Scaling Droplet Public Networking
By Armando Migliaccio
- Published:
- 6 min read
The Evolution of Scalable but Simple Networking Solutions
At DigitalOcean, we pride ourselves on the simplicity of the solutions that we offer to our customers. And this applies to our networking offerings as well. At the time of writing this piece, each Droplet is created with a public interface, which has a v4 address (or an optional v6 address) that is publicly routable on the internet. There is no layer in between like those in a NAT gateway. This results in a simple user experience, which gives customers access to their own Droplets.
The simplicity of the networking offered translates into the underlying data center design as well. Once packets destined for the Droplet’s public addresses reach DigitalOcean’s data centers, they are switched directly to hypervisors and sent to the Droplet networking stack via a virtual switch running on the hypervisor (Open vSwitch). The reverse path works similarly with the hypervisor virtual switch taking packets from the Droplet and moving them from layer-2 networking to the core infrastructure.
As we’ve scaled over the years, however, this simple model began to create performance and reliability challenges in the way the networking infrastructure was deployed and managed – from the scarcity of IPv4 addresses to the scalability limitations of layer-2 networking.
After nearly two years spent iterating, we’re excited to share our solution to these challenges, along with the phases in deploying the new networking model. This piece will explore our growing pains, how we tackled them, and the accomplishments achieved throughout this journey.
Early Days: the Scaling Issues
If you looked at the networking design of one of our most popular global regions (like TOR1), you would see a simple CLOS fabric where the Droplet’s default gateway resides on core switches, while the spine/leaf layers (including the hypervisor) operate as a simple access layer. This design is relatively easy to deploy, configure, and integrate – which made perfect sense at the scale DigitalOcean was operating in its early days.
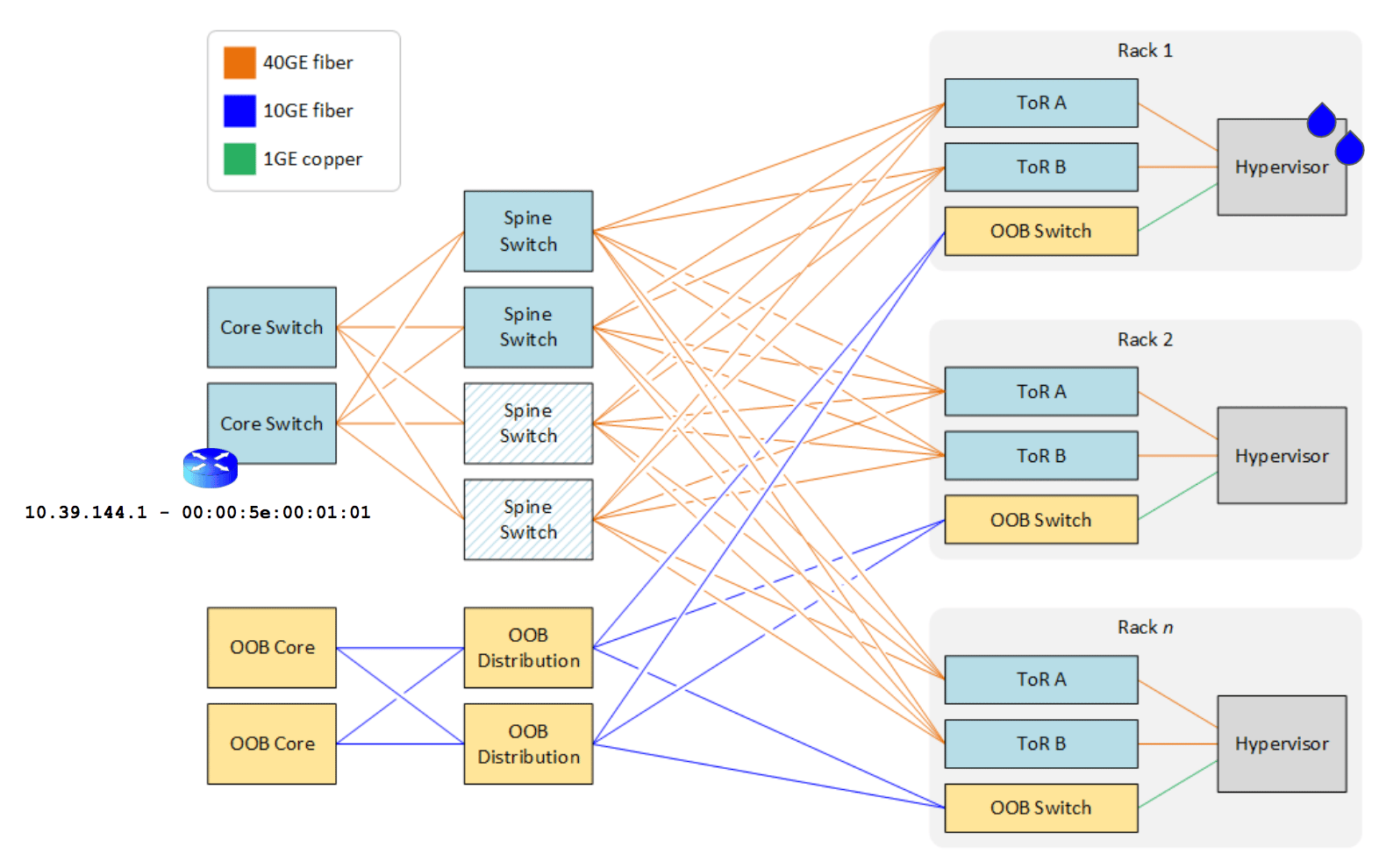
But this design has a a number of shortcomings:
Performance: When a hypervisor or a core does not know the destination for a packet, it would do what any endpoint would do on a layer-2 domain when it needs to discover the destination for a packet. It would broadcast a request for address resolution (using ARP for IPv4). This means that at large scale, the network will begin to get congested with a lot of broadcast traffic or unknown unicast.
- Troubleshooting: Broadcast traffic makes troubleshooting much more difficult due to the sheer number of endpoints involved in the broadcast domain, making us victims of the proverbial finding the needle in the haystack.
