AI Technical Writer

When we think of cutting-edge AI models, the first names that usually come to mind are Google, Anthropic, or OpenAI. But recently, a Chinese food delivery and restaurant review company called Meituan released LongCat-Flash. Despite not being a major tech giant, Meituan has developed an impressive open-source AI model that is slowly gaining attention for its smart design and strong performance. At its core, the model uses 560 million base parameters, but what makes it stand out is its Mixture of Experts (MoE) architecture. Instead of running every parameter for every task, the model dynamically activates only the ones it needs, ranging between 18.6 billion and 31.3 billion parameters. This makes it faster and more efficient, cutting down unnecessary computation and even reducing communication overlap. The result? It can process about 100 tokens per second while keeping costs low. Performance-wise, this model has shown it can hold its own against big names and even surpass Anthropic’s Claude in some agentic benchmarks. It’s not just powerful but also versatile: it supports multiple languages (including regional Indian ones), works well for creative writing, coding, reasoning, and even content moderation, and is open-sourced under an MIT license, making it freely available for both research and commercial use.
Key Takeaways
- LongCat-Flash Base activates fewer parameters than many larger models but still delivers top-tier performance.
- With 560B total parameters and only ~27B activated per token, it competes with other high-end models.
- Shows strong results on tough benchmarks like MMLU-Pro, logical reasoning, math, and real-world coding tasks.
- The model’s design focuses on efficiency, stability, and scalability, making training and deployment more practical.
LongCat-Flash-Chat Features
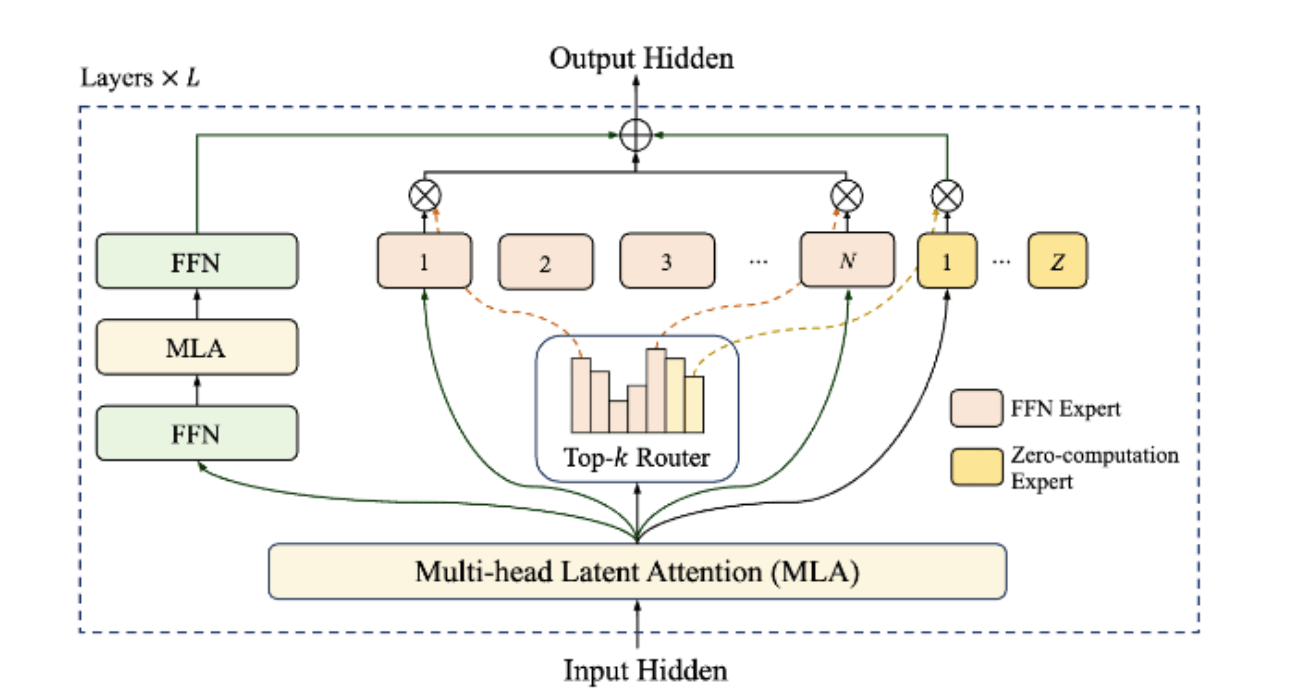
Scalable and Efficient Design
- Mixture of Experts (MoE) – Instead of using all parameters at once, the model picks only a few “experts” (specialized parameter groups) for each token. This saves computation and speeds up training/inference.
