
Introduction
What’s interesting about ServiceNow’s new multimodal reasoning model, Apriel-1.5-15B-Thinker, is its emphasis on midtraining over post-training and Reinforcement Learning (RL)). Note that a type of post-training, supervised fine tuning (SFT), is still employed, albeit just for textual data consisting of reasoning traces and not for image data.
The model is 15 billion parameters, open weight, multimodal, and deployable on a single GPU. To put this into context, this is less than gpt-oss, an open-weight multimodal reasoning model from OpenAI, which has variants with 20B and 120B parameters, making this a more memory-efficient model to deploy. In spite of its small parameter count, the model is highly performant; the model is reported to be AT LEAST 1/10th the size of any other model that scores > 50 on the Artificial Analysis Intelligence Index.
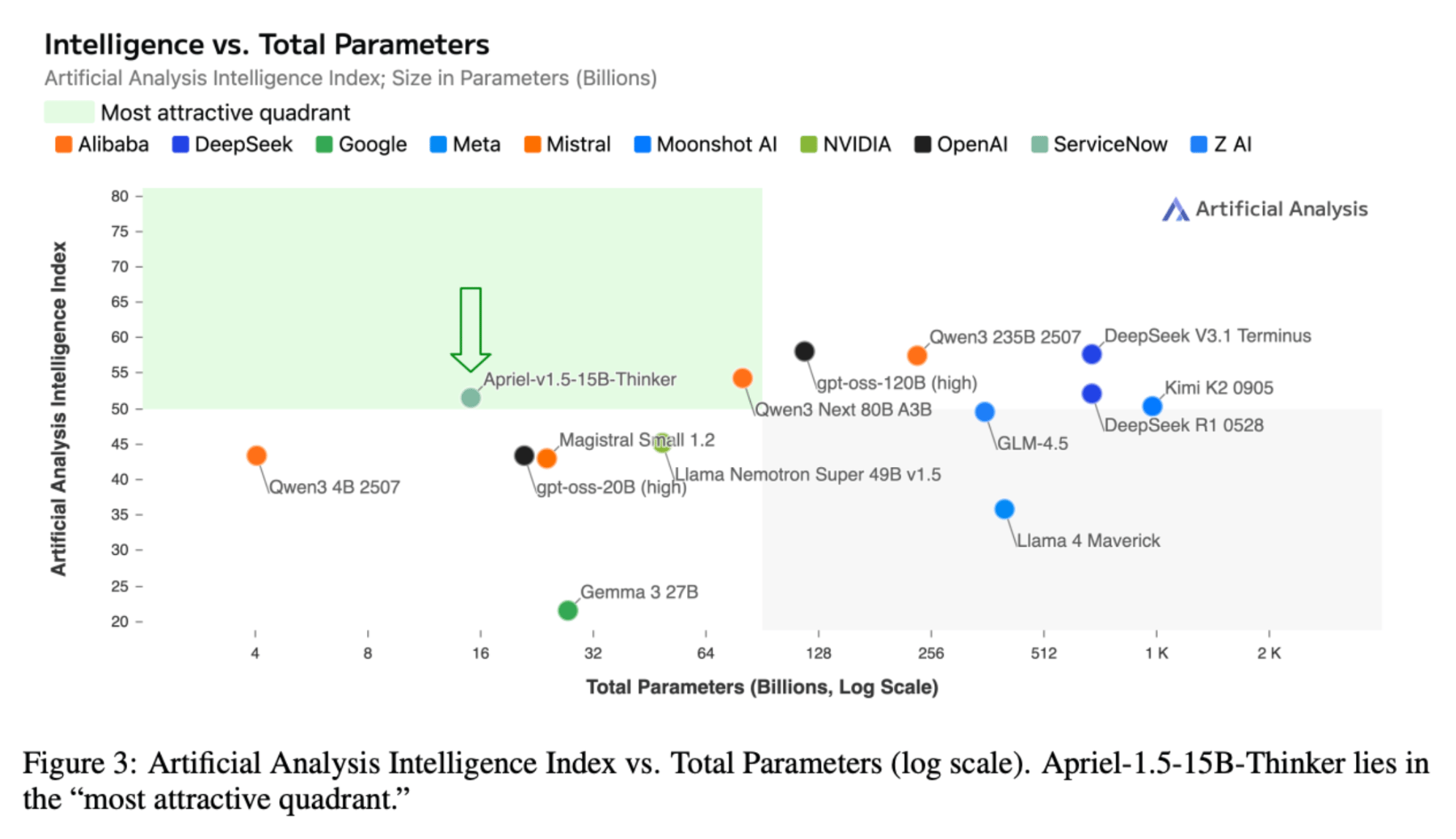
The Artificial Analysis Intelligence Index is a combination metric for measuring general intelligence in large language models. This index aggregates results from ten benchmarks, each targeting a distinct dimension of model capability.
