
Introduction
In the field of robotics, there is greater emphasis on developing general-purpose robotics. Gains in computer vision and natural language processing have allowed for the development of Vision Language Action (VLA) models, which seek to provide robots with a “general intelligence” capable of interpreting the physical world through a unified multimodal lens.
Early milestones like Google DeepMind’s RT-1 and RT-2 demonstrated that transformers could map visual and linguistic inputs directly to robotic actions at scale, beginning the VLA model paradigm. Concurrently, datasets such as DROID and platforms like Aloha have expanded the diversity of manipulation tasks and improved hardware accessibility for the broader research community.
This article provides an overview of recent progress in VLA models for robotics. For more technical details, see the references and additional resources section.
Key Takeaways
- Robotics is shifting from task-specific programming to general-purpose Vision-Language-Action (VLA) models, aiming for “general intelligence” through unified multimodal input (vision, language) to action output.
- RT-1 (Google DeepMind) was the beginning of the VLA paradigm, demonstrating that a transformer could map multimodal inputs (images + language) directly to robot actions, generalizing across 700+ tasks.
- RT-2 coined the term VLAs. This work expanded upon RT-1 by integrating weights from large Vision-Language Models (VLMs) pre-trained on internet data, endowing robots with semantic understanding and reasoning. It represents actions as text tokens for co-fine-tuning.
- The Open X-Embodiment dataset, a massive collection of 1M trajectories from 20+ robot types pooled from 22 institutions was used for the training models like RT-2-X and OpenVLA to generalize across different robot hardware (multi-embodiment generalization).
- OpenVLA is a 7B parameter, open-source VLA model built on Prismatic VLM and Llama 2, trained on an even larger portion of the Open X-Embodiment data, making VLA research more accessible.
- Initiatives like the π series (π-zero, π-0.5, etc.) from Physical Intelligence represent the ongoing effort to create and open-source general-purpose foundation models for robotics.
Robotic Transformer 1 (RT-1)
RT-1 from Google DeepMind demonstrated the utility of the transformer (decoder-only) for processing multimodal inputs (images taken from a robot camera and text as natural language task descriptions) and outputting action tokens.
This model was trained on a large, diverse dataset of 130k robot trajectories across 700+ tasks, allowing it to generalize to new situations rather than being programmed for specific tasks. For example, when told to “pick up the apple,” RT-1 can identify the apple in its camera view and execute the appropriate grasping and movement actions.
 source
source
RT-1 features image and action tokenization, along with token compression, to improve inference speed.
Robotic Transformer 2 (RT-2)
RT-2 expanded upon RT-1 by incorporating vision-language models (VLMs) pre-trained on internet-scale data. This gave the robot “knowledge” from a massive corpora of image and text data on the web. In contrast to RT-1 which learned solely from robot demonstrations, RT-2 could leverage semantic understanding from its VLM backbone.
What’s particularly interesting is that in order to fit both natural language responses and robotic actions into the same format, the researchers expressed the actions as text tokens and incorporated them directly into the training set of the model along with natural language tokens. Also originating from Google DeepMind, this is the work that coined the term Vision-Language-Action model.
 source
source
This work presented two instantiations of VLAs composed of VLM backbones PaLM-E and PaLI-X, which the researchers call RT-2-PaLM-E and RT-2-PaLI-X. These models are co-fine-tuned with robotic trajectory data to output robot actions, which are represented as text tokens.
 source
source
The text tokens would de-tokenize into robot actions, during inference, allowing for closed loop control. This allowed the researchers to leverage the generalization, semantic understanding, and reasoning of pretrained VLMs in learning robotic policies.
