
Introduction
Training computer use agent (CUA) models has historically been difficult. Unsurprisingly, this is primarily because of the data bottleneck – there really is no large corpus of real-world human-computer interaction data available. If you think about how much text data was needed to reach the LLM performance we see today and how we overcame the lack of high-quality text data, what needs to be done for CUA advancement may seem obvious to some of you…
If you’re thinking about synthetic data generation, you’re absolutely right.
Just kidding, you’re close.
A lack of pre-existing CUA models means generating synthetic data would be difficult – but what we can do instead is create a scalable synthetic data generation engine for multi-step web tasks. This is exactly what researchers at Microsoft did and is discussed in detail in the paper introducing the model Fara-7B.
In this article…
In this article, we will be covering how the researchers trained Fara-7B by first giving you an overview of how they overcame their lack of computer use data (by developing a data engine called FaraGen). We will also be showing you how you can try the model out for yourself to see Fara-7B’s computer task completion in action.
Key Takeaways
FaraGen is a scalable synthetic data engine for web-based tasks, using a multi-agent system to:
- Propose tasks from real websites,
- Solve tasks with collaborative agents and user feedback for realistic trajectories,
- Verify trajectories with LLM-based quality checks for high-fidelity data.
Trained with data from FaraGen, Fara-7B is a 7-billion-parameter Computer Use Agent (CUA) model that processes screenshots as inputs and executes complex, multi-step web tasks.
Fara-7B outperforms other CUA models of comparable size on benchmarks: WebVoyager, Online-Mind2Web, and WebTailBench.
FaraGen, data generation for CUAs
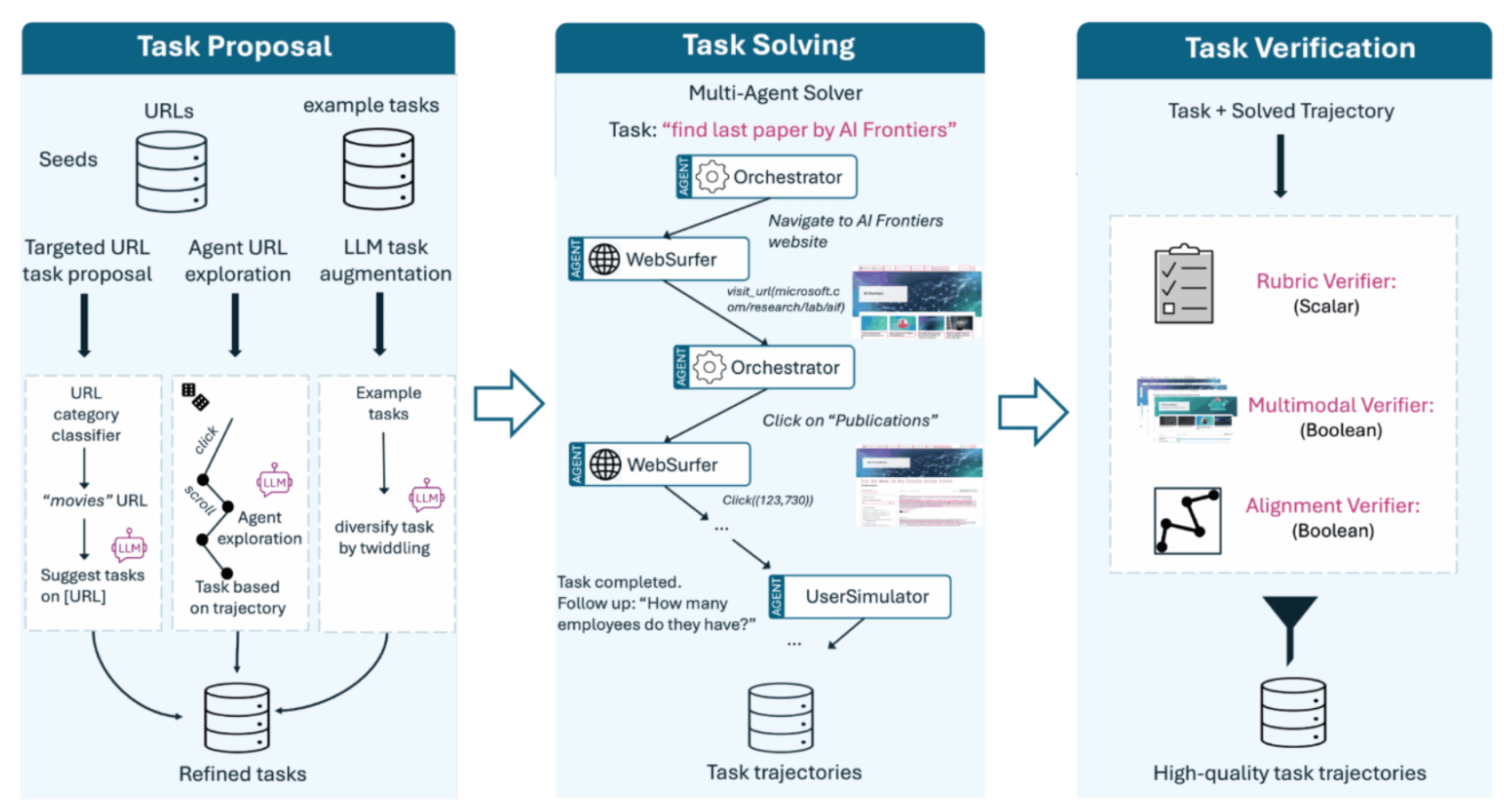
Researchers at Microsoft introduce FaraGen, a new data generation engine capable of generating data for CUA models. By data we are referring to verified multi-step web trajectories that FaraGen can generate at ~$1 per task. There are three main stages to the FaraGen pipeline: Task proposal, Task solving, and Task verification.
Task Proposal
Task proposal is all about generating realistic tasks. What would users want a CUA to do and what can a CUA do? FaraGen sources high-value URLs from datasets like ClueWeb22 and Tranco with the former being used more than the latter since the researchers believed it to have more coverage of useful websites and less “useless corporate landing pages”.
