
Introduction
Many data analysis, big data, and machine learning projects require scraping websites to gather the data that you’ll be working with. The Python programming language is widely used in the data science community, and therefore has an ecosystem of modules and tools that you can use in your own projects. In this tutorial we will be focusing on the Beautiful Soup module.
Beautiful Soup, an allusion to the Mock Turtle’s song found in Chapter 10 of Lewis Carroll’s Alice’s Adventures in Wonderland, is a Python library that allows for quick turnaround on web scraping projects. Currently available as Beautiful Soup 4 and compatible with both Python 2.7 and Python 3, Beautiful Soup creates a parse tree from parsed HTML and XML documents (including documents with non-closed tags or tag soup and other malformed markup).
In this tutorial, we will collect and parse a web page in order to grab textual data and write the information we have gathered to a CSV file.
Prerequisites
Before working on this tutorial, you should have a local or server-based Python programming environment set up on your machine.
You should have the Requests and Beautiful Soup modules installed, which you can achieve by following our tutorial “How To Work with Web Data Using Requests and Beautiful Soup with Python 3.” It would also be useful to have a working familiarity with these modules.
Additionally, since we will be working with data scraped from the web, you should be comfortable with HTML structure and tagging.
Understanding the Data
In this tutorial, we’ll be working with data from the official website of the National Gallery of Art in the United States. The National Gallery is an art museum located on the National Mall in Washington, D.C. It holds over 120,000 pieces dated from the Renaissance to the present day done by more than 13,000 artists.
We would like to search the Index of Artists, which, at the time of updating this tutorial, is available via the Internet Archive’s Wayback Machine at the following URL:
https://web.archive.org/web/20170131230332/https://www.nga.gov/collection/an.shtm
Note: The long URL above is due to this website having been archived by the Internet Archive.
The Internet Archive is a non-profit digital library that provides free access to internet sites and other digital media. This organization takes snapshots of websites to preserve sites’ histories, and we can currently access an older version of the National Gallery’s site that was available when this tutorial was first written. The Internet Archive is a good tool to keep in mind when doing any kind of historical data scraping, including comparing across iterations of the same site and available data.
Beneath the Internet Archive’s header, you’ll see a page that looks like this:
Since we’ll be doing this project in order to learn about web scraping with Beautiful Soup, we don’t need to pull too much data from the site, so let’s limit the scope of the artist data we are looking to scrape. Let’s therefore choose one letter — in our example we’ll choose the letter Z — and we’ll see a page that looks like this:

In the page above, we see that the first artist listed at the time of writing is Zabaglia, Niccola, which is a good thing to note for when we start pulling data. We’ll start by working with this first page, with the following URL for the letter Z:
https://web.archive.org/web/20121007172955/http://www.nga.gov/collection/anZ1.htm
It is important to note for later how many pages total there are for the letter you are choosing to list, which you can discover by clicking through to the last page of artists. In this case, there are 4 pages total, and the last artist listed at the time of writing is Zykmund, Václav. The last page of Z artists has the following URL:
https://web.archive.org/web/20121010201041/http://www.nga.gov/collection/anZ4.htm
However, you can also access the above page by using the same Internet Archive numeric string of the first page:
https://web.archive.org/web/20121007172955/http://www.nga.gov/collection/anZ4.htm
This is important to note because we’ll be iterating through these pages later in this tutorial.
To begin to familiarize yourself with how this web page is set up, you can take a look at its DOM, which will help you understand how the HTML is structured. In order to inspect the DOM, you can open your browser’s Developer Tools.
Importing the Libraries
To begin our coding project, let’s activate our Python 3 programming environment. Make sure you’re in the directory where your environment is located, and run the following command:
- . my_env/bin/activate
With our programming environment activated, we’ll create a new file, with nano for instance. You can name your file whatever you would like, we’ll call it nga_z_artists.py in this tutorial.
