By Hanif Jetha
 no Kubernetes")
Introdução
Ao executar vários serviços e aplicativos em um cluster do Kubernetes, uma pilha de registros centralizada a nível de cluster pode ajudar você a classificar rapidamente e analisar o volume pesado de dados de registro produzidos por seus Pods. Uma solução popular de registro centralizada é a pilha Elasticsearch, Fluentd e Kibana (EFK).
O Elasticsearch é um motor de busca em tempo real, distribuído e escalável que permite uma pesquisa de texto completo e estruturada, além de análise. Geralmente, ele é utilizado para indexar e fazer pesquisas em grandes volumes de dados de registro, mas também pode ser usado para pesquisar muitos outros tipos de documentos.
O Elasticsearch é geralmente implantado ao lado do Kibana, um poderoso front-end de visualização de dados e painel para o Elasticsearch. O Kibana permite que você explore seus dados de registro do Elasticsearch através de uma interface Web e construa painéis e consultas para responder rapidamente a perguntas e obter conhecimento sobre seus aplicativos do Kubernetes.
Neste tutorial, usaremos o Fluentd para coletar, transformar e enviar dados de registro ao back-end do Elasticsearch. O Fluentd é um coletor de dados de código aberto popular que será configurado em nossos nós do Kubernetes para rastrear arquivos de registro de contêineres, filtrar e transformar os dados de registro e entregá-los ao cluster do Elasticsearch, onde eles serão indexados e armazenados.
Vamos começar configurando e iniciando um cluster escalável do Elasticsearch e, em seguida, criaremos o Serviço e Implantação do Kibana Kubernetes. Para finalizar,será configurado o Fluentd como um DaemonSet para que ele execute em cada nó de trabalho do Kubernetes.
Pré-requisitos
Antes de começar com este guia, certifique-se de que você tenha disponível o seguinte:
-
Um cluster do Kubernetes 1.10+ com controle de acesso baseado em função (RBAC) habilitado
- Certifique-se de que seu cluster tenha recursos suficientes disponíveis para implantar a pilha EFK e, caso não tenha, aumente seu cluster adicionando nós de trabalho. Vamos implantar um cluster de 3 Pods do Elasticsearch (você pode reduzir esse número para 1, se necessário), bem como usar um único Pod de Kibana. Todo nó de trabalho também executará um pod do Fluentd. O cluster neste guia consiste em 3 nós de trabalho e em um plano de controle gerenciado.
-
A ferramenta
kubectlde linha de comando instalada em sua máquina local, configurada para se conectar ao seu cluster. Você pode ler mais sobre como instalar okubectlna documentação oficial.
Assim que tiver esses componentes configurados, você estará pronto para começar com este guia.
Passo 1 — Criando um Namespace
Antes de implantarmos um cluster do Elasticsearch, vamos primeiro criar um Namespace no qual instalaremos toda a nossa instrumentação de registro. O Kubernetes permite que você separe objetos que estiverem executando em seu cluster usando uma abstração de “cluster virtual” chamada Namespaces. Neste guia, vamos criar um namespace kube-logging no qual instalaremos os componentes de pilha EFK. Esse Namespace também permitirá que limpemos rapidamente e removamos a pilha de registro sem perder nenhuma função do cluster do Kubernetes.
Para começar, investigue primeiro os Namespaces existentes em seu cluster usando o kubectl:
- kubectl get namespaces
Você deverá ver os três primeiros Namespaces a seguir, que vêm pré-instalados com seu cluster do Kubernetes:
OutputNAME STATUS AGE
default Active 5m
kube-system Active 5m
kube-public Active 5m
O Namespace default abriga objetos que são criados sem especificar um Namespace. O Namespace kube-system contém objetos criados e usados pelo sistema Kubernetes, como o kube-dns, kube-proxy e o kubernetes-dashboard. É bom manter esse Namespace limpo e não polui-lo com seu as cargas de trabalho do seu aplicativo e instrumentação.
O Namespace kube-public é outro Namespace criado automaticamente que pode ser usado para armazenar os objetos que você gostaria que fossem lidos e possam ser acessados ao longo de todo o cluster, mesmo para os usuários não autenticados.
Para criar o Namespace kube-logging, abra e edite primeiro um arquivo chamado kube-logging.yaml usando seu editor favorito, como o nano:
- nano kube-logging.yaml
Dentro do seu editor, cole o objeto Namespace YAML a seguir:
kind: Namespace
apiVersion: v1
metadata:
name: kube-logging
Então, salve e feche o arquivo.
Aqui, especificamos o objeto do Kubernetes kind como um objeto Namespace. Para aprender mais sobre objetos Namespace, consulte a documentação oficial do Kubernetes Passo a passo de Namespaces. Também especificamos a versão da API do Kubernetes usado para criar o objeto (v1) e damos a ele um name, kube-logging.
Assim que tiver criado o arquivo do objeto Namespace kube-logging.yaml, crie o Namespace usando kubectl create com a sinalização de nome de arquivo -f :
- kubectl create -f kube-logging.yaml
Você deve ver o seguinte resultado:
Outputnamespace/kube-logging created
Em seguida, você poderá confirmar que o Namespace foi criado com sucesso:
- kubectl get namespaces
Neste ponto, você deve ver o novo Namespace kube-logging:
OutputNAME STATUS AGE
default Active 23m
kube-logging Active 1m
kube-public Active 23m
kube-system Active 23m
Agora, podemos implantar um cluster do Elasticsearch neste Namespace de registro isolado.
Passo 2 — Criando o Elasticsearch StatefulSet
Agora que criamos um Namespace para abrigar nossa pilha de registros, podemos começar a implantar seus vários componentes. Primeiramente, vamos começar implantando um cluster de 3 nós do Elasticsearch.
Neste guia, usamos 3 Pods do Elasticsearch para evitar a questão de “dupla personalidade” que ocorre em clusters altamente disponíveis e com múltiplos nós. Em alto nível, “dupla personalidade” é o que aparece quando um ou mais nós não conseguem se comunicar com os outros e vários mestres “divididos” são eleitos. Com 3 nós, se um deles se desconectar temporariamente do cluster, os outros dois nós podem eleger um novo mestre e o cluster pode continuar funcionando enquanto o último nó tenta reingressar. Para aprender mais, leia as páginas Uma nova era para a coordenação de cluster em Elasticsearch e Configurações de votação.
