AI/ML Technical Content Strategist

Earlier this month during their I/O conference, Google unveiled several releases that are making great waves in the AI community. Namely, Gemini Diffusion, Imagen 4, and Veo 3 all offer revolutionary advances in their respective fields. These closed-source models from Google DeepMind showcase the true potential of AI development for creative endeavors going forward. In particular, Veo 3 seems to have unlimited potential for the entertainment industry with its impressive versatility and quality.
In this article, we are going to discuss Veo 3 in detail, including our thoughts on how it works, a showcase of videos we generated with the model, and a discussion of how it compares with closed source alternatives like Wan2.1 and HunyuanVideo. Follow along, and learn about whether Veo 3 is a viable addition to your creative workflow for video creation!
What is Veo 3?
Per the Veo 3 model card, “Veo 3 is a video generation system capable of synthesizing high-quality, high-resolution video with audio from a text prompt or input image”. Furthermore, we know that Veo 3 utilizes a latent diffusion based architecture in order to operate. This makes sense, as latent diffusion is considered the SOTA technique for getting the highest quality performance in generative media applications. We can infer that, like other latent diffusion models, the diffusion process is applied to the temporal audio latents and the spatio-temporal video latent representations of the original data. With closed-sourced advances in latent diffusion development from Google, they have likelu figured out how to evenly apply this process across each modality to achieve the high quality results. For more information about how diffusion models work, check out our original writeup on Stable Diffusion!
We also know that the Veo 3 models were trained on significant amounts of audio, text, and visual data. This data was all correspondingly labeled and annotated by various Google Gemini models to achieve high quality, consistent annotation levels across all data types. We can assume that the video data comes from various sources, including YouTube. This is what truly allows Google to surpass all competition here: they have some of the best resource access in the world for video data.
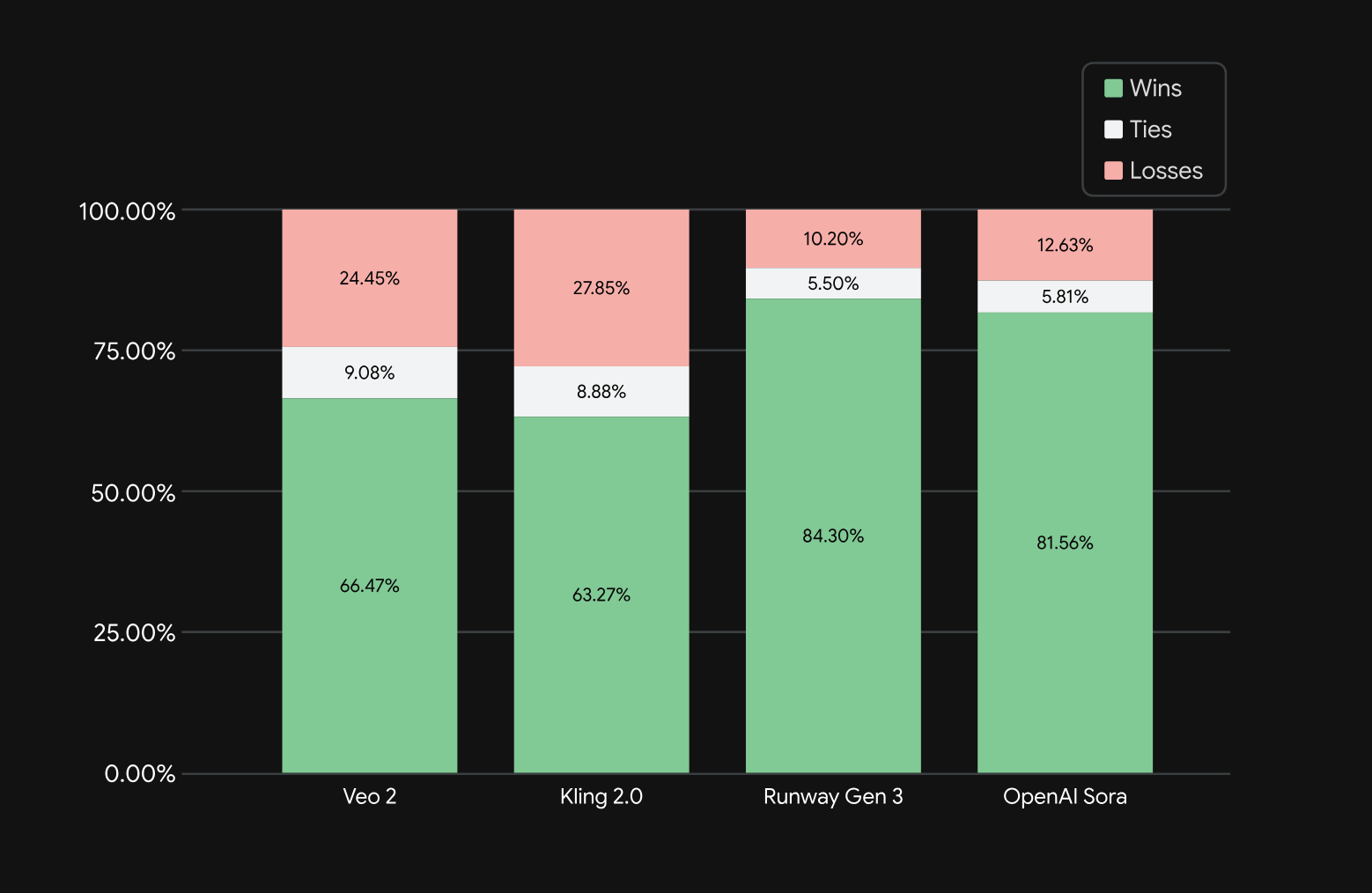
Putting all this information together, Veo 3 is likely a system of diffusion based models that are designed to make connective visual and audio that matches the other generation perfectly. Thanks to their access to huge amounts of video data & unknown innovations in latent diffusion technology, Veo 3 seems to surpass all competition in preferential competitions. See the table above, where Veo 3 is shown to be more popular than all other SOTA models as measured by participants tested on Meta’s MovieGenBench.