- nano nga_z_artists.py
Within this file, we can begin to import the libraries we’ll be using — Requests and Beautiful Soup.
The Requests library allows you to make use of HTTP within your Python programs in a human readable way, and the Beautiful Soup module is designed to get web scraping done quickly.
We will import both Requests and Beautiful Soup with the import statement. For Beautiful Soup, we’ll be importing it from bs4, the package in which Beautiful Soup 4 is found.
# Import libraries
import requests
from bs4 import BeautifulSoup
With both the Requests and Beautiful Soup modules imported, we can move on to working to first collect a page and then parse it.
Collecting and Parsing a Web Page
The next step we will need to do is collect the URL of the first web page with Requests. We’ll assign the URL for the first page to the variable page by using the method requests.get().
import requests
from bs4 import BeautifulSoup
# Collect first page of artists’ list
page = requests.get('https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ1.htm')
<$>[note] Note: Because the URL is lengthy, the code above and throughout this tutorial will not pass PEP 8 E501 which flags lines longer than 79 characters. You may want to assign the URL to a variable to make the code more readable in final versions. The code in this tutorial is for demonstration purposes and will allow you to swap out shorter URLs as part of your own projects.<$>
We’ll now create a BeautifulSoup object, or a parse tree. This object takes as its arguments the page.text document from Requests (the content of the server’s response) and then parses it from Python’s built-in html.parser.
import requests
from bs4 import BeautifulSoup
page = requests.get('https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ1.htm')
# Create a BeautifulSoup object
soup = BeautifulSoup(page.text, 'html.parser')
With our page collected, parsed, and set up as a BeautifulSoup object, we can move on to collecting the data that we would like.
Pulling Text From a Web Page
