By Hanif Jetha
 в Kubernetes")
Введение
При запуске разнообразных служб и приложений в кластере Kubernetes централизованный комплекс регистрации данных кластерного уровня поможет быстро сортировать и анализировать большие объемы данных журналов подов. В числе популярных централизованных решений регистрации данных нельзя не назвать комплекс Elasticsearch, Fluentd, and Kibana (EFK).
Elasticsearch — распределенный и масштабируемый механизм поиска в реальном времени, поддерживающий полнотекстовый и структурированный поиск, а также аналитику. Он обычно используется для индексации больших журналов и поиска в них данных, но также его можно использовать и для поиска во многих различных видах документов.
Elasticsearch обычно развертывается вместе с Kibana, мощным интерфейсом визуализации данных, который выступает как панель управления Elasticsearch. Kibana позволяет просматривать данные журналов Elasticsearch через веб-интерфейс и создавать информационные панели и запросы для быстрого получения ответов на вопросы и аналитических данных по вашим приложениям Kubernetes.
В этом обучающем модуле мы используем Fluentd для сбора данных журнала и их преобразования и отправки на сервер Elasticsearch. Fluentd — популярный сборщик данных с открытым исходным кодом, который мы настроим на узлах Kubernetes для отслеживания файлов журнала контейнеров, фильтрации и преобразования данных журнала и их доставки в кластер Elasticsearch, где они будут индексироваться и храниться.
Для начала мы настроим и запустим масштабируемый кластер Elasticsearch, а затем создадим службу и развертывание Kibana в Kubernetes. В заключение мы настроим Fluentd как DaemonSet, который будет запускаться на каждом рабочем узле Kubernetes.
Предварительные требования
Прежде чем начать прохождение этого обучающего модуля, вам потребуется следующее:
-
Кластер Kubernetes 1.10+ с включенным контролем доступа на основе ролей (RBAC)
- Убедитесь, что кластер имеет достаточно ресурсов для развертывания комплекса EFK. Если ресурсов недостаточно, добавьте в кластер еще рабочие узлы. Мы развернем кластер Elasticsearch с 3 подами (при необходимости вы можете масштабировать развертывание до 1 пода), а также один под Kibana. На каждом рабочем узле также будет запущен под Fluentd. Используемый в этом обучающем модуле кластер будет состоять из 3 рабочих узлов и управляемого уровня управления.
-
Инструмент командной строки
kubectl, установленный на локальном компьютере и настроенный для подключения к вашему кластеру. Дополнительную информацию об установкеkubectlможно найти в официальной документации.
Проверив наличие этих компонентов, вы можете начинать прохождение этого обучающего модуля.
Шаг 1 — Создание пространства имен
Прежде чем разворачивать кластер Elasticsearch, мы создадим пространство имен, куда установим весь инструментарий ведения журналов. Kubernetes позволяет отделять объекты, работающие в кластере, с помощью виртуального абстрагирования кластеров через пространства имен. В этом обучающем модуле мы создадим пространство имен kube-logging, куда установим компоненты комплекса EFK. Это пространство имен также позволит нам быстро очищать и удалять комплекс журналов без потери функциональности кластера Kubernetes.
Для начала исследуйте существующие пространства имен в вашем кластере с помощью команды kubectl:
- kubectl get namespaces
Вы должны увидеть следующие три начальных пространства имен, которые предустанавливаются в кластерах Kubernetes:
OutputNAME STATUS AGE
default Active 5m
kube-system Active 5m
kube-public Active 5m
Пространство имен default содержит объекты, которые создаются без указания пространства имен. Пространство имен kube-system содержит объекты, созданные и используемые системой Kubernetes, в том числе kube-dns, kube-proxy и kubernetes-dashboard. Это пространство имен лучше регулярно очищать и не засорять его рабочими задачами приложений и инструментария.
Пространство имен kube-public — это еще одно автоматически создаваемое пространство имен, которое можно использовать для хранения объектов, которые вы хотите сделать доступными и читаемыми во всем кластере, в том числе для пользователей, которые не прошли аутентификацию.
Для создания пространства имен kube-logging откройте файл kube-logging.yaml в своем любимом текстовом редакторе, например nano:
- nano kube-logging.yaml
В редакторе вставьте следующий код YAML объекта пространства имен:
kind: Namespace
apiVersion: v1
metadata:
name: kube-logging
Затем сохраните и закройте файл.
Здесь мы зададим вид объекта Kubernetes как объект Namespace. Чтобы узнать больше об объектах Namespace, ознакомьтесь с кратким обзором пространств имен в официальной документации по Kubernetes. Также мы зададим версию Kubernetes API, используемую для создания объекта (v1), и присвоим ему имя kube-logging.
После создания файла объекта пространства имен kube-logging.yaml создайте пространство имен с помощью команды kubectl create с флагом -f имя файла:
- kubectl create -f kube-logging.yaml
Вы должны увидеть следующий результат:
Outputnamespace/kube-logging created
Теперь вы можете проверить, было ли пространство имен создано успешно:
- kubectl get namespaces
Теперь вы должны увидеть новое пространство имен kube-logging:
OutputNAME STATUS AGE
default Active 23m
kube-logging Active 1m
kube-public Active 23m
kube-system Active 23m
Теперь мы можем развернуть кластер Elasticsearch в изолированном пространстве имен logging, предназначенном для журналов.
Шаг 2 — Создание набора Elasticsearch StatefulSet
Мы создали пространство имен для нашего комплекса ведения журналов, и теперь можем начать развертывание его компонентов. Вначале мы развернем кластер Elasticsearch из 3 узлов.
В этом руководстве мы будем использовать 3 пода Elasticsearch, чтобы избежать проблемы «разделения мозга», которая встречается в сложных кластерах с множеством узлов и высоким уровнем доступности. Такое «разделение мозга» происходит, когда несколько узлов не могут связываться с другими узлами, и в связи с этим выбирается несколько отдельных основных узлов. В случае с 3 узлами, если один узел временно отключается от кластера, остальные два узла могут выбрать новый основной узел, и кластер будет продолжать работу, пока последний узел будет пытаться снова присоединиться к нему. Дополнительную информацию можно найти в документах «Новая эпоха координации кластеров в Elasticsearch» и «Конфигурации голосования».