Using Veo 3
To get started with Veo 3, you can use the new Flow application from Google. Login to your Google account, and sign up for a Google AI subscription as needed to access Flow. Flow lets you generate videos from text prompts or still image inputs on Veo 3 and Veo 2. Veo 3 generations are more costly, with only ten being made available per month on the Pro subscription, while 100 Veo 2 generations can be generated using the same credit quota.
Veo 3 Video Showcase
Now let’s look at some videos we generated with Veo 3! We tried to get as much variety in terms of subject matter, input methodology, and style as possible in these five videos.
The prompt for this video was “3d CGI footage of third-person viewpoint magic-based video game. The player character runs through a misty forest while casting magic spells at goblin and hobgoblin enemies. An hud shows health and mana in the lower left corner while a minimap is spread across the top of the screen going towards an objective. Low volume orchestral music a la Dark Souls plays in the background”
In this first scene, we can see a detailed 3d video game scene. In it, a character runs across a misty forest while fighting monsters with a magical staff. Clear animations for running and attacking are shown. There are distinct elements for video games, like a HUD, health bar, and minimap, that change throughout the video. Also notable is the clear audio for each action and motion, with thematically appropriate background music. This shows incredibly prompt adherence, understanding of a unique style like video game animation, and the capability to correspondingly generate aesthetically accurate audio.
For this next video, we sought to go for a photorealistic style on a surreal subject. For this, we used the following prompt: “A unique alien mammal with three round eyes arranged in a triangular pattern, six jointed legs covered in iridescent blue fur, and a long prehensile tail wraps itself around a thick brown tree branch. The creature’s elongated body features a combination of reptilian and mammalian characteristics, with smooth grey skin visible beneath patches of the blue fur. Dense forest foliage surrounds the branch, creating a natural backdrop with filtered sunlight highlighting the creature’s features. Professional wildlife photography with sharp focus and natural lighting in ultra high definition 4K resolution.”
As we can see from the video, there is impressive prompt adherence, image quality, and appropriate sound generation for both the subject and background. The unique creature has elements shared by the animals described in the prompt while being utterly alien in it’s design. Despite that, it appears completely realistic albeit posed awkwardly. The sound design works perfectly to show the creature is in the wild somewhere, as intended.
