AI/ML Technical Content Strategist

Multimodal generation is one of the directions every AI development seems to be trending towards. In short, this is the capacity for AI to intake and generate material from all different mediums, like audio, image, or text. We have already seen this with models like BAGEL and Ming-lite, and more prominently in the wider AI user community with GPT-4o and OpenAI’s other Omni models.
This past month, a plethora of new any-to-any models have risen to prominence for good reason. Models like Ovis U1 to Show O2 show some serious potential in this direction, for example. But the model that caught our attention the most stands out: OmniGen2.
We covered the first OmniGen at the time of its release in 2024, and have been watching closely for the next iteration of the project. This any to any model differs from the original by relying on two distinct decoding pathways for text and image modalities, utilizing unshared parameters and a decoupled image tokenizer. In practice, this gives it capabilities in domains like image understanding, image generation, image editing, and in-context generation (combining inputs across modalities).
In this article, we discuss how OmniGen2 works under the hood before jumping into a coding demo using a DigitalOcean GPU Droplet. Follow along for tips on using the model to its fullest potential.
OmniGen2: Under the Hood
