AI/ML Technical Content Strategist

Large Language Models have been used for anything and everything we can imagine; from creating simple instruction responses to reasoning solutions to complex math problems to creating step-by-step instructions for guiding a robot’s movements, LLMs are driving a technological revolution forward in front of our eyes. The capabilities of these models are seemingly infinite, so where do we go from here?
One of the avenues we can explore is adding new modalities to the model, making it capable of taking in our input and making an output in formats besides text. Using text, audio, or images, we can expand the capabilities of LLMs to these other modalities during training. For example, using LLMs to generate images is not something new, as we have seen it with BAGEL and then later HunyuanImage 3.0. But, while it has been done before, it arguably hasn’t been applied to more complex use cases yet.
Emu3.5 changes everything there with the introduction of their visual guidance and storytelling pipeline. With Emu3.5, not only can we generate textual instructions for our response, but also a corresponding collection of images in the form of a visual narrative to guide our actions.
In this article, we will take a comprehensive look at Emu3.5: how it works, how it generates images and text, and instructions on how to use it. Follow along with us for a complete guide on using Emu3.5 with DigitalOcean’s GPU Droplets!
Key Takeaways
- Emu3.5 is a new multimodal world model that natively predicts the next state across vision and language, making it ideal for creating visual guides and stories
- Emu3.5 can create visual guides walking you step-by-step through complex processes
- Running Emu3.5 on a NVIDIA H200 powered Gradient GPU Droplet takes just minutes to get started!
Emu3.5: An Overview of the Visual Guidance Pipeline
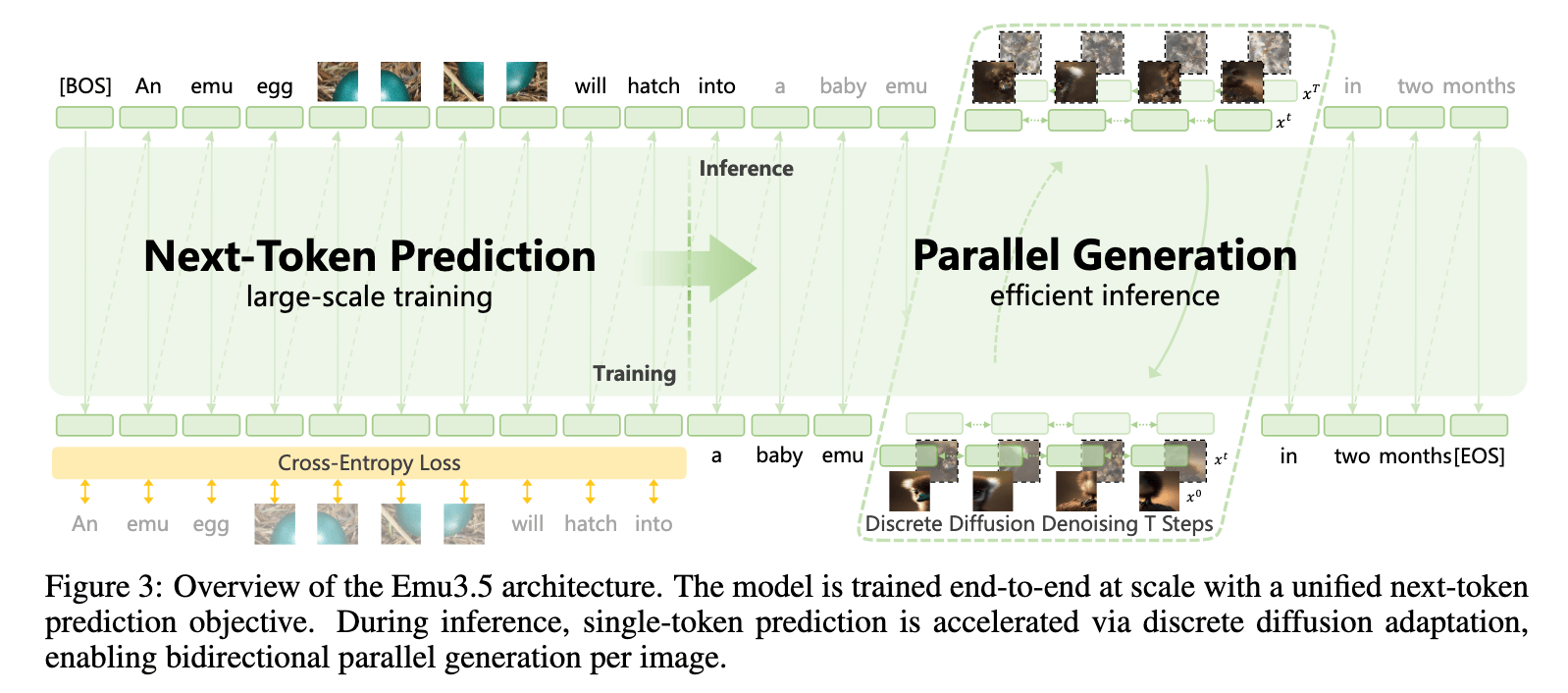
Emu3.5’s greatest innovation lies in its strategy. The unique model is, at its core, a “large-scale multimodal world model that natively predicts the next state across interleaved vision and language” (Source). What this means is that the model is able to dynamically predict the next step in the generation process for images and text, creating the simulacra of storytelling or visual guidance capabilities. To make this possible, the model is altogether a strong LLM, potent image generator, and powerful any to any (image editor) model in its own right.