For this project, we’ll collect artists’ names and the relevant links available on the website. You may want to collect different data, such as the artists’ nationality and dates. Whatever data you would like to collect, you need to find out how it is described by the DOM of the web page.
To do this, in your web browser, right-click — or CTRL + click on macOS — on the first artist’s name, Zabaglia, Niccola. Within the context menu that pops up, you should see a menu item similar to Inspect Element (Firefox) or Inspect (Chrome).
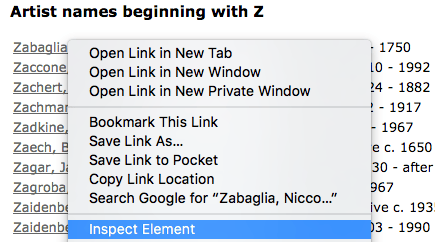
Once you click on the relevant Inspect menu item, the tools for web developers should appear within your browser. We want to look for the class and tags associated with the artists’ names in this list.
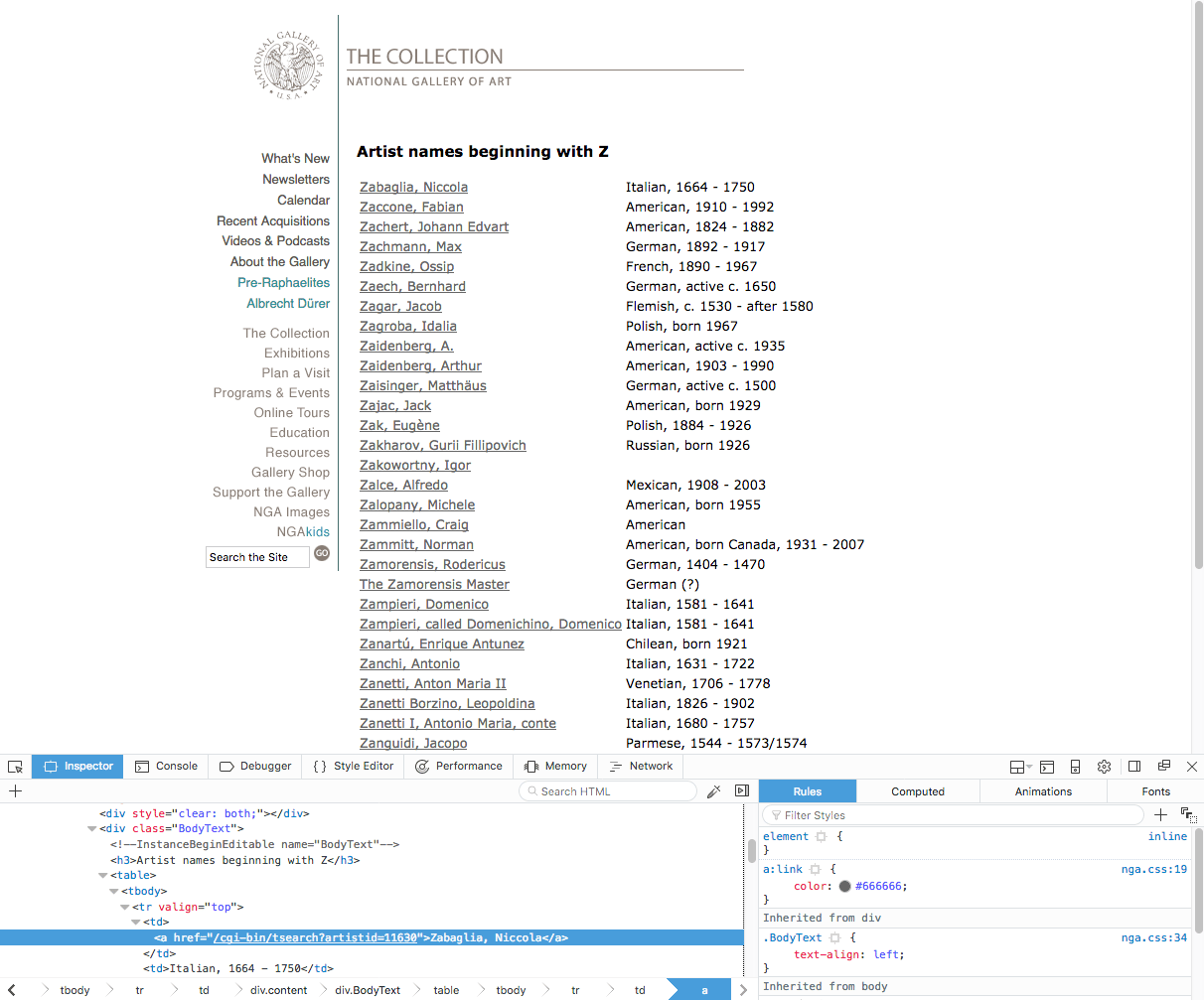
We’ll see first that the table of names is within <div> tags where class="BodyText". This is important to note so that we only search for text within this section of the web page. We also notice that the name Zabaglia, Niccola is in a link tag, since the name references a web page that describes the artist. So we will want to reference the <a> tag for links. Each artist’s name is a reference to a link.
To do this, we’ll use Beautiful Soup’s find() and find_all() methods in order to pull the text of the artists’ names from the BodyText <div>.
import requests
from bs4 import BeautifulSoup
# Collect and parse first page
page = requests.get('https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ1.htm')
soup = BeautifulSoup(page.text, 'html.parser')
# Pull all text from the BodyText div
artist_name_list = soup.find(class_='BodyText')
# Pull text from all instances of <a> tag within BodyText div
artist_name_list_items = artist_name_list.find_all('a')
Next, at the bottom of our program file, we will want to create a for loop in order to iterate over all the artist names that we just put into the artist_name_list_items variable.
We’ll print these names out with the prettify() method in order to turn the Beautiful Soup parse tree into a nicely formatted Unicode string.
...