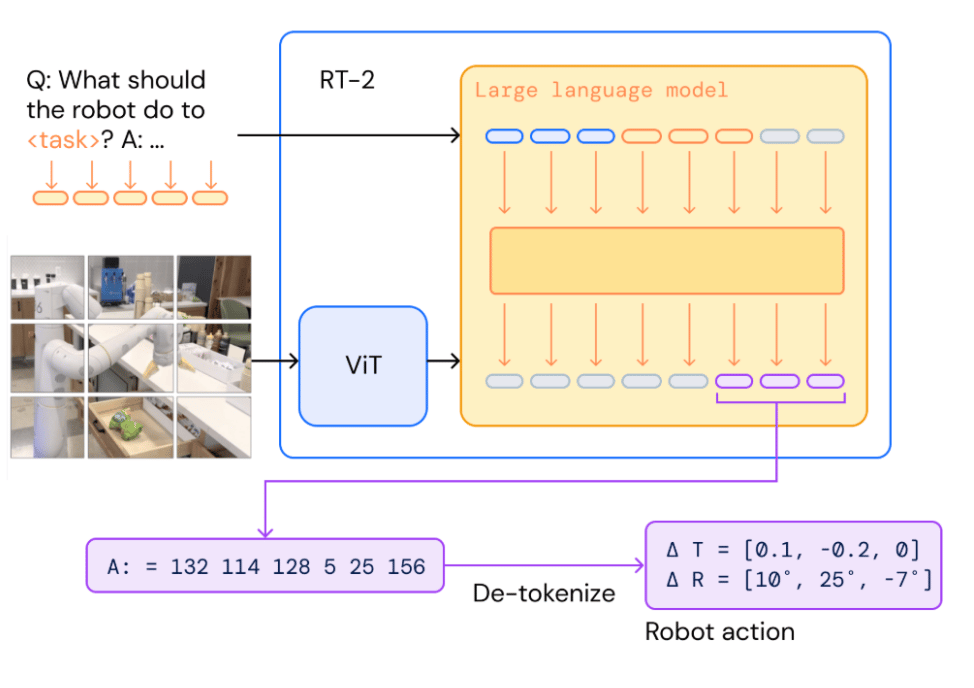
Similar to VLMs, RT-2 exhibited chain-of-thought reasoning. Ablations reveal the significance of pre-trained weights and the trend of model generalization improving with model size.
RT-2-X
Rather than a single new model, this was a collaborative effort to pool robotic data from 22 institutions across different robot platforms. The resulting dataset (Open X-Embodiment dataset) contained ~1M trajectories from 20+ robot types. Models trained on this diverse data (called RT-X models) showed better generalization across different robot hardware.
Open-VLA
OpenVLA is a 7B parameter VLA built upon the Prismatic VLM backbone, Llama 2 LLM, and DINOV2 + SigLIP for vision. This model is trained on 970k episodes from the Open X-Embodiment data which contains 27 real robot datasets, trained on 15 more datasets than RT-2-X.
Check out our tutorial on fine-tuning Open-VLA with DigitalOcean GPU Droplets.
Physical Intelligence’s π-series
Building general-purpose foundation models for robotics is a long-term goal for Physical Intelligence.
They open-sourced a VLA model π0 (Pi-zero), with newer iterations such as π0.5 and π0.6.
With π0 a 3 billion parameter VLM is adapted for real-time dexterous robot control by augmenting it with continuous action outputs via flow matching. This allowed π0 to output motor commands at high frequencies, enabling it to solve a range of downstream tasks. This model supports post-training for dexterous tasks like laundry folding, packing fragile items (e.g., eggs), dish handling, garbage disposal, cable routing, and more. Subsequent iterations π0.5 and π0.6, the RL-trained π*0.6 demonstrated advanced capabilities, including autonomous cleaning of never-before-seen Airbnb homes and success in a “Robot Olympics” benchmark with multiple autonomous events (claiming top performance on many remaining challenging robotic tasks).
FAQ
What is a Vision-Language-Action (VLA) model?
A VLA model is a type of artificial intelligence model, typically built on a transformer architecture, that can take multimodal inputs – specifically visual data (like images from a robot’s camera) and language instructions (natural language text) – and directly output robotic actions to accomplish a task in the physical world. They aim to provide robots with a form of “general intelligence.”