The model was trained on a massive corpus of a pre-training dataset that integrates four major components:
- interleaved vision-language data: videos with text descriptions interleaved at each stage of the video
- vision-text pairs: images paired with detailed text captions
- any-to-image data: sets of images with captions accurately describing changes to the image
- text-only data: text data for LLM training
Together, the model is trained on this data in 4 main stages: S1 (stage 1) where the model is pre-trained on 10 trillion tokens, S2 where the model is further trained on 3 trillion tokens to refine the models capabilities (image resolution, model accuracy, etc.), and a supervised fine-tuning post-training stage where the model is trained to complete a variety of multimodal tasks like any-to-any and visual guidance. Finally, there is a reinforcement learning stage where the model is further refined to human standards for generalization, task-specificity, and a unified nature (the ability to complete different tasks with a single model).
Getting Started with Emu3.5 on a Gradient GPU Droplet
To get started with Emu3.5, we need sufficient GPU compute. We recommend at least a single NVIDIA H200 for this model. Follow this tutorial for step by step instructions on setting up your environment to run AI/ML technology with a GPU Droplet.
Once your GPU Droplet has spun up and you have accessed it with SSH on your local machine, move to the next section.
Emu3.5 Visual Guidance Gradio Demo
Now in our GPU Droplet, we can set up Emu3.5 by pasting the following script into our remote terminal:
git clone https://github.com/baaivision/Emu3.5
cd Emu3.5
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
pip install flash_attn==2.8.3 --no-build-isolation
mkdir weights
hf download BAAI/Emu3.5-VisionTokenizer --local-dir ./weights/Emu3.5-VisionTokenizer/
hf download BAAI/Emu3.5 --local-dir ./weights/Emu3.5/
hf download BAAI/Emu3.5-Image --local-dir ./weights/Emu3.5-Image/
This block of code will take a few minutes to run, but it will set up everything required to run Emu3.5 for you. Once the setup code is completely run, we can start the demo. The premade demos can then be run with the following commands:
### For image generation or any-to-image tasks
CUDA_VISIBLE_DEVICES=0 python gradio_demo_image.py --host 0.0.0.0 --port 7860
### For Visual Guidance and Story Telling tasks
CUDA_VISIBLE_DEVICES=0 python gradio_demo_interleave.py --host 0.0.0.0 --port 7860
For this demo, we will run the latter. Once it has spun up, use your VS Code/Cursor applications’ simple browser to view the outputted URL on your local browser, as outlined in the setup tutorial.