- Zero-computation experts – Not all tokens need heavy computation. The model assigns more resources to important tokens, while less important ones get minimal computation.
- Dynamic parameter activation – Out of a total 560B parameters, only 18.6B–31.3B are activated depending on the input’s complexity. On average, ~27B are active per token.
- Shortcut-connected MoE (ScMoE) – Communication between devices (GPUs/accelerators) can slow down training. ScMoE helps overlap computation with communication, reducing bottlenecks and allowing scaling to tens of thousands of accelerators.
- Result – High efficiency, faster inference, and lower latency at scale.
Smart Model Scaling
-
Hyperparameter transfer – Instead of tuning hyperparameters (like learning rate, batch size) from scratch for huge models, LongCat-Flash predicts the best settings by transferring results from smaller models. This saves time and ensures stability.
-
Half-scale checkpoint growth – The model is initialized from a smaller (half-size) trained checkpoint, which helps it learn faster and more reliably than starting fresh. Stability suite –
- Router-gradient balancing: Prevents certain experts from being overloaded.
- Hidden z-loss: Stops the model from producing extremely large activations that can destabilize training.
- Fine-tuned optimizer settings: Ensures smoother convergence.
-
Deterministic computation – Every training run produces identical results, making experiments reproducible and helping detect Silent Data Corruption (SDC), which can otherwise go unnoticed.
Multi-Stage Training for Agentic Abilities
-
Agentic capabilities – The ability to reason, plan, use tools, and interact with environments (going beyond simple Q&A).
-
Two-stage pretraining fusion – Mixes different datasets, giving more weight to reasoning-intensive domains (like math, code, logic).
-
Mid-training improvements – Expands reasoning and coding skills while also increasing context length to 128k tokens, allowing the model to handle much longer conversations/documents.
-
Multi-stage post-training – Builds stronger agentic behavior by simulating complex tasks.
-
Multi-agent synthesis framework – Creates training problems with controlled difficulty along three axes:
- Information processing – how much reasoning is required.
- Tool-set complexity – how many tools/APIs the model needs to use.
- User interaction – how interactive and dynamic the task is.
-
Result – A model that’s better at reasoning, coding, planning, and handling complex interactive tasks.
Deployment of LongCat-Flash-Chat
LongCat-Flash-Chat supports deployment on SGLang and vLLM, with basic adaptations implemented in both frameworks. For full instructions, refer to the official Deployment Guide in the LongCat-Flash-Chat repository.
Hardware Requirements:
- FP8 weights: At least 1 node (e.g., 8×H20-141G)
- BF16 weights: At least 2 nodes (e.g., 16×H800-80G)
Set up the Python Environment
Start by updating your system packages and installing essential build tools.
sudo apt update && sudo apt upgrade -y
sudo apt install -y git build-essential
Verify your NVIDIA GPU setup and CUDA installation.
nvidia-smi
nvcc --version
Upgrade pip and install uv, a faster package installer, followed by the SGLang library with all dependencies.
pip install --upgrade pip
pip install uv
uv pip install "sglang[all]>=0.5.2.rc0"
Clone LongCat-Flash-Chat Repository
Clone the official LongCat-Flash-Chat GitHub repository and navigate into the project directory.
git clone https://github.com/meituan-longcat/LongCat-Flash-Chat.git
cd LongCat-Flash-Chat
Deploy Model
SGLang Deployment
To launch the model with SGLang, you can choose between FP8 single-node or BF16 multi-node setups.
Single Node (FP8)
Run this command to deploy LongCat-Flash-Chat on a single GPU node using FP8 precision.
python3 -m sglang.launch_server \
--model meituan-longcat/LongCat-Flash-Chat-FP8 \
--trust-remote-code \
--attention-backend flashinfer \
--enable-ep-moe \
--tp 8
Multi Node (BF16)
For distributed training or inference across two nodes, use BF16 precision with tensor and expert parallelism enabled.
python3 -m sglang.launch_server \
--model meituan-longcat/LongCat-Flash-Chat \
--trust-remote-code \
--attention-backend flashinfer \
--enable-ep-moe \
--tp 16 \
--nnodes 2 \
--node-rank $NODE_RANK \
--dist-init-addr $MASTER_IP:5000
Enable Multi-Token Prediction (MTP)
Add these parameters to enable speculative decoding for faster generation.