Создание службы без главного узла
Для начала мы создадим службу Kubernetes без главного узла с именем elasticsearch, которая будет определять домен DNS для 3 подов. Служба без главного узла не выполняет балансировку нагрузки и не имеет статического IP-адреса. Дополнительную информацию о службах без главного узла можно найти в официальной документации по Kubernetes.
Откройте файл с именем elasticsearch_svc.yaml в своем любимом редакторе:
- nano elasticsearch_svc.yaml
Вставьте следующий код YAML службы Kubernetes:
kind: Service
apiVersion: v1
metadata:
name: elasticsearch
namespace: kube-logging
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node
Затем сохраните и закройте файл.
Мы определяем службу с именем elasticsearch в пространстве имен kube-logging и присваиваем ей ярлык app: elasticsearch. Затем мы задаем для .spec.selector значение app: elasticsearch, чтобы служба выбирала поды с ярлыком app: elasticsearch. Когда мы привязываем Elasticsearch StatefulSet к этой службе, служба возвращает записи DNS A, которые указывают на поды Elasticsearch с ярлыком app: elasticsearch.
Затем мы задаем параметр clusterIP: None, который делает эту службу службой без главного узла. В заключение мы определяем порты 9200 и 9300, которые используются для взаимодействия с REST API и для связи между узлами соответственно.
Создайте службу с помощью kubectl:
- kubectl create -f elasticsearch_svc.yaml
Вы должны увидеть следующий результат:
Outputservice/elasticsearch created
Еще раз проверьте создание службы с помощью команды kubectl get:
kubectl get services --namespace=kube-logging
Вы должны увидеть следующее:
OutputNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 26s
Мы настроили службу без главного узла и стабильный домен .elasticsearch.kube-logging.svc.cluster.local для наших подов. Теперь мы можем создать набор StatefulSet.
Создание набора StatefulSet
Набор Kubernetes StatefulSet позволяет назначать подам стабильный идентификатор и предоставлять им стабильное и постоянное хранилище. Elasticsearch требуется стабильное хранилище, чтобы его данные сохранялись при перезапуске и изменении планировки подов. Дополнительную информацию о рабочей задаче StatefulSet можно найти на странице Statefulsets в документации по Kubernetes.
Откройте файл с именем elasticsearch_statefulset.yaml в своем любимом редакторе:
- nano elasticsearch_statefulset.yaml
Мы изучим каждый раздел определения объекта StatefulSet, вставляя в этот файл блоки.
Для начала вставьте следующий блок:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
В этом блоке мы определяем объект StatefulSet под названием es-cluster в пространстве имен kube-logging. Затем мы связываем его с ранее созданной службой elasticsearch, используя поле serviceName. За счет этого каждый под набора StatefulSet будет доступен по следующему адресу DNS: es-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local, где [0,1,2] соответствует назначенному номеру пода в виде обычного целого числа.
Мы задали 3 копии (пода) и устанлвили для селектора matchLabels значение app: elasticseach, которое мы также отразим в разделе .spec.template.metadata. Поля .spec.selector.matchLabels и .spec.template.metadata.labels должны совпадать.
Теперь мы можем перейти к спецификации объекта. Вставьте следующий блок кода YAML непосредственно под предыдущим блоком:
. . .
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
Здесь мы определяем поды в наборе StatefulSet. Мы присвоим контейнерам имя elasticsearch и выберем образ Docker docker.elastic.co/elasticsearch/elasticsearch:7.2.0. Сейчас вы можете изменить метку образа, чтобы она соответствовала вашему собственному образу Elasticsearch или другой версии образа. Для целей настоящего обучающего модуля тестировалась только версия Elasticsearch 7.2.0.
Мы используем поле resources, чтобы указать, что контейнеру требуется всего гарантировать всего десятую часть ресурсов vCPU с возможностью увеличения загрузки до 1 vCPU (что ограничивает использование ресурсов подом при первоначальной обработке большого объема данных или при пиковой нагрузке). Вам следует изменить эти значения в зависимости от ожидаемой нагрузки и доступных ресурсов. Дополнительную информацию о запросах ресурсов и ограничениях можно найти в официальной документации по Kubernetes.
Мы откроем и назовем порты 9200 и 9300 для REST API и связи между узлами соответственно. Мы зададим volumeMount с именем data, который будет монтировать постоянный том с именем data в контейнер по пути /usr/share/elasticsearch/data. Мы определим VolumeClaims для набора StatefulSet в другом блоке YAML позднее.
В заключение мы зададим в контейнере несколько переменных среды:
cluster.name: имя кластера Elasticsearch, в данном обучающем модуле этоk8s-logs.node.name: имя узла, которое мы устанавливаем как значение поля.metadata.nameс помощьюvalueFrom. Оно разрешается какes-cluster-[0,1,2]в зависимости от назначенного узлу порядкового номера.discovery.seed_hosts: это поле использует список потенциальных главных узлов в кластере, инициирующем процесс обнаружения узлов. Поскольку в этом обучающем модуле мы уже настроили службу без главного узла, наши поды имеют домены в формеes-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local, так что мы зададим соответствующее значение для этой переменной. Используя разрешение DNS в локальном пространстве имен Kubernetes мы можем сократить это доes-cluster-[0,1,2].elasticsearch. Дополнительную информацию об обнаружении Elasticsearch можно найти в официальной документации по Elasticsearch.cluster.initial_master_nodes: в этом поле также задается список потенциальных главных узлов, которые будут участвовать в процессе выбора главного узла. Обратите внимание, что для этого поля узлы нужно указывать по имениnode.name, а не по именам хостов.ES_JAVA_OPTS: здесь мы задаем значение-Xms512m -Xmx512m, которое предписывает JVM использовать минимальный и максимальный размер выделения памяти 512 МБ. Вам следует настроить эти параметры в зависимости от доступности ресурсов и потребностей вашего кластера. Дополнительную информацию можно найти в разделе «Настройка размера выделяемой памяти».