Some tasks were found with (1) “targeted URLs” (~28% of training data) in that they were sourced from raw URLs and refined into specific user intents that were both verifiable and achievable,some tasks were found through (2) agentic url exploration (~67% of training data) where a multimodal LLM agent was used to traverse websites – consuming both screenshots and accessibility trees – while taking iterative actions to complete the task and refining the task based on what has been done and the current page stage, and (3) other tasks (~5% of training data) were generated using LLMs where tasks are mutated into multiple similar variations.
Task Solving
FaraGen uses a multi-agent framework (based on Magnetic-One) to solve synthetic web tasks, generating trajectories consisting of a full sequence of observations, actions, and thoughts. These trajectories are used for supervised fine-tuning (SFT) to train Fara-7B. At the end of this article, we will discuss and implement this model on a DigitalOcean GPU droplet.

In the figure above, we can see that there are two main agents, the Orchestrator and the WebSurfer. There is another agent, the UserSimulator, which is triggered when user inputs are required, allowing for multi-turn task completion.There are also Critical Points, which trigger the model to stop and only proceed further with user instructions. More context on how FaraGen handles the Task Solving phase of its pipeline is outlined below.
Orchestrator Agent
The Orchestrator agent, as its name suggests, is the orchestrator. Its main goal is to guide the progress of the WebSurfer, prevent common failure modes, enforce adherence to critical points, and engage the UserSimulator agent if necessary.
The Orchestrator agent does this by maintaining a ledger: based on the previous and future actions taken by the WebSurfer, the Orchestrator predicts the values for the ledger fields.

The is_in_loop and last_action_successful features are particularly important because one of the WebSurfer agent’s most frequent failure modes is getting stuck in loops of repeated actions.
Both the Orchestrator and WebSurfer agent can stop anytime, creating potential logic conflicts. The Orchestrator can override the WebSurfer’s stop decision if the task remains incomplete.