Criando o serviço que executa em segundo plano
Para começar, vamos criar um serviço Kubernetes que executa em segundo plano, chamado elasticsearch, o qual definirá um domínio DNS para os 3 Pods. Um serviço que executa em segundo plano não realiza o balanceamento de carga nem tem um IP estático; para aprender mais sobre serviços que executam em segundo plano, consulte a documentação do Kubernetes oficial.
Abra um arquivo chamado elasticsearch_svc.yaml usando seu editor favorito:
- nano elasticsearch_svc.yaml
Cole o arquivo YAML no seguinte serviço do Kubernetes:
kind: Service
apiVersion: v1
metadata:
name: elasticsearch
namespace: kube-logging
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node
Então, salve e feche o arquivo.
Definimos um Service chamado elasticsearch no Namespace kube-logging e o identificamos como app: elasticsearch. Então, configuramos o .spec.selector para app: elasticsearch de modo que o Serviço selecione os Pods com o rótulo app: elasticsearch. Quando associamos nosso Elasticsearch StatefulSet com esse serviço, o serviço irá retornar registros DNS A que apontam para Pods do Elasticsearch com o rótulo app: elasticsearch.
Então, configuramos o clusterIP: None, que torna o serviço remotamente gerenciável. Por fim, definimos as portas 9200 e 9300 que são usadas para interagir com a API REST e para a comunicação entre nós, respectivamente.
Crie o serviço usando o kubectl:
- kubectl create -f elasticsearch_svc.yaml
Você deve ver o seguinte resultado:
Outputservice/elasticsearch created
Por fim, verifique novamente se o serviço foi criado com sucesso usando o kubectl get:
kubectl get services --namespace=kube-logging
Você deve ver o seguinte:
OutputNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 26s
Agora que configuramos nosso serviço que executa em segundo plano e um domínio .elasticsearch.kube-logging.svc.cluster.local estável para nossos Pods, podemos seguir em frente e criar o StatefulSet.
Criando o StatefulSet
Um Kubernetes StatefulSet permite que você atribua uma identidade estável aos Pods, dando a eles um armazenamento estável e persistente. O Elasticsearch exige armazenamento estável para manter dados através de reprogramações e reinícios dos Pods. Para aprender mais sobre a carga de trabalho do StatefulSet, consulte a página Statefulsets de documentos do Kubernetes.
Abra um arquivo chamado elasticsearch_statefulset.yaml no seu editor favorito:
- nano elasticsearch_statefulset.yaml
Vamos passar pelas definições do objeto StatefulSet seção por seção, colando blocos nesse arquivo.
Inicie colando no seguinte bloco:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
Nesse bloco, definimos um StatefulSet chamado es-cluster no namespace kube-logging. Então, associamos ele ao nosso serviço elasticsearch criado anteriormente usando o campo serviceName. Isso garante que cada Pod no StatefulSet estará acessível usando o seguinte endereço DNS: es-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local, no qual [0,1,2] corresponde ao número ordinal inteiro atribuído ao Pod.
Especificamos 3 replicas (Pods) e configuramos o seletor matchLabels para o app: elasticseach, que então espelhamos na seção .spec.template.metadata. Os campos .spec.selector.matchLabels e .spec.template.metadata.labels devem corresponder.
Agora, podemos seguir em frente para as especificações do objeto. Cole o seguinte bloco de YAML imediatamente abaixo do bloco anterior:
. . .
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
Aqui definimos os Pods no StatefulSet. Nomeamos os contêineres de elasticsearch e escolhemos a imagem Docker docker.elastic.co/elasticsearch/elasticsearch:7.2.0. Neste ponto, você pode modificar essa tag de imagem para corresponder à sua própria imagem interna do Elasticsearch ou uma versão diferente. Note que, para os fins deste guia, apenas o 7.2.0 do Elasticsearch foi testado.
Em seguida, usamos o campo resources para especificar que o contêiner precisa de uma vCPU (CPU virtual) de pelo menos 0,1 garantida para ele que possa estourar até 1 da vCPU (o que limita o uso de recursos do Pod ao realizar uma ingestão inicial grande ou lidar com um pico de carga). Você deve modificar esses valores, dependendo da sua carga esperada e dos recursos disponíveis. Para aprender mais sobre pedidos e limites de recursos, consulte a Documentação do Kubernetes oficial.
Em seguida, abrimos e nomeamos as portas 9200 e 9300 para a API REST e a comunicação entre nós, respectivamente. Especificamos um volumeMount chamado data que irá montar o PersistentVolume chamado data para o contêiner no caminho /usr/share/elasticsearch/data. Vamos definir os VolumeClaims para este StatefulSet em um bloco YAML posterior.
Finalmente, definimos algumas variáveis de ambiente no contêiner:
cluster.name: o nome do cluster do Elasticsearch, que neste guia ék8s-logs.node.name: o nome do nó, que definimos para o campo.metadata.nameusando ovalueFrom. Isso resolverá paraes-cluster-[0,1,2], dependendo do número ordinal atribuído ao nó.discovery.seed_hosts: este campo define uma lista de nós elegíveis para o mestre no cluster que irá semear o processo de descoberta do nós. Neste guia, graças ao serviço que executa em segundo plano que configuramos anteriormente, nossos Pods têm domínios na formaes-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local, para que possamos definir essa variável adequadamente. Ao usar a resolução de namespace local de DNS Kubernetes, podemos encurtar isso paraes-cluster[0,1,2].elasticsearch. Para aprender mais sobre a descoberta do Elasticsearch, consulte a documentação do Elasticsearch oficial.cluster.initial_master_nodes: este campo também especifica uma lista de nós elegíveis para o mestre que participarão no processo de eleição do mestre. Note que para esse campo você deve identificar os nós por seusnode.namee não seus nomes de host.ES_JAVA_OPTS: aqui, definimos isso em-Xms512m -Xmx512m, o que diz ao JVM para usar um tamanho mínimo e máximo de pilha de 512 MB. Você deve ajustar esses parâmetros dependendo da disponibilidade de recursos e necessidades do seu cluster. Para aprender mais, consulte o tópico Configurando o tamanho de pilha.