Следующий блок, который мы будем вставлять, выглядит следующим образом:
. . .
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
В этом блоке мы определяем несколько контейнеров инициализации, которые запускаются до главного контейнера приложения elasticsearch. Каждый из этих контейнеров инициализации выполняется до конца в заданном порядке. Дополнительную информацию о контейнерах инициализации можно найти в официальной документации по Kubernetes.
Первый такой контейнер с именем fix-permissions запускает команду chown для смены владельца и группы каталога данных Elasticsearch на 1000:1000, UID польздователя Elasticsearch. По умолчанию Kubernetes монтирует каталог данных как root, что делает его недоступным для Elasticsearch. Дополнительную информацию об этом шаге можно найти в документации по Elasticsearch «Замечания по использованию в производстве и значения по умолчанию».
Второй контейнер с именем increase-vm-max-map запускает команду для увеличения предельного количества mmap в операционной системе, которое по умолчанию может быть слишком низким, в результате чего могут возникать ошибки памяти. Дополнительную информацию об этом шаге можно найти в официальной документации по Elasticsearch.
Следующим запускается контейнер инициализации increase-fd-ulimit, который запускает команду ulimit для увеличения максимального количества дескрипторов открытых файлов. Дополнительную информацию об этом шаге можно найти в документации по Elasticsearch «Замечания по использованию в производстве и значения по умолчанию».
Примечание. В документе «Замечания по использованию в производстве и значения по умолчанию» для Elasticsearch также указывается возможность отключения подкачки для повышения производительности. В зависимости от вида установки Kubernetes и провайдера, подкачка может быть уже отключена. Чтобы проверить это, выполните команду exec в работающем контейнере и запустите cat /proc/swaps для вывода активных устройств подкачки. Если этот список пустой, подкачка отключена.
Мы определили главный контейнер приложений и контейнеры инициализации, которые будут запускаться перед ним для настройки ОС контейнера. Теперь мы можем доставить в наш файл определения объекта StatefulSet заключительную часть: блок volumeClaimTemplates.
Вставьте следующий блок volumeClaimTemplate:
. . .
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: do-block-storage
resources:
requests:
storage: 100Gi
В этом блоке мы определяем для StatefulSet шаблоны volumeClaimTemplates. Kubernetes использует эти настройки для создания постоянных томов для подов. В приведенном выше блоке мы использовали имя data (это имя, на которое мы уже ссылались в определении volumeMounts), и присвоили ему тот же ярлык app: elasticsearch, что и для набора StatefulSet.
Затем мы задаем для него режим доступа ReadWriteOnce, и это означает, что его может монтировать для чтения и записи только один узел. В этом обучающем модуле мы определяем класс хранения do-block-storage, поскольку мы используем для демонстрации кластер DigitalOcean Kubernetes. Вам следует изменить это значение в зависимости от того, где вы запускаете свой кластер Kubernetes. Дополнительную информацию можно найти в документации по постоянным томам.
В заключение мы укажем, что каждый постоянный том должен иметь размер 100 ГиБ. Вам следует изменить это значение в зависимости от производственных потребностей.
Полная спецификация StatefulSet должна выглядеть примерно так:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: do-block-storage
resources:
requests:
storage: 100Gi
Когда вы будете удовлетворены конфигурацией Elasticsearch, сохраните и закройте файл.
Теперь мы развернем набор StatefulSet с использованием kubectl:
- kubectl create -f elasticsearch_statefulset.yaml
Вы должны увидеть следующий результат:
Outputstatefulset.apps/es-cluster created
Вы можете отслеживать набор StatefulSet, развернутый с помощью kubectl rollout status:
- kubectl rollout status sts/es-cluster --namespace=kube-logging
При развертывании кластера вы увидите следующие результаты:
OutputWaiting for 3 pods to be ready...
Waiting for 2 pods to be ready...
Waiting for 1 pods to be ready...
partitioned roll out complete: 3 new pods have been updated...
После развертывания всех подов вы можете использовать запрос REST API, чтобы убедиться, что кластер Elasticsearch функционирует нормально.
Для этого вначале нужно перенаправить локальный порт 9200 на порт 9200 одного из узлов Elasticsearch (es-cluster-0) с помощью команды kubectl port-forward:
- kubectl port-forward es-cluster-0 9200:9200 --namespace=kube-logging
В отдельном окне терминала отправьте запрос curl к REST API:
- curl http://localhost:9200/_cluster/state?pretty
Результат должен выглядеть следующим образом:
Output{
"cluster_name" : "k8s-logs",
"compressed_size_in_bytes" : 348,
"cluster_uuid" : "QD06dK7CQgids-GQZooNVw",
"version" : 3,
"state_uuid" : "mjNIWXAzQVuxNNOQ7xR-qg",
"master_node" : "IdM5B7cUQWqFgIHXBp0JDg",
"blocks" : { },
"nodes" : {
"u7DoTpMmSCixOoictzHItA" : {
"name" : "es-cluster-1",
"ephemeral_id" : "ZlBflnXKRMC4RvEACHIVdg",
"transport_address" : "10.244.8.2:9300",
"attributes" : { }
},
"IdM5B7cUQWqFgIHXBp0JDg" : {
"name" : "es-cluster-0",
"ephemeral_id" : "JTk1FDdFQuWbSFAtBxdxAQ",
"transport_address" : "10.244.44.3:9300",
"attributes" : { }
},
"R8E7xcSUSbGbgrhAdyAKmQ" : {
"name" : "es-cluster-2",
"ephemeral_id" : "9wv6ke71Qqy9vk2LgJTqaA",
"transport_address" : "10.244.40.4:9300",
"attributes" : { }
}
},
...
Это показывает, что журналы k8s-logs нашего кластера Elasticsearch успешно созданы с 3 узлами: es-cluster-0, es-cluster-1 и es-cluster-2. В качестве главного узла выступает узел es-cluster-0.
Теперь ваш кластер Elasticsearch запущен, и вы можете перейти к настройке на нем клиентского интерфейса Kibana.