How does VLA differ from traditional robotics programming?
Traditional robotics requires explicit programming for specific tasks. VLA models, in contrast, are trained on massive, diverse datasets of robot trajectories and web-scale vision-language data. This allows them to generalize, interpret novel instructions, and handle new situations without being explicitly programmed for every single task.
What is the significance of RT-1 and RT-2?
RT-1 (Robotics Transformer-1) was a foundational model that demonstrated the feasibility of using a transformer architecture to map multimodal inputs directly to robot actions at scale. RT-2 advanced this by incorporating weights from large Vision-Language Models (VLMs) pre-trained on internet data, giving the robot broader semantic understanding and reasoning capabilities.
What is the Open X-Embodiment dataset and why is it important?
The Open X-Embodiment dataset is a massive, diverse collection of robot trajectories pooled from multiple institutions and different robot platforms (over 20 types). Its importance lies in enabling models like RT-2-X and OpenVLA to train on multi-embodiment data, significantly improving their ability to generalize and perform tasks across different robot hardware.
What is OpenVLA?
OpenVLA is a 7B parameter open-source VLA model built using publicly available backbones (like Prismatic VLM, Llama 2, DINOV2, and SigLIP). It was trained on an even larger portion of the Open X-Embodiment data than its predecessors, making it a powerful and accessible resource for the research community.
What is the goal of the π-series (Pi-zero, Pi-zero.5, etc.)?
The π-series, developed by Physical Intelligence, represents an ongoing initiative to create and open-source general-purpose foundation models specifically for robotics, furthering the goal of building truly adaptable and general-purpose robotic agents.
Final Thoughts
The journey from task-specific robots to general-purpose VLAs is fascinating because it’s an example of how gains in different subdomains in AI such as language and vision modeling allow for embodied intelligence. Models like RT-1 and RT-2 laid the groundwork by demonstrating the feasibility of using transformer architectures to unify vision, language, and action, leveraging internet-scale pre-training to endow robots with broader semantic understanding. The subsequent efforts, such as RT-2-X and OpenVLA, showcase the effectiveness of scaling data with massive, diverse, multi-embodiment datasets (like the Open X-Embodiment dataset) in achieving true generalization across different physical systems. While foundational models are still in their early stages, the rapid progress, marked by initiatives like the π-series, suggests that we are well on our way towards building truly intelligent, adaptable, and general-purpose robots capable of operating effectively in the unstructured real world. We’re excited to see all kinds of use cases such as Digital Biology Lab Automation!
DigitalOcean seeks to make your ambitions with AI possible: Train, Infer, and Build Agents with Gradient.
References and Additional Resources
RT-1 (Robotic Transformer 1) (December 13, 2021) RT-1: Robotics Transformer for real-world control at scale (blog) RT-1: ROBOTICS TRANSFORMER FOR REAL-WORLD CONTROL AT SCALE (paper)
RT-2 (Robotic Transformer 2)
(July 28, 2023)
RT-2: New model translates vision and language into action - Google DeepMind (blog)
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control (paper)
RT-X and Open X-Embodiment (October 3, 2023) Scaling up learning across many different robot types
OpenVLA
(June 13,2024)
OpenVLA (blog)
OpenVLA: LeRobot Research Presentation #5 by Moo Jin Kim
Physical Intelligence
π 0 : Our First Generalist Policy**
π0: A Foundation Model for Robotics with Sergey Levine - 719
Chelsea Finn: Building Robots That Can Do Anything
Fully autonomous robots are much closer than you think – Sergey Levine
FAST: Efficient Robot Action Tokenization
Emergence of Human to Robot Transfer in Vision-Language-Action Models
Noteworthy
Libero benchmark (2023): Benchmarking Knowledge Transfer in Lifelong Robot Learning
DROID: a diverse robot manipulation dataset
Aloha
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (blog) Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware (paper)
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