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
# Create for loop to print out all artists' names
for artist_name in artist_name_list_items:
print(artist_name.prettify())
Let’s run the program as we have it so far:
- python nga_z_artists.py
Once we do so, we’ll receive the following output:
Output<a href="/web/20121007172955/https://www.nga.gov/cgi-bin/tsearch?artistid=11630">
Zabaglia, Niccola
</a>
...
<a href="/web/20121007172955/https://www.nga.gov/cgi-bin/tsearch?artistid=3427">
Zao Wou-Ki
</a>
<a href="/web/20121007172955/https://www.nga.gov/collection/anZ2.htm">
Zas-Zie
</a>
<a href="/web/20121007172955/https://www.nga.gov/collection/anZ3.htm">
Zie-Zor
</a>
<a href="/web/20121007172955/https://www.nga.gov/collection/anZ4.htm">
<strong>
next
<br/>
page
</strong>
</a>
What we see in the output at this point is the full text and tags related to all of the artists’ names within the <a> tags found in the <div class="BodyText"> tag on the first page, as well as some additional link text at the bottom. Since we don’t want this extra information, let’s work on removing this in the next section.
Removing Superfluous Data
So far, we have been able to collect all the link text data within one <div> section of our web page. However, we don’t want to have the bottom links that don’t reference artists’ names, so let’s work to remove that part.
In order to remove the bottom links of the page, let’s again right-click and Inspect the DOM. We’ll see that the links on the bottom of the <div class="BodyText"> section are contained in an HTML table: <table class="AlphaNav">:
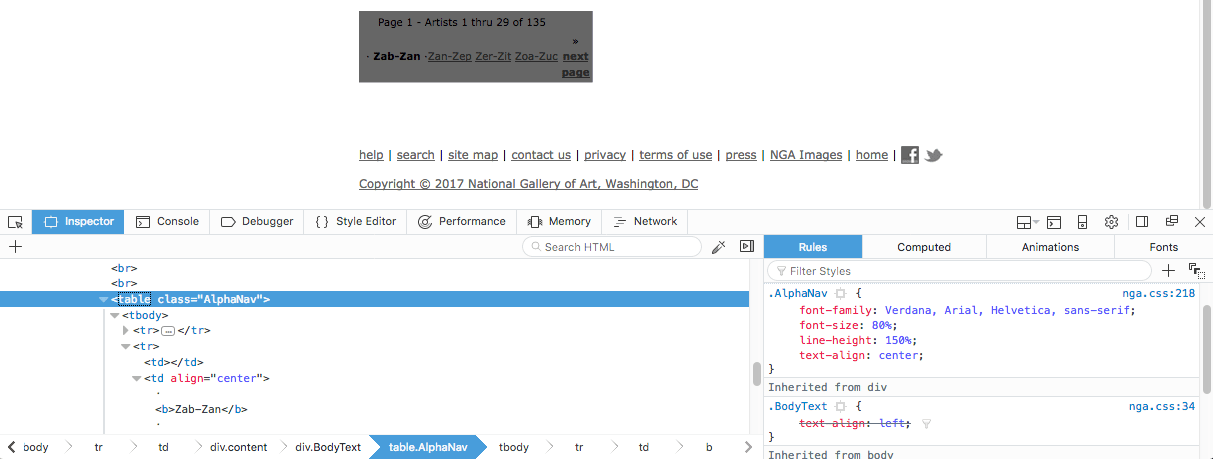
We can therefore use Beautiful Soup to find the AlphaNav class and use the decompose() method to remove a tag from the parse tree and then destroy it along with its contents.
We’ll use the variable last_links to reference these bottom links and add them to the program file:
import requests
from bs4 import BeautifulSoup
page = requests.get('https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ1.htm')
soup = BeautifulSoup(page.text, 'html.parser')
# Remove bottom links
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
for artist_name in artist_name_list_items:
print(artist_name.prettify())
Now, when we run the program with the python nga_z_artist.py command, we’ll receive the following output:
Output<a href="/web/20121007172955/https://www.nga.gov/cgi-bin/tsearch?artistid=11630">
Zabaglia, Niccola
</a>
<a href="/web/20121007172955/https://www.nga.gov/cgi-bin/tsearch?artistid=34202">
Zaccone, Fabian
</a>
...
