
How Ghost migrated from dedicated servers to DigitalOcean
“Ghost(Pro) was migrated to DigitalOcean to enable on-demand scaling.”
Sebastian Gierlinger, Senior DevOps Engineer
Ghost, Senior DevOps Engineer
How Ghost migrated from dedicated servers to DigitalOcean
Introduction
This DigitalOcean Blueprint article was written by Sebastian Gierlinger, a Senior DevOps Engineer at Ghost. It covers the steps that were taken to migrate the Ghost(Pro) infrastructure from dedicated servers to DigitalOcean Droplets. In each step, Sebastian will discuss the challenges that were faced, how each challenge was solved, and why each solution was chosen. He’ll also provide links to relevant resources that he found to be helpful.
Ghost(Pro) is the hosted platform for Ghost, an open-source blogging platform, where users can rent pre-built Ghost blogs with a few clicks. Ghost(Pro) is what continuously funds the Nonprofit organization, the Ghost Foundation, that manages the Ghost open source project. Originally hosted on dedicated servers, Ghost(Pro) was migrated to DigitalOcean to enable on-demand scaling.
Problem statement
In the last quarter of 2014, Ghost(Pro) was quickly outgrowing its original, dedicated server infrastructure, as it was serving about 100 million requests from tens of thousands of blogs every month. Scaling the existing infrastructure would require about two months of lead time for purchasing and deploying new physical servers. In short, the limitations of scaling a dedicated server infrastructure were threatening the growth of the Ghost(Pro) platform and, as a result, the further development of the Ghost open source project.
We needed to resolve our inability to scale quickly, before it could have a negative impact on customers or our growth, by migrating to improved infrastructure.
Requirements
From our experience of running Ghost(Pro) for over a year, we had a good idea of what was needed to improve our service. We determined that our next infrastructure should meet these requirements:
- Ability to scale up server capacity within minutes
- Enough RAM to serve thousands of blogs
- Offer great customer support
- Allow us to migrate our software without a significant refactor
DigitalOcean satisfied all of these requirements.
During the planning of the migration, we determined that we needed to perform a zero-downtime migration. We’ll get into the technical reasons for this later.
Migration outline
Planning the migration of any project starts out with a certain level of uncertainty; it’s simply impossible to anticipate all of the required steps, let alone any issues that you’ll encounter. Our migration plan was formed through an iterative process of research and implementation.
Because this is a retrospective post, we were able to organize the migration process into these broad steps for easier understanding:
- Create an inventory of existing server infrastructure
- Secure public network
- Secure private network
- Replicate databases
- Update DNS (cutover exclusively to destination servers)
- Decommission old environment
Today, as a result of the migration, the Ghost(Pro) server topology looks like this:
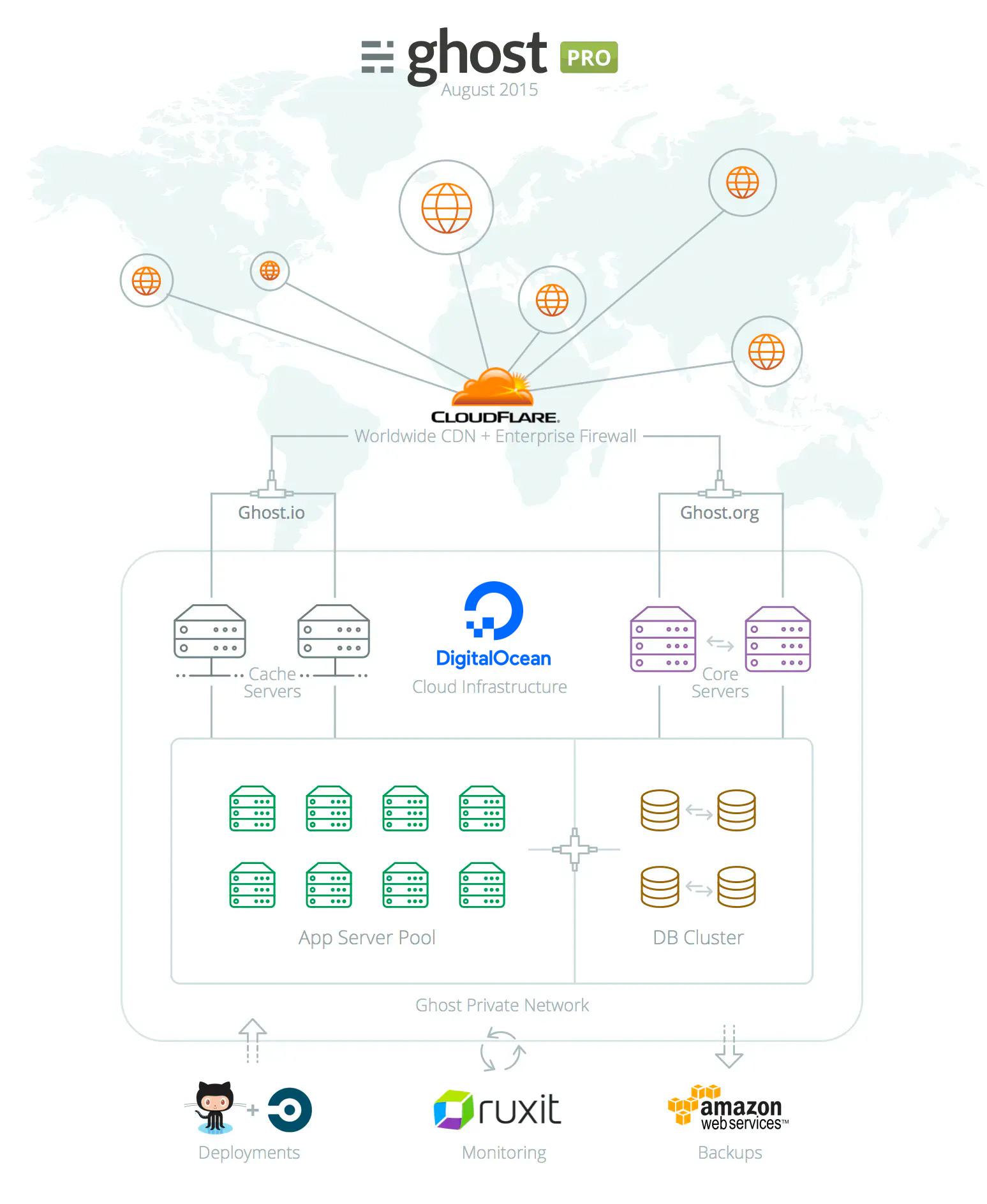