--speculative-draft-model-path meituan-longcat/LongCat-Flash-Chat \
--speculative-algorithm NEXTN \
--speculative-num-draft-tokens 2 \
--speculative-num-steps 1 \
--speculative-eagle-topk 1
vLLM Deployment
You can also deploy LongCat-Flash-Chat using vLLM, which provides efficient inference for large models.
Single Node (FP8) vLLM Deployment
Deploy the FP8 model using tensor parallelism for high-speed inference.
vllm serve meituan-longcat/LongCat-Flash-Chat-FP8 \
--trust-remote-code \
--enable-expert-parallel \
--tensor-parallel-size 8
Multi Node (BF16) vLLM Deployment
To scale across multiple nodes, configure both the master and worker nodes as shown below.
Node 0 (master)
Run this on the main node.
vllm serve meituan-longcat/LongCat-Flash-Chat \
--trust-remote-code \
--tensor-parallel-size 8 \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-address $MASTER_IP \
--data-parallel-rpc-port 13345
Node 1 (worker)
Run this on the secondary node to join the distributed setup.
vllm serve meituan-longcat/LongCat-Flash-Chat \
--trust-remote-code \
--tensor-parallel-size 8 \
--headless \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-start-rank 1 \
--data-parallel-address $MASTER_IP \
--data-parallel-rpc-port 13345
Include the following speculative configuration for faster inference.
--speculative_config '{"model": "meituan-longcat/LongCat-Flash-Chat", "num_speculative_tokens": 1, "method":"longcat_flash_mtp"}'
Test Deployment
Finally, verify that your GPU resources are active and test the model’s inference.
nvidia-smi # Check GPU usage
python test_inference.py # Run sample prompt to verify
Performance
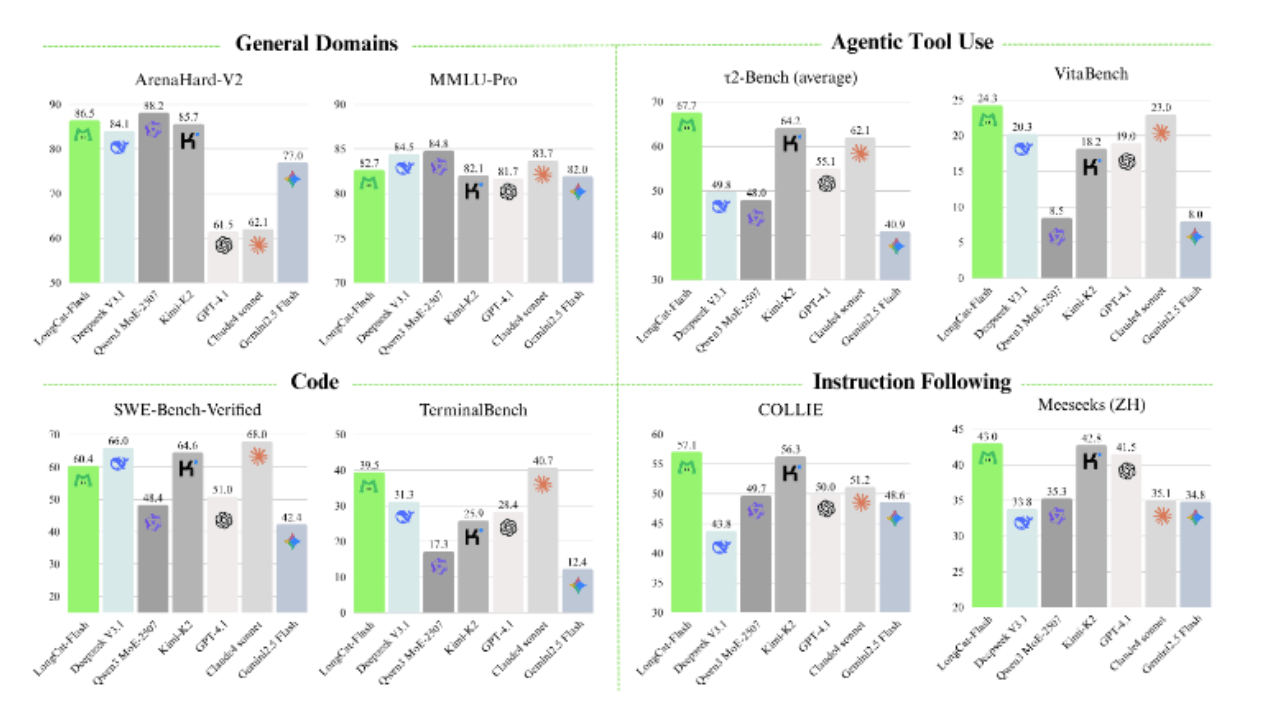
The LongCat-Flash Base model shows a remarkable parameter efficiency, achieving performance matching with or superior to much larger models despite its compact size of 560B total parameters and 27B active parameters. In general-domain benchmarks such as MMLU, CEval, CMMLU, and MMLU-Pro, LongCat-Flash Base matches or exceeds state-of-the-art models, showing a particularly strong advantage on more challenging tasks.