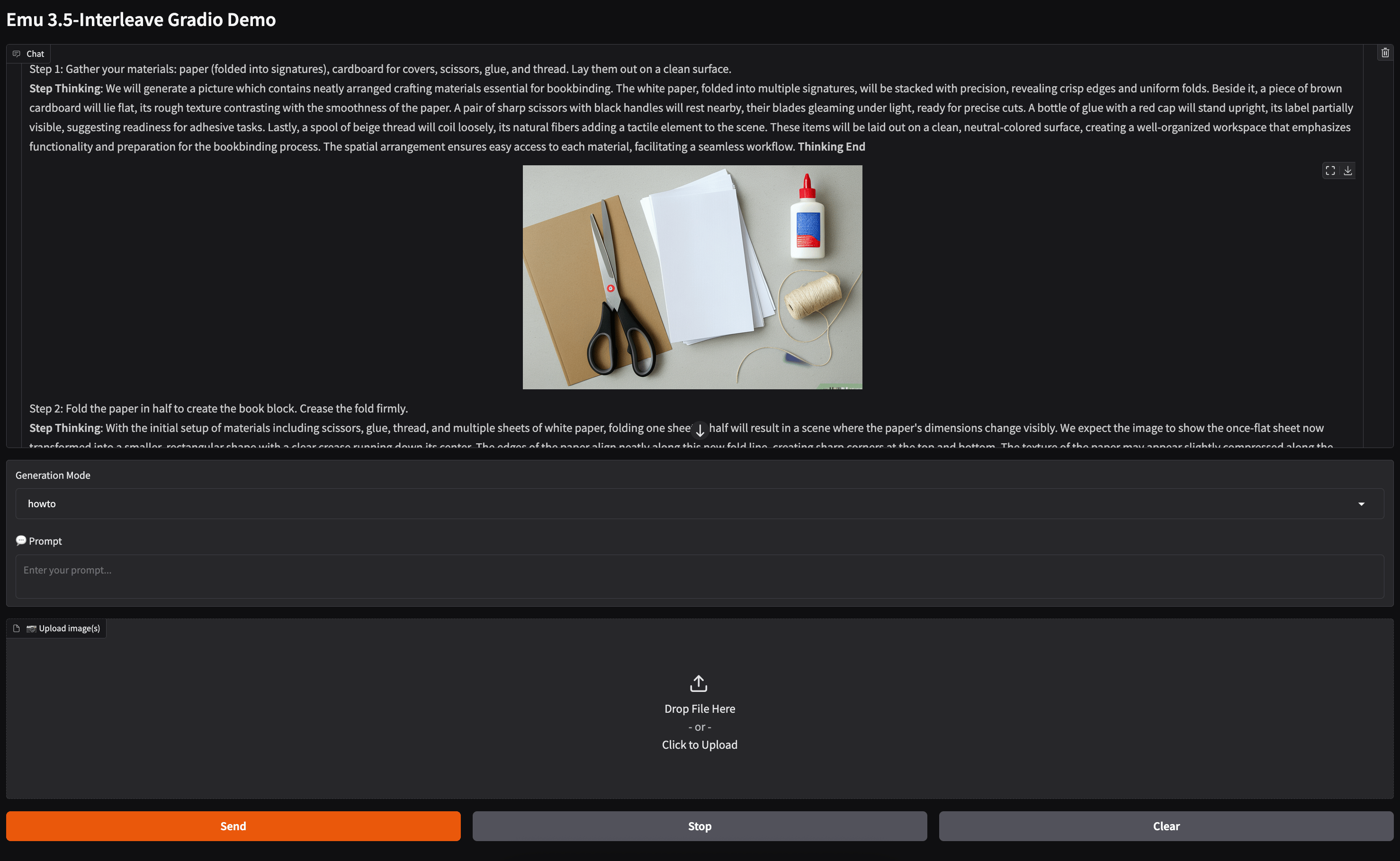
Now, lets look at the application page. Here, we have two options as shown by the “Generation Mode” option in the middle. Select “howto” for visual guidance. Next, we can input our desired task for the model to show us how to complete. For example, we asked the model to show us how to mine for gold in the California Gold Rush. The model output a 5 step process showing how to pan for gold in streams and rivers, as shown in the image below.

As we can see, the instructions are rich in detail and the photos are informative for the task at hand. We also tasked the model with a variety of other questions like showing how to bind a book and how to 3d model and print an action figure to great success. Overall, the visual guidance model shows that the LLM-guided instruction generation is very potent with Emu3.5.

Less functional but more fun, the model is also a great storyteller. We tasked the model with telling a story about a traditional Dungeons and Dragons party getting lost in a modern Wal-Mart, and were delighted by how the model imagined the characters would behave.