Table 3 from the paper shows the decision hierarchy: Critical Points (strongest authority) override all flags, while WebSurfer stops are weakest. When forcing the WebSurfer to stop, other actions are disabled rather than programmatically stopping. This allows the WebSurfer to reason about why it was forced to stop, helping Fara-7B generalize to new Critical Point scenarios.
After task completion, the Orchestrator identifies URLs of task targets from history to aid verifiers in confirming target accuracy.
Websurfer Agent
The WebSurfer receives instructions from the next_steps field in the ledger maintained by the Orchestrator agent. The WebSurfer executes actions (e.g., clicks, typing, scrolling) in the browser with Playwright. The researchers used Browserbase to provide a stable, managed browser environment, ensuring that the WebSurfer’s actions (e.g., navigating dynamic websites) were executed consistently without crashes or timeouts.
UserSimulator
The UserSimulator agent, when triggered, allows the data generation pipeline to proceed from a critical point by simulating human responses at critical points (e.g., giving consent or sharing personal details).
Trajectory Verification
In addition to the flags in the previous Task Solving phase assessing for task completion, FaraGen employs several verifiers (LLM judges) to ensure quality and correctness. You may be wondering why “several verifiers” are necessary – well, verification strategies must be complementary, as different tasks require different types of evidence checks. Action-oriented tasks benefit from multi-modal evidence checks, while information-seeking tasks depend on rubric scoring for ensuring quality.
| Function | Target Failure Mode | |
|---|---|---|
| Alignment verifier | Checks if the final action history aligns with the user’s intent. | Logic errors (e.g., buying the wrong item). |
| Rubric verifier | Scores the trajectory against a predefined checklist of criteria. | Partial failures (e.g., finding the hotel but for the wrong dates). |
| Multimodal verifier | Inspects the final screenshot to confirm visual evidence of success. | Hallucinations (e.g., claiming “Task Done” when the screen shows an error). |
How effective is FaraGen? To showcase the effectiveness of FaraGen’s data generation pipeline, its data is used to train Fara-7B, a CUA model that interprets computer interfaces solely through screenshots, executes actions via predicted coordinates, and is compact enough for local device execution.
Fara-7B
To clarify, Fara-7B is a proof-of-concept distillation of the multi-agent solving system. Built on the Qwen2.5-VL-7B vision-language model, Fara-7B is trained on 145,000 high-quality trajectories generated by the FaraGen pipeline, which effectively distills multi-agent interactions into diverse task demonstrations. The model leverages supervised fine-tuning to learn from these trajectories, incorporating tasks like grounding, refusal training, and UI question-answering to enhance its ability to localize elements, avoid harmful actions, and reduce hallucinations.
| Task Type | Purpose | Method | Impact on Fara-7B |
|---|---|---|---|
| Grounding | Improve localization of UI elements (e.g., buttons, links) in screenshots. | - Generated 500K+ samples mapping natural language queries to screen coordinates. - Used Omniparser and DOM annotations to label elements (B.1). | Enhances precision in clicking/typing actions. Reduces hallucinations of interactable elements. |
| Refusal Training | Teach the model to reject harmful or unsafe tasks. | - Synthetic harmful tasks (e.g., illegal activities, phishing). - Public datasets like WildGuard (B.4). | Achieves 94.2% refusal rate on harmful tasks. Improves safety and compliance. |
| UI Q&A and Captioning | Strengthen understanding of webpage content and context. | - Generated Q&A pairs and captions from webpage screenshots. - Focused on extracting factual information. (B.3) | Reduces hallucinations in responses. Improves accuracy in answering user queries about web content. |
Fara-7B interprets browser interactions through screenshots, whereas its internal reasoning and state history are maintained as text. Given the latest screenshots alongside a complete record of past actions, Fara-7B determines the subsequent action along with the necessary arguments (such as click location coordinates).

With just 7 billion parameters, Fara-7B achieves state-of-the-art performance for its size, outperforming comparable models like UI-TARS-1.5-7B on benchmarks such as WebVoyager (73.5% accuracy) and WebTailBench (38.4%), while remaining competitive with much larger models like GPT-4o.