For reasoning tasks, it attains higher average scores than comparable models on GPQA, SuperGPQA, WinoGrande, and CLUEWSC. In mathematics and coding benchmarks, including GSM8K, MATH, MBPP+, HumanEval+, MultiPL-E, and CRUXEval, LongCat-Flash Base consistently outperforms many larger models, with only minor gaps on select benchmarks. These results are further enhanced through a multi-stage post-training process, which improves reasoning, coding, and agentic tool-use capabilities.
High-quality problem sets are generated using persona-based and self-instruct strategies for math and coding, while logical reasoning datasets are carefully curated and verified for correctness and clarity.
Additionally, the model’s agentic abilities are strengthened through a multi-agent framework that simulates complex tasks involving information processing, tool-set complexity, and interactive user reasoning.
Overall, LongCat-Flash Base delivers competitive performance across a wide range of benchmarks while maintaining a highly efficient use of parameters, making it a strong and all-rounder base model.
FAQ’s
Q1. What makes the LongCat-Flash Base model unique compared to other base models?
The LongCat-Flash Base model is designed with a Mixture of Experts (MoE) architecture, using only a few active parameters out of a total of 560B, making it significantly more parameter-efficient than other large-scale models while still delivering state-of-the-art performance.
Q2. How does LongCat-Flash Base perform in reasoning and coding tasks?
It demonstrates superior reasoning capabilities, achieving higher scores on benchmarks like GPQA, SuperGPQA, and BBH. In coding benchmarks such as MBPP+, HumanEval+, MultiPL-E, and CRUXEval, it often outperforms larger models, making it particularly strong in problem-solving and software engineering scenarios.
Q3. How does LongCat-Flash Base enhance its agentic tool-use abilities?
The model is trained with a multi-agent framework that simulates complex tasks involving tools, users, and environments. Agents like ToolSetAgent, UserProfileAgent, and InstructionAgent create realistic task scenarios, improving the model’s ability to interact strategically, process information, and solve problems with minimal user queries.
Q4. How does LongCat-Flash Base compare to DeepSeek-V3.1 and Llama-4-Maverick?
While models like DeepSeek-V3.1 and Llama-4-Maverick activate fewer parameters, LongCat-Flash Base outperforms them in most benchmarks, especially in MMLU-Pro, reasoning, math, and coding tasks, proving that efficiency does not come at the cost of capability.
Conclusion
Meituan, a Chinese company, has proved that bigger isn’t always better with the LongCat-Flash model. The best part of the model is that it focuses on using its parameters more efficiently by activating only a fraction of them while still achieving performance that matches or even surpasses much larger competitors. The model shows that smart architectural design, training strategies, and efficient scaling can deliver notable results without the need for overcomplicated computational overhead. It performs well on complex benchmarks like MMLU-Pro, logical reasoning tests, and coding challenges, all while remaining highly parameter-efficient. Its multi-stage training pipeline, which includes persona-driven problem generation, multi-agent tool simulations, and step-by-step verification, ensures that the model learns to reason, code, and interact in realistic and challenging scenarios. LongCat-Flash has set a new standard for what efficient, capable AI models can achieve. This makes it a model not just for benchmarks, but for practical use in research and industry alike.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