Key Takeaways
-
Midtraining Emphasis: Apriel-1.5-15B-Thinker stands out for its focus on a “midtraining” pipeline (depth upscaling, staged continual pre-training, and text-only SFT) rather than extensive post-training and RL.
-
Memory Efficiency & Performance: Despite its 15-billion-parameter count, it is an open-weight, multimodal reasoning model deployable on a single GPU, offering a memory-efficient alternative to larger models while maintaining high performance (scoring > 50 on the Artificial Analysis Intelligence Index at 1/10th the size of comparable models).
-
Open-Weight Release: The release includes the model checkpoint, training recipes, and evaluation protocols, fostering transparency and further research.
-
Staged Training Approach: The model benefits from a multi-stage training process, including initialization from Pixtral-12B-Base-2409, depth upscaling, projection network realignment, and a two-stage continual pretraining (text-focused, then image-focused), followed by Supervised Fine-Tuning (SFT) using curated, high-signal data.
-
General-Purpose Capabilities: Apriel-1.5-15B-Thinker is designed for a broad range of instruction tasks, including code assistance, logical reasoning, and function calling, but is not suitable for safety-critical applications requiring absolute factual accuracy.
Release Details
The open-weight release of Apriel-1.5-15B-Thinker includes the model checkpoint, all training recipes, and evaluation protocols. To our knowledge, the release does not include the specific datasets used.
However, there are vague mentions of the nature of the data:
- Pretraining-style corpora
- Web-style text and images
- Reasoning-rich samples
- Verified and unverified synthetic data
Weight Initialization
This model was not pretrained from scratch. The researchers initialized the training of this model with the weights of Pixtral-12B-Base-2409, a 12-billion-parameter multimodal model. This base model is of a LLaVA architecture, where we have a vision encoder connected to a multimodal decoder with a two-layer fully connected projection network. We’re curious about why this particular model was chosen for weight initialization given it came out last year and smaller and more performant models exist. The paper mentions that their logic was "to enable multimodal capabilities in a compute efficient manner” and they “used a version from Unsloth, which is no longer available at https://huggingface.co/unsloth as of this writing.”