- Hardware limitations: Each hardware switch has a finite amount of memory space devoted to storing the MAC entries per broadcast domain. In our most popular regions, we are operating very close to the physical limitations of our networking gear.
- Huge failure domains: Even though we operate redundant infrastructure, a failure of a single core switch can cause a significant outage due to how layer-2 failover protocols work as the blast radius spans the entire data center.
- Inefficient infrastructure utilization: The plug-and-play nature of layer-2 means the networking gear must implement the equivalent of a spanning tree protocol to avoid network loops. Avoiding network loops means that not all the links and infrastructure gear can or will be used at once.
- Configuration errors: As the number of VLANs to configure increases, the chance of a misconfiguration across the many thousands of top-of-rack switches increases with it.
One way to address these scalability issues is to horizontally replicate each data center layout, (also known as a layer-2 zone), which is something we’ve done in our largest data centers like FRA1 or NYC3. But this scaling mechanism does introduce the more subtle problem of efficiently utilizing the publicly routable IPv4 addresses, which are scarce and expensive. Over the years, DigitalOcean has bought a number of contiguous blocks as we’ve expanded globally, but there are physical hardware limitations that prevent these contiguous blocks from being fully utilized across zones once assigned to a given layer-2 zone. As a result, once the constraints are hit – and due to the nature of how layer-2 operates – these IPs get stranded. This means they cannot be actively allocated and assigned to Droplets created in data center zones that have available compute capacity. Historically speaking, a solution to this problem would be buying more IPs and/or adding more zones, both of which are very expensive.
The Journey Toward our Solution
The common industry practice to solve for scalability challenges while also retaining mobility and agility for virtual machines is to virtualize the network. This is done by separating the logical traffic (the Droplet’s) from the physical traffic (the hypervisor’s) in what is usually referred as the overlay/underlay split. The underlay traffic runs over a routed IP fabric (whose packets are forwarded via any routing protocol of choice, usually BGP), while the overlay traffic runs on a so-called SDN fabric, which can employ a variety of protocols to distribute packets to and from virtual machines. The protocols in SDN solutions vary greatly depending on various factors like whether or not encapsulation is employed.
