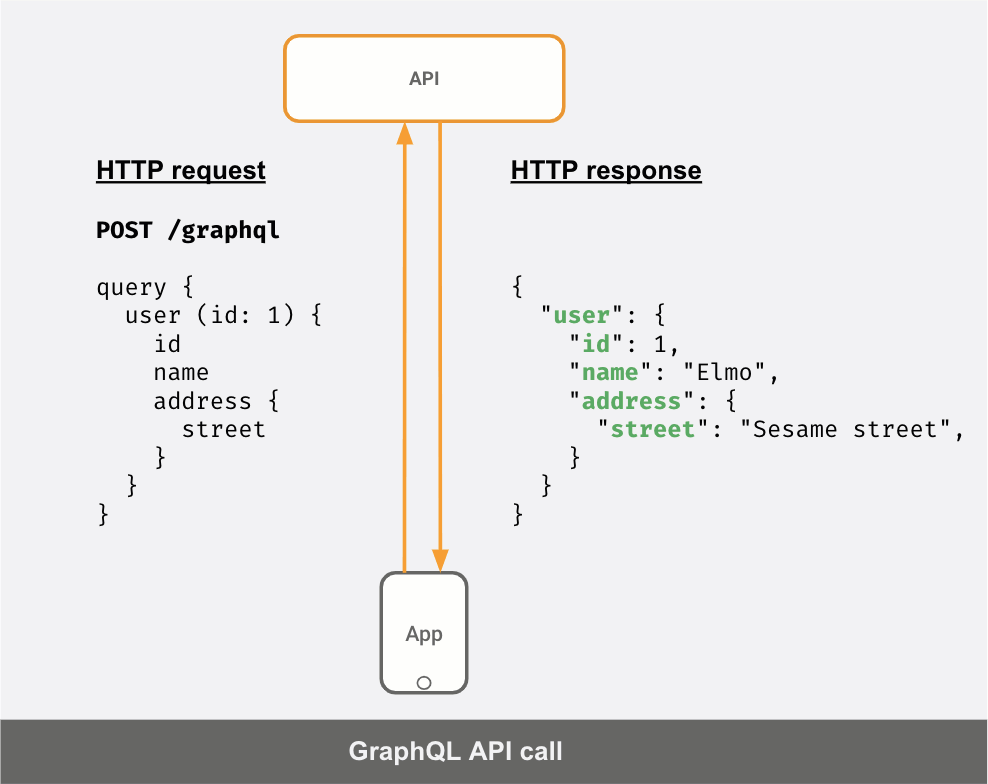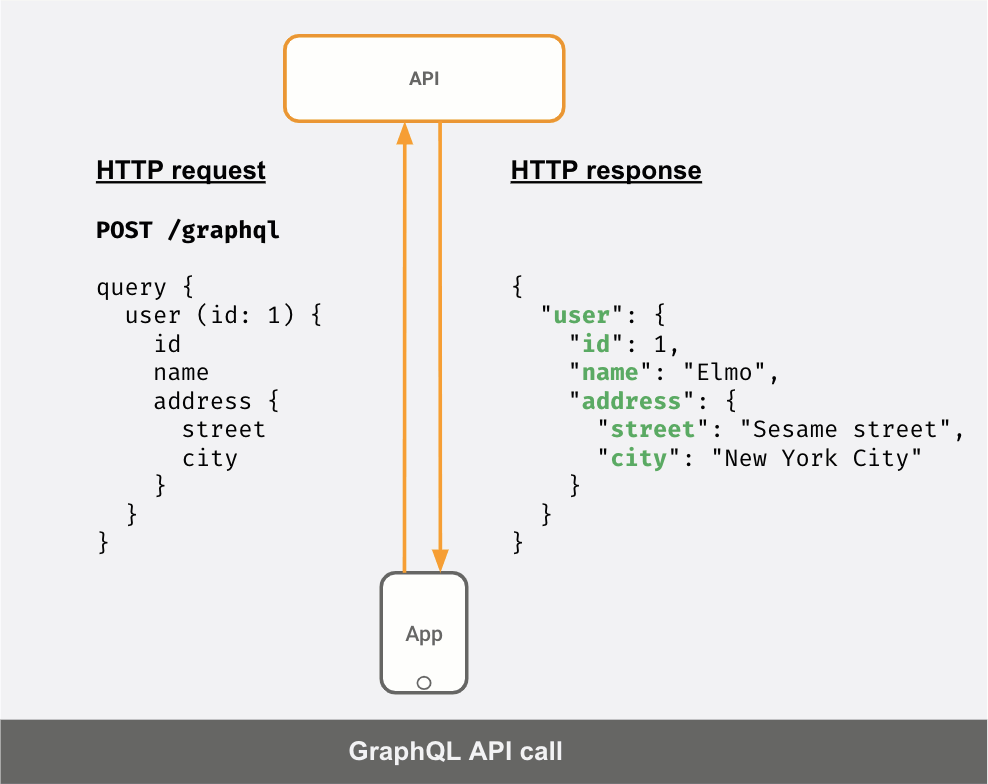
GraphQL adopters see these benefits because:
- A GraphQL API allows the frontend developer to easily fetch required data across multiple resources in just a single API call instead of making multiple REST API calls.
- A GraphQL API supports subscriptions as a standard part of the spec that makes it easy to consume real-time information on the frontend, without having to bother with setting up complex networking clients manually.
- A GraphQL server supports introspection and has a type system that makes it possible to have great tooling for API consumers. Community tools use these introspection APIs to give you everything from auto-complete to API exploration to codegen so that you don’t have to create request/response classes for your APIs!
The best way of understanding new technology like GraphQL is by trying it out. In this tutorial, we’re going to use Hasura on DigitalOcean to explore GraphQL.
Set up a GraphQL Server
Let’s first set up a GraphQL server and get a hang of it before we deep dive into more GraphQL. We’re going to use the Hasura GraphQL Engine, which is available as a 1-Click application. It is packed with a Postgres database and Caddy web server for easy and automatic HTTPS using Let’s Encrypt.
[Related: Want more Caddy? Check out the tutorial “Deploying a Fully-automated Git-based Static Website in Under 5 Minutes”]
Create your Hasura GraphQL Droplet, which installs all the required software and packages itself using Docker. Once the Droplet is ready, head to the Droplet IP on a browser. The Hasura console will open up, and this is where we will interact with the Hasura GraphQL Server to create the schema, test out APIs, manage data etc.
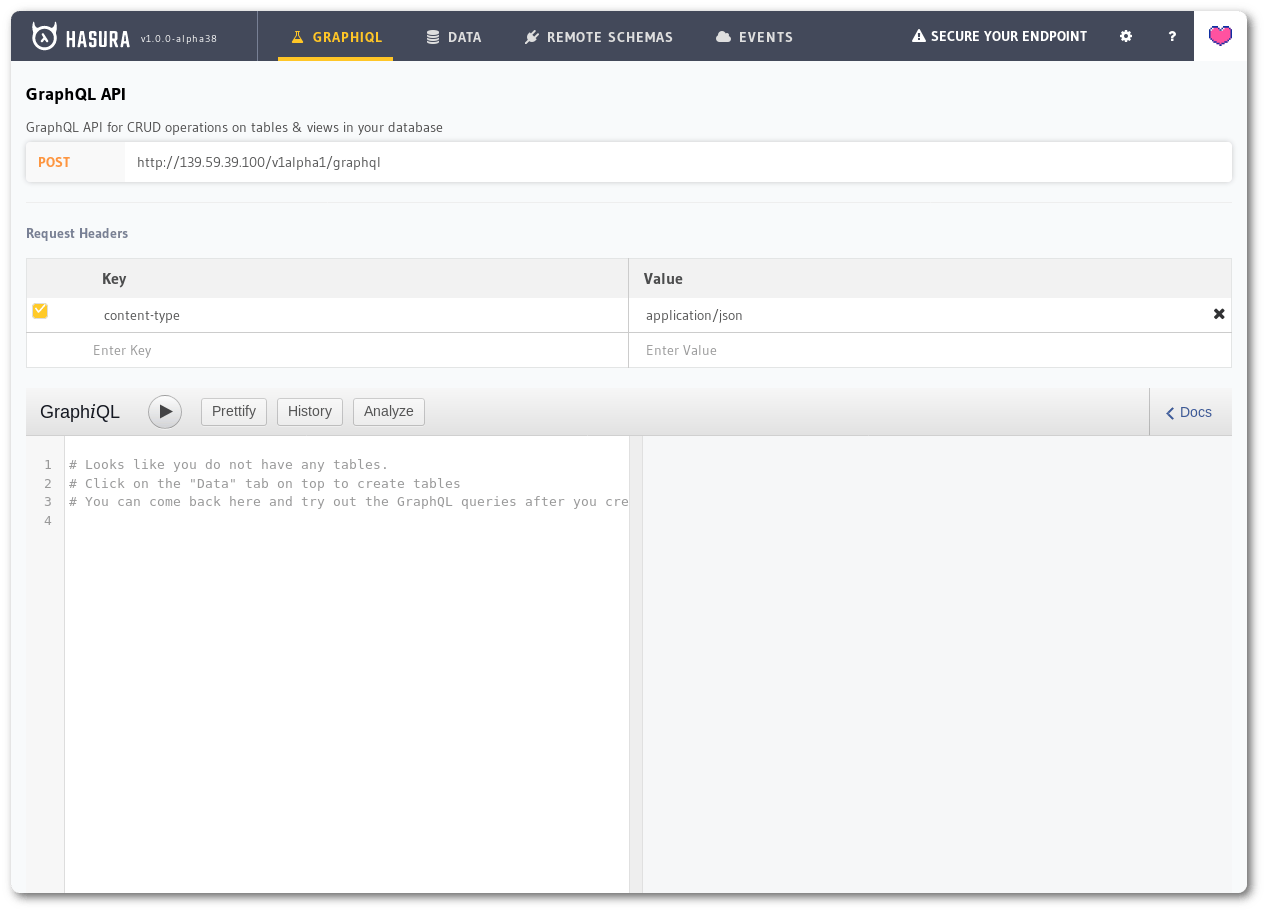
A screenshot of the Hasura console showing the default GraphiQL tab where users can try out GraphQL queries.