O próximo bloco que vamos colar é semelhante ao seguinte:
. . .
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
Nesse bloco, definimos vários contêineres Init que são executados antes do contêiner do app principal elasticsearch. Cada um desses Contêineres Init são executados até o fim na ordem em que foram definidos. Para aprender mais sobre os Contêineres Init, consulte a Documentação do Kubernetes oficial.
O primeiro, chamado fix-permissions, executa um comando chown para alterar o proprietário e o grupo do diretório de dados do Elasticsearch para 1000:1000, o UID do usuário do Elasticsearch. Por padrão, o Kubernetes monta o diretório de dados como root, o que o torna inacessível ao Elasticsearch. Para aprender mais sobre esse passo, consulte as “Notas para o uso de produção e padrões” do Elasticsearch.
O segundo, chamado increase-vm-max-map, executa um comando para aumentar os limites do sistema operacional em contagens do mmp, os quais, por padrão, podem ser baixos demais, resultando em erros de falta de memória. Para aprender mais sobre esse passo, consulte a documentação do Elasticsearch oficial.
O próximo Contêiner Init a ser executado é o increase-fd-ulimit, o qual executa o comando ulimit para aumentar o número máximo de descritores de arquivos abertos. Para aprender mais sobre este passo, consulte as “Notas para o uso de produção e padrões” da documentação oficial do Elasticsearch.
Nota: as Notas de uso de produção do Elasticsearch também mencionam a desativação do swap por razões de desempenho. Dependendo da sua instalação ou provedor do Kubernetes, o swap pode já estar desabilitado. Para verificar isso,utilize o exec em um contêiner em funcionamento e execute o cat/proc/swaps para listar dispositivos de swap ativos. Caso não tenha nada lá, o swap está desabilitado.
Agora que definimos nosso contêiner de app principal e os Contêineres Init que são executados antes dele para ajustar o SO do container, podemos adicionar a peça final ao nosso arquivo de definição de objeto do StatefulSet: o volumeClaimTemplates.
Cole o seguinte bloco volumeClaimTemplate :
. . .
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: do-block-storage
resources:
requests:
storage: 100Gi
Nesse bloco, definimos o volumeClaimTemplates do StatefulSet. O Kubernetes usará isso para criar PersistentVolumes para os Pods. No bloco acima, nós o chamamos de data (que é o name ao qual nos referimos nos volumeMounts definidos anteriormente) e damos a ele o mesmo rótulo app: elasticsearch do nosso StatefulSet.
Então, especificamos seu modo de acesso como ReadWriteOnce, o que significa que ele só pode ser montado como leitura-gravação por um único nó. Definimos a classe de armazenamento como do-block-storage neste guia, já que usamos um cluster do Kubernetes da DigitalOcean para fins demonstrativos. Você deve alterar esse valor dependendo de onde estiver executando seu cluster do Kubernetes. Para aprender mais, consulte a documentação Volume persistente.
Por fim, especificamos que queremos que cada PersistentVolume tenha 100 GiB de tamanho. Você deve ajustar esse valor, dependendo das suas necessidades de produção.
As especificações completas do StatefulSet devem ter aparência semelhante a esta:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: do-block-storage
resources:
requests:
storage: 100Gi
Assim que estiver satisfeito com sua configuração do Elasticsearch, salve e feche o arquivo.
Agora, implante o StatefulSet usando o kubectl:
- kubectl create -f elasticsearch_statefulset.yaml
Você deve ver o seguinte resultado:
Outputstatefulset.apps/es-cluster created
Você pode monitorar o StatefulSet enquanto ele é implantado usando a opção kubectl rollout status:
- kubectl rollout status sts/es-cluster --namespace=kube-logging
Você deve ver o seguinte resultado enquanto o cluster está sendo implantado:
OutputWaiting for 3 pods to be ready...
Waiting for 2 pods to be ready...
Waiting for 1 pods to be ready...
partitioned roll out complete: 3 new pods have been updated...
Assim que todos os Pods tiverem sido implantados, você poderá verificar se o seu cluster do Elasticsearch está funcionando corretamente, executando um pedido na API REST.
Para fazer isso, primeiro encaminhe a porta local 9200 para a porta 9200 em um dos nós do Elasticsearch (es-cluster-0) usando o kubectl port-forward:
- kubectl port-forward es-cluster-0 9200:9200 --namespace=kube-logging
Então, em uma janela de terminal separada, faça um pedido curl na API REST:
- curl http://localhost:9200/_cluster/state?pretty
Você deve ver o seguinte resultado:
Output{
"cluster_name" : "k8s-logs",
"compressed_size_in_bytes" : 348,
"cluster_uuid" : "QD06dK7CQgids-GQZooNVw",
"version" : 3,
"state_uuid" : "mjNIWXAzQVuxNNOQ7xR-qg",
"master_node" : "IdM5B7cUQWqFgIHXBp0JDg",
"blocks" : { },
"nodes" : {
"u7DoTpMmSCixOoictzHItA" : {
"name" : "es-cluster-1",
"ephemeral_id" : "ZlBflnXKRMC4RvEACHIVdg",
"transport_address" : "10.244.8.2:9300",
"attributes" : { }
},
"IdM5B7cUQWqFgIHXBp0JDg" : {
"name" : "es-cluster-0",
"ephemeral_id" : "JTk1FDdFQuWbSFAtBxdxAQ",
"transport_address" : "10.244.44.3:9300",
"attributes" : { }
},
"R8E7xcSUSbGbgrhAdyAKmQ" : {
"name" : "es-cluster-2",
"ephemeral_id" : "9wv6ke71Qqy9vk2LgJTqaA",
"transport_address" : "10.244.40.4:9300",
"attributes" : { }
}
},
...
Isso indica que nosso cluster do Elasticsearch k8s-logs foi criado com sucesso com 3 nós: es-cluster-0, es-cluster-1 e es-cluster-2. O nó mestre atual é o es-cluster-0.
Agora que o seu cluster do Elasticsearch está funcionando, você prosseguir com a configuração de uma front-end do Kibana para ele.
