
Scaling to billions on top of DigitalOcean
“Scaling to billions on top of DigitalOcean”
Den Golotyuk, Engineer
.io, Engineer
Scaling to billions on top of DigitalOcean
Who we are
We are a young team of 15 people. We are building a tool to detect critical changes in business indicators’ behavior. The key feature of our system is that all data are collected in the unsampled form and all metrics are checked for deviations in real time to automatically notify the client on important changes.
Technologically speaking — it’s all about big numbers even for small projects. We process 20 billion events a day. Data should be collected from many sources and be constantly checked for anomalies. A single client event can lead to a dozen other events being stored and processed (e.g. different slices and intersections of a certain metric).
We’d like to share our experience on scaling our app to 700 million requests per day in just 6 months on top of DigitalOcean infrastructure.
Our figures
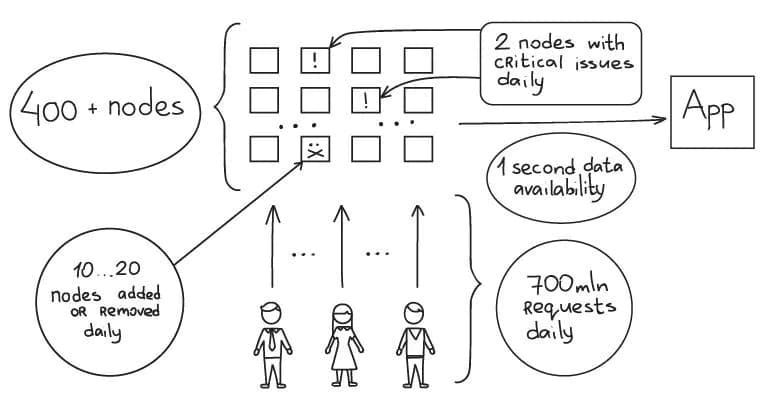
- 400+ nodes
- From 0 to 700 million requests a day in 6 months
- 20 billion events collected daily
- 10 - 20 nodes are added or removed every day
- 2 nodes experience critical issues every day
- Technologies: Nginx, Nodejs, Python, PHP, R, Mysql, Redis, Memcache
Why cloud
Our project is still young but is growing very quickly. From the start we needed a special platform that would ensure that architecture wouldn’t hold us back later. Everything had to be done quickly with lots of trials and modifications. Dedicated servers were out of the question as they are too slow and complicated.
We knew that we would face scalability issues very soon, so we decided to build a growth-focused system from the start. What it meant for us:
- No powerful server configurations. We use techniques like database sharding even for micro-nodes.
- All nodes should have at least one backup. If one goes down, the other is still up.
- We should be able to add nodes very fast. Sometimes every minute counts.
The architecture of dedicated servers does not differ much from cloud systems when it comes to scaling. They both include multiple nodes, redundancy, automatic failover, sharding, and balancing. But relying on high-performance hardware from the start of the project will surely become a problem later. Many system components will need to be radically changed. Utilizing small nodes for the same components right from the start helps to create a scalable architecture. It might be a more complicated way, but it’s definitely much faster.
Our expenses could be reduced by 30% if we were to switch to powerful dedicated servers. But in this case, we would have to pay for hardware failures and hire a system administrator (yes, we do not have one right now!) to deal with all this stuff.
Why DigitalOcean
Amazon Web Services is a popular solution for startups. Not just for cloud nodes, but for the entire infrastructure. However, we had some specific requirements:
- A simple system with a simple API. Amazon is anything but simple.
- Smallest configurations at the lowest costs. We would have to pay almost 3 times more to Amazon for the same configurations.
- Simple billing. Go ahead and try to figure out how much Amazon S3 will cost before using it!
We still use some Amazon services (for example, Route 53), but 95% of our system works with DigitalOcean nodes.
So here comes DigitalOcean.
Challenges
As the project is growing fast, we are facing several challenges that we’d like to share with DigitalOcean readers.
Configuration
The core of our system is based on small 1GB x 1-core nodes. Yet we put a lot of thought into choosing an appropriate configuration from the get-go. For a while, we were creating all our nodes using the smallest 0.5GB x 1-core plan. However, the issue was that the bulk of resources were utilized by the operating system and almost nothing was left for such demanding services as MySQL.
Currently, we have settled on using the following configurations:
- Frontends — 2GB x 2-core
- Data storages — 1GB x 1-core
- AI nodes (r and python – anomaly detection subsystem) — 2GB x 2-core
Swap
All DigitalOcean nodes have SWAP disabled. It’s very convenient as it ensures that services are working with the highest performance. However, on the second month of growth (when we had a few dozen nodes) we experienced constant problems as some processes were killed by the system. Sometimes it was MySQL:

As we began enabling SWAP, we soon burned our fingers — some nodes started performing 10 times slower. Finally, we disabled SWAP for almost all nodes and decided to scale horizontally. Now the number of nodes is steadily increasing and SWAP is enabled only for a few of them.

SWAP is used only for servers with secondary functions, which do not create any visible application performance issues for users. For example, full-text search nodes can get into SWAP during text re-indexing process, which slows down operation, but is not critical to users.
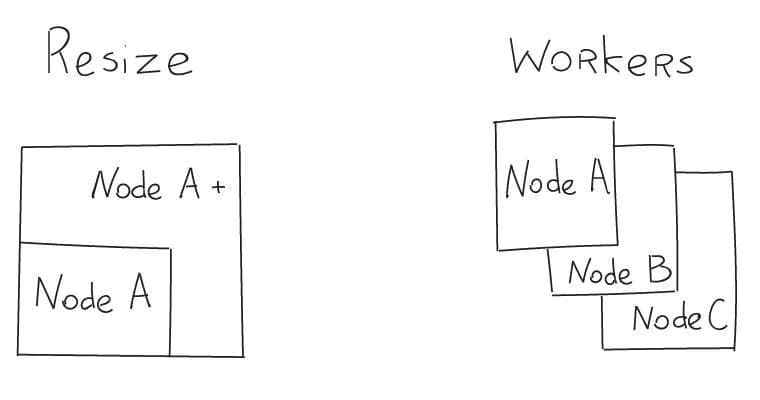
Resize
Resize is a powerful and cool feature. But you should be careful with it. Every time you resize a node, the growth problem is just postponed. Changing server performance only solves today’s problem. A scalable solution can only be created by adding new nodes and distributing the load between them. Resize is more of an exception, but sometimes can act as an emergency measure.
Communication between nodes
Communication between nodes remains our greatest challenge. Needless to say, Private Networking should be used for communication.
Some of our nodes are located in different data centers and communicate over the Internet. Traffic restrictions and security requirements dictate that we use SSL and GZIP data compression for efficiency.
Many-to-one requests
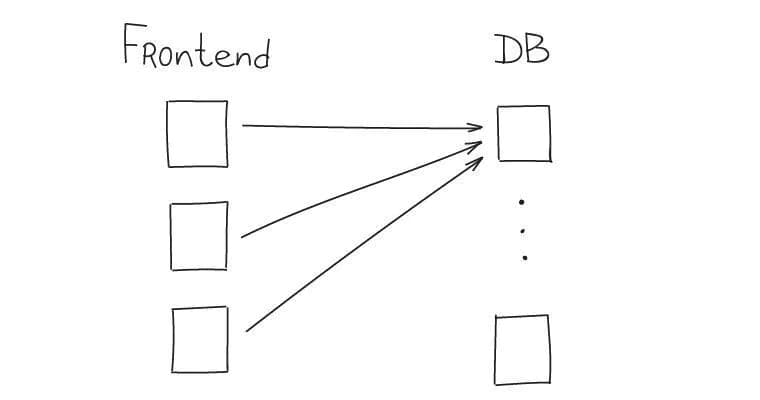
Small nodes based architecture poses another problem when several nodes send requests to a single node. During growth the number of sending nodes is constantly increasing, so is the load on the receiving node.
Currently, we use this solution for frontends and databases. We use Consistent Hashing to determine data nodes, so we’ve got high load peaks on some DBs:
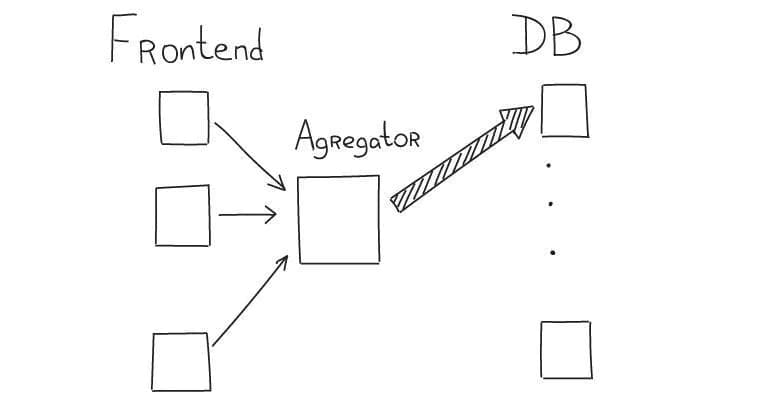
We solved this by creating intermediate nodes with a simple function of aggregating and proxying requests. This reduces the load on databases nodes:
Failover
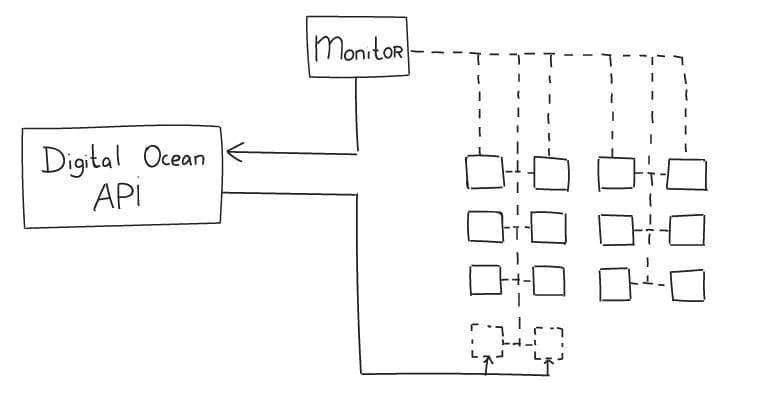
And here comes the awesome DigitalOcean API. We use the following approach for all our nodes:
- Constant availability and load monitoring with our own script and collected.
- In the event of a failure, the node is automatically removed from the worker’s pool.
- If a high-load peak happens, new nodes are created via DigitalOcean API and are added to the worker’s pool.
Security
Each DigitalOcean node has an external IP address and is available via internet. To ensure communication security between different nodes and clients we use SSL only. Additionally, service access is limited at the hardware level; connections are accepted only from IP addresses in the white list.