<a href="/web/20121007172955/http://www.nga.gov/cgi-bin/tsearch?artistid=11631">
Zanotti, Giampietro
</a>
<a href="/web/20121007172955/http://www.nga.gov/cgi-bin/tsearch?artistid=3427">
Zao Wou-Ki
</a>
At this point, we see that the output no longer includes the links at the bottom of the web page, and now only displays the links associated with artists’ names.
Until now, we have targeted the links with the artists’ names specifically, but we have the extra tag data that we don’t really want. Let’s remove that in the next section.
Pulling the Contents from a Tag
In order to access only the actual artists’ names, we’ll want to target the contents of the <a> tags rather than print out the entire link tag.
We can do this with Beautiful Soup’s .contents, which will return the tag’s children as a Python list data type.
Let’s revise the for loop so that instead of printing the entire link and its tag, we’ll print the list of children (i.e. the artists’ full names):
import requests
from bs4 import BeautifulSoup
page = requests.get('https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ1.htm')
soup = BeautifulSoup(page.text, 'html.parser')
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
# Use .contents to pull out the <a> tag’s children
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
print(names)
Note that we are iterating over the list above by calling on the index number of each item.
We can run the program with the python command to view the following output:
OutputZabaglia, Niccola
Zaccone, Fabian
Zadkine, Ossip
...
Zanini-Viola, Giuseppe
Zanotti, Giampietro
Zao Wou-Ki
We have received back a list of all the artists’ names available on the first page of the letter Z.
However, what if we want to also capture the URLs associated with those artists? We can extract URLs found within a page’s <a> tags by using Beautiful Soup’s get('href') method.
From the output of the links above, we know that the entire URL is not being captured, so we will concatenate the link string with the front of the URL string (in this case https://web.archive.org/).
These lines we’ll also add to the for loop:
...
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
links = 'https://web.archive.org' + artist_name.get('href')
print(names)
print(links)
When we run the program above, we’ll receive both the artists’ names and the URLs to the links that tell us more about the artists:
OutputZabaglia, Niccola
https://web.archive.org/web/20121007172955/https://www.nga.gov/cgi-bin/tsearch?artistid=11630
Zaccone, Fabian
https://web.archive.org/web/20121007172955/https://www.nga.gov/cgi-bin/tsearch?artistid=34202
...
Zanotti, Giampietro
https://web.archive.org/web/20121007172955/https://www.nga.gov/cgi-bin/tsearch?artistid=11631
Zao Wou-Ki
https://web.archive.org/web/20121007172955/https://www.nga.gov/cgi-bin/tsearch?artistid=3427
Although we are now getting information from the website, it is currently just printing to our terminal window. Let’s instead capture this data so that we can use it elsewhere by writing it to a file.
Writing the Data to a CSV File
Collecting data that only lives in a terminal window is not very useful. Comma-separated values (CSV) files allow us to store tabular data in plain text, and is a common format for spreadsheets and databases. Before beginning with this section, you should familiarize yourself with how to handle plain text files in Python.
First, we need to import Python’s built-in csv module along with the other modules at the top of the Python programming file:
import csv
Next, we’ll create and open a file called z-artist-names.csv for us to write to (we’ll use the variable f for file here) by using the 'w' mode. We’ll also write the top row headings: Name and Link which we’ll pass to the writerow() method as a list:
f = csv.writer(open('z-artist-names.csv', 'w'))
f.writerow(['Name', 'Link'])
Finally, within our for loop, we’ll write each row with the artists’ names and their associated links:
f.writerow([names, links])
You can see the lines for each of these tasks in the file below:
import requests
import csv
from bs4 import BeautifulSoup
page = requests.get('https://web.archive.org/web/20121007172955/http://www.nga.gov/collection/anZ1.htm')
soup = BeautifulSoup(page.text, 'html.parser')
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
# Create a file to write to, add headers row
f = csv.writer(open('z-artist-names.csv', 'w'))
f.writerow(['Name', 'Link'])
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
links = 'https://web.archive.org' + artist_name.get('href')
# Add each artist’s name and associated link to a row
f.writerow([names, links])
When you run the program now with the python command, no output will be returned to your terminal window. Instead, a file will be created in the directory you are working in called z-artist-names.csv.