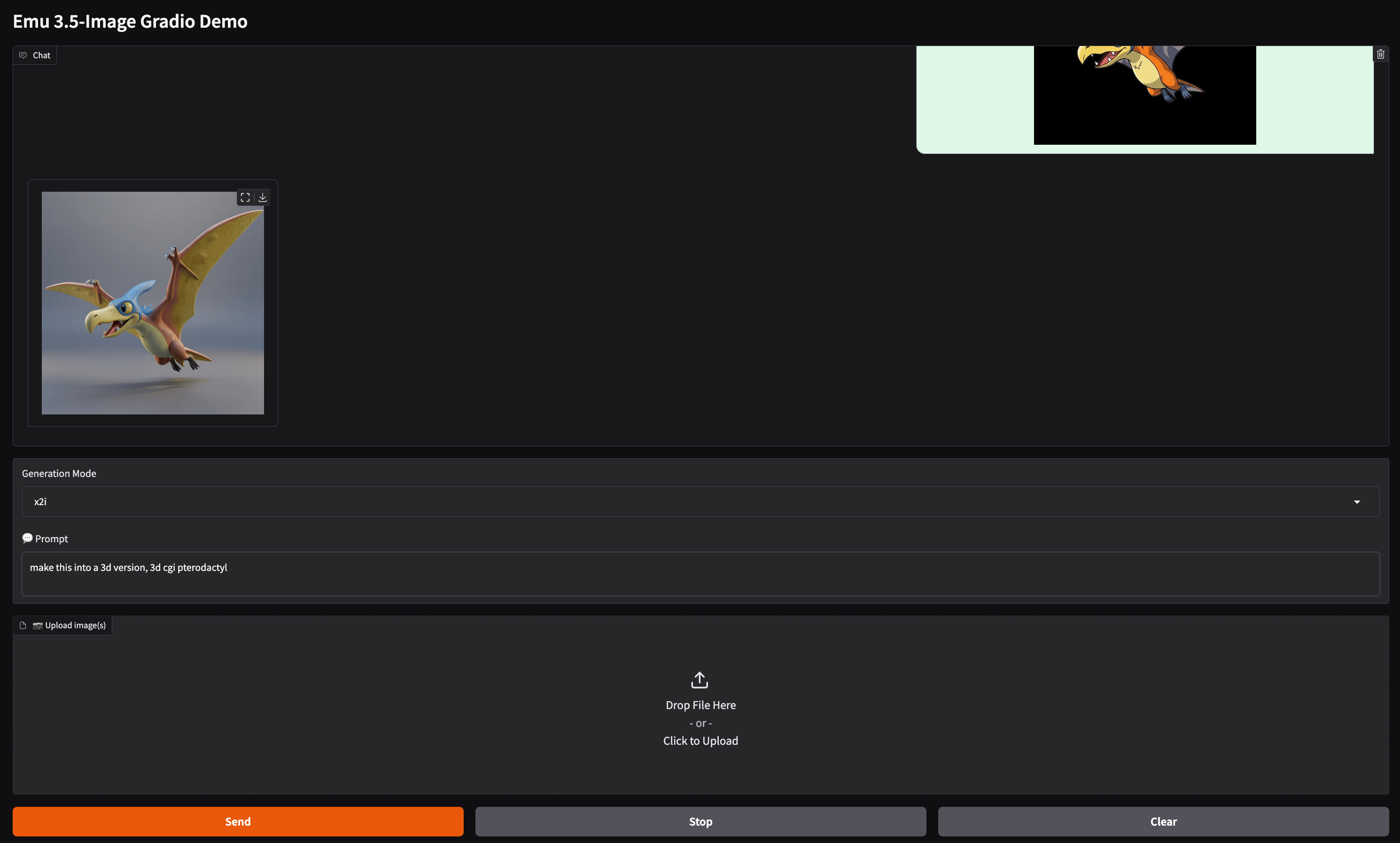
Finally, we want to look at the other demo, the image generation and editing demo. Look at the example above. We asked the model to take a 2d cartoon drawing of a dinosaur and turn it into a realistic 3d representation. The model succeeded with almost no artifacts or evidence of the original 2d nature. This is just one example of the model’s image editing capabilities. Overall, we found it to be more versatile and capable than many of the models we covered in our image editing review, even Qwen Image Edit.
Closing Thoughts
Emu3.5 is perhaps the most innovative release in image generation in recent development. The ability to create interleaved stories and guides using both images and text is a true step forward in terms of combining LLM and computer vision technologies into viable solutions for real problems. Not only that, Emu3.5 is a potent image generator and editor in its own right. We recommend using this model to create your own guides and image edits over all available competitive model paradigms.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