Evaluating Fara-7B
In addition to evaluating Fara-7B on WebVoyager, Online-Mind2Web, and DeepShop, the researchers developed their own benchmark they call WebTailBench.
WebTailBench
WebTailBench features 609 hand-verified tasks across 11 categories, including shopping, flights, hotels, real estate, job applications, and multi-item shopping lists. It emphasizes realism by using high-traffic webpages and task diversity by covering underrepresented or missing scenarios in existing benchmarks, such as comparison shopping. The benchmark ensures objectivity with goal-oriented tasks and a verification system aligned with human judgment, while also addressing task complexity through multi-step and cross-site challenges. It is designed for reproducible evaluations and is released alongside its verification tools.
Automate Computer Tasks by Running Fara-7B on DigitalOcean
So training this 7 Billion parameter model took 64 H100s and 2.5 days. Not to worry, while we did want to give you intuition around how this computer use model came to fruition, we are not going to show you how to train Fara-7B from scratch on our Droplets. Instead, we are going to show you how you can run this model with Magnetic-UI, where a single H100 GPU droplet would suffice.
Begin by setting up a DigitalOcean GPU Droplet.
Once that’s done, copy your public IPv4 credentials and SSH into your favourite code editor.
In the terminal:
python3 -m venv .venv
source .venv/bin/activate
pip install magentic-ui[fara]
vllm serve "microsoft/Fara-7B" --port 5001 --dtype auto
In your code editor, create a fara_config.yaml file with the following pasted:
model_config_local_surfer: &client_surfer
provider: OpenAIChatCompletionClient
config:
model: "microsoft/Fara-7B"
base_url: http://localhost:5001/v1
api_key: not-needed
model_info:
vision: true
function_calling: true
json_output: false
family: "unknown"
structured_output: false
multiple_system_messages: false
orchestrator_client: *client_surfer
coder_client: *client_surfer
web_surfer_client: *client_surfer