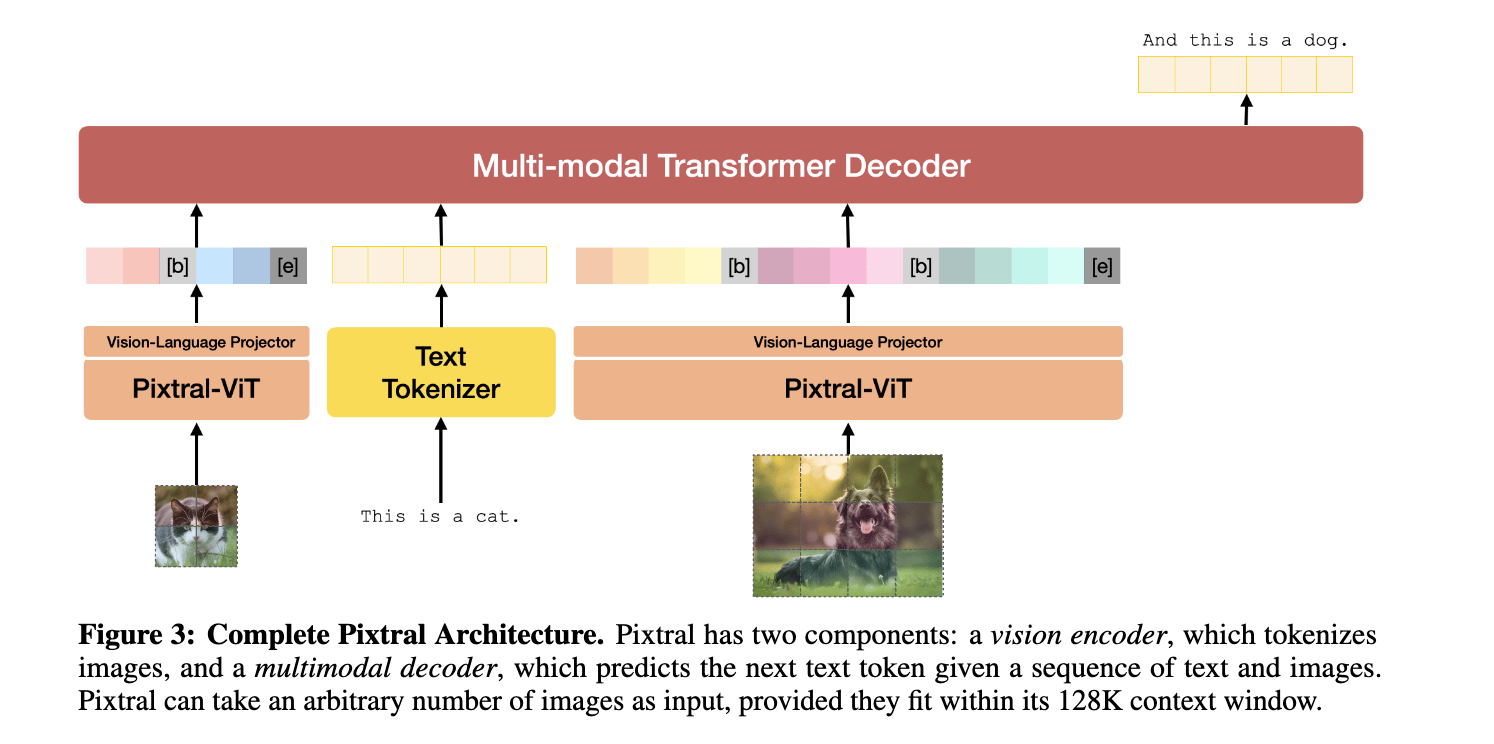
Midtraining
Given the “newness” of the term, the definition of midtraining varies. Hence, we often observe papers specifying their definition like below.

With Apriel-1.5-15B-Thinker, the midtraining pipeline is structured with a three stage pipeline: depth upscaling, staged continual pre-training, and high-quality text only SFT.
Depth Upscaling
By depth upscaling, the paper is referring to increasing the number of hidden layers in the decoder from 40 to 48. A similar approach was taken in their previous model, Apriel-Nemotron-15B-Thinker, where they transformed a 12B model into a stable 15B model by creating additional transformer layers using various approaches including averaging, max-pooling, averaging alternative layers, and duplicating layers – followed by training on a large corpus of text tokens – half of which the model had previously seen and other half from “high-quality web content, technical literature, mathematical problem sets, programming code, and StackExchange discussions”. This is a more compute-efficient and data-efficient approach than training from scratch, albeit with increasing the number of layers, there’s still a tradeoff of better performance for reduced computational efficiency. Before proceeding to projection network alignment, the weights of six equispaced intermediate checkpoints from the depth upscaling stage were averaged in equal proportions.
Projection Network Realignment
Following layer scaling, the researchers realigned the projection network with training on image captioning datasets, multimodal instruction-response pairs, and document understanding tasks – without altering the pretrained weights of the encoder or decoder. This is likely to help stabilize the model’s performance by ensuring the expanded decoder could still effectively interpret the visual features provided by the encoder. The checkpoint obtained during projection network realignment is what is used for subsequent training stages.
Training Setup
The researchers used a sequence length of 8192 (with sequence packing) and a learning rate of 5e-5 with linear decay for both depth upscaling and projection network realignment.
