
Building a 120TB-daily data pipeline on DigitalOcean
“With DigitalOcean, we have been able to make scaling the technical infrastructure of our business cost effective and efficient.”
Rick O'Toole, Cofounder and CTO
Rockerbox, Cofounder and CTO
Building a 120TB-daily data pipeline on DigitalOcean
Who we are
Rockerbox is an advertising and analytics company specializing in understanding user behavior. Our product depends on understanding the current behavior of our advertiser’s audience and using this information to model and find similar users.
We aim to be efficient
Efficiency is part of our DNA at Rockerbox. Our goal is to make the advertising and marketing efforts of our customers more efficient and effective.
Efficiency doesn’t stop at the service we provide our customers. It is also embedded in the technology we build and the processes we design. We have designed a system with the capacity to process up to 120TB of data on a peak day. Using other web services and cloud providers, we could easily throw away a lot of money just trying to hit response time mandates set by our partners.
With DigitalOcean, we are able to operate with a cost structure that is roughly 20% of what other independent cloud providers were charging us when things like bandwidth overage charges were tacked on. DigitalOcean’s simple pricing has made it easy for us to embrace scale without worry about minimums, discounts, and penalties.
Our technical breakdown
Data collection is at the core of our platform. To collect this data, we need a constant presence on the internet that is dependable, redundant, and scalable.
We also need to be able to process, store, and retrieve this information for use internally by our media traders and externally as part of our analytics platform. Based on these requirements, we need to strike a balance between three different variables:
- Network efficiency
- Processing power
- Long-term storage
To balance these three requirements while maintaining cost efficiency on DigitalOcean, we split Droplets based on whether they need to be network efficient or CPU efficient.
Data collection
To collect data, we deploy a plethora of boxes with static IP addresses which act as our primary interface to ad exchanges, third-party data sources, and on-page pixels. With DigitalOcean, we are able to easily provision these static boxes without paying more for the right to reserve the IP address.
Different data sources have different requirements as related to network efficiency. We have 3 different types of statically deployed network boxes:
- Data providers: 50 (2 core Droplet) VMs designed to respond in <10 ms to a fixed host. These boxes operate as the Rockerbox “data provider” on ad exchanges and provide information about what we want to buy and the price we are willing to pay.
- Bidders: 25 (1-2 core Droplet) VMs in < 200 ms designed to respond to an ad exchange. These boxes operate as our “bidder” on ad exchanges and execute logic related to information received from our data provider.
- Analytics: 25 (1-2 core Droplet) VMs to interface with the entire internet in under 500 ms. These boxes operate as mini web servers that help track information about users, such as when they were served an ad and when they convert for a product.
Mesos cluster for data processing
To maximize processing power and long-term storage, we also run a cluster of boxes where dynamic, changing workloads can be processed. Our statically deployed network boxes pass the data they collect to our cluster, where we prepare, process, and model our data.
For this, we wanted the flexibility to write diverse applications that operate within a set amount of infrastructure while having the flexibility to pull more resources for distributed jobs.
Specifically, we run a Mesos Cluster with a Hadoop-distributed file system (HDFS) on top of DigitalOcean. This cluster consists of 50+ (8 core Droplets) VMs and is optimized for disk space, CPU, and memory. These boxes handle our data pipeline, model generation, databases, and end-user applications.
Mesos gives us the flexibility to run:
- Long-running services are written in Java (like Kafka and custom stream processing applications).
- Short running Python applications wrapped in Docker containers (like synchronization scripts and front-end micro frameworks).
- Spark jobs for building models.
- Auto deploys of branches while evaluating testing and merging.
By using Mesos, we have a few advantages:
- We are able to design applications with the mindset that they will span multiple physical machines.
- We are able to reduce the cost of running very large applications by spreading them out over more devices.
- We can automatically monitor, restart, and scale applications from a central interface.
- We build with a true microservice architecture in mind that doesn’t depend on specific tooling designed around certain frameworks.