- Cloudflare provides a Content Delivery Network (CDN), Domain Name Services (DNS), caching and protection from malicious requests
- Core Servers host ghost.org and are responsible for user and payment management
- Cache Servers are used to further speed up responses and direct requests to the correct blogs
- App Server Pool consists of many App Servers which run our customer’s Ghost blogs
- DB Cluster is a cluster of MySQL databases that hold your blog data
- GitHub handles our source code management
- Ruxit is responsible for monitoring Ghost(Pro) infrastructure
- Amazon S3 is used to store encrypted, off-site backups
Let’s take a look the steps that got us to our new, scalable server infrastructure.
Step 1: Create inventory
The first step was to create an inventory of what was currently running on our existing dedicated server infrastructure using a configuration management tool.
Why?
When planning the migration of any service, it is important to have a way to reliably reproduce the existing environment. This will help ensure that the migration will go smoothly. Naturally, this requires that every server and software component is accounted for.
When Ghost(Pro) was first set up, shortcuts were taken to get it up and running quickly. We configured our original servers manually so, although the existing platform worked fine, we did not have every little configuration detail documented.
How?
To solve the issue of not having a complete inventory of our installed software packages, firewall settings, and other server configuration, we introduced a configuration management system to our toolkit. One of the benefits of configuration management is that, once the system is set up, it doubles as a documentation and deployment tool.
When it was time to choose a configuration management system, we considered several popular configuration management tools, including Puppet, Chef, Ansible, and SaltStack. We needed a tool that could get the job done and wasn’t overloaded with complexity. Ultimately, we chose SaltStack.
Here are some of the reasons that we decided on SaltStack:
- It’s lightweight, and easy to install and maintain
- It uses a master/minion management infrastructure, in which the Salt Master “pushes” changes to the Minions. This means there is reduced risk of the Master being DDOSed by hundreds of Minions trying to contact it when compared to an architecture where the Minions pull changes from the Master
- It has a dedicated master server. This prevents administrators and developers from deploying changes directly from unprotected dev machines
- It uses ZeroMQ, instead of SSH, for communications between the Master and Minions. ZeroMQ uses less processor power and is more efficient than SSH when it comes to handling many concurrent connections, while still providing encryption
As an added bonus, Salt Cloud, which is included with SaltStack, integrates closely with the - DigitalOcean API to scale our service by generating new droplets, and allows us to manage our infrastructure from the command line. It proved to be a really important tool for starting, stopping, and deploying servers, reliably, within minutes.