This tab where we try out the GraphQL queries is called GraphiQL. It serves as a playground/documentation for the GraphQL server with features like validation, autocomplete, etc… Throughout this guide, we’ll use GraphiQL to try and test out our queries.
There is a public endpoint setup at https://learn-graphql.demo.hasura.app so that users can try out the steps in this tutorial without actually creating a Droplet.
Create a table
Hasura creates the GraphQL schema by looking at Postgres schema. If there is a table called product, there will be a GraphQL type called product. We’ll come back to this again after we’ve made our first GraphQL query.
Let’s create a table in Postgres and get GraphQL on that, all through the Hasura console.
Navigate to *Data -> Create* table on the console and create a table called `team` with the following columns:
Column Name Type
id Integer
(auto-increment) nameText
Other inputs and checkboxes like default value, nullable and, unique can be ignored. Choose `id` as the Primary Key and click the *Create* button.
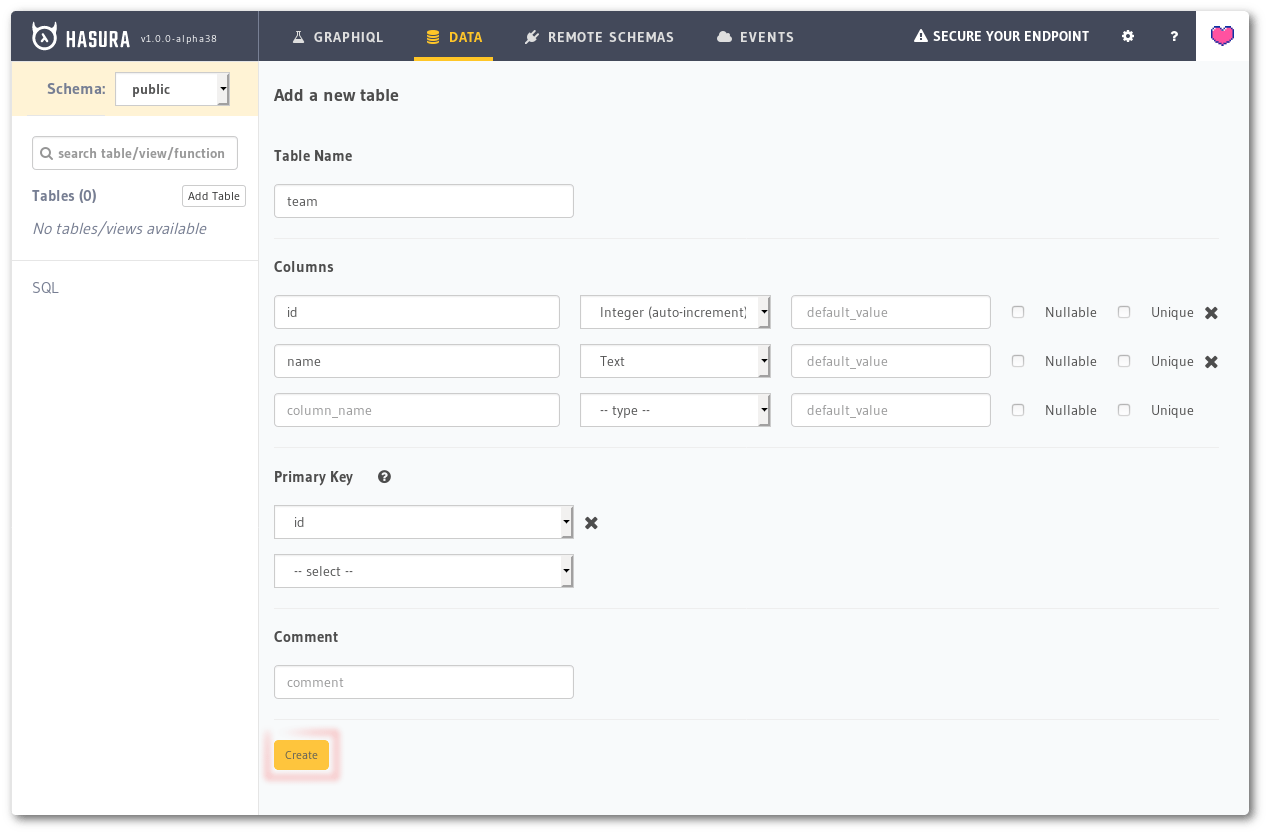
Screenshot of console showing the create table screen with details filled in.
Insert sample data
Once the table is created, you will be taken to the table’s dashboard. Let’s go to the *Insert Row* tab and add some rows. The id column will be disabled as it is going to be auto-generated. You will only be able to enter the name. Once you enter one name, say Avengers, click the Save button. You will see a notification on the top right corner saying that the row has been inserted!
The text will remain in the name input box and the button will change to Insert Again from Save. Edit the name input box to add the next team, Justice League, and click the Insert Again button.
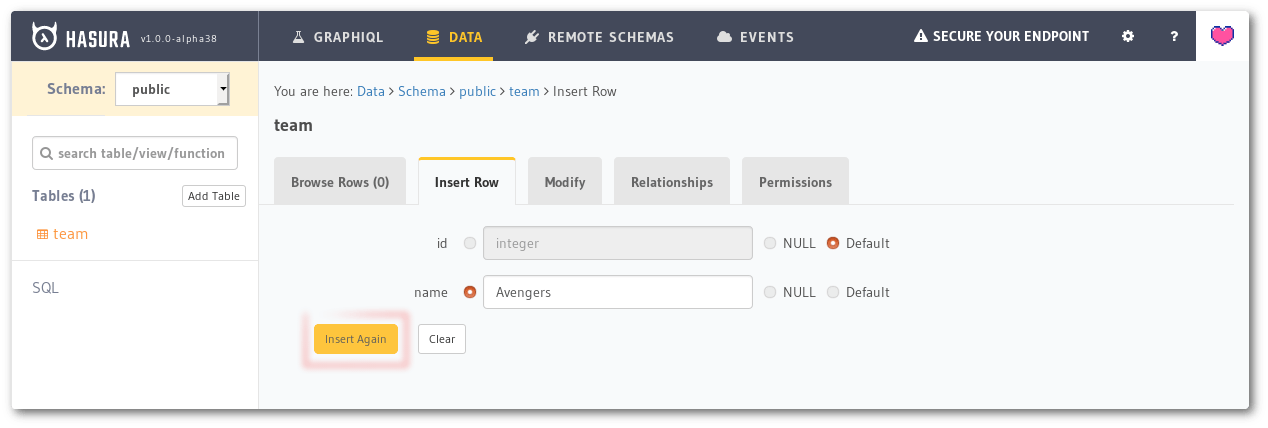
Inserting rows into the table.
Now if we go to Browse Rows tab, we can see that we have inserted two teams with name Avengers and Justice League, for which the id has been auto-generated. Avengers got id 1 and Justice League got id 2.
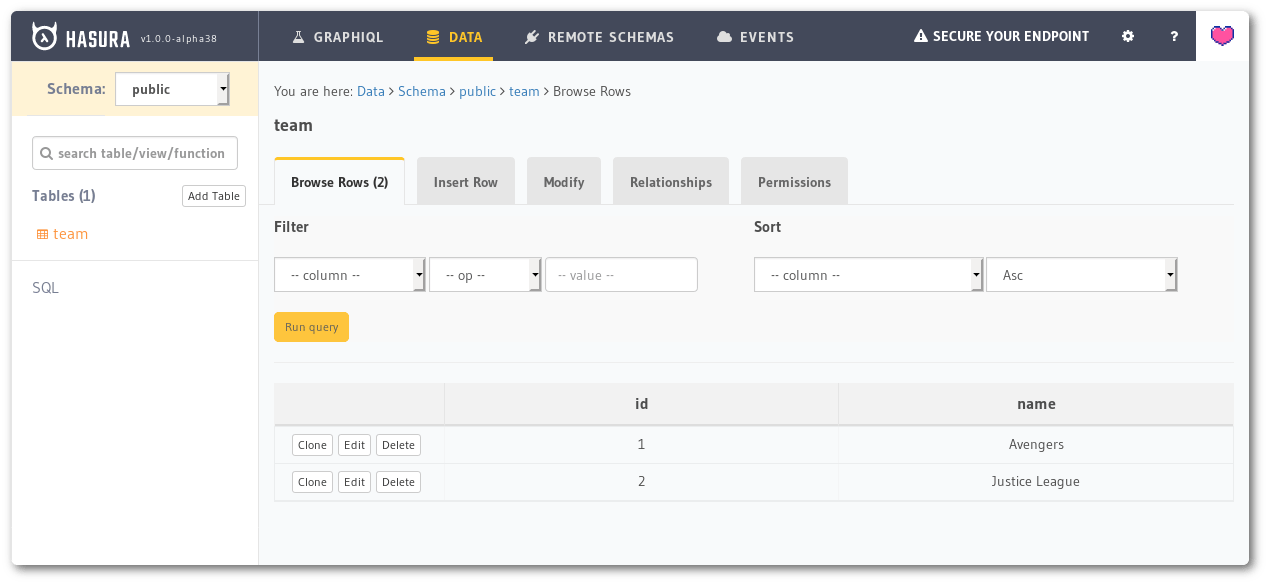
Team table showing two rows.