Шаг 3 — Создание развертывания и службы Kibana
Чтобы запустить Kibana в Kubernetes, мы создадим службу с именем kibana, а также развертывание, состоящее из одной копии пода. Вы можете масштабировать количество копий в зависимости от ваших производственных потребностей и указывать тип LoadBalancer, чтобы служба запрашивала балансировку нагрузки на подах развертывания.
В этом случае мы создадим службу и развертывание в одном и том же файле. Откройте файл с именем kibana.yaml в своем любимом редакторе:
- nano kibana.yaml
Вставьте следующую спецификацию службы:
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
ports:
- port: 5601
selector:
app: kibana
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.2.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601
Затем сохраните и закройте файл.
В этой спецификации мы определили службу с именем kibana в пространстве имен kube-logging и присвоить ему ярлык app: kibana.
Также мы указали, что она должна быть доступна на порту 5601, и использовали ярлык app: kibana для выбора целевых подов службы.
В спецификации Deployment мы определим развертывание с именем kibana и укажем, что нам требуется 1 копия пода.
Мы будем использовать образ docker.elastic.co/kibana/kibana:7.2.0. Сейчас вы можете заменить этот образ на собственный частный или публичный образ Kibana, который вы хотите использовать.
Мы укажем, что нам требуется гарантировать для пода не менее 0.1 vCPU и не более 1 vCPU при пиковой нагрузке. Вам следует изменить эти значения в зависимости от ожидаемой нагрузки и доступных ресурсов.
Теперь мы используем переменную среды ELASTICSEARCH_URL для установки конечной точки и порта для кластера Elasticsearch. При использовании Kubernetes DNS эта конечная точка соответствует названию службы elasticsearch. Этот домен разрешится в список IP-адресов для 3 подов Elasticsearch. Дополнительную информацию о Kubernetes DNS можно получить в документе DNS для служб и подов.
Наконец мы настроим для контейнера Kibana порт 5601, куда служба kibana будет перенаправлять запросы.
Когда вы будете удовлетворены конфигурацией Kibana, вы можете развернуть службу и развертывание с помощью команды kubectl:
- kubectl create -f kibana.yaml
Вы должны увидеть следующий результат:
Outputservice/kibana created
deployment.apps/kibana created
Вы можете проверить успешность развертывания, запустив следующую команду:
- kubectl rollout status deployment/kibana --namespace=kube-logging
Вы должны увидеть следующий результат:
Outputdeployment "kibana" successfully rolled out
Чтобы получить доступ к интерфейсу Kibana, мы снова перенаправим локальный порт на узел Kubernetes, где запущена служба Kibana. Получите подробную информацию о поде Kibana с помощью команды kubectl get:
- kubectl get pods --namespace=kube-logging
OutputNAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 55m
es-cluster-1 1/1 Running 0 54m
es-cluster-2 1/1 Running 0 54m
kibana-6c9fb4b5b7-plbg2 1/1 Running 0 4m27s
Здесь мы видим, что наш под Kibana имеет имя kibana-6c9fb4b5b7-plbg2.
Перенаправьте локальный порт 5601 на порт 5601 этого пода:
- kubectl port-forward kibana-6c9fb4b5b7-plbg2 5601:5601 --namespace=kube-logging
Вы должны увидеть следующий результат:
OutputForwarding from 127.0.0.1:5601 -> 5601
Forwarding from [::1]:5601 -> 5601
Откройте в своем браузере следующий URL:
http://localhost:5601
Если вы увидите следующую приветственную страницу Kibana, это означает, что вы успешно развернули Kibana в своем кластере Kubernetes:

Теперь вы можете перейти к развертыванию последнего компонента комплекса EFK: сборщика данных журнала Fluentd.
Шаг 4 — Создание набора демонов Fluentd
В этом обучающем модуле мы настроим Fluentd как набор демонов. Это тип рабочей задачи Kubernetes, запускающий копию указанного пода на каждом узле в кластере Kubernetes. Используя контроллер набора демонов, мы развернем под агента регистрации данных Fluentd на каждом узле нашего кластера. Дополнительную информацию об архитектуре регистрации данных можно найти в документе «Использование агента регистрации данных узлов» в официальной документации по Kubernetes.
В Kubernetes приложения в контейнерах записывают данные в stdout и stderr, и их потоки регистрируемых данных записываются и перенаправляются в файлы JSON на узлах. Под Fluentd отслеживает эти файлы журналов, фильтрует события журналов, преобразует данные журналов и отправляет их на сервенюу часть регистрации данных Elasticsearch, которую мы развернули на шаге 2.
Помимо журналов контейнеров, агент Fluentd также отслеживает журналы системных компонентов Kubernetes, в том числе журналы kubelet, kube-proxy и Docker. Полный список источников, отслеживаемых агентом регистрации данных Fluentd, можно найти в файле kubernetes.conf, используемом для настройки агента регистрации данных. Дополнительную информацию по регистрации данных в кластерах Kubernetes можно найти в документе «Регистрация данных на уровне узлов» в официальной документации по Kubernetes.
Для начала откройте файл fluentd.yaml в предпочитаемом текстовом редакторе:
- nano fluentd.yaml
Мы снова будем вставлять определения объектов Kubernetes по блокам с указанием дополнительного контекста. В этом руководстве мы используем спецификацию набора демонов Fluentd, предоставленную командой обслуживания Fluentd. Также команда обслуживания Fluentd предоставляет полезный ресурс Kuberentes Fluentd.
Вставьте следующее определение служебной учетной записи:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
Здесь мы создаем служебную учетную запись fluentd, которую поды Fluentd будут использовать для доступа к Kubernetes API. Мы создаем ее в пространстве имен kube-logging и снова присваиваем ей ярлык app: fluentd. Дополнительную информацию о служебных учетных записях в Kubernetes можно найти в документе «Настройка служебных учетных записей для подов» в официальной документации по Kubernetes.
Затем вставьте следующий блок ClusterRole:
. . .