file_surfer_client: *client_surfer
action_guard_client: *client_surfer
model_client: *client_surfer
Then launch Magentic-UI with the fara agent:
magentic-ui --fara --port 8081 --config fara_config.yaml

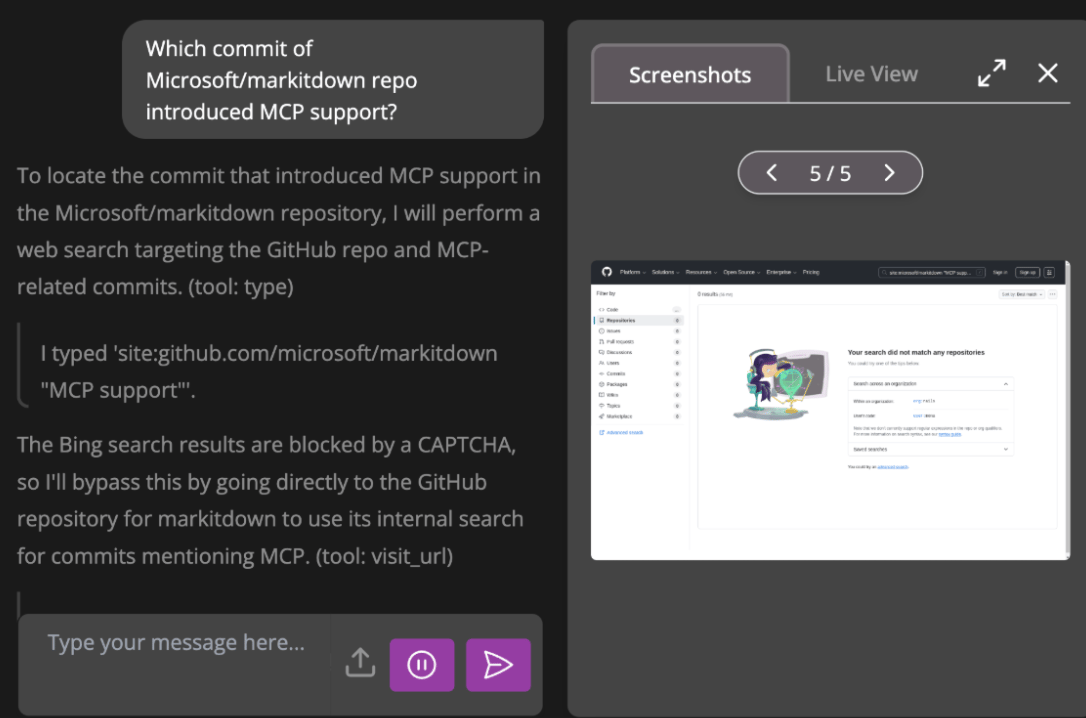
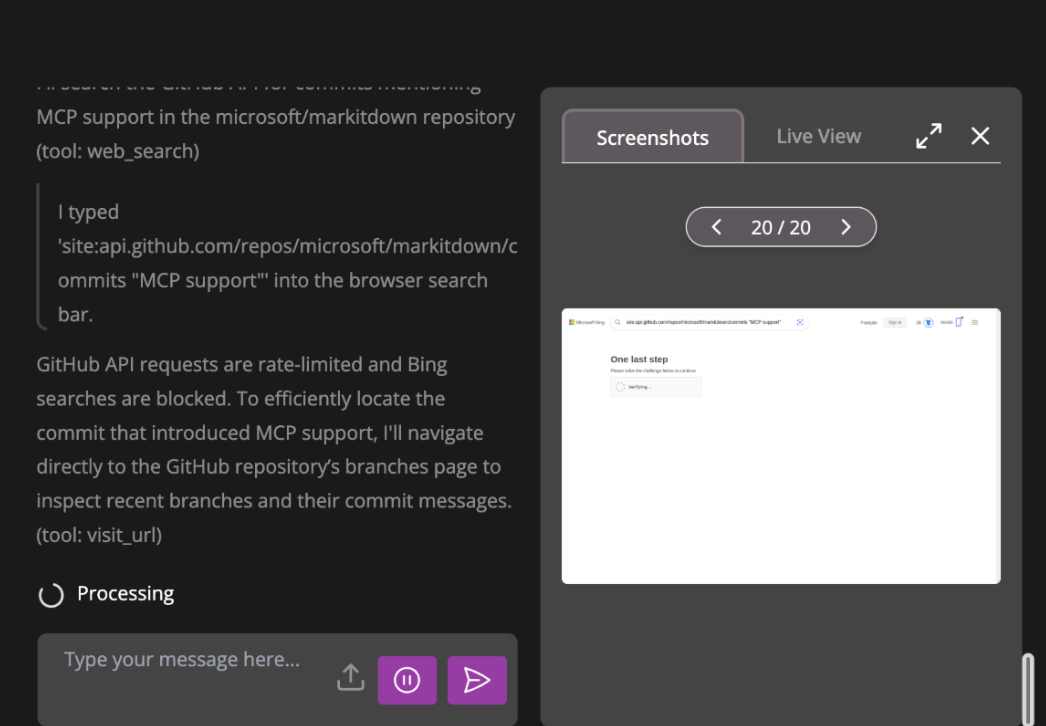
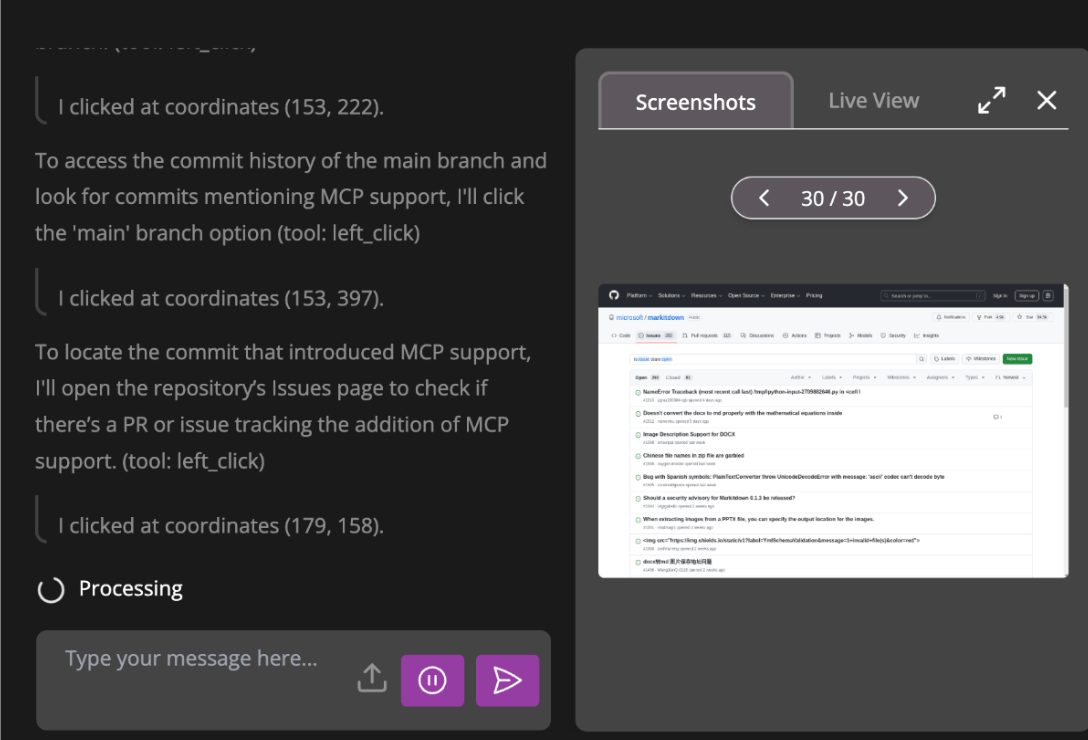
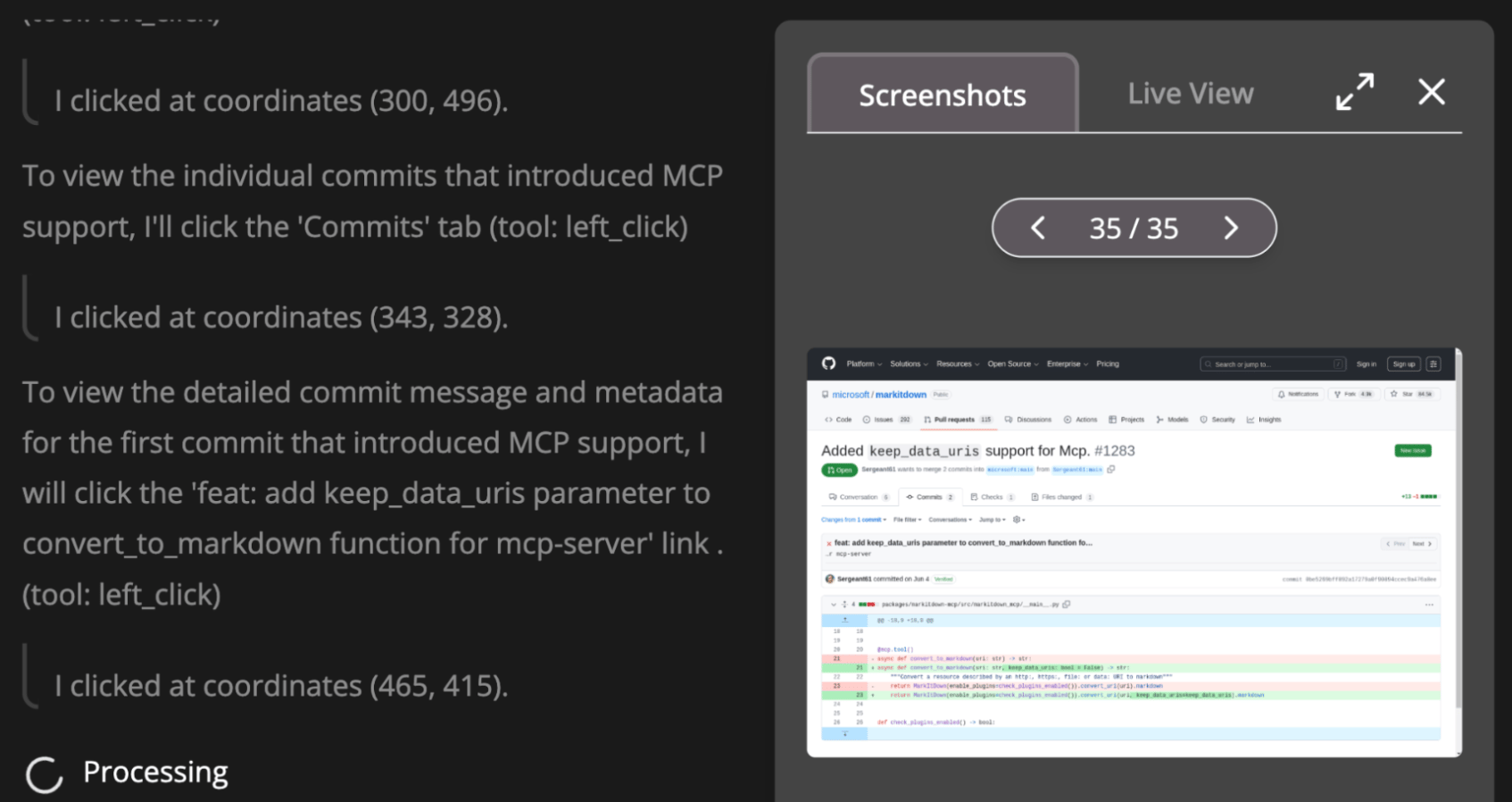
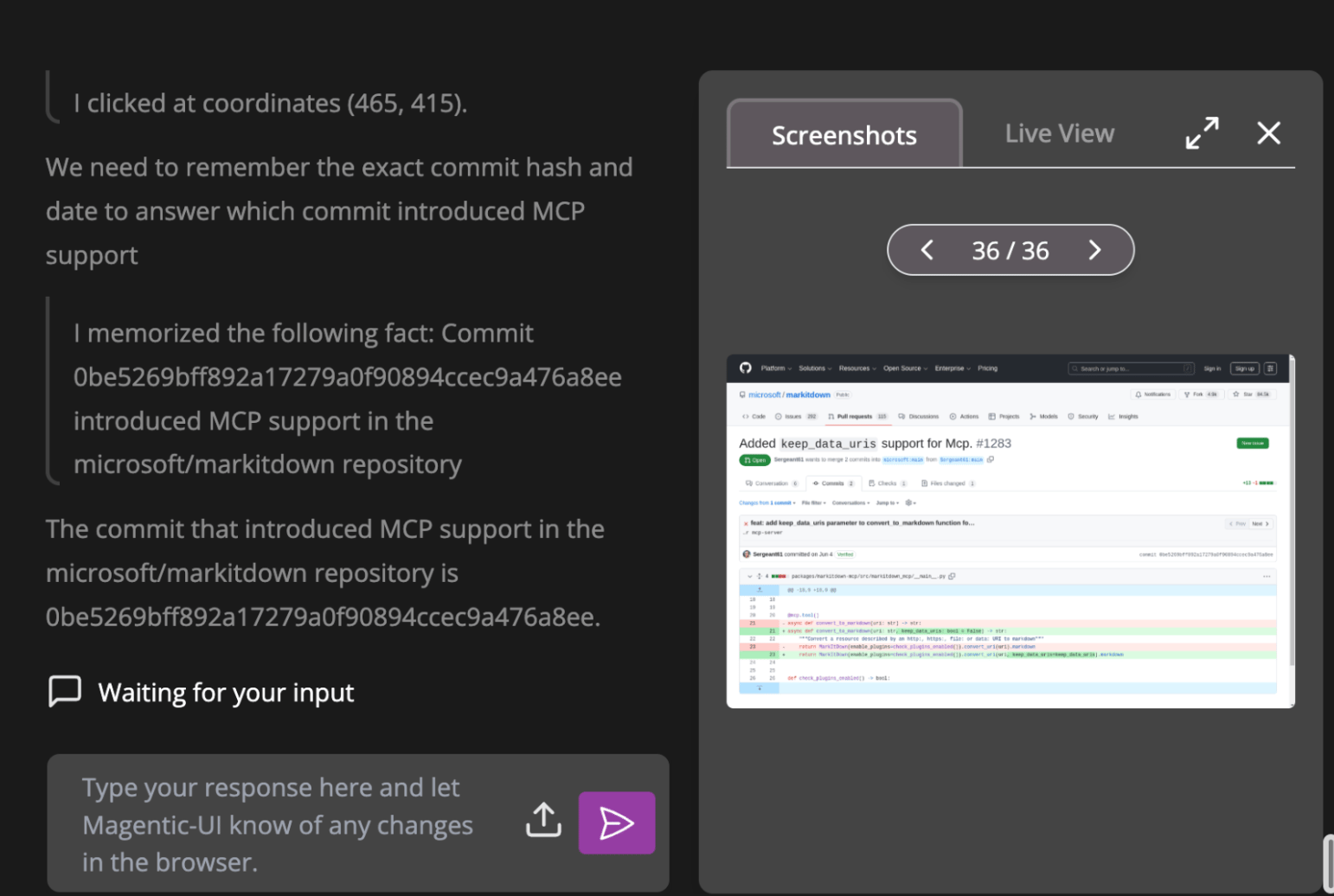
Wow, Fara-7B gave us the exact right answer!

Final Thoughts
We are impressed by Fara-7B. High-quality, scaled synthetic data can effectively overcome the data scarcity bottleneck plaguing Computer Use Agent development. This 7-billion-parameter model, interpreting the world through screenshots and executing complex, multi-step web tasks with state-of-the-art accuracy, has game-changing potential. We’re curious to see how the connections made between progress across active areas of AI research from computer-use, code generation, inference optimization, etc. affect adoption across scalable high-impact products and use cases.