This is standard Postgres stuff. Let’s jump into GraphQL now.
Try out GraphQL
Switch to the GraphiQL tab by clicking the link on the top of the console. You will see a URL on top, which is the GraphQL API endpoint; a section to add HTTP headers; and, then the GraphiQL screen split into left and right sides. We enter the GraphQL query on the left side editor and then click the *Play* button on top and the API response appears on the right side.
Copy the following GraphQL query and paste into the left side of GraphiQL. Now, click on the button with *Play* icon on it. This will send the query to the server and show the response on the right side.
query { team { id name } }
The response will appear on the right.
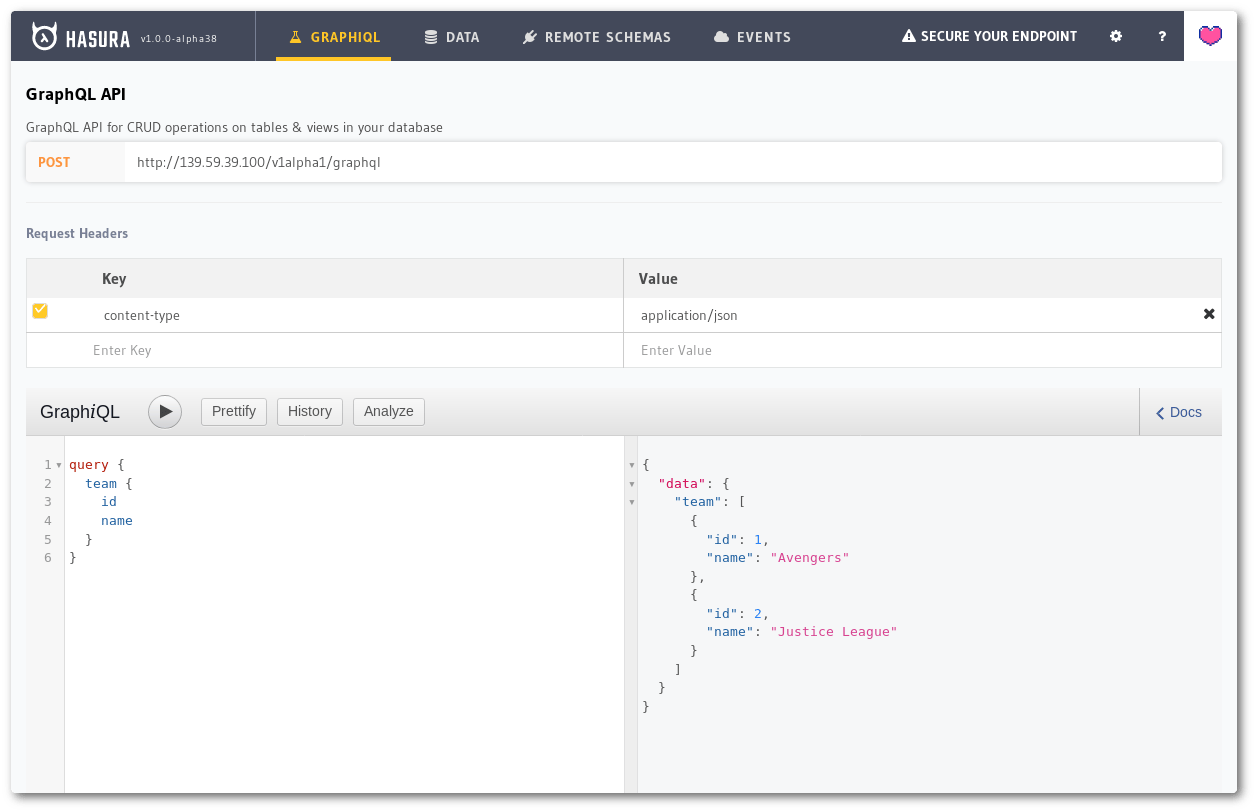
Executing the query to get all teams.
Woohoo! You have made your first GraphQL query on Hasura. The query above is asking the server to give information on all team objects along with the id and name columns.
GraphQL Query
A GraphQL query is a string that is sent to a server to be interpreted and fulfilled, which then returns JSON back to the client. It is designed for developers of web/mobile apps (HTTP clients) to be able to make API calls to fetch the data they need from their backend APIs in a more convenient way.
Let’s take a closer look at what that means. Let’s say you have an API to fetch all teams. This is a typical way to do it with REST: (Request is shown on the left and response on the right).
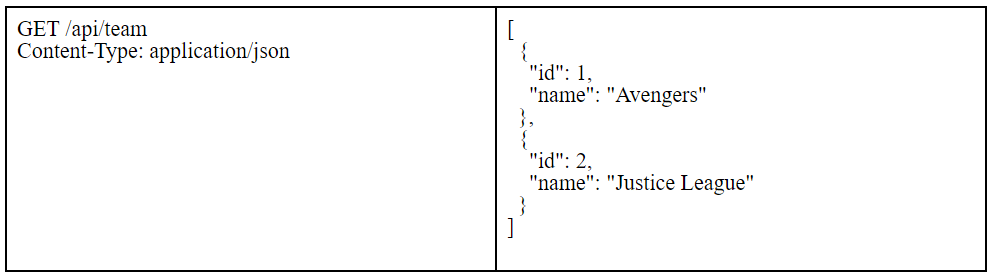
But, with a GraphQL API, the request would look like this:
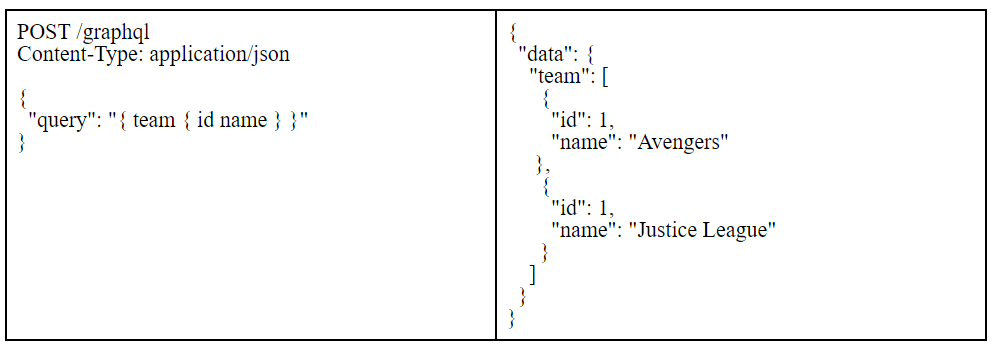
This is what GraphiQL is doing under the hood. It is taking the query string; wrapping it in a JSON object, with a top-level query key; and, POST-ing it to the server. All GraphQL client libraries takes care of this and, as a user, we will only have to deal with the query string.
Instead of GET-ing a resource at a URL qualified by the resource, we POST a GraphQL query to a single endpoint. The query defines the resource we want with any parameter of subresources. It is not JSON, but a string representation of the data we need, wrapped in a JSON body. The server responds with a JSON in the same shape of the data we requested: there is team key at top level, then id and name nested inside.
Types of queries
There are three different types of GraphQL queries.
- Query
- Mutation
- Subscription
Queries are typically used to fetch data, mutations for writing data and subscriptions for fetching real-time data. All three of them are collectively called “queries” again.
Parts of a query
Each GraphQL query, whether it is a query, mutation, or subscription, fundamentally contains fields and arguments.
Fields
A field simply indicate that we are asking the server for that particular info. For example, in the following query that we ran earlier:
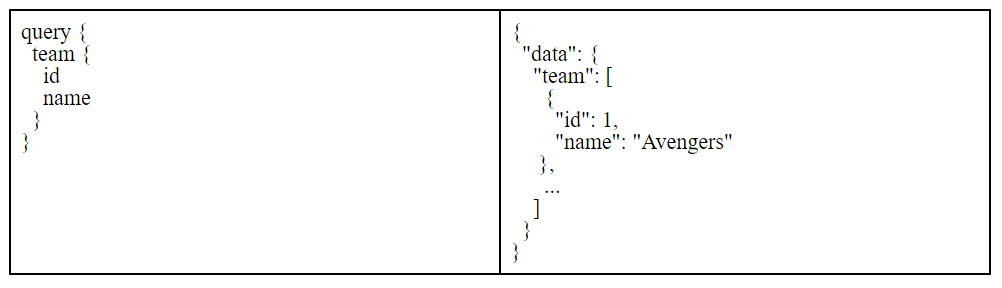
We ask the server for the field team and its subfields id and name, and the server returns data in the same shape as we asked for.
Arguments
In something like REST, we could only pass a single set of argument - as query parameters and URL segments. For example, to get a particular profile, a typical REST call would look like the following:

Or like this:

With GraphQL, every field can take any arbitrary number of arguments as defined by the schema. The REST API above would look like this with GraphQL:
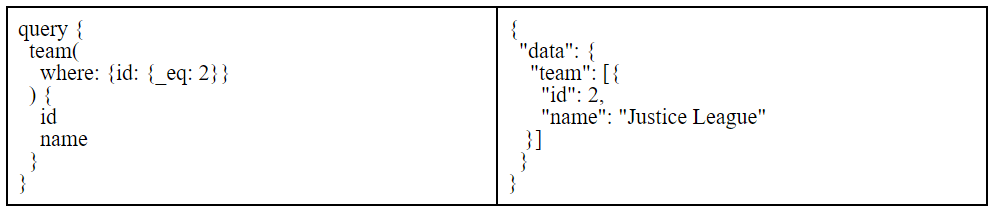
Try this out in GraphiQL.