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
Здесь мы определяем блок ClusterRole с именем fluentd, которому мы предоставляем разрешения get, list и watch для объектов pods и namespaces. ClusterRoles позволяет предоставлять доступ к ресурсам в кластере Kubernetes, в том числе к узлам. Дополнительную информацию о контроле доступа на основе ролей и ролях кластеров можно найти в документе «Использование авторизации RBAC» в официальной документации Kubernetes.
Теперь вставьте следующий блок ClusterRoleBinding:
. . .
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging
В этом блоке мы определяем объект ClusterRoleBinding с именем fluentd, которй привязывает роль кластера fluentd к служебной учетной записи fluentd. Это дает служебной учетной записи fluentd разрешения, заданные для роли кластера fluentd.
Сейчас мы можем начать вставку спецификации набора демонов:
. . .
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
Здесь мы определяем набор демонов с именем fluentd в пространстве имен kube-logging и назначаем ему ярлык app: fluentd.
Вставьте следующий раздел:
. . .
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
Здесь мы сопоставляем ярлык app: fluentd, определенный в .metadata.labels и назначаем для набора демонов служебную учетную запись fluentd. Также мы выбираем app: fluentd как поды, управляемые этим набором демонов.
Затем мы определяем допуск NoSchedule для соответствия эквивалентному вызову в главных узлах Kubernetes. Это гарантирует, что набор демонов также будет развернут на главных узлах Kubernetes. Если вы не хотите запускать под Fluentd на главных узлах, удалите этот допуск. Дополнительную информацию о вызовах и допусках Kubernetes можно найти в разделе «Вызовы и допуски» в официальной документации по Kubernetes.
Теперь мы начнем определять контейнер пода с именем fluentd.
Мы используем официальный образ v1.4.2 Debian от команды, обслуживающей Fluentd. Если вы хотите использовать свой частный или публичный образ Fluentd или использовать другую версию образа, измените тег image в спецификации контейнера. Файл Dockerfile и содержание этого образа доступны в репозитории fluentd-kubernetes-daemonset на Github.
Теперь мы настроим Fluentd с помощью нескольких переменных среды:
FLUENT_ELASTICSEARCH_HOST: мы настроим службу Elasticsearch без главных узлов, которую мы определили ранее:elasticsearch.kube-logging.svc.cluster.local. Это разрешается список IP-адресов для 3 подов Elasticsearch. Скорее всего, реальный хост Elasticsearch будет первым IP-адресом, который будет выведен в этом списке. Для распределения журналов в этом кластере вам потребуется изменить конфигурацию плагина вывода Fluentd Elasticsearch. Дополнительную информацию об этом плагине можно найти в документе «Плагин вывода Elasticsearch».FLUENT_ELASTICSEARCH_PORT: в этом параметре мы задаем ранее настроенный портElasticsearch 9200.FLUENT_ELASTICSEARCH_SCHEME: мы задаем для этого параметра значениеhttp.FLUENTD_SYSTEMD_CONF: мы задаем для этого параметра значениеdisable, чтобы подавить выводsystemd, который не настроен в контейнере.
Вставьте следующий раздел:
. . .
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
Здесь мы указываем предельный объем памяти 512 МиБ в поде FluentD и гарантируем выделение 0,1 vCPU и 200 МиБ памяти. Вы можете настроить эти ограничения ресурсов и запросы в зависимости от ожидаемого объема журнала и доступных ресурсов.
Затем мы смонтируем пути хостов /var/log и /var/lib/docker/containers в контейнер, используя varlog и varlibdockercontainers volumeMounts. Эти тома определяются в конце блока.
Последний параметр, который мы определяем в этом блоке, — это параметр terminationGracePeriodSeconds, дающий Fluentd 30 секунд для безопасного выключения при получении сигнала SIGTERM. После 30 секунд контейнеры получают сигнал SIGKILL. Значение по умолчанию для terminationGracePeriodSeconds составляет 30 с, так что в большинстве случаев этот параметр можно пропустить. Дополнительную информацию о безопасном прекращении рабочих задач Kubernetes можно найти в документе Google «Лучшие практики Kubernetes: осторожное прекращение работы».
Полная спецификация Fluentd должна выглядеть примерно так:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
После завершения настройки набора демонов Fluentd сохраните и закройте файл.
Теперь выгрузите набор демонов с помощью команды kubectl:
- kubectl create -f fluentd.yaml
Вы должны увидеть следующий результат:
Outputserviceaccount/fluentd created
clusterrole.rbac.authorization.k8s.io/fluentd created
clusterrolebinding.rbac.authorization.k8s.io/fluentd created
daemonset.extensions/fluentd created
Убедитесь, что набор демонов успешно развернут, с помощью команды kubectl:
- kubectl get ds --namespace=kube-logging
Вы должны увидеть следующее состояние:
OutputNAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
fluentd 3 3 3 3 3 <none> 58s
Такой результат показывает, что работает 3 пода fluentd, что соответствует количеству узлов в нашем кластере Kubernetes.
Теперь мы можем проверить Kibana и убедиться, что данные журнала собираются надлежащим образом и отправляются в Elasticsearch.
При активном перенаправлении kubectl port-forward перейдите на адрес http://localhost:5601.