The sequence length determines how many tokens the model processes in a single forward/backward pass. This is also referred to as the context window. A longer sequence length allows the model to see a much larger context at once. For tasks like multimodal instruction-response and document understanding, a long sequence allows for connecting distant pieces of information. Sequence packing means combining multiple shorter training examples into one long sequence (in this case, up to 8192 tokens). This efficiently utilizes the GPU by minimizing the computational overhead of padding (wasted computation on empty tokens), speeding up the training time.
The learning rate controls the step size during the optimization process using gradient descent. With linear decay, the researchers start the learning rate at 5 × 10⁻⁵ (or 0.00005) and with gradual weight updates gradually decrease the learning rate to 0. This helps prevent the training process from overshooting the optimal solution, allowing for more stable convergence.
Continual Pretraining
The continual pretraining is divided into two stages. The first one focuses on text data and the second one focusing on image data.
You may be wondering why its name has continual and pre-training in it. What could that mean? And why is it different from fine-tuning? Our interpretation of this paper is that the training of this model involves “continuing” the pre-training of a base model (Pixtral-12B). Hence “continual pre-training”. This is different from fine-tuning which involves enhancing the model’s performance on a specific task whereas here, the researchers wanted to improve general multimodal performance.
Below is a table outlining how the researchers approached the staged continual pre-training.
| Feature | CPT Stage 1: Foundational Reasoning and Multimodal Data | CPT Stage 2: Targeted Visual Reasoning Data |
|---|---|---|
| Purpose | To enhance textual reasoning and develop broad multimodal capabilities and foundational image understanding. | To further improve visual reasoning capabilities, specifically targeting spatial structure, compositional understanding, and fine-grained perception. |
| Dataset Composition | Mixture of text-only and multimodal tokens: 50% Text-only Tokens: Mathematical/scientific reasoning, coding, and general knowledge. 20% Replayed Tokens: From the decoder upscaling stage. 30% Multimodal Tokens: Document/chart understanding, image captioning, long-form image descriptions, OCR, and reasoning over visual mathematical/logical problems. | Targeted multimodal dataset constructed via a synthetic data generation pipeline applied to large collections of raw images. Primary categories include: Image Reconstruction, Visual Matching, Object Detection, and Counting |
| Unfrozen (Trained) vs Frozen (Untrained) Components | Vision Encoder, Projection Network, and Decoder were all unfrozen (updated during training). | Vision Encoder was frozen (not updated). The Projection Network and Decoder were updated. |
| Sequence Length | 32768 (with sequence packing). | 16384 (with sequence packing). |
| Learning Rate | 5 e-5 with cosine decay and 10% warmup. | 1e-5 with cosine decay and 10% warmup. |
| Loss Computation | Computed on all the tokens in the sequence. | Computed only on the responses for samples in an instruction-response format. |
| Final Checkpoint | Weights of three equispaced intermediate checkpoints were averaged. | The final checkpoint from this stage was used as the base model for future stages (SFT). |
Supervised Fine-Tuning (SFT)
While depth upscaling and continual pretraining resulted in a base model with decent reasoning capabilities, Supervised Fine-Tuning (SFT) allows for further improvement. The researchers were mindful about compute and therefore curated data (high-signal prompts) and used open-source models (gpt-oss-120B) as annotators instead of training their own annotator model.
| Aspect | Details |
|---|---|
| Dataset | Millions of high-quality instruction-response pairs with explicit reasoning traces |
| Domains | Math, coding, science, tool calling, conversations, instruction-following, security, content moderation, robustness |
| Annotator Model | gpt-oss-120b (chosen over DeepSeek-R1- 0528 for compute efficiency) |
| Verification | Execution-verified data for verifiable domains; samples evolved toward complexity |
| Data Processing | De-duplication, content filtering, heuristic filtering, LLM-as-Judge verification, execution-based checks, rejection sampling, format checks, benchmark decontamination |
| Initial Training | 4 epochs at 32768 sequence length |
| Smaller Run 1 | 25% stratified subset, 4 epochs at 32768 sequence length |
| Smaller Run 2 | 49152 sequence length using mixed-length samples |
| Updates | Decoder only (text data only) |
| Loss Computation | Response tokens only |
| Final Model | Weight average of two smaller runs for cost-effective performance gains |
Implementation
Note that the Apriel family of models is designed to handle a wide range of general-purpose instruction tasks, such as code assistance and generation, logical reasoning and multi-step problem-solving, question answering, and information retrieval. These models also excel in function calling, executing complex instructions, and supporting agent-based applications. However, they are not intended for deployment in safety-critical environments without human supervision or in contexts where absolute factual accuracy is required.