A query using the where argument.
Similarly, there are many other arguments available for queries, like order_by, limit, offset etc. You can try them out in GraphiQL: use Ctrl/Cmd+Space to open up the auto-complete suggestions.
Query variables
But how do we parametrize this? Since the query is a string, a naive way would be to implement string interpolation. But this can introduce bugs and is not efficient.
Any GraphQL query can be parametrized by defining variables. Variables can be used in the query string and the values of those variables can be sent in a separate object. This makes it easy to re-use queries by using different set of variables instead of something like string interpolation. Variables need to be defined before they can be used and while defining the type also need to be provided.
Here is an example:
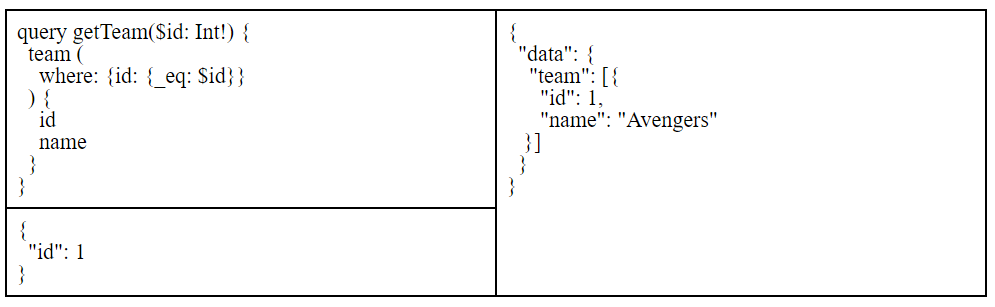
The first column contains the query, the column below that contains the variables object, and the right column contains the response, as represented in GraphiQL. Try this query out and see the response:
A query along with variables.
Here we are defining a variable called id, as denoted by the prefix $ and it is of type Int. The ! indicates that this variable is mandatory for this query to be executed. The client typically send the variables in a JSON object with key variables in the JSON POST body along with the query string.
The POST body would look something like this:
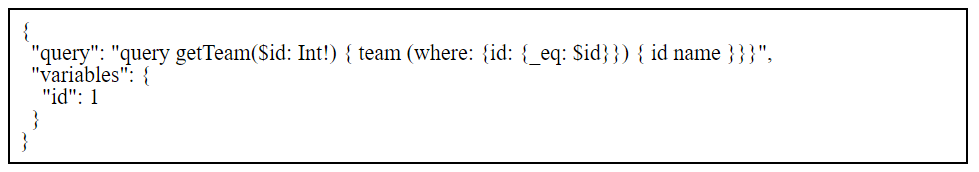
Now, the query string need only be defined once in your application and for various ids, the variables can be changed as required.
Query
A query is a GraphQL query typically used to fetch data. All the examples we saw earlier are “queries.” For example, when we get the team with id 2:
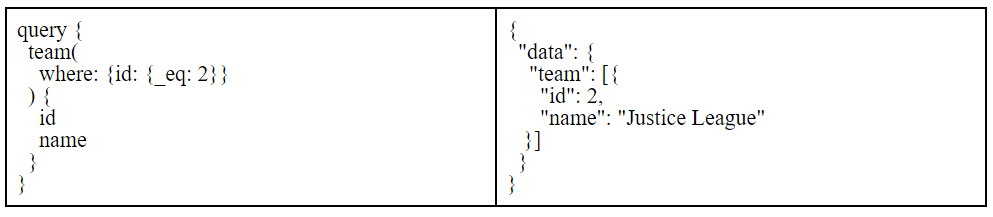
Multiple root nodes
Let’s take a look at how we can query multiple tables (or nodes) in the same query. For that, let us create a new table first.
Go back to the Data tab and create a new table called superhero with the following columns:
Column Name Type
id Integer
(auto-increment) nameText
team_id Integer
Other inputs and checkboxes like default value, nullable, and unique can be ignored. Choose id as the Primary Key and click the Create button.
Creating the superhero table.
Once the table is created, you’ll be taken to the Modify tab. Let’s switch to Insert Rows tab and insert some rows like we did last time.
The id column will be disabled like last time, since it will be auto-generated by Postgres. Let’s enter the name and team_id for each super hero. If we scroll back, team_id is 1 for Avengers and 2 for Justice League.
name team_id
Captain America 1
Black Widow 1
Batman 2
Wonder Woman 2
Once we add the data, using GraphQL, we can fetch data from multiple nodes (tables) in the same query. Copy the following query into GraphiQL and hit the Play button.

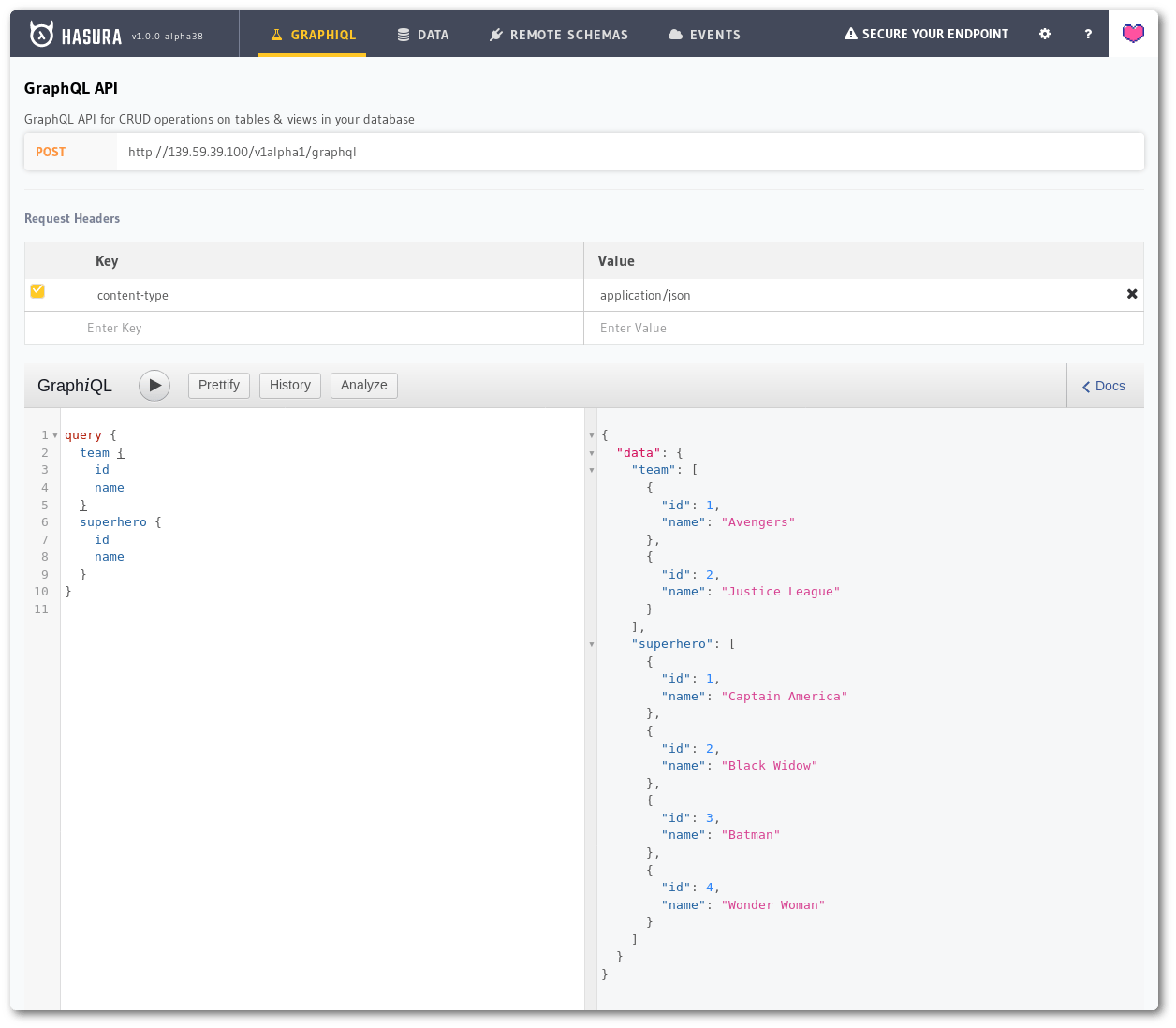
Using multiple nodes in the same GraphQL query.
Similarly how many ever such top-level nodes can be included in a single query. This applies to mutations too, but subscription spec limits subscriptions to contain only one top-level node.
Querying related data
For data that are related and are in multiple tables, we can define relationships over the columns and query them in a nested format. For e.g. let us see how we can query for the team and get all the superheroes in that team.
In order to do this, we need to create a relationship between team and superhero tables. We already know that team_id is our link. In relational database modelling, a foreign key constraint is added on this column to indicate the values in this columns should also be present as the id column in team table. Let’s first add that constraint. Note that this is totally optional and will only act as a constraint, as a foreign key is not required to create a relationship.
Head to the Data tab, click on the superhero table on the left and then go to the Modify tab. On this tab, click on the Edit button next to team_id column. This will open up certain properties of that column. The last one among them will be a Foreign Key. Tick the checkbox there and then choose team as the reference table and id as the reference column. Then click the Save button.