Passo 3 — Criando a implantação e serviço do Kibana
Para iniciar o Kibana no Kubernetes, vamos criar um serviço chamado kibana e uma implantação constituída por uma réplica de um Pod. Você pode dimensionar o número de réplicas dependendo das suas necessidades de produção. Além disso, pode especificar opcionalmente um tipo de LoadBalancer para que o serviço faça o balanceamento da carga nos Pods da Implantação.
Desta vez, vamos criar o serviço e a implantação no mesmo arquivo. Abra um arquivo chamado kibana.yaml no seu editor favorito:
- nano kibana.yaml
Cole a seguinte especificação de serviço:
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
ports:
- port: 5601
selector:
app: kibana
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.2.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601
Então, salve e feche o arquivo.
Nessa especificação, definimos um serviço chamado kibana no namespace kube-logging e demos a ele o rótulo app: kibana.
Também especificamos que ele deve estar acessível na porta 5601 e usar o rótulo app: kibana para selecionar os Pods de destino do serviço.
Na especificação Deployment, definimos uma implantação chamada kibana e especificamos que gostaríamos 1 réplica de Pod.
Usamos a imagem docker.elastic.co/kibana/kibana:7.2.0. Neste ponto, você pode substituir sua própria imagem Kibana privada ou pública para usar.
Especificamos que queremos 0,1 de uma vCPU, pelo menos, garantida para o Pod, usando até um limite de 1 vCPU. Você pode modificar esses parâmetros, dependendo da sua carga esperada e dos recursos disponíveis.
Em seguida, usamos a variável de ambiente ELASTICSEARCH_URL para definir o ponto de extremidade e porta para o cluster do Elasticsearch. Ao usar o Kubernetes DNS, esse ponto de extremidade corresponde ao seu nome de serviço, elasticsearch. Este domínio fará a resolução em relação a uma lista de endereços IP para os 3 Pods do Elasticsearch. Para aprender mais sobre o DNS do Kubernetes, consulte DNS para serviços e Pods.
Por fim, definimos para o contêiner do Kibana a porta 5601, para a qual o serviço kibana irá encaminhar pedidos.
Assim que estiver satisfeito com sua configuração do Kibana, é possível implantar o serviço e a implantação usando o kubectl:
- kubectl create -f kibana.yaml
Você deve ver o seguinte resultado:
Outputservice/kibana created
deployment.apps/kibana created
Você pode verificar se a implantação foi bem-sucedida, executando o seguinte comando:
- kubectl rollout status deployment/kibana --namespace=kube-logging
Você deve ver o seguinte resultado:
Outputdeployment "kibana" successfully rolled out
Para acessar a interface do Kibana, vamos novamente encaminhar uma porta local ao nó do Kubernetes executando o Kibana. Obtenha os detalhes do Pod do Kibana usando o kubectl get:
- kubectl get pods --namespace=kube-logging
OutputNAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 55m
es-cluster-1 1/1 Running 0 54m
es-cluster-2 1/1 Running 0 54m
kibana-6c9fb4b5b7-plbg2 1/1 Running 0 4m27s
Aqui, observamos que nosso Pod do Kibana se chama kibana-6c9fb4b5b7-plbg2.
Encaminhe a porta local 5601 para a porta 5601 neste Pod:
- kubectl port-forward kibana-6c9fb4b5b7-plbg2 5601:5601 --namespace=kube-logging
Você deve ver o seguinte resultado:
OutputForwarding from 127.0.0.1:5601 -> 5601
Forwarding from [::1]:5601 -> 5601
Agora, no seu navegador Web, visite o seguinte URL:
http://localhost:5601
Se ver a seguinte página de boas-vindas do Kibana, você implantou o Kibana no seu cluster do Kubernetes com sucesso:

Agora, é possível seguir em frente para a implantação do componente final da pilha do EFK: o coletor de registros, Fluentd.
Passo 4 — Criando o DaemonSet do Fluentd
Neste guia, vamos configurar o Fluentd como um DaemonSet, que é um tipo de carga de trabalho do Kubernetes que executa uma cópia de um determinado Pod em cada nó no cluster do Kubernetes. Ao usar este controle do DaemonSet, vamos implantar um Pod do agente de registros do Fluentd em cada nó do nosso cluster. Para aprender mais sobre essa arquitetura de registros, consulte o tópico “Usando um agente de registros de nó” dos documentos oficiais do Kubernetes.
No Kubernetes, aplicativos no contêiner que registram para o stdout e stderr têm seus fluxos de registro capturados e redirecionados para os arquivos em JSON nos nós. O Pod do Fluentd irá rastrear esses arquivos de registro, filtrar eventos de registro, transformar os dados de registro e despachá-los para o back-end de registros do Elasticsearch que implantamos no Passo 2.
Além dos registros no contêiner, o agente do Fluentd irá rastrear os registros de componentes do sistema do Kubernetes, como os registros kubelet, kube-proxy e Docker. Para ver uma lista completa das origens rastreadas pelo agente de registros do Fluentd, consulte o arquivo kubernetes.conf usado para configurar o agente de registros. Para aprender mais sobre como fazer registros em clusters do Kubernetes, consulte o tópico “Registro no nível de nó” da documentação oficial do Kubernetes.
Inicie abrindo um arquivo chamado fluentd.yaml no seu editor de texto favorito:
- nano fluentd.yaml
Novamente, vamos colar as definições de objeto do Kubernetes bloco a bloco, fornecendo contexto enquanto prosseguimos. Neste guia, usamos a especificação DaemonSet do Fluentd fornecida pelos mantenedores do Fluentd. Outro recurso útil fornecido pelos mantenedores do Fluentd é o Fluentd para o Kubernetes.
Primeiro, cole a seguinte definição do ServiceAccount:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
Aqui, criamos uma conta de serviço chamada fluentd que os Pods do Fluentd irão usar para acessar a API do Kubernetes. Criamos a conta no Namespace kube-logging e, mais uma vez, damos a ela o rótulo app: fluentd. Para aprender mais sobre contas de serviço no Kubernetes, consulte o tópico Configurar contas de serviço para Pods nos documentos oficiais do Kubernetes.
Em seguida, cole o seguinte bloco ClusterRole:
. . .