Result
Although the initial setup and deployment of the new Ghost(Pro) infrastructure took some time – about three weeks – SaltStack had already shown its power. The second iteration took about one week to deploy. The third installation of our hosted platform, which became our production systems today, took only two days.
Creating an inventory and moving to a configuration management tool was an iterative process that spanned almost the entire migration of our platform. In addition to making the migration possible, it also surfaced parts of our setup that needed improvement.
Resources
If you are looking to get started with SaltStack, check out the first tutorial in the DigitalOcean SaltStack series: An Introduction to SaltStack Terminology and Concepts. From there, you will find other tutorials that will help you use SaltStack in your own infrastructure.
If you are interested in learning about some of the other popular configuration management tools, here are some tutorials that can help you get started:
- How To Install Puppet
- How To Install and Configure Ansible
- How To Understand the Chef Configuration Environment
Step 2: Secure public network
The second step was to secure the public network of our platform’s internal servers with a firewall.
Why?
In our old environment, only our public-facing servers were available on the internet. All of our other servers, such as app and database servers, were only accessible via an internal private network. With the move to DigitalOcean’s cloud, where every server – even ones that don’t need to be accessed publicly – has a public IP address, we needed to solve this new security concern.
How?
We secured the public network of our internal servers by setting up an iptables firewall that blocks everything except SSH traffic. Since our servers are running Ubuntu, we used UFW as the interface to iptables.
As with the rest of the infrastructure, our firewall configuration is centrally managed with SaltStack. This allows us to easily manage the firewall across all of our servers, even ones that require special firewall rules.
Result
All non-public servers, which include the app and database servers (see topology diagram), have their access blocked off to the public. Aside from the private network, which we’ll discuss in a moment, all of our internal servers are only accessible over SSH with certificate-based authentication.
Resources
If you are looking to learn about the basics of firewalls, start with the What is a Firewall and How Does it Work? tutorial. It explains the basics of firewalls and links out to other tutorials that will help you set up a firewall to protect your public network interfaces using iptables, UFW, or FirewallD (CentOS).
Step 3: Secure private network
The third step was to secure the private network of all of our servers with a VPN.
Why?
DigitalOcean’s private networking feature allows Droplets within the same data center to communicate with each other without sending traffic out of the data center. While this feature is great because it enables high bandwidth and low latency connections within our infrastructure, the private network is shared amongst all Droplets in the data center, including those that belong to other DigitalOcean customers. That is, our private network is protected from general Internet connections but not necessarily from Droplets on the private network that don’t belong to us.
How?
We chose to secure the private network of all of our servers by setting up a Virtual Private Network (VPN). The encryption and authentication features offered by a VPN are perfectly suited to our needs.
We selected Tinc as our VPN solution primarily because it uses a mesh routing layout, which means that VPN traffic is sent directly to the destination host when possible. It also allows us to route traffic through connected Droplets to reach Droplets that are not directly attached to the requester. Unlike OpenVPN, which can complicate VPN management because it routes every connection through a central VPN server, our VPN behaves much like a traditional private network.
It also allows us to extend our VPN to Droplets in remote data centers if we ever decide that we need to span multiple data centers.
Like our firewall configuration, we use SaltStack to centrally manage our VPN configuration. This allows us to automatically update the Tinc VPN configuration amongst all of our servers, which ensures that our VPN membership is always accurate and up to date.
Result
All network traffic within our infrastructure is secure, as it goes through Tinc VPN on private network interfaces. Every Droplet runs a Tinc daemon, which is responsible for connecting (and reconnecting) to a given list of Droplets. As a result of using a mesh VPN, the configuration of the VPN connections between servers is very simple.
Resources
If you are looking to get started with Tinc as a VPN solution, check out the How To Install Tinc and Set Up a Basic VPN on Ubuntu 14.04 tutorial.
Step 4: Activate database replication
The fourth step was to migrate our databases by setting up replication.
Why?
Originally, we were planning on taking Ghost(Pro) offline during the database migration. This would allow us to quiesce – pause to ensure data consistency – and create backups of the MySQL databases. Then we could transfer the backups to our new database servers, and restore them to complete the database migration. However, after analyzing our existing data, we quickly realized that this process would not be viable. We had about 500 GB worth of databases, which meant that the migration would require an estimated 6 hours of downtime, not including any unanticipated errors. Taking our services offline for that long was simply unacceptable. We needed another solution.
We decided to turn to replication to migrate our MySQL databases. Database replication, which maintains identical copies of a database across multiple servers, provides a way to migrate a database without interrupting it. This eliminated the need for any downtime of our service and gave us the safety net of being able to test our new database servers before switching our old database servers off.