As we mentioned before, inference can be performed on a single GPU. Begin by setting up a DigitalOcean GPU Droplet. To set up a GPU Droplet in a Jupyter Notebook environment, follow this tutorial: “Setting Up the GPU Droplet Environment for AI/ML Coding - Jupyter Labs”.
We suggest choosing an AI/ML ready or inference optimized image. DigitalOcean offers GPUs from both NVIDIA and AMD.
In terminal:
pip install transformers==4.48 jinja2==3.1.0 torch torchvision jupyter
pip install huggingface-hub
huggingface-cli download ServiceNow-AI/Apriel-1.5-15b-Thinker
jupyter lab --allow-root
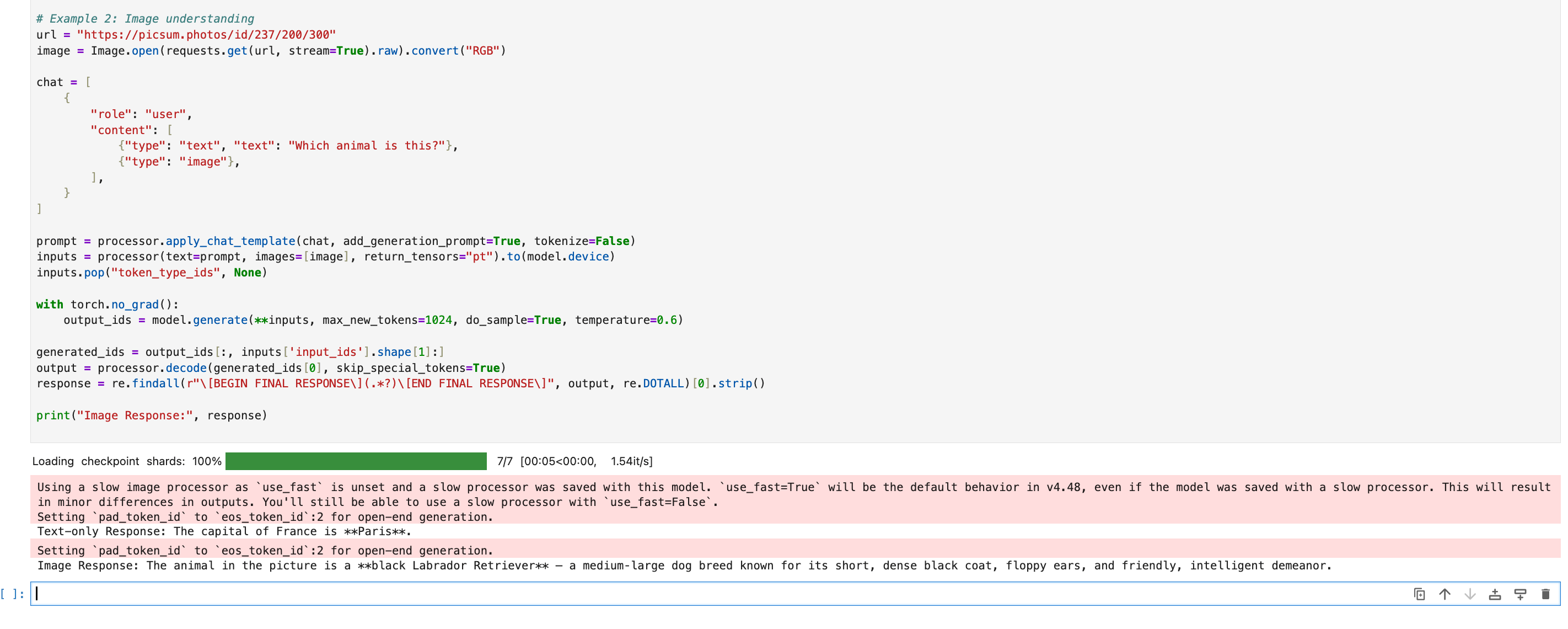
So in this example code snippet, we’ll go through two example prompts.
