What's Your Libscore?
By Jesse Chase
- Published:
- 4 min read
The contributors to Libscore, including our own Creative Director Jesse Chase, wanted to offer this post as a thank you for all the support the project has received. Julian Shapiro launched Libscore last month hoping that the developer community would find the tool useful, and continues to be grateful for all of the positivity and constructive feedback throughout the web.
For those who haven’t heard, Libscore is a brand new open-source project that scans the top million websites to determine which third-party JavaScript libraries they are using. The tool aims to help front-end open source developers measure their impact – you can read all about it here.
In this post, we’ll break down the technology that Libscore leverages and discuss some of the challenges getting it off the ground. We were also lucky enough to talk with Julian and get some insight as to where he sees the project going.
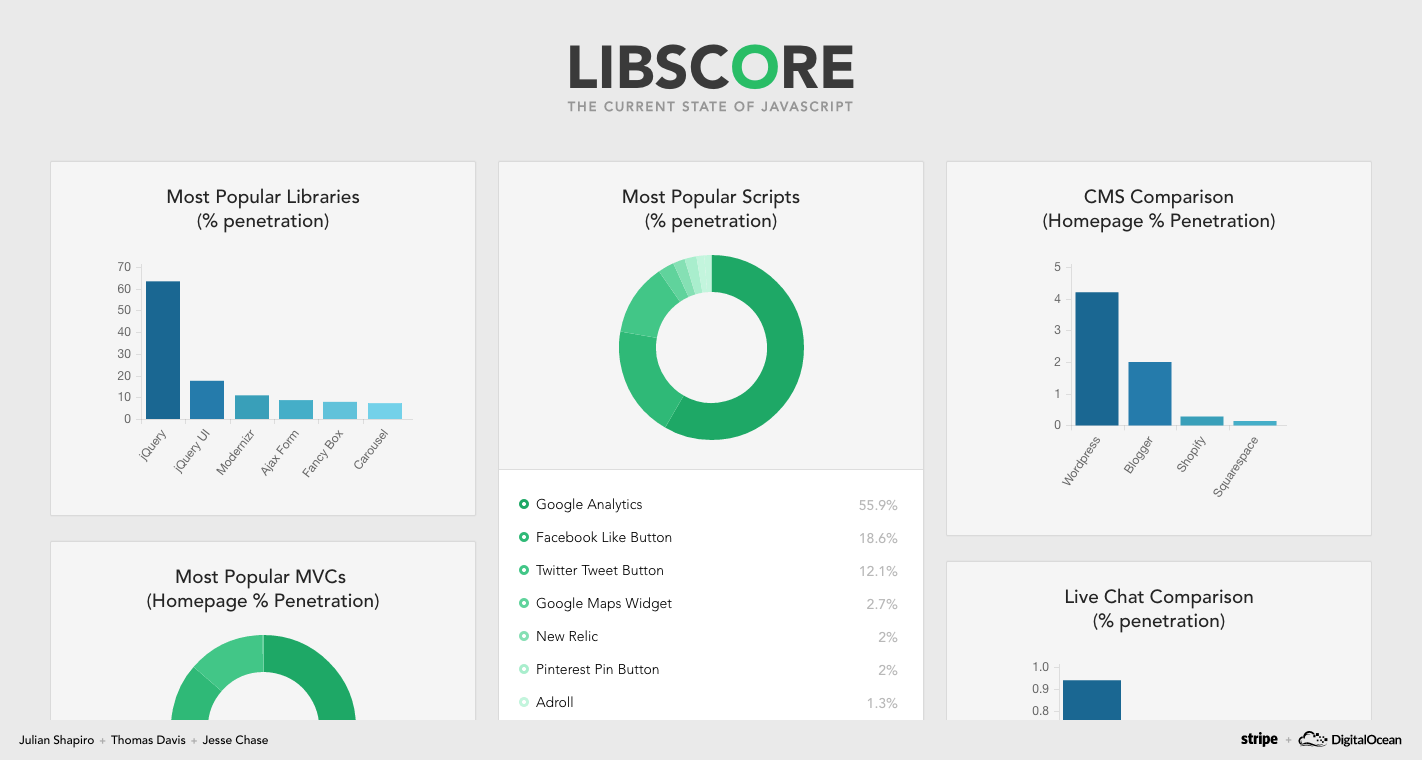
Thomas Davis: A Technical Overview
Unlike traditional web crawlers, Libscore thoroughly scans the run-time environment of each website into a headless browser. This allows Libscore to monitor the operating environment on each website and to detect as many libraries as possible – even those that have been pre-bundled and required as modules. The tradeoff, of course, is that running one million headless browser connections is much more resource intensive than performing basic cURL requests and parsing static HTML.