Depending on what you use to open it, it may look something like this:
Name,Link
"Zabaglia, Niccola",https://web.archive.org/web/20121007172955/http://www.nga.gov/cgi-bin/tsearch?artistid=11630
"Zaccone, Fabian",https://web.archive.org/web/20121007172955/http://www.nga.gov/cgi-bin/tsearch?artistid=34202
"Zadkine, Ossip",https://web.archive.org/web/20121007172955/http://www.nga.gov/cgi-bin/tsearch?artistid=3475w
...
Or, it may look more like a spreadsheet:
In either case, you can now use this file to work with the data in more meaningful ways since the information you have collected is now stored in your computer’s memory.
Retrieving Related Pages
We have created a program that will pull data from the first page of the list of artists whose last names start with the letter Z. However, there are 4 pages in total of these artists available on the website.
In order to collect all of these pages, we can perform more iterations with for loops. This will revise most of the code we have written so far, but will employ similar concepts.
To start, we’ll want to initialize a list to hold the pages:
pages = []
We will populate this initialized list with the following for loop:
for i in range(1, 5):
url = 'https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ' + str(i) + '.htm'
pages.append(url)
Earlier in this tutorial, we noted that we should pay attention to the total number of pages there are that contain artists’ names starting with the letter Z (or whatever letter we’re using). Since there are 4 pages for the letter Z, we constructed the for loop above with a range of 1 to 5 so that it will iterate through each of the 4 pages.
For this specific web site, the URLs begin with the string https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ and then are followed with a number for the page (which will be the integer i from the for loop that we convert to a string) and end with .htm. We will concatenate these strings together and then append the result to the pages list.
In addition to this loop, we’ll have a second loop that will go through each of the pages above. The code in this for loop will look similar to the code we have created so far, as it is doing the task we completed for the first page of the letter Z artists for each of the 4 pages total. Note that because we have put the original program into the second for loop, we now have the original loop as a nested for loop contained in it.
The two for loops will look like this:
pages = []
for i in range(1, 5):
url = 'https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ' + str(i) + '.htm'
pages.append(url)
for item in pages:
page = requests.get(item)
soup = BeautifulSoup(page.text, 'html.parser')
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
links = 'https://web.archive.org' + artist_name.get('href')
f.writerow([names, links])
In the code above, you should see that the first for loop is iterating over the pages and the second for loop is scraping data from each of those pages and then is adding the artists’ names and links line by line through each row of each page.
These two for loops come below the import statements, the CSV file creation and writer (with the line for writing the headers of the file), and the initialization of the pages variable (assigned to a list).
Within the greater context of the programming file, the complete code looks like this:
import requests
import csv
from bs4 import BeautifulSoup
f = csv.writer(open('z-artist-names.csv', 'w'))
f.writerow(['Name', 'Link'])
pages = []
for i in range(1, 5):
url = 'https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ' + str(i) + '.htm'
pages.append(url)
for item in pages:
page = requests.get(item)
soup = BeautifulSoup(page.text, 'html.parser')
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
links = 'https://web.archive.org' + artist_name.get('href')
f.writerow([names, links])
Since this program is doing a bit of work, it will take a little while to create the CSV file. Once it is done, the output will be complete, showing the artists’ names and their associated links from Zabaglia, Niccola to Zykmund, Václav.