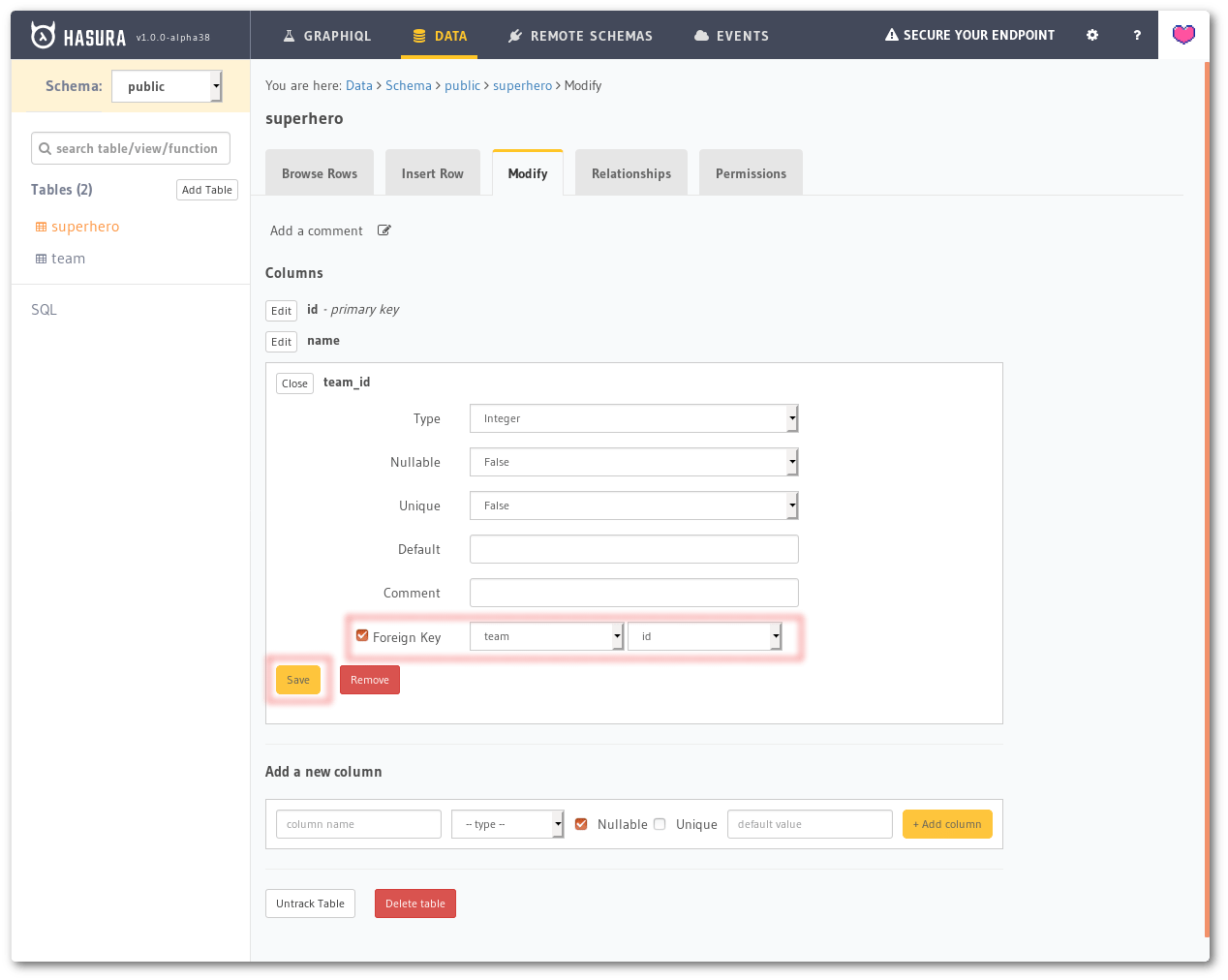
Creating a Foreign Key constraint on team_id column
Once the save has happened, a notification appears on the top right saying the constraint is created.
Now, head to the team table by clicking on the left sidebar. Go to the Relationships tab and you’ll see a new array relationship suggestion.
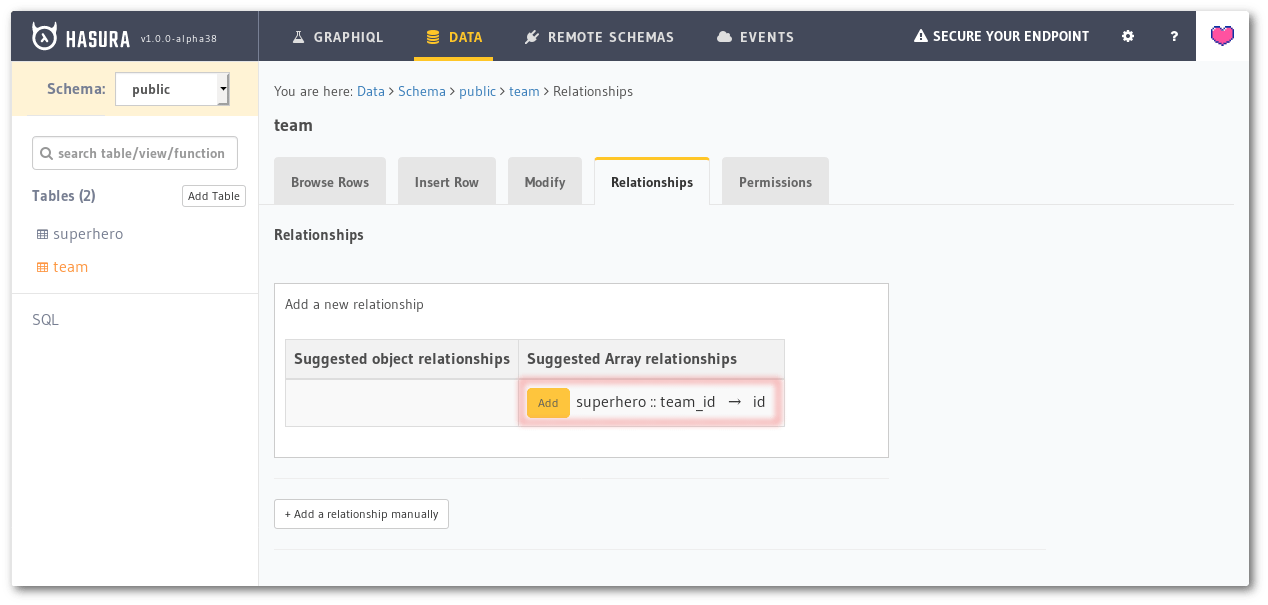
Array relationship suggestion on the team table
Click on the Add button here. A name will be auto-filled for the relationship, let’s change it to just superheroes and click the Save button.
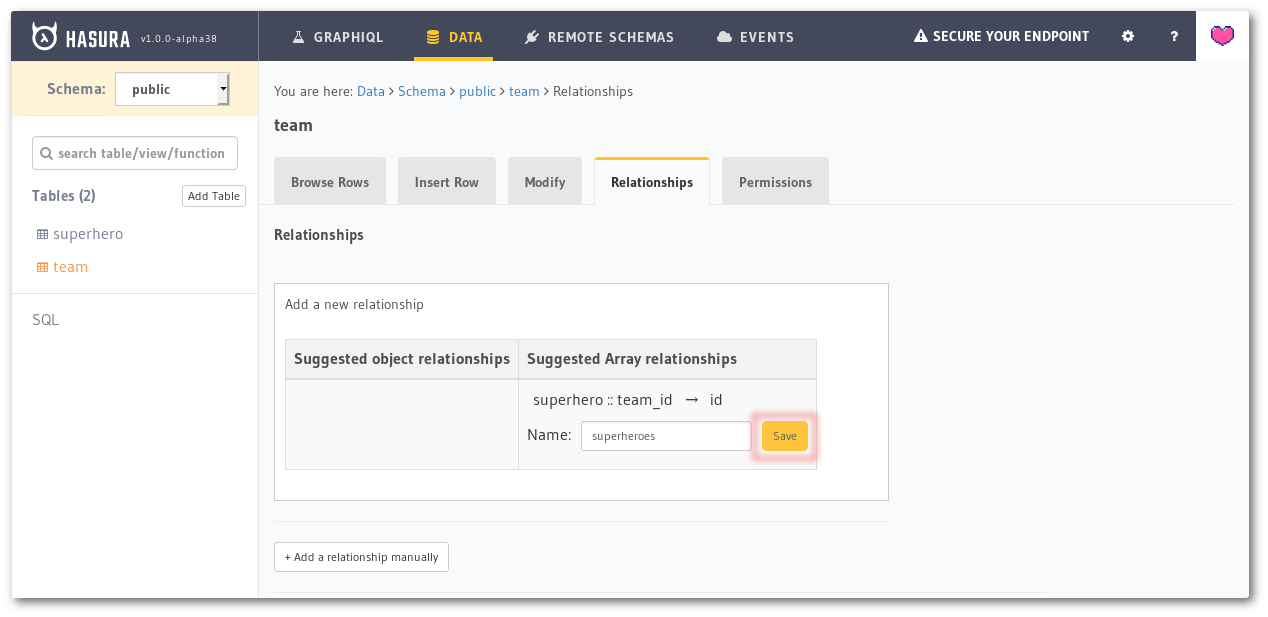
Entering the array relationship name as superheroes
You’ll see a notification on the top right saying the relationship is saved.
Now, head back to GraphiQL by clicking on the top bar and copy paste the following query and click *Play* button to execute.