The biggest insight we gained while designing the crawler is that the best way to weed out false positives for third-party plugins is to leverage the broader data set we’re aggregating. Specifically, we weed out third-party libraries that didn’t exist on at least 30 sites out of the 1 million crawled. Using meta-heuristics like these allowed us to more confidently detect libraries that were in fact third-party plugins, and not just arbitrary JavaScript variables that were leaking to the global scope.
On the backend, crawls are queued via Redis with the results stored in MongoDB. Both services are loaded fully into RAM which allows our RESTful API to serve requests faster than it would querying the disk. The main bottleneck to crawling concurrency is network bandwidth, but thanks to DigitalOcean, it was a breeze to repeatedly clone instances and run crawls during off-peak times in different regions. Ultimately, using just a few high-RAM DigitalOcean instances, we parse 600 websites per minute and complete the entire crawl in under 36 hours at the end of each month.
As the crawler runs, raw library usage data for each site is appended to a master JSON file, which we simply read from the file system with Nodejs. Once all the raw usage data is collected we start a process dubbed “ingestion”, which is responsible for aggregating the results and making them accessible via the API. We actually attempted to load the entire dataset into ram to perform our calculations, but quickly ran into a quirky problem with V8 not being able to allocate anymore than approximately 1GB of memory for arrays. For now, we are splitting up the raw dump into smaller files to bypass the memory limit, though in the future we might just rewrite the project to use a more suitable language and environment.
Jesse Chase: Design Improvements
While Libscore currently serves as an invaluable tool for surfacing library adoption data, the future is even more exciting. To illustrate it let’s jump ahead 6 months – smack in the middle of summer. At this point, Libscore will have crawled through the top million sites 6 times already (or 6 million domain crawls!), bringing forth rich month-over-month trend data on library usage.
By providing users with a soon-to-be-released time series graph, with the ability to plot multiple libraries over the same time period, developers will gain new insights into how libraries are changing over time. For example, users will be able to see why a library’s usage plummeted from one month to the next – potentially due to the increased adoption of another library. Soon, this data will be fully visualized.
Julian Shapiro: The Future Of Libscore
Libscore is more than a destination for JavaScript statistics; it’s also a data store that can be leveraged in the marketing of open source projects. One way we’re enabling this is via embeddable badges that showcase real-time site counts. Open source developers can show off these badges in their GitHub README’s, and journalists writing about open source can similarly include them to provide context on the real-world usage of libraries.
In addition to badges, we’re also releasing quarterly reports on the state of JavaScript library usage. These reports will showcase trends, helping developers learn which libraries are rising in popularity and which are falling. We hope these reports will become a valuable contribution to discussions around the state of web development tooling, and to finally provide the community with concrete data they can use to make decisions.
Creator and developer – Julian Shapiro
Backend developer – Thomas Davis
Creative Director – Jesse Chase
About the author
Related Articles
Under the Hood: Serving Kimi K3
Jonathan Dieu
- July 30, 2026
- 12 min read

The Inference Alpha: Maximizing Frontier Models on AMD
Balaji Varadarajan
- June 10, 2026
- 12 min read
Open by Design: How NVIDIA and DigitalOcean Are Building the Stack for the Always-On Agentic Era
- June 2, 2026
- 7 min read