Нажмите Discover в левом меню навигации:
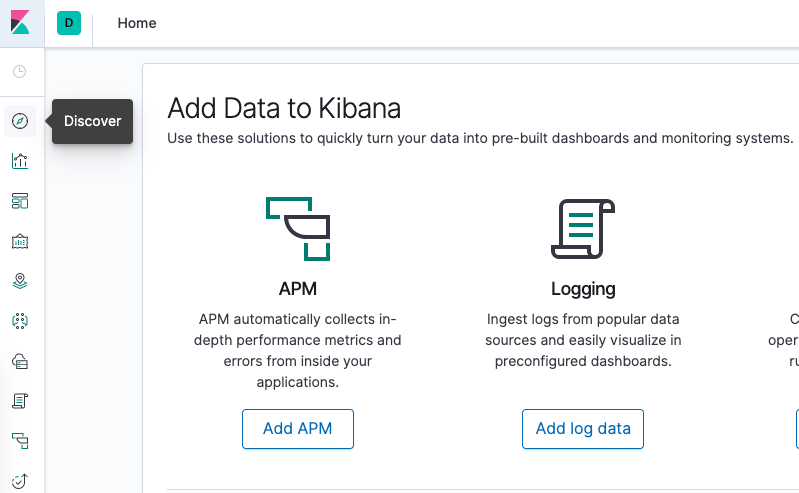
Вы увидите следующее окно конфигурации:
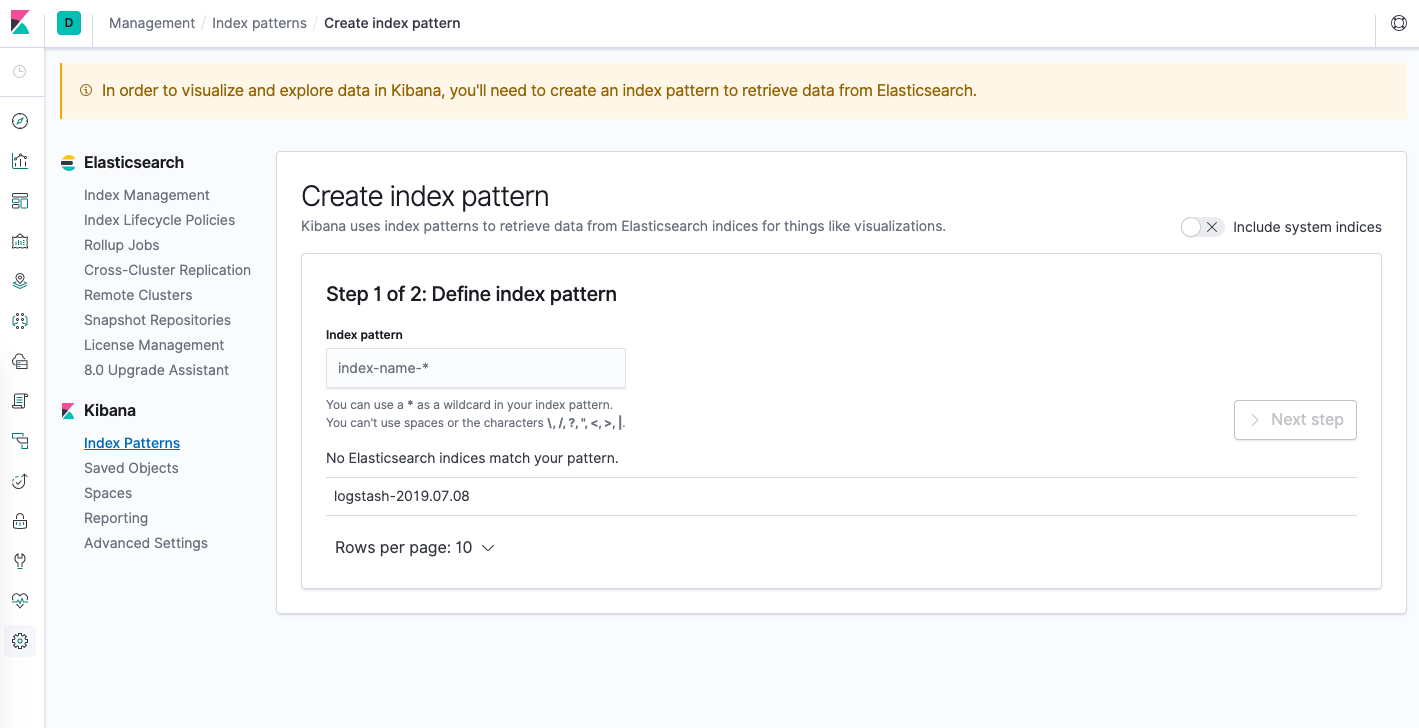
Эта конфигурация позволяет определить индексы Elasticsearch, которые вы хотите просматривать в Kibana. Дополнительную информацию можно найти в документе «Определение шаблонов индексов» в официальной документации по Kibana. Сейчас мы будем использовать шаблон с подстановочным символом logstash-* для сбора всех данных журнала в нашем кластере Elasticsearch. Введите logstash-* в текстовое поле и нажмите «Следующий шаг».
Откроется следующая страница:
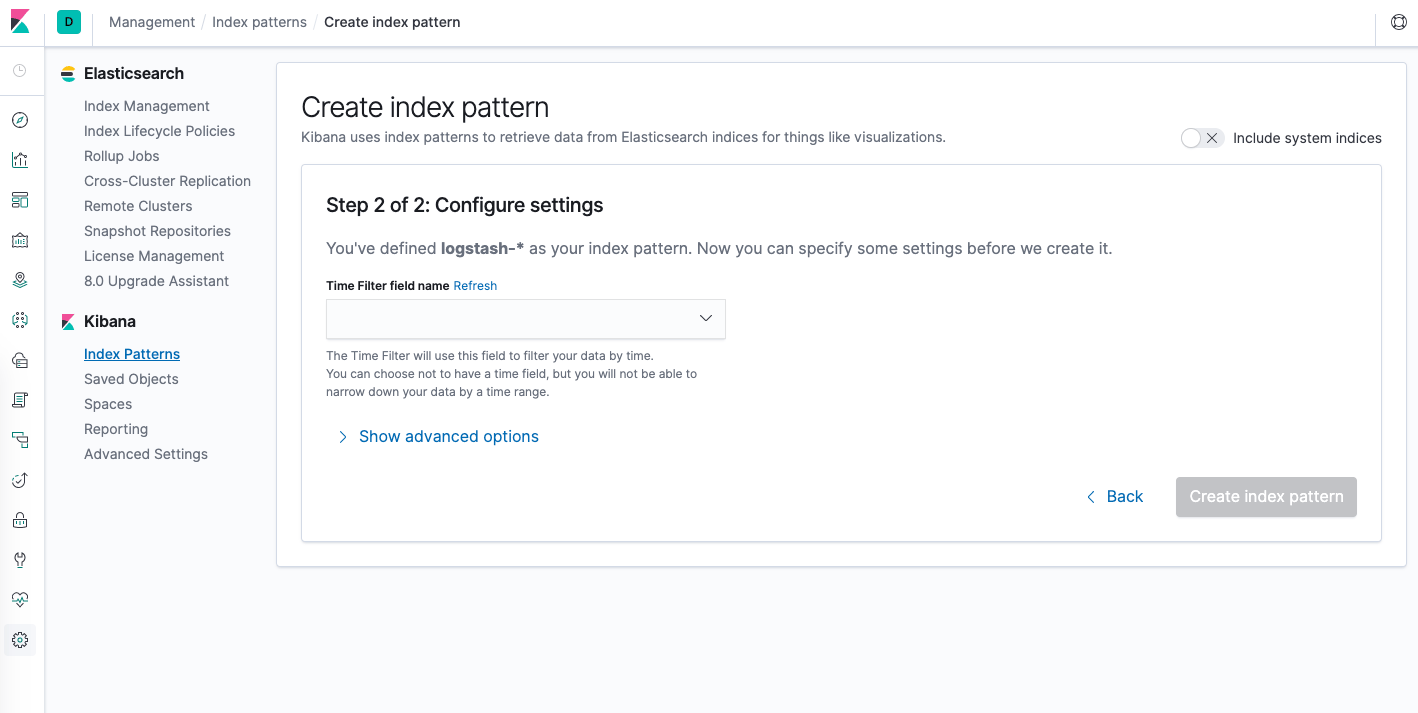
Эти настройки позволяют указать, какое поле будет использовать Kibana для фильтрации данных по времени. Выберите в выпадающем списке поле @timestamp и нажмите «Создать шаблон индекса».