Next, we wanted to see how the image to video capabilities performed. To do this, we generated a still image of a pair of people in a tea shop. We then tasked the Veo 3 model with animating the photorealistic scene using the following prompt: “A photorealistic scene inside a Chinese tea shop shows a woman and a man sitting across from each other at a wooden table, their white ceramic teacups touching in a toasting gesture. The table holds a traditional Chinese teapot, matching saucers, and small plates. The shop’s interior features red paper lanterns hanging from the ceiling, dark wooden wall panels with carved designs, and shelves displaying various tea canisters and ceramic items. Natural light filters through a front window, illuminating steam rising from the teacups. Film-style photography with shallow depth of field and warm natural lighting creates focus on subjects against softly blurred background elements.”
We were very impressed with the results of this generation. First, the quality of the video is very impressive, with zero artifacts. The length of the video does create some behavioral repetition in the video, but that could easily be remedied with editing. Second, the audio is perfectly accurate to the prompt. We especially like the sounds of the tea cups clinking on time perfectly to the video. Overall, we believe that the model excels at photorealistic scenes like this one.
Next, we used an image that had a unique art style and text writing to push the capabilities of the model for image to video. We combined the original input image, generated with a similar prompt to the video on Imagen 4, with the following prompt: “A propaganda video features a detailed scene of a cosmonaut in a white spacesuit reaching out to shake hands shaking hands with a translucent, gelatinous alien, blob creature against the backdrop of an alien landscape. The alien planet’s surface is covered with bright pink plant formations, crystalline rock structures, and purple grass, set against an orange-tinted sky containing three distinct suns. A futuristic city with flying cars lies in the distance. The scene is rendered in Norman Rockwell’s signature realistic style, with careful attention to the reflective surfaces of the spacesuit and the translucent quality of the alien creature. A bold text banner frames the bottom of the image, spelling out “Make new friends! Come to Rigel-4!” in block letters. The entire poster is contained within a thick decorative border.”
As we can see from above, the video accurately captures the prompt with some strange quirks. While the audio is all matching to the effects, movements, and actions depicted in the video, the characters move stiffly and, literally, backwards. Perhaps this is for similar reasons to the methodology used by FramePack? Nonetheless, the video is likely the least “accurate” to the original prompt of any created video for this article.
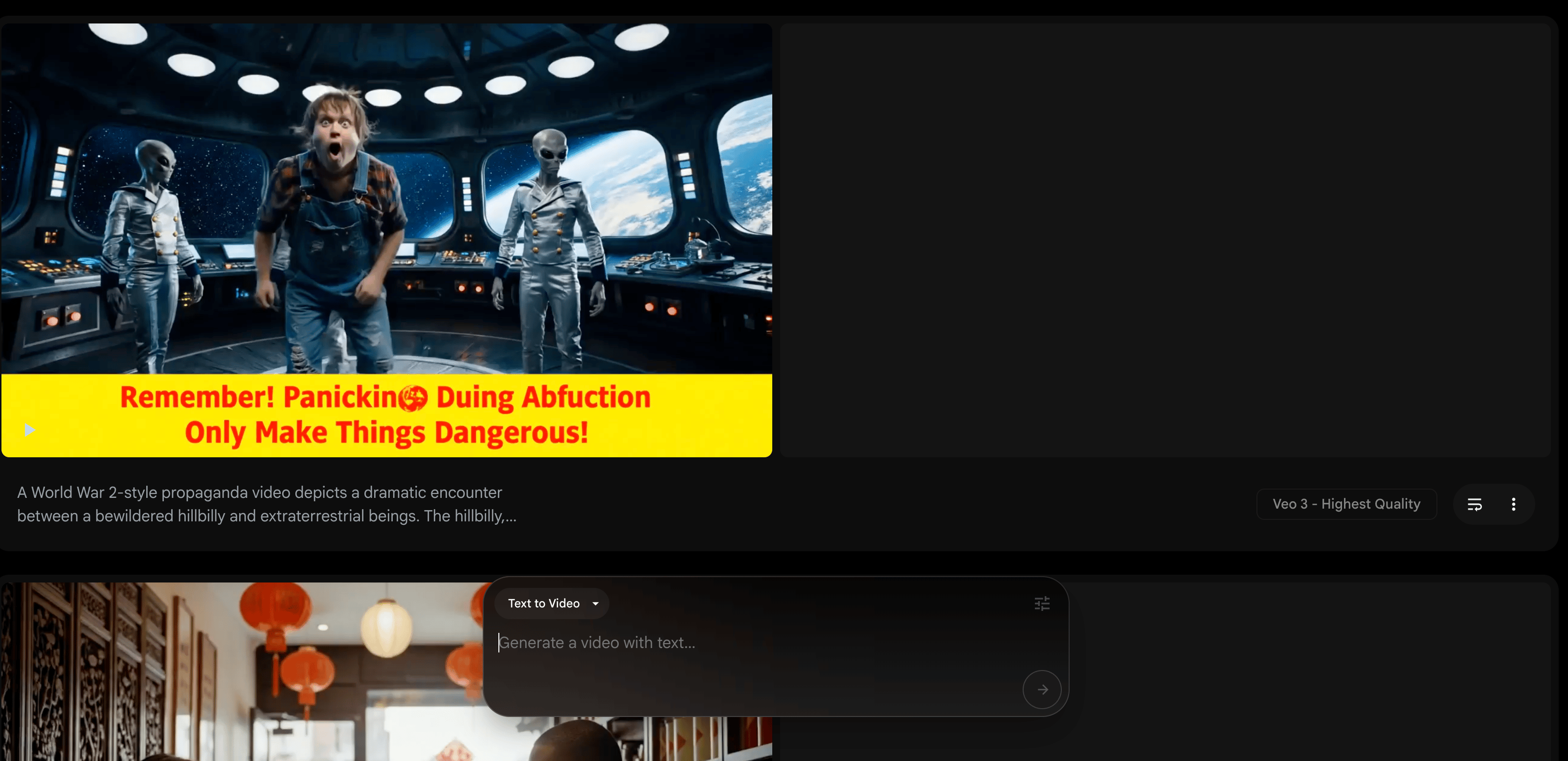