A basic text prompt inquiring about the capital of France and another inspecting the image below.

#Tested with transformers==4.48
import re
import requests
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForImageTextToText
# Load model
model_id = "ServiceNow-AI/Apriel-1.5-15b-Thinker"
model = AutoModelForImageTextToText.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
processor = AutoProcessor.from_pretrained(model_id)
# Example 1: Text-only prompt
chat = [
{
"role": "user",
"content": [
{"type": "text", "text": "What is the capital for France?"},
],
}
]
inputs = processor.apply_chat_template(chat, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt")
inputs = {k: v.to(model.device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
inputs.pop("token_type_ids", None)
with torch.no_grad():
output_ids = model.generate(**inputs, max_new_tokens=1024, do_sample=True, temperature=0.6)
generated_ids = output_ids[:, inputs['input_ids'].shape[1]:]
output = processor.decode(generated_ids[0], skip_special_tokens=True)
response = re.findall(r"\[BEGIN FINAL RESPONSE\](.*?)\[END FINAL RESPONSE\]", output, re.DOTALL)[0].strip()
print("Text-only Response:", response)
# Example 2: Image understanding
url = "https://picsum.photos/id/237/200/300"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
chat = [
{
"role": "user",
"content": [
{"type": "text", "text": "Which animal is this?"},
{"type": "image"},
],
}
]
prompt = processor.apply_chat_template(chat, add_generation_prompt=True, tokenize=False)
inputs = processor(text=prompt, images=[image], return_tensors="pt").to(model.device)
inputs.pop("token_type_ids", None)
with torch.no_grad():
output_ids = model.generate(**inputs, max_new_tokens=1024, do_sample=True, temperature=0.6)
generated_ids = output_ids[:, inputs['input_ids'].shape[1]:]
output = processor.decode(generated_ids[0], skip_special_tokens=True)
response = re.findall(r"\[BEGIN FINAL RESPONSE\](.*?)\[END FINAL RESPONSE\]", output, re.DOTALL)[0].strip()
print("Image Response:", response)
Below is the model’s output. Try the model out for yourself with more challenging prompts.
Conclusion
Apriel-1.5-15B-Thinker is a 15B parameter model that runs on a single GPU. It uses depth upscaling, staged continual pre-training, and text-only SFT to get good reasoning performance despite its low parameter count. Try out the model and let us know what you think.
FAQ
What is Apriel-1.5-15B-Thinker?
Apriel-1.5-15B-Thinker is an open-weight, 15-billion-parameter multimodal reasoning model developed by ServiceNow. It’s designed to be deployable on a single GPU.
What makes Apriel-1.5-15B-Thinker unique?
The model emphasizes “midtraining” over extensive post-training and Reinforcement Learning (RL). It achieves high performance despite its relatively small parameter count, making it memory-efficient.
What is “midtraining” in the context of this model?
Midtraining for Apriel-1.5-15B-Thinker involves a three-stage pipeline: depth upscaling, staged continual pre-training, and high-quality text-only Supervised Fine-Tuning (SFT).
Can I deploy Apriel-1.5-15B-Thinker on a single GPU?
Yes, one of the key features of Apriel-1.5-15B-Thinker is its ability to perform inference on a single GPU, making it accessible for deployment.
Is the dataset used for training Apriel-1.5-15B-Thinker publicly available?
The open-source release includes the model checkpoint, training recipes, and evaluation protocols, but the specific datasets used are not included in the release. There are vague mentions of pretraining-style corpora, web-style text and images, reasoning-rich samples, and verified/unverified synthetic data.
What are the intended uses of Apriel-1.5-15B-Thinker?
The Apriel family of models is designed for a wide range of general-purpose instruction tasks, including code assistance, logical reasoning, problem-solving, question answering, information retrieval, function calling, and agent-based applications.
Are there any limitations or considerations for using Apriel-1.5-15B-Thinker?
These models are not intended for deployment in safety-critical environments without human supervision or in contexts where absolute factual accuracy is required.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