Being Considerate
When scraping web pages, it is important to remain considerate of the servers you are grabbing information from.
Check to see if a site has terms of service or terms of use that pertains to web scraping. Also, check to see if a site has an API that allows you to grab data before scraping it yourself.
Be sure to not continuously hit servers to gather data. Once you have collected what you need from a site, run scripts that will go over the data locally rather than burden someone else’s servers.
Additionally, it is a good idea to scrape with a header that has your name and email so that a website can identify you and follow up if they have any questions. An example of a header you can use with the Python Requests library is as follows:
import requests
headers = {
'User-Agent': 'Your Name, example.com',
'From': 'email@example.com'
}
url = 'https://example.com'
page = requests.get(url, headers = headers)
Using headers with identifiable information ensures that the people who go over a server’s logs can reach out to you.
Conclusion
This tutorial went through using Python and Beautiful Soup to scrape data from a website. We stored the text that we gathered within a CSV file.
You can continue working on this project by collecting more data and making your CSV file more robust. For example, you may want to include the nationalities and years of each artist. You can also use what you have learned to scrape data from other websites.
To continue learning about pulling information from the web, read our tutorial “How To Crawl A Web Page with Scrapy and Python 3.”
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Community and Developer Education expert. Former Senior Manager, Community at DigitalOcean. Focused on topics including Ubuntu 22.04, Ubuntu 20.04, Python, Django, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Thanks for the tutorial! I’ve been using the requests and BeautifulSoup libraries for a little while, but always struggle matching the regex. Previously I hadn’t found much good documentation out there, and I always spend hours doing trial and error. This is pretty detailed and helpful. Thank you. I was able to populate this Python/Django website SeekingBeer using these libraries, but I spent forever messing around with the code.
The first part of the tutorial was fine - but then it falls apart. This is a very common problem - The author knows the material so well they forget we have never seen most of the topic or task. So just getting the Z names and printing them to the terminal and CSV files worked just fine.
When it came to adding all the pages and writing the code to the CSV files - I started getting the dreaded Unicode encoding errors. I have worked with beautiful soup before and I really liked how you started out.
File “nga_z_artists.py”, line 29, in <module> f.writerow([names, links]) UnicodeEncodeError: ‘ascii’ codec can’t encode character u’\xe4’ in position 16: ordinal not in range(128)
File “nga_z_artists.py”, line 3 f.writerow([names, links])nd associated link to a row’)m’) SyntaxError: invalid syntax
Thanks for this terrific tutorial, Lisa! The part about iterating over a series of result pages was especially helpful to me.
Hi Lisa,
The following commands aren’t working as I believe the layout of the page has changed. artist_name_list = soup.find(class_=‘BodyText’) artist_name_list_items = artist_name_list.find_all(‘a’)
Can you please update the code?
Although I appreciate this tutorial, since many others are bland or vague…I have found that even the beginning code doesn’t work for Python3.6.4…It sucks that BeautifulSoup changes so much you can never find reliable information…
A solution in 3 lines of code: http://buklijas.info/blog/2018/03/15/find-emails-on-web-page/
Hi, great tutorial. Unfortunately, I am running int an error… Although my sys.version says I am running Python 3.6.4, I am still getting codec errors. Yesterday it would save the .cvs up till the first name which had a special character in it. I deleted everything, reinstalled python, anaconda, sublime text 3, and now it just saves a blank .csv. Anything you would suggest? Here is a screenshot: https://imgur.com/a/ISz0tH8
Hi Lisa, Excellent tutorial! Your tutorial is clear and concise with minimal research on my part. I especially like how you add the code with each segment you lecture on so the student is left with working code that leads to error free “Output”.
Very helpful.
Thanks, Rick
I only signed up to leave this comment.
Thank you so much, very good, on-point tutorial. This is really one of the best sources on the internet on this topic and I believe it will be more than helpful to people like me who just started web scraping with python.
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