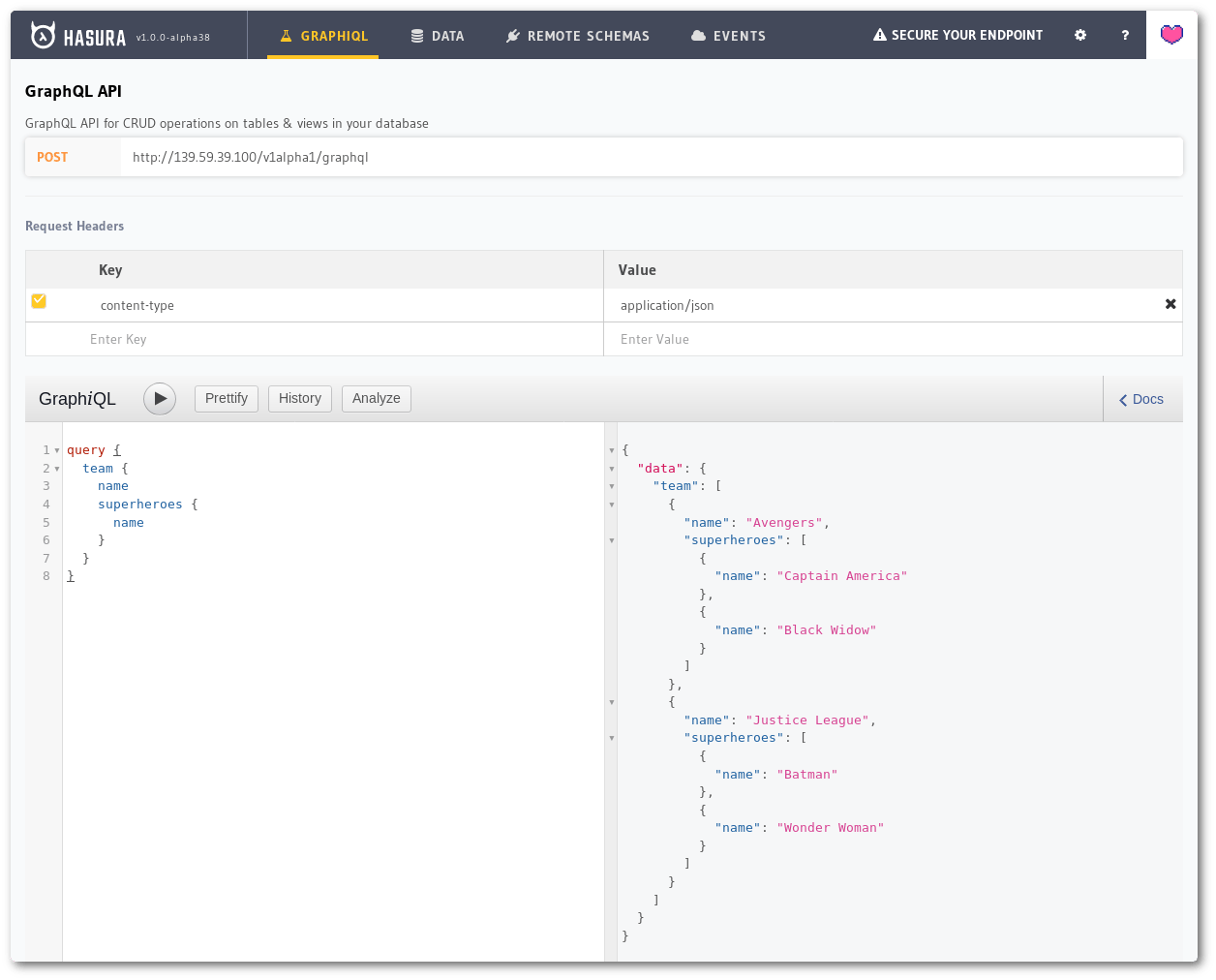
Querying related data
One query can traverse related objects and their fields, letting clients fetch lots of related data in one request, instead of making several round trips as one would need in a classic REST architecture.
Mutation
In GraphQL realm, a mutation is a type of query that typically mutates data, like database insert/update/deletes. REST equivalents would be PUT/POST/DELETE requests. Let’s say I need to add a new superhero to my database. A REST request would look like the following:

Now, let’s take a look at the GraphQL equivalent:

We can also have the name as a variable so that we do not have to manipulate strings to insert different Avengers.
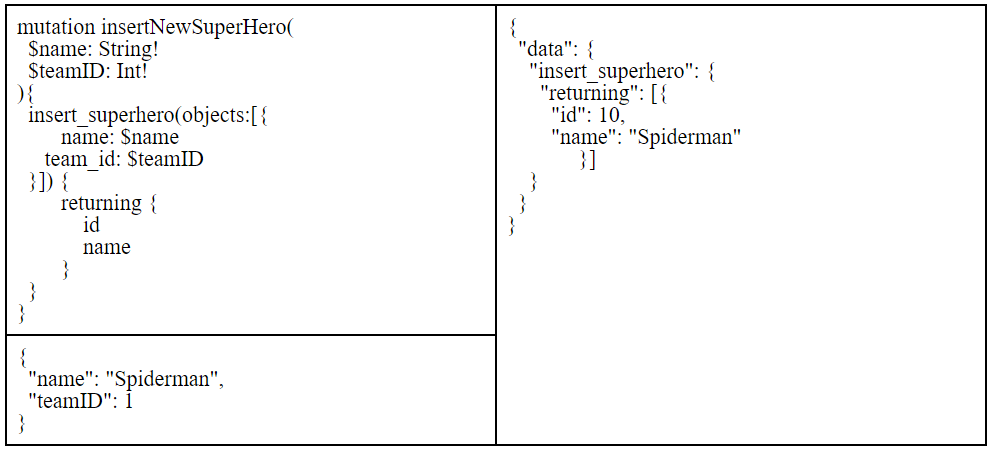
Like we mentioned before, the first column is the query, the one on the bottom are the variables, and the right columns shows us the response.
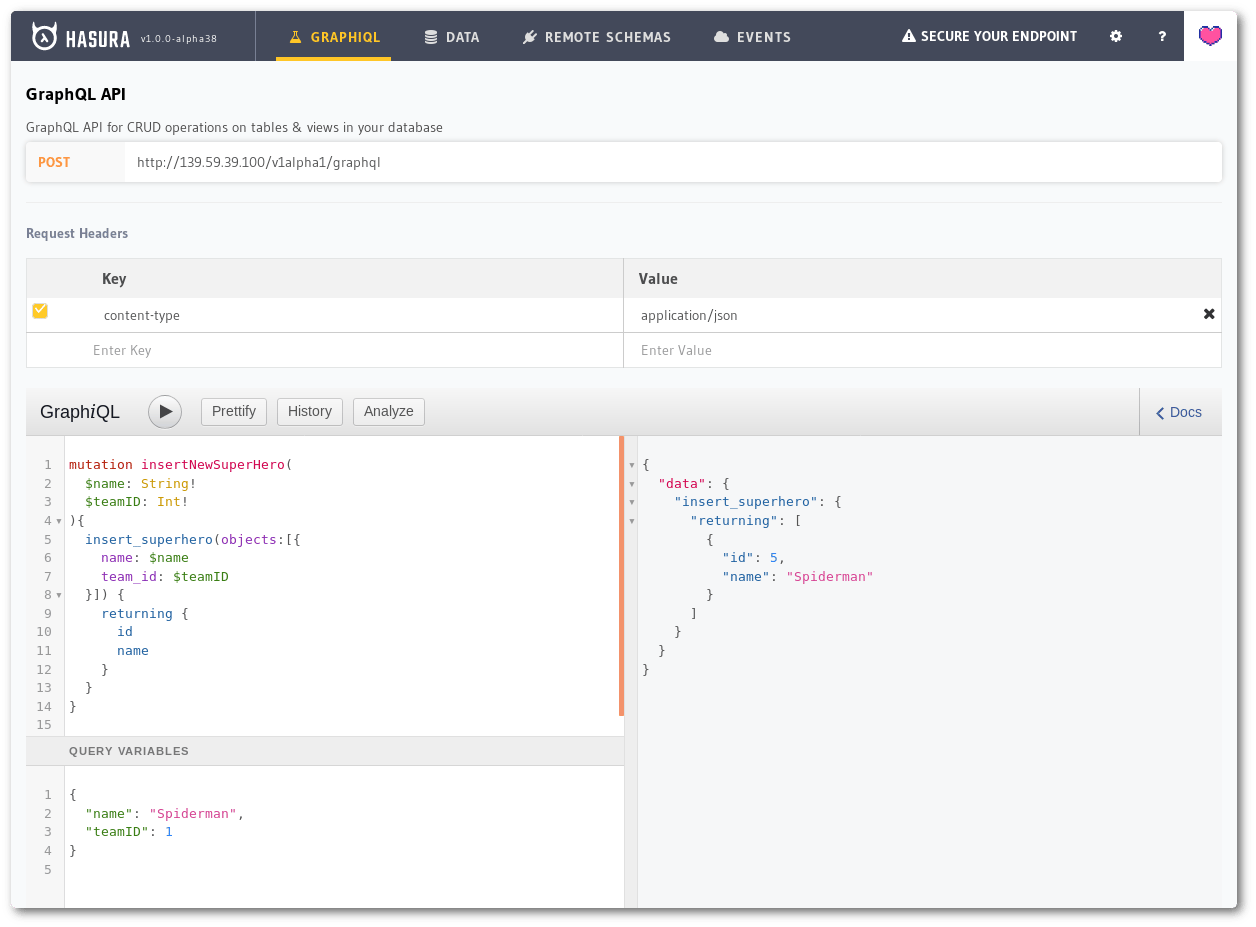
A mutation inserting a new superhero
Like queries, we can mix multiple mutations in the same request. You can also insert related data in a single mutation.