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
Aqui, definimos um ClusterRole chamado fluentd ao qual concedemos as permissões get, list e watch nos objetos pods e namespaces. Os ClusterRoles permitem que você conceda acesso aos recursos Kubernetes no escopo do cluster como nós. Para aprender mais sobre o Controle de acesso baseado em função (RBAC) e as funções no cluster, consulte o tópico Usando a autorização RBAC da documentação oficial do Kubernetes.
Agora, cole no seguinte bloco ClusterRoleBinding:
. . .
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging
Neste bloco, definimos um ClusterRoleBinding chamado fluentd, o qual vincula o ClusterRole fluentd à conta de serviço fluentd. Isso concede à ServiceAccount fluentd as permissões listadas na função do cluster fluentd.
Neste ponto, podemos começar a adicionar a especificação real do DaemonSet:
. . .
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
Aqui, definimos um DaemonSet chamado fluentd no Namespace kube-logging e damos a ele o rótulo app: fluentd.
Em seguida, cole na seguinte seção:
. . .
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
Aqui, combinamos o rótulo app: fluentd definido em .metadata.labels e então atribuimos a conta de serviço fluentd ao DaemonSet. Também selecionamos o app: fluentd como os Pods gerenciados por esse DaemonSet.
Em seguida, definimos uma tolerância NoSchedule para corresponder ao taint (conceito de repelência) equivalente nos nós mestres do Kubernetes. Isso garantirá que o DaemonSet também seja implantado para os mestres do Kubernetes. Se não quiser executar um Pod do Fluentd nos seus nós mestres, remova essa tolerância. Para aprender mais sobre taints e tolerâncias do Kubernetes, consulte o tópico “Taints e tolerâncias” dos documentos oficiais do Kubernetes.
Em seguida, começamos a definir o contêiner do Pod, ao qual chamamos de fluentd.
Usamos a imagem oficial do Debian v1.4.2 fornecida pelos mantenedores do Fluentd. Se quiser usar sua própria imagem do Fluentd privada ou pública, ou usar uma versão diferente de imagem, modifique a tag image na especificação do contêiner. O Dockerfile e conteúdo dessa imagem estão disponíveis no repositório Github fluentd-kubernetes-daemonset do Fluentd.
Em seguida, configuramos o Fluentd usando algumas variáveis de ambiente:
FLUENT_ELASTICSEARCH_HOST: configuramos essa variável para o endereço de serviço do Elasticsearch que executa em segundo plano definido anteriormente:elasticsearch.kube-logging.svc.cluster.local. Isso resolverá para uma lista de endereços IP dos 3 Pods do Elasticsearch. O host real do Elasticsearch será provavelmente o primeiro endereço IP retornado nesta lista. Para distribuir os registros ao longo do cluster, será necessário modificar a configuração para plug-in de saída do Elasticsearch do Fluentd. Para aprender mais sobre esse plug-in, consulte o tópico Plug-in de saída do Elasticsearch.FLUENT_ELASTICSEARCH_PORT: configuramos essa variável na porta do Elasticsearch que configuramos anteriormente cedo, a9200.FLUENT_ELASTICSEARCH_SCHEME: configuramos esta variável comohttp.FLUENTD_SYSTEMD_CONF: configuramos esta variável comodisablepara suprimir resultados relacionados aosystemdque não são configurados no contêiner.
Por fim, cole na seguinte seção:
. . .
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
Aqui, especificamos um limite de memória de 512 MiB no Pod do FluentD e garantimos-lhe 0,1 de vCPU e 200 MiB de memória. Você pode ajustar esses limites de recurso e pedidos dependendo do seu volume de registro previsto e dos recursos disponíveis.
Em seguida, vamos montar os caminhos de host /var/log e /var/lib/docker/containers no contêiner usando o varlog e os varlibdockercontainers dos volumeMounts. Esses volumes são definidos no final do bloco.
O parâmetro final que definimos neste bloco é o terminationGracePeriodSeconds, o qual dá ao Fluentd 30 segundos para desligar-se graciosamente após receber um sinal SIGTERM. Após 30 segundos, um sinal SIGKILL é enviado aos contêineres. O valor padrão para o terminationGracePeriodSeconds é 30 s, de modo que, na maioria dos casos, esse parâmetro pode ser omitido. Para aprender mais sobre encerrar graciosamente as cargas de trabalho do Kubernetes, consulte o tópico “Boas práticas do Kubernetes: encerrando com graça” do Google.
As especificações completas do Fluentd devem se parecer com isso:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
Assim que terminar de configurar o DaemonSet do Fluentd, salve e feche o arquivo.
Agora, implante o DaemonSet usando o kubectl:
- kubectl create -f fluentd.yaml
Você deve ver o seguinte resultado:
Outputserviceaccount/fluentd created
clusterrole.rbac.authorization.k8s.io/fluentd created
clusterrolebinding.rbac.authorization.k8s.io/fluentd created
daemonset.extensions/fluentd created
Verifique se o seu DaemonSet foi implantado com sucesso usando o kubectl:
- kubectl get ds --namespace=kube-logging
Você deve ver o seguinte status como resultado:
OutputNAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
fluentd 3 3 3 3 3 <none> 58s
Isso indica que há 3 Pods fluentd em execução, o que corresponde ao número de nós no nosso cluster do Kubernetes.
Agora, podemos pedir ao Kibana para verificar se os dados de registro estão sendo corretamente coletados e despachados para o Elasticsearch.
Com o kubectl port-forward ainda aberto, navegue até http://localhost:5601.