How?
Taking advantage of replication to migrate our databases required some additional planning. While we can’t include all of the details, for brevity’s sake, here is the sequence of the notable steps that we went through.
1. Configure master/slave replication
We configured the original database server to be the master, and the new database server to be the slave. This meant that the data was replicated in one direction, from the original database system to the database system in the new infrastructure.
2. Test new infrastructure
Using this master/slave setup, we were able to do load testing and see if our new Ghost(Pro) system behaved equivalently to our old setup. Note that, due to the nature of the setup, the changes made to the slave database during our tests did not affect the original (master) database.
After our tests were successful, we wiped out the data in the new (slave) database servers to prepare for the next step.
3. Configure master/master replication
With the new database servers tested, we activated master/master replication which meant that all database changes were being replicated in both directions.
Result
Once master/master replication was activated, and the original database was migrated to our new servers, the new infrastructure was ready for use. We had two completely functional instances of the Ghost(Pro) infrastructure, old and new, with synchronized databases. However, the new infrastructure was not yet active because the ghost.org and ghost.io DNS records – how our users access our services – were still pointing at the old infrastructure.
This meant that the migration of our service was now reduced to switching the DNS entries to point to the new servers. As an added benefit of using master/master database replication, our setup would allow us quickly and easily revert back to our old infrastructure if we ran into any issues.
Resources
To learn about setting up database replication in your own environment, check out these tutorials:
Step 5: Update DNS records
The fifth step was to put our new infrastructure into production by updating our DNS records.
Why?
To put our new infrastructure into production, all we needed to do was update our DNS records for our publicly-facing cache and core servers, ghost.io, and ghost.org respectively.
How?
Updating DNS records is sometimes problematic because of the time it takes for DNS changes to propagate. If done improperly, the propagation could take hours and users could be sent to the old and the new system. We use CloudFlare to manage our DNS entries, which allows us to make DNS changes in real-time, so we were able to avoid those issues.
When we were ready to start using our system, we performed the following sequence. First, we updated ghost.org to point to the new core servers then tested that it worked. Next, we updated ghost.io to point to new cache servers then ran more tests.
Result
After updating our DNS records to point to the new cache and core servers, our new infrastructure was live; all of our users were accessing our Ghost(Pro) service from our new infrastructure on DigitalOcean, the same set of servers that is presently in production.
We still had the ability to revert our DNS changes to switch back to the original infrastructure if we encountered any problems. This would only take a few seconds because the production database was still available to both infrastructures, because master/master replication was still active, and DNS propagation with Cloudflare occurs almost instantly. Fortunately, this was not necessary because the migration to new servers went through without a hitch.
Resources
As we discussed, we use Cloudflare to control our service’s domain records. In addition to their DNS services, we also pay for their Application Firewall, CDN, and DDOS protection. They also provide a basic service, with fewer features, for free. To use CloudFlare to manage your domain, follow the Configure Your Domain to Use Cloudflare section of this tutorial.
Alternatively, DigitalOcean also provides name servers that you can point your domain to. However, the DigitalOcean DNS might not be the ideal solution for quick DNS propagation for a migration project because the TTL (time to live) value is not configurable. Check out how to set that up by following this tutorial: How To Point to DigitalOcean Nameservers.
If you’re looking for a primer on DNS concepts, the Introduction to DNS Terminology, Components, and Concepts tutorial is a great way to get caught up.
Step 6: Decommission old environment
The last step was to retire the servers in our old environment.
Why?
With our service running completely on our new DigitalOcean setup, we no longer had a need for our original dedicated server infrastructure. Decommissioning our old environment would save us in operational and legacy management costs.
How?
Before powering off our old infrastructure, we needed to switch off replication between our old and new database servers.
Result
With database replication no longer active between our two environments, our active Ghost(Pro) setup no longer had any ties to the old infrastructure. Once we powered off our old servers, our migration was complete!
Conclusion
Migrating the Ghost(Pro) platform from dedicated servers to DigitalOcean was a success!
We wanted to share our experience because we know that migrating server environments is a challenging task that many projects face. We hope that the details of how we migrated to DigitalOcean will be a helpful resource to other projects that are looking to do a migration of their own.
More stories

Read how DigitalOcean and NVIDIA help Hippocratic AI create safe, compliant AI agents for healthcare appointment management and close care gaps.

Traversal uses DigitalOcean’s AI and GPU infrastructure to power advanced root cause analysis, helping enterprises understand complex system issues.
From launch spikes to daily play, Double Eleven trusts DigitalOcean Droplets to keep Rust online.
Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