Subscription
Subscriptions provide real-time capabilities in GraphQL. Traditionally there are two options to obtain live data on the client side. One is calling the REST endpoint at regular intervals of time till we get the desired state (also called polling) and the other is to push an event to the client from the server using websockets.
Polling is a highly inefficient process and implementing websockets are a nightmare. GraphQL subscriptions also works over websockets, but GraphQL community has standardised what the language the websocket server and client should speak. Because of that, all clients and servers are compatible with each other and the integration is seamless.
Any query can be converted into a subscription with Hasura. For example, the query to get all Avengers can be made into a subscription like this, and if a web component is rendered (say React) using this data, the component re-renders when a new item gets added. This can be experimented on easily by opening two GraphiQL windows: running a subscription on one window, while try making a mutation on the other one.
The subscription on the left column, when copied onto GraphiQL and executed, is asking the server to send changes on the team table, particularly for the one with id equals 1, as and when they happen. The mutation on the right, when executed, will insert a new superhero to the superhero table. Since the two tables are related through team_id, Hasura notices that there is a new superhero that has been added to team 1 and pushed that information onto the client. The result of the subscription updates automatically—all in real-time.

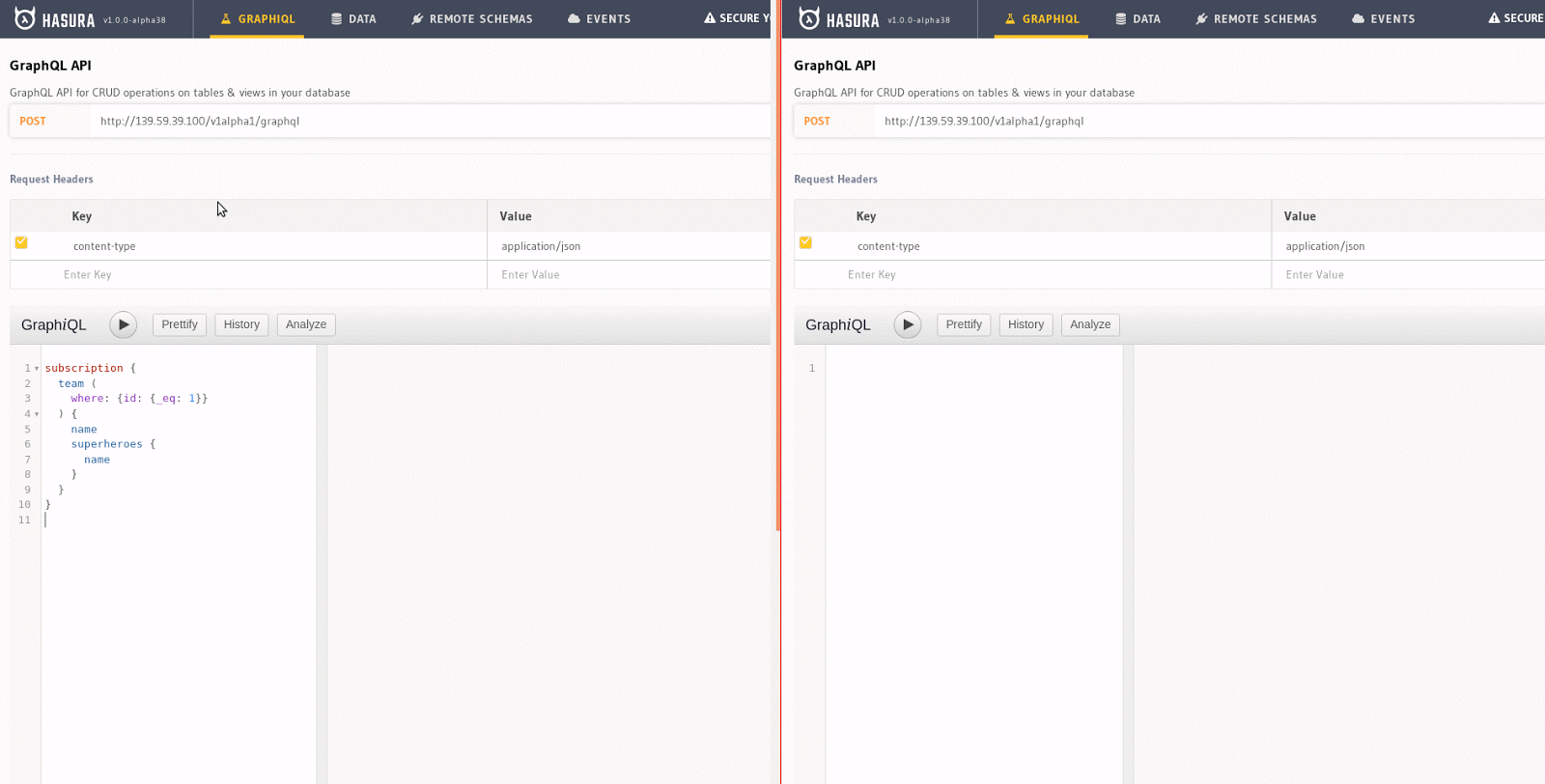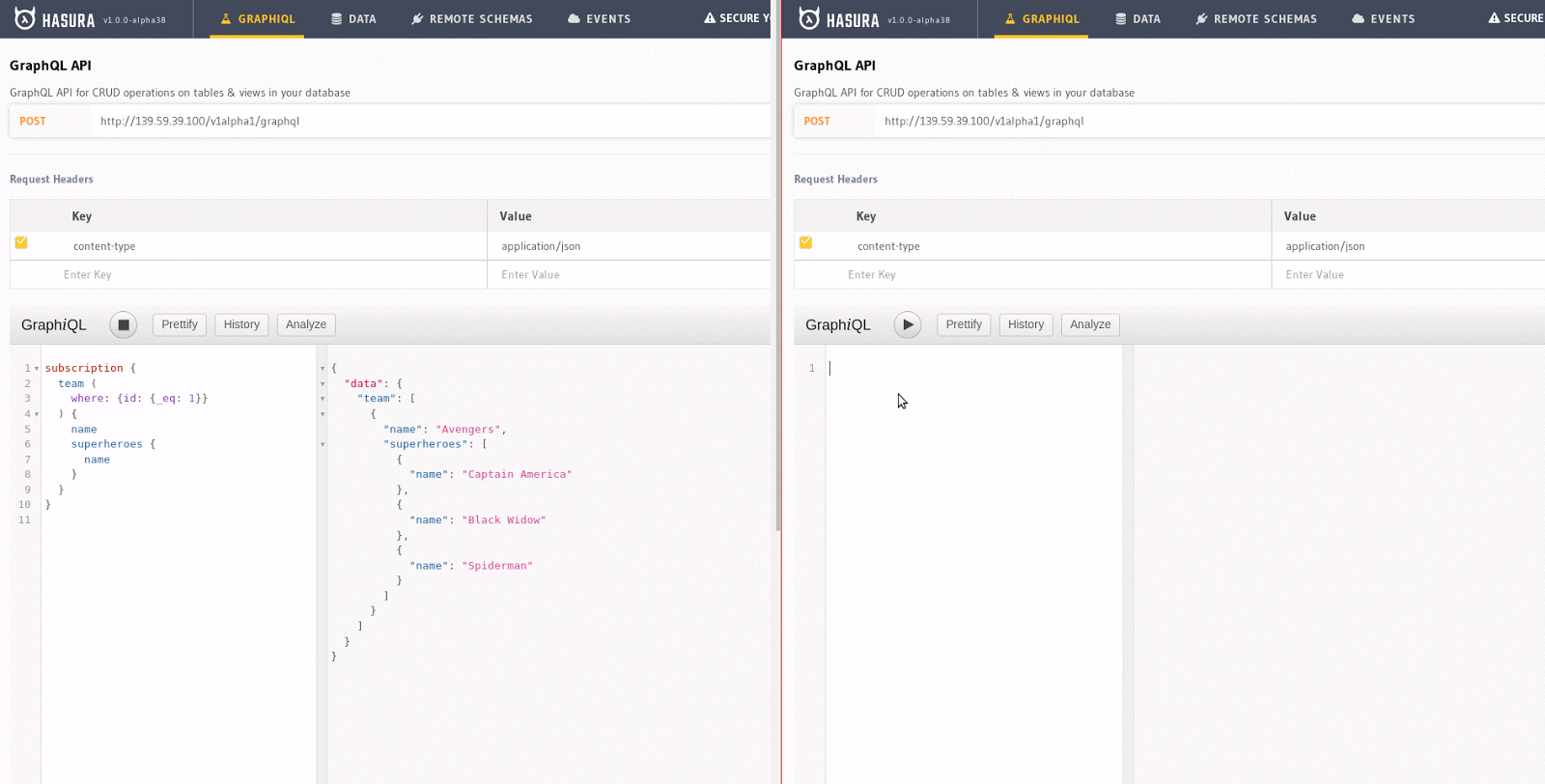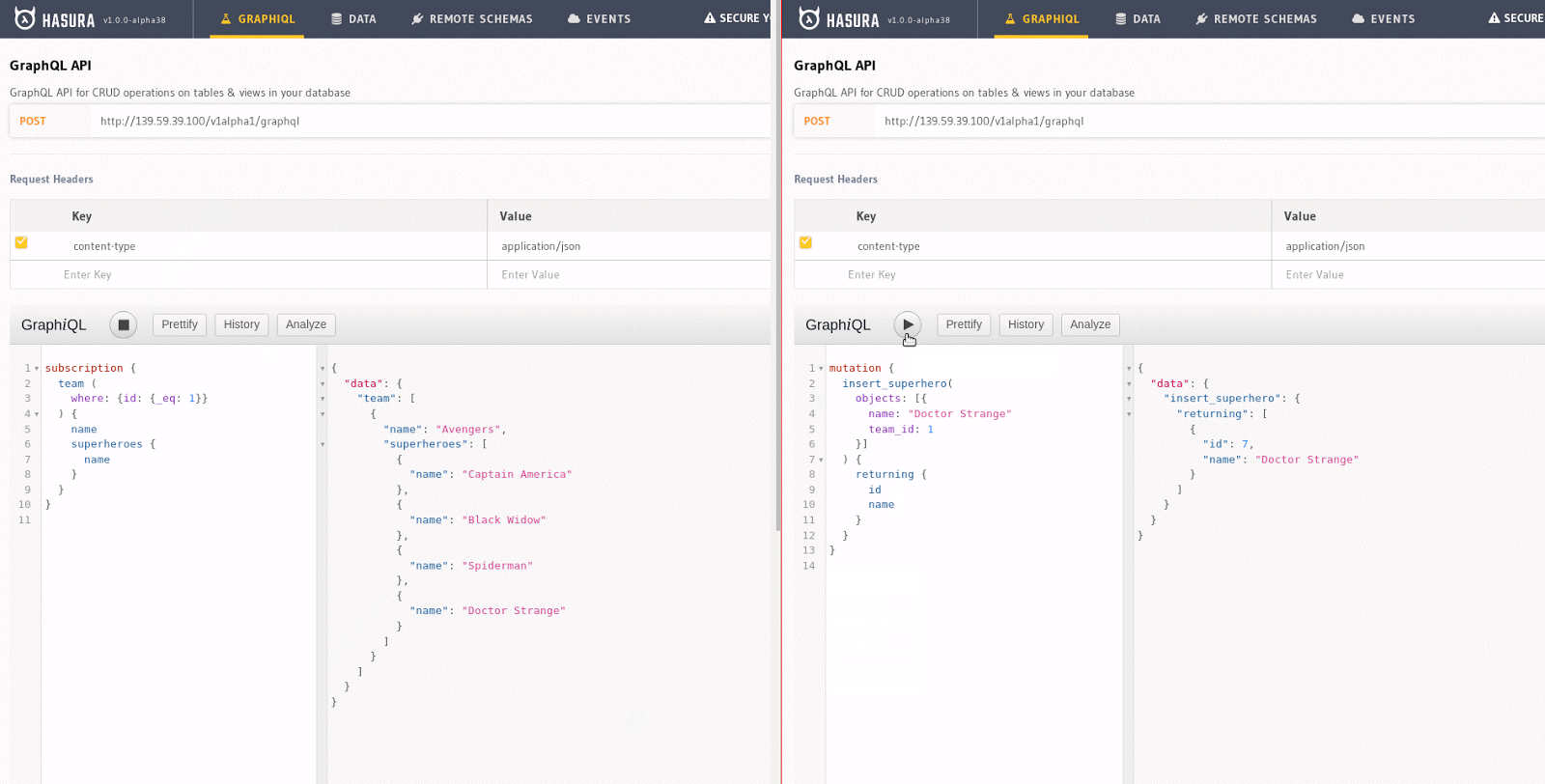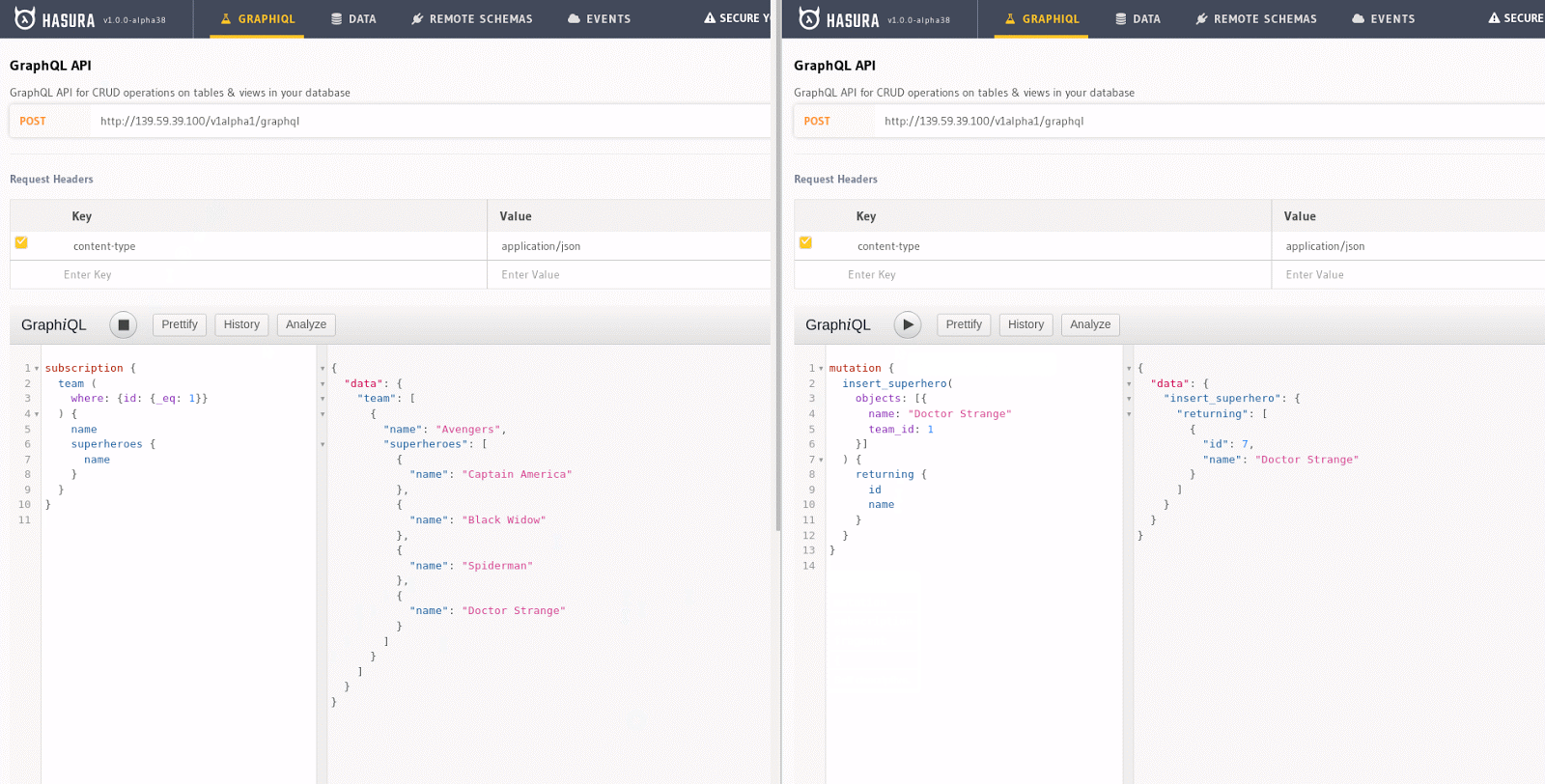
A GIF showing subscriptions
Under the hood, the GraphQL client and the server communicate over websockets and messages are transferred without any extra involvement from the user. When used in a application, the client library takes care of all the plumbing for the user.
The GraphQL Schema
Documenting APIs is very important for team collaboration and feature velocity. The backend team works on the API, documents it, and passes it down to the frontend team. But, by the time the frontend team gets to use the APIs, the documentation could be out of date, missing, or plain wrong, since a separate human process is required for maintaining docs.