Below is an example of how data is received by our network optimized boxes, passed to our data processing applications within the Mesos cluster, and ultimately written to a data store that end users have access to:
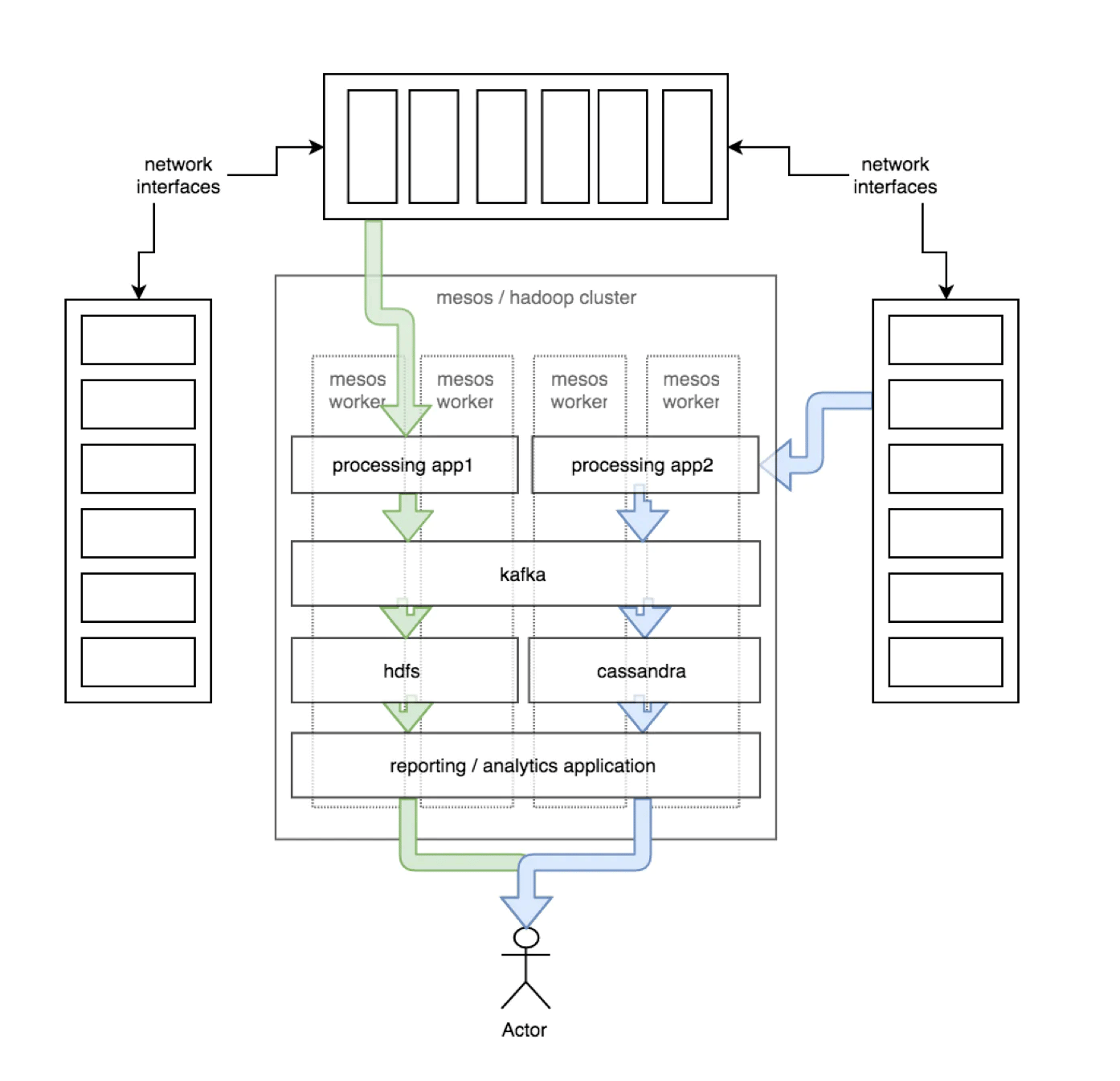
To support the platform we described above, we run approximately 200 Droplets on DigitalOcean.
Long-term storage
Looking back at historical data to analyze and test models is an important capability of our infrastructure and tech stack. To enable cost-effective long-term storage, we synchronize a majority of our log-level data stored in HDFS to DigitalOcean’s Object Storage product, Spaces. We use the DigitalOcean Spaces NYC3 region, which is located in the same city as the majority of our Droplets.
When we want to retrieve information stored on Spaces, we simply mount an external HDFS table using the standard Apache Hadoop connector for S3 that points to our Space and execute HQL queries against this data source. These types of queries require a strong match between the partitioning schema we originally used when writing our logs to match our access pattern. This is rare since most data is partitioned based on time, but it allows us access when debugging and also allows us to integrate directly with our “active” data sources. There is no cost to upload data to Spaces, and no cost for bandwidth between a Spaces region and Droplets in the same region, so this setup does not add bandwidth costs.
In closing
At peak, we are processing over 200k requests per second. This translates to a data pipeline that is capable of processing over 3B requests per day. While other companies have huge fleets of servers to run this type of infrastructure, we’re able to accomplish this with 200+ VMs. With DigitalOcean, we have been able to make scaling the technical infrastructure of our business cost-effective and efficient.
More stories

Read how DigitalOcean and NVIDIA help Hippocratic AI create safe, compliant AI agents for healthcare appointment management and close care gaps.

Traversal uses DigitalOcean’s AI and GPU infrastructure to power advanced root cause analysis, helping enterprises understand complex system issues.
From launch spikes to daily play, Double Eleven trusts DigitalOcean Droplets to keep Rust online.
Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