For the final video in the showcase, we wanted to again push the limits of the model by asking it to generate a complex video with written text. We did this with the following prompt: “A World War 2-style propaganda video depicts a dramatic encounter between a bewildered hillbilly and extraterrestrial beings. The hillbilly, wearing denim overalls with a ripped flannel shirt underneath, stands with mouth agape and eyes wide in an expression of shock. Three grey aliens in metallic silver naval uniforms with polished brass buttons stand before him on the curved metallic floor of a UFO’s command deck. The bridge features glowing control panels with blinking lights and a large circular window showing stars and Earth visible in space. Block text at the bottom of the poster reads “Remember! Panicking During Abduction May Only Make Things Dangerous!” in bold red letters against a yellow banner. The scene is rendered in brilliant detail, intricate details 4k footage hd high definition”
As we can see from the video above, the model performed admirably at the task but falls short on several counts. First, the audio is essentially silent. The model has no idea how to fill the background noises of a strange environment, like a spaceship, without obvious prompting from the user. Second, the text is obviously poorly rendered and even misspelled. While the model tried, this seems like it is not fully ready for production use when writing is involved. Fortunately, the video ended up having very high prompt adherence, strong graphical fidelity, and fairly comical, and we thought it a fitting example of the limitations and strengths of the model shown in a single video.
Comparison with Open-Source Video tools
In short, there is no real competition from open-source models that comes close to the capabilities of Veo 3 when it comes to pure video generation. Not only is Veo 3 the only model that can produce the concurrent audio that makes the videos so valuable, but Veo 3 is a clear step above in graphical quality and prompt adherence, as well. We recommend Veo 3 for any project that requires video generation tasks.
That being said, there are still a plethora of situations where Wan or HunyuanVideo are actually much better. For example, the release of VACE makes Wan extremely customizable in ways that closed-source competition has not yet made available. In general, the level of control a user can achieve over generations on closed-source video models like Veo 3 is just lower than what is possible with Wan and ComfyUI in a custom workflow. We recommend exploring both options to see what best fits your use case.
Closing Thoughts
Veo 3 is the most powerful video generation model yet. The integration with the audio generation model alone elevates it far above the competition. We have been very impressed with our experimentation with the model so far, and encourage all of you to test it out!
For Video generation tips with open-source tools on DigitalOcean, check out our tutorials on Wan and HunyuanVideo for more information!
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