Clique em Discover (Descobrir) no menu de navegação à esquerda:
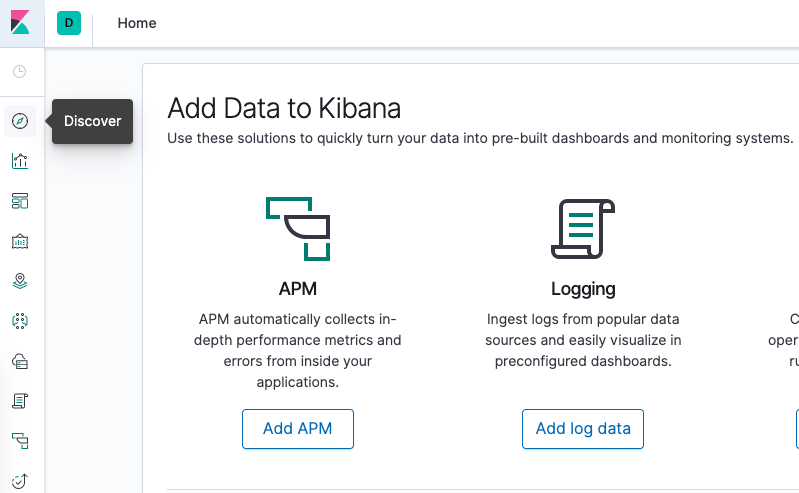
Você deve ver a seguinte janela de configuração:
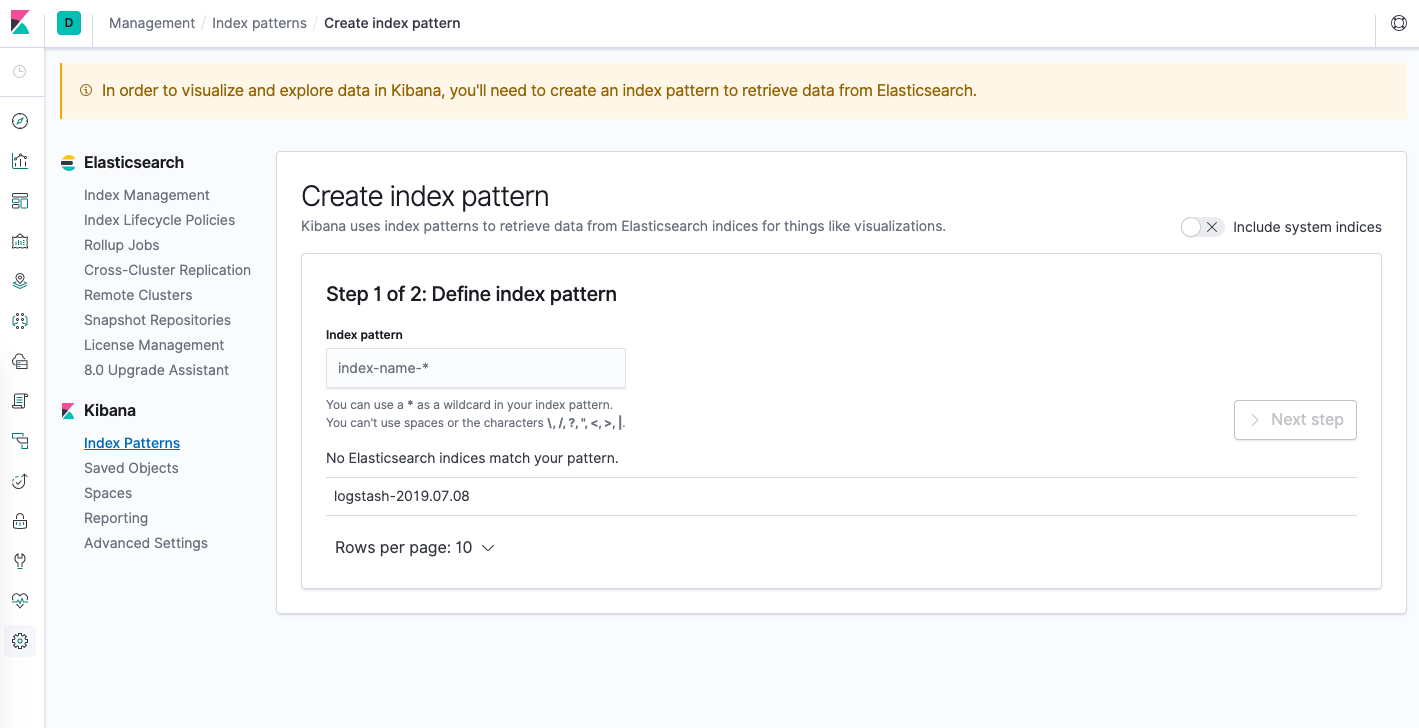
Isso permite que você defina os índices do Elasticsearch que você deseja explorar no Kibana. Para aprender mais, consulte tópico Definindo seus padrões de índice nos documentos oficiais do Kibana. Por enquanto, vamos usar o padrão curinga logstash-* para capturar todos os dados de registro no nosso cluster do Elasticsearch. Digite logstash-* na caixa de texto e clique em Next step (Próximo passo).
Na sequência, você será levado para a seguinte página:
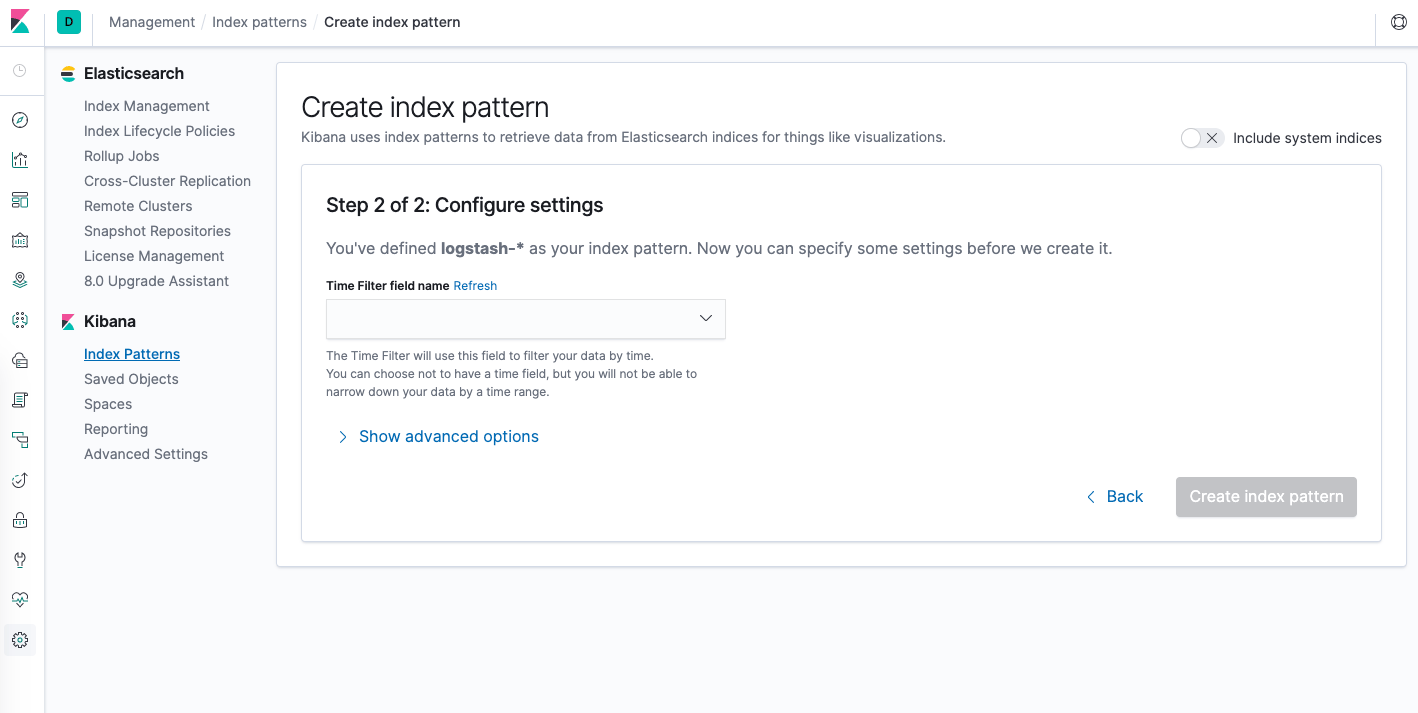
Isso permite que você configure qual campo o Kibana usará para filtrar dados de registro por horário. Na lista suspensa, selecione o campo @timestamp e clique em Create index pattern (Criar padrão de índice).