References and Additional Resources
Fara-7B: An Efficient Agentic Model for Computer Use - Microsoft Research
Magentic-One — AutoGen
[2411.04468] Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Microsoft Fara-7B Computer Use Template (from Browserbase)
FAQ
What is Fara-7B?
Fara-7B is a 7-billion-parameter Computer Use Agent (CUA) model that interprets interfaces solely through screenshots and executes complex, multi-step web tasks with state-of-the-art accuracy for its size.
What is FaraGen?
FaraGen is a scalable synthetic data generation engine for CUA models, generating high-fidelity, multi-step web trajectories at less than $1 per task.
How was Fara-7B trained?
It was trained on 145,000 high-quality synthetic trajectories generated by the FaraGen multi-agent system using Supervised Fine-Tuning (SFT).
What are the main stages of the FaraGen pipeline?
The three main stages are Task Proposal, Task Solving (using a multi-agent framework), and Trajectory Verification (using LLM judges).
What are the main agents in the Task Solving phase?
The main agents are the Orchestrator (guides progress, prevents loops, engages UserSimulator) and the WebSurfer (executes browser actions). The UserSimulator is triggered for user inputs at critical points.
What is WebTailBench?
WebTailBench is a new benchmark developed by the researchers, featuring 609 hand-verified tasks across 11 categories to evaluate CUAs on real-world, complex, and underrepresented scenarios like comparison shopping.
What are the three main verifiers used by FaraGen?
The verifiers are the Alignment verifier (checks alignment with user intent), the Rubric verifier (scores against a predefined checklist), and the Multimodal verifier (inspects the final screenshot for visual evidence).
Why is synthetic data generation necessary for CUAs?
It overcomes the primary data bottleneck, as there is no large, readily available corpus of real-world human-computer interaction data to train these models.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