Shared resources
At first, we were afraid that node performance would be very difficult to predict, as it is impossible to predict their shared physical environment load. We track Stolen CPU indicator:
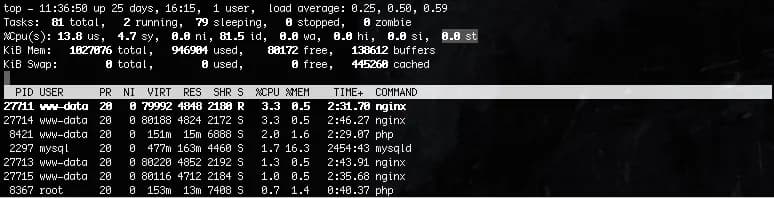
And almost always it has acceptable values with rare peaks.
Underlying physics
DigitalOcean proved to be really good for this issue. Only 1% of our nodes experienced rebooting from the very start.
Nevertheless, you should be prepared for node rebooting. In any case it’s an absolute requirement if you’re creating a stable system.
Bottom line
In spite of the opinion that cloud services are only suitable for small projects and startups, we decided to launch our service using DigitalOcean. At the moment we are satisfied with the selected approach, since it allows for quick responses to load growth, even within a two-fold increase over a few hours.
Drop us a line, we’ll be happy to hear your comments and share our experience.
More stories

Read how DigitalOcean and NVIDIA help Hippocratic AI create safe, compliant AI agents for healthcare appointment management and close care gaps.

Traversal uses DigitalOcean’s AI and GPU infrastructure to power advanced root cause analysis, helping enterprises understand complex system issues.
From launch spikes to daily play, Double Eleven trusts DigitalOcean Droplets to keep Rust online.
Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