Agora, clique em Discover (Descobrir) no menu de navegação à esquerda.
Você deve ver um gráfico de histograma e algumas entradas recentes de registro:
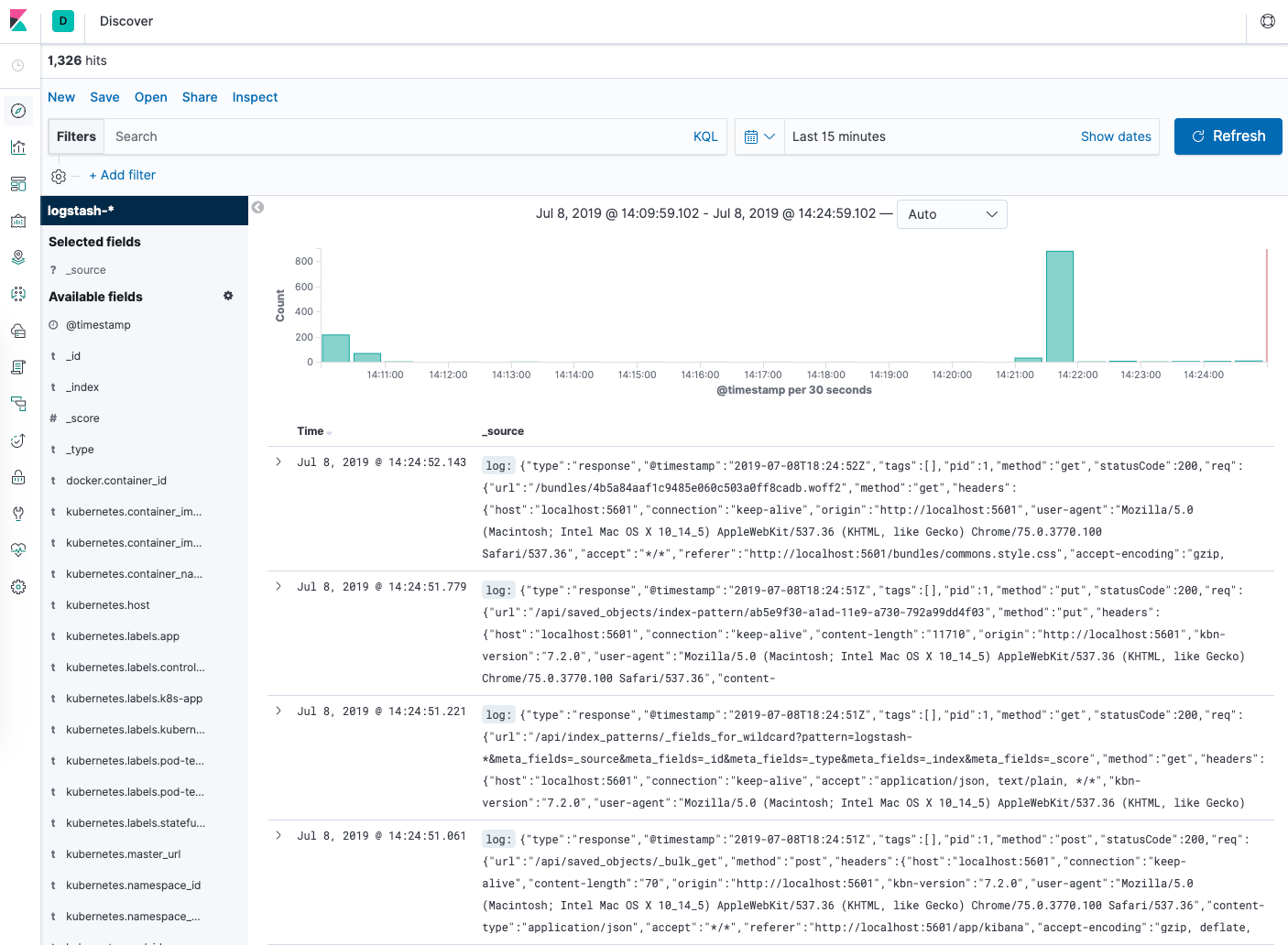
Neste ponto, você configurou e implantou com sucesso a pilha de EFK no seu cluster do Kubernetes. Para aprender como usar o Kibana para analisar seus dados de registro, consulte o Guia de usuário do Kibana.
Na próxima seção opcional, implantaremos um Pod contador simples que imprime números no stdout e encontraremos seus registros no Kibana.
Passo 5 (Opcional) — Testando o registro do contêiner
Para demonstrar um uso básico do Kibana para explorar os últimos registros de um determinado Pod, vamos implantar um Pod contador mínimo que imprima números sequenciais no stdout.