We considered many factors at DigitalOcean in order to choose a SDN solution and integration strategies for our physical underlay. Throughout the evaluation, we realized that no turnkey solution – either open source or commercial – would allow us to maintain a low total cost of ownership (TCO) while minimizing the impact to our customers during the lift and shift of the old machinery to the new one. For example, VXLAN encapsulation (and solutions based on EVPN) was impossible because a good portion of our hypervisor fleet was incapable of VXLAN hardware offload – and the operational cost involved in replacing these NICs was prohibitive. The penalty caused by tunneling was devastating in terms of vCPU cores burned due to encapsulation/decapsulation in software, and the loss of line-rate speed. Running pure L3 routing to the host was impossible without route summarization to circumvent hardware limitations in routing tables in leaf/spines. Route summarization was also out of the question without overhauling our compute scheduling layer and/or reorganizing the existing customer workload.
After significant analysis, the aha! moment struck: Employing label switching (namely MPLS) in conjunction with a layer-3 protocol like BGP allowed us to work around hardware limitations in our fabric, while achieving a routed solution for our public Droplet networking. The rest of the story was mostly smooth from there. Each Droplet v4 (and v6 addresses) is advertised as BGP route(s) into the underlay fabric from a bespoke distributed SDN controller as they come and go from hypervisors. For this orchestration layer, we fully leveraged the power of open source: BIRD, GoBGP, and OVS.
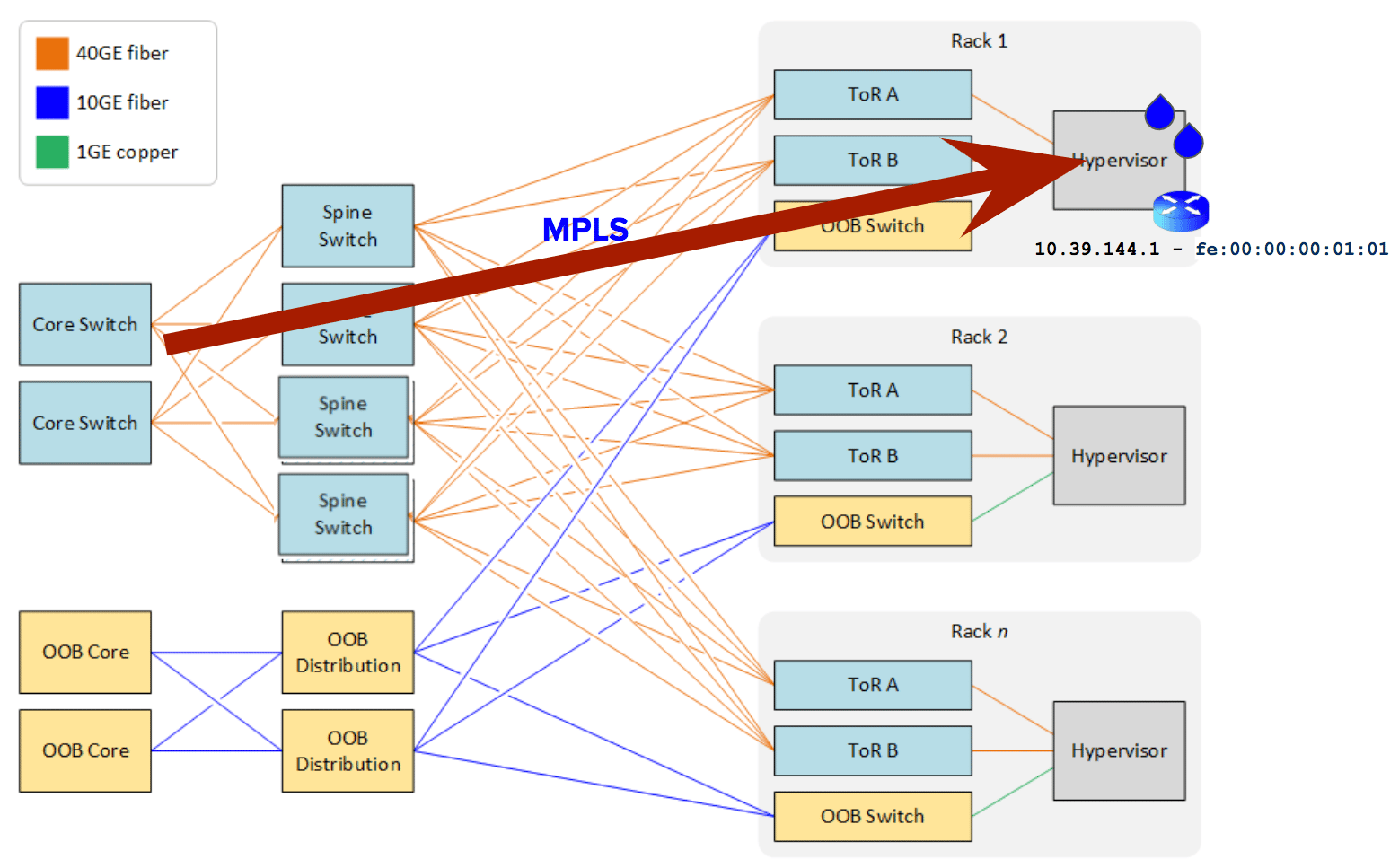
With an effort involving multiple teams and spanning multiple years, we are now in the last stages of our journey to scale out our public Droplet networking to new limits. In very simple terms, we turned the layer-2 design into a layer-3 design. Each hypervisor in the fleet now acts as the Droplet’s default gateway. Packets are then forwarded step by step from the core via spine and leaf layers all the way to the hypervisor (instead of being switched over layer-2).