Теперь нажмите Discover в левом меню навигации.
Вы увидите гистограмму и несколько последних записей в журнале:
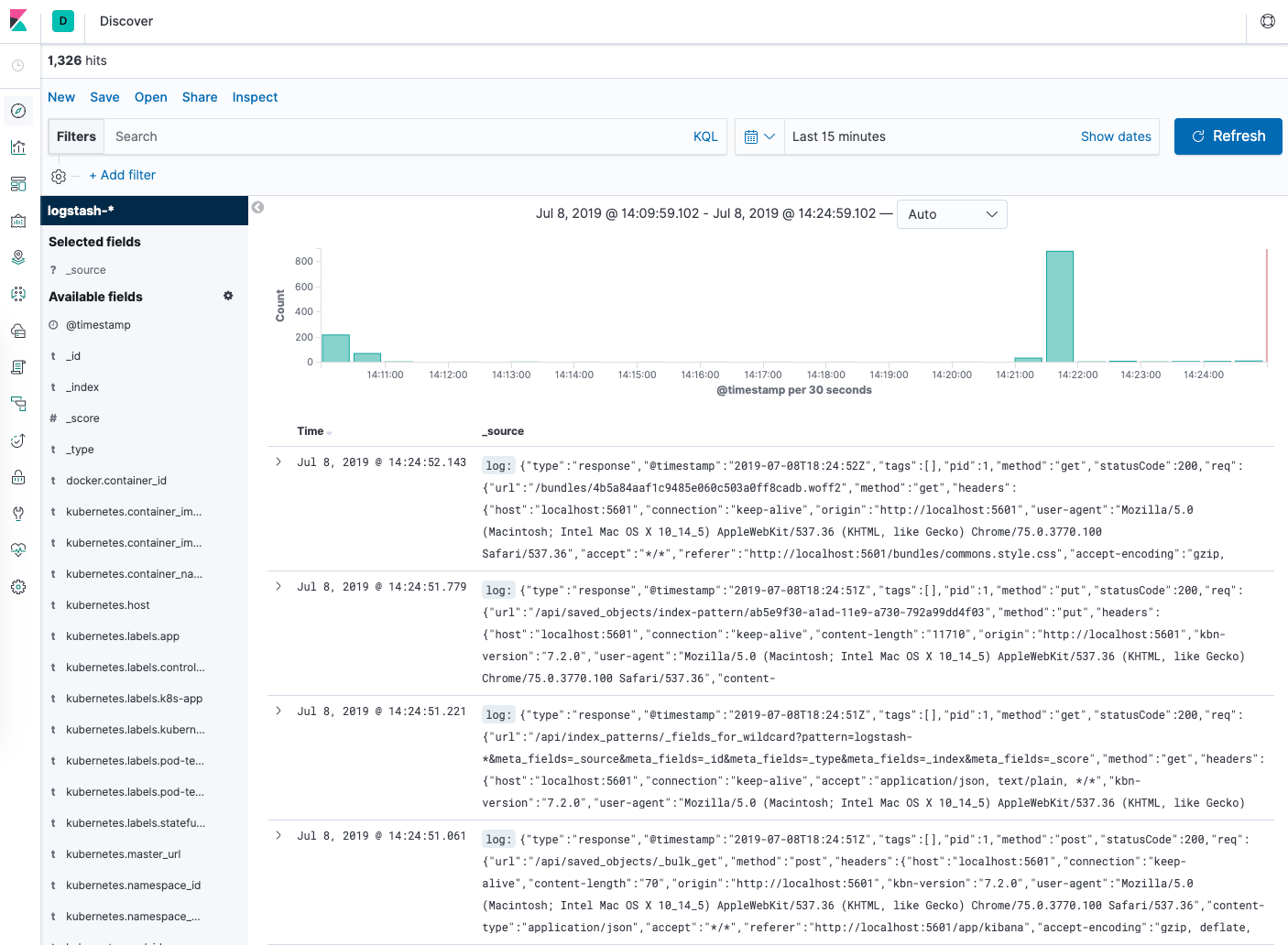
Вы успешно настроили и развернули комплекс EFK в своем кластере Kubernetes. Чтобы научиться использовать Kibana для анализа данных журнала, используйте «Руководство пользователя Kibana».
В следующем необязательном разделе мы развернем простой под счетчика, который распечатывает числа в stdout, и найдем его журналы в Kibana.
Шаг 5 (необязательный) — Тестирование регистрации данных контейнеров
Для демонстрации простого примера использования Kibana для просмотра последних журналов пода мы развернем простой под счетчика, распечатывающий последовательности чисел в stdout.