GraphQL attempts to address this issues by introducing a type system for the API: the GraphQL schema. It talks about what fields the client can query, whether it is an integer or a string, what are the parameters for this mutation, is this parameter required or not etc.
In fact, you could make a GraphQL query to get this schema. This is called introspection, where the server publishes its own schema and clients can query it when required. This opens up lot of possibilities, including type safety for your API. Clients can look at this schema and generate code required for making idiomatic type safe API calls and errors could be caught at compile time itself instead of at runtime (for clients written in typed languages). IDEs can exploit this and show live feedback like autocomplete and validation on the queries written by the developer.
Try out the following query:

There is a *Docs* button on the top right corner of GraphiQL tab where you can browse this schema. It is helpful in figuring out what are the queries/mutations/subscriptions supported by the server and what their arguments and return types are.
Conclusion
In this tutorial, we learned about GraphQL by setting up a GraphQL server over Postgres and by trying out some GraphQL queries, mutations, and subscriptions. We have gone through the types of GraphQL queries and the different parts within a query. We also walked though how a GraphQL schema helps building intelligent tools for the ecosystem, which increases developer productivity.
As next steps, you’d want to integrate GraphQL with your application, including authentication and authorization. Check out the resources below for further reading.
Resources
- Building your schema
- GraphQL Queries
- GraphQL Mutations
- GraphQL Subscriptions
- Event Triggers
- Remote Schemas
- Authentication/Access control
- Database Migrations
- Hasura GraphQL Guides
Community and Support
If you have any questions regarding this tutorial or using Hasura, please reach out to the Hasura community:
About the author
Related Articles

Introducing langchain-gradient: Seamless LangChain Integration with DigitalOcean Gradient™ AI Platform
Narasimha Badrinath
- August 19, 2025
- 2 min read

Agentic Cloud: Reinventing the Cloud with AI Agents
Bratin Saha, Chief Product & Technology Officer
- May 19, 2025
- 5 min read

How to optimize your cloud architecture for business growth
- May 9, 2025
- 5 min read