Vamos começar criando o Pod. Abra um arquivo chamado counter.yaml no seu editor favorito:
- nano counter.yaml
Então, cole as especificações do Pod a seguir:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
Salve e feche o arquivo.
Este é um Pod mínimo chamado counter que executa um loop while, imprimindo números sequencialmente.
Implante o Pod counter usando o kubectl:
- kubectl create -f counter.yaml
Assim que o Pod tiver sido criado e estiver em execução, navegue de volta para o painel do Kibana.
A partir da página Discover, na barra de busca digite kubernetes.pod_name:counter. Isso filtra os dados de registro dos Pods chamados counter.
Assim, você deve ver uma lista de entradas do registro do Pod counter:
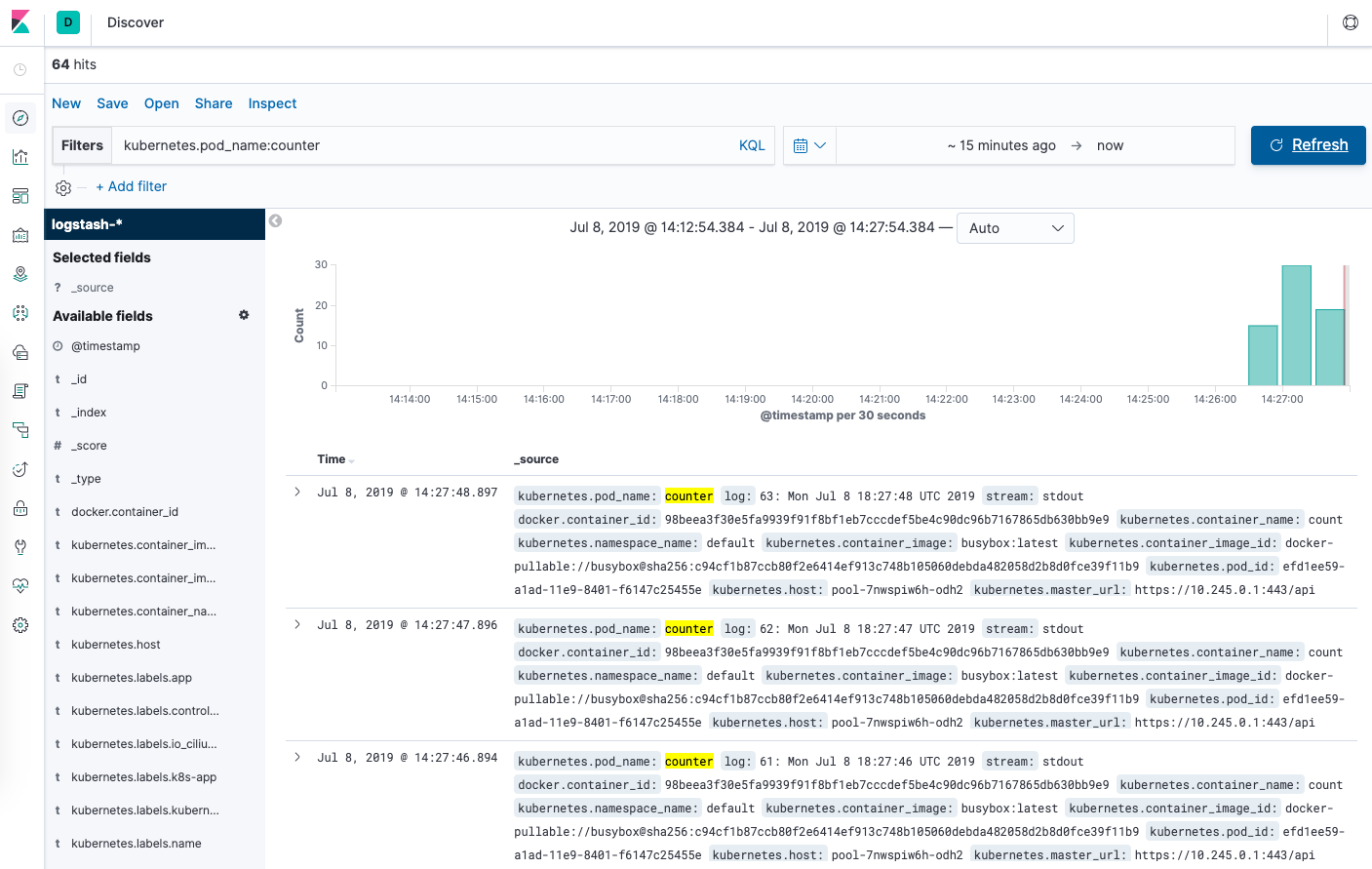
Você pode clicar em qualquer uma das entradas de registro para ver metadados adicionais como o nome do contêiner, nó do Kubernetes, Namespace, entre outros.
Conclusão
Neste guia, demonstramos como configurar o Elasticsearch, Fluentd e Kibana em um cluster do Kubernetes. Usamos uma arquitetura de registro mínima que consiste em um único Pod de agente de registro em execução em cada nó de trabalho do Kubernetes.
Antes de implantar essa pilha de registro no seu cluster de produção do Kubernetes, é melhor ajustar os requisitos e limites de recursos conforme indicado neste guia. Você também pode querer configurar o X-Pack para habilitar recursos de monitoramento e segurança integrados.
A arquitetura de registro que usamos aqui compreende 3 Pods do Elasticsearch, um único Pod do Kibana (sem balanceamento de carga) e um conjunto de Pods do Fluentd implantados como um DaemonSet. Você pode querer dimensionar essa configuração dependendo da sua produção ou uso. Para aprender mais sobre como dimensionar sua pilha do Elasticsearch e do Kibana, consulte o tópico Dimensionando o Elasticsearch.
O Kubernetes também permite arquiteturas de agente de registro mais complexas que podem atender melhor ao seu caso de uso. Para aprender mais, consulte o tópico Arquitetura de registros dos documentos do Kubernetes.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
DevOps Engineer, Former Technical Writer and Editor at DigitalOcean. Expertise in topics including Ubuntu, Kubernetes, Docker, CentOS.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
I am following this tutorial, but i am getting a different result. Elasticsearch logs card shows: No log data found Set up Filebeat, then configure your Elasticsearch output to your monitoring cluster. I tried out Filebeat, but i am getting the same results.
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