Для начала создадим под. Откройте файл с именем counter.yaml в своем любимом редакторе:
- nano counter.yaml
Вставьте в него следующую спецификацию пода:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
Сохраните и закройте файл.
Это простой под с именем counter, который запускает цикл while и печатает последовательности чисел.
Разверните под counter с помощью kubectl:
- kubectl create -f counter.yaml
Когда под будет создан и запущен, вернитесь в информационную панель Kibana.
В панели поиска на странице Discover введите kubernetes.pod_name:counter. Этот запрос отфильтрует данные журнала для пода с именем counter.
Вы увидите список записей в журнале для пода counter:
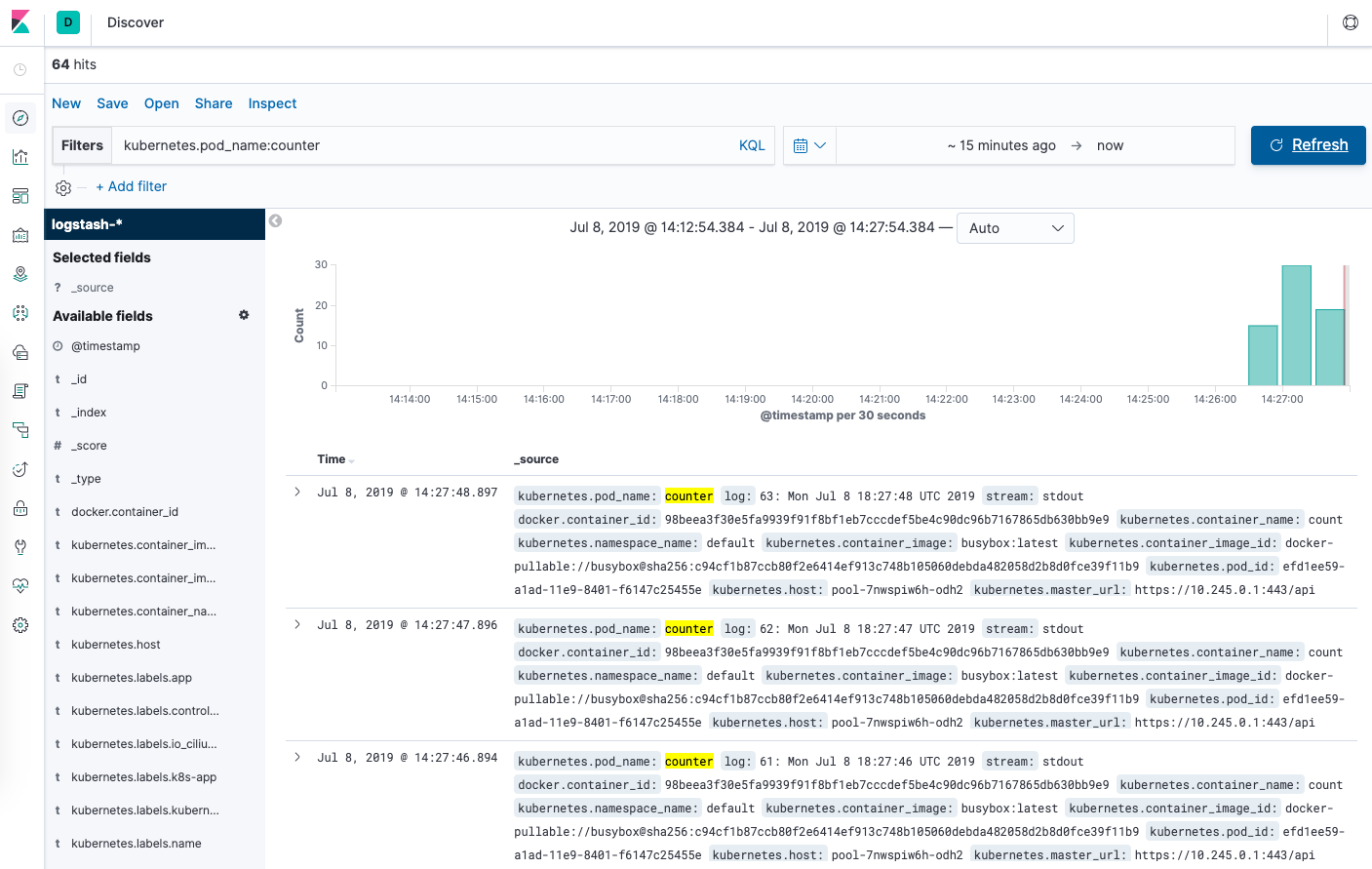
Вы можете нажать на любую запись в журнале, чтобы посмотреть дополнительные метаданные, в том числе имя контейнера, узел Kubernetes, пространство имен и т. д.
Заключение
В этом обучающем модуле мы продемонстрировали процессы установки и настройки Elasticsearch, Fluentd и Kibana в кластере Kubernetes. Мы использовали минимальную архитектуру журнала, состоящую из простого пода агента ведения журнала на каждом рабочем узле Kubernetes.
Прежде чем развернуть комплекс ведения журнала в рабочем кластере Kubernetes, лучше всего настроить требования к ресурсам и ограничения в соответствии с указаниями этого обучающего модуля. Также вы можете настроить X-Pack для поддержки встроенных функций мониторинга и безопасности.
Использованная нами архитектура ведения журналов включает 3 пода Elasticsearch, один под Kibana (без балансировки нагрузки), а также набор подов Fluentd, развернутый в форме набора демонов. При желании вы можете масштабировать эти настройки в зависимости от конкретной реализации решения. Дополнительную информацию о масштабировании комплекса Elasticsearch и Kibana можно найти в документе «Масштабирование Elasticsearch».
Kubernetes также позволяет использовать более сложны архитектуры агентов регистрации данных, которые могут лучше подойти для определенных решений. Дополнительную информацию можно найти в документе «Архитектура регистрации данных» в документации по Kubernetes.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
DevOps Engineer, Former Technical Writer and Editor at DigitalOcean. Expertise in topics including Ubuntu, Kubernetes, Docker, CentOS.
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