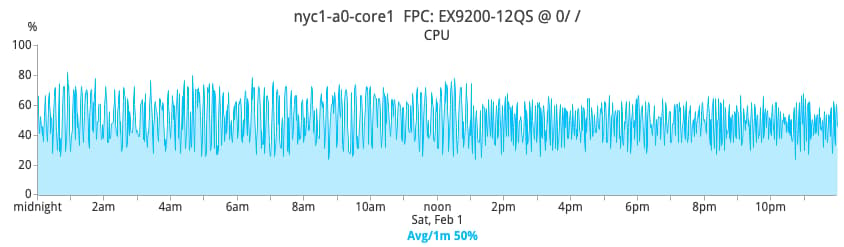
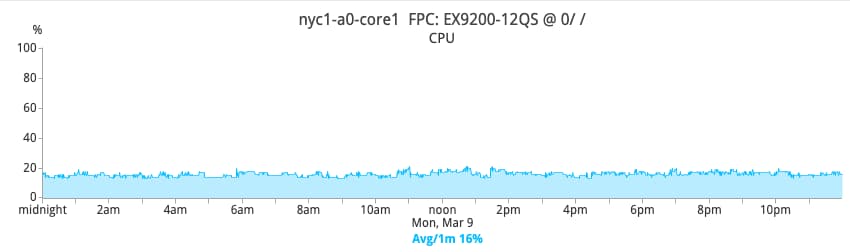
The positive effects on the networking gear are profound. For example, given the drastic reduction of broadcast and unknown unicast traffic that the networking gear has to process, overall CPU consumption becomes much more stable and greatly reduced. The pictures below show the CPU percentage of one core switch in NYC1 before and after the switch to layer-3.
Before
After
If you are interested in learning more about the intricate details of the solution, this OVSCon 2019 presentation goes into more depth about the steps taken to achieve this transition.
Final Considerations
Rolling out layer-3 across our fleet has been an ongoing effort for the last year and half. This piece only explores the tip of a very big iceberg. Today, the following regions are layer-3-enabled: TOR1, BLR1, NYC1. More regions will follow throughout 2020. The greatest challenge we faced as an engineering team was accomplishing the architectural shift with minimal disruption to our customers. But the overall success of this experience (though not without hiccups) was an exceptional milestone, proving we have the resources and expertise to deploy significantly complex and innovative solutions! What else does this shift mean for our customers? You’ll continue to get the best-in-class networking experience for your Droplets and applications.
Related Blog Posts
Digital Ocean’s Journey From TechStars Reject To Cloud-Hosting Darling
What’s New With the DigitalOcean Network
Zero Touch Provisioning: How to Build a Network Without Touching Anything
Floating IPs: Start Architecting Your Applications for High Availability
Building the Next Generation of DigitalOcean Networking
Tutorials
About the author
Related Articles
Under the Hood: Serving Kimi K3
Jonathan Dieu
- July 30, 2026
- 12 min read

Outperforming Fable 5 at half the price: meet model synthesis, a new server-side tool on DigitalOcean Inference Engine
- July 23, 2026
- 8 min read
Upcoming GPU Pricing Updates
- July 21, 2026
- 2 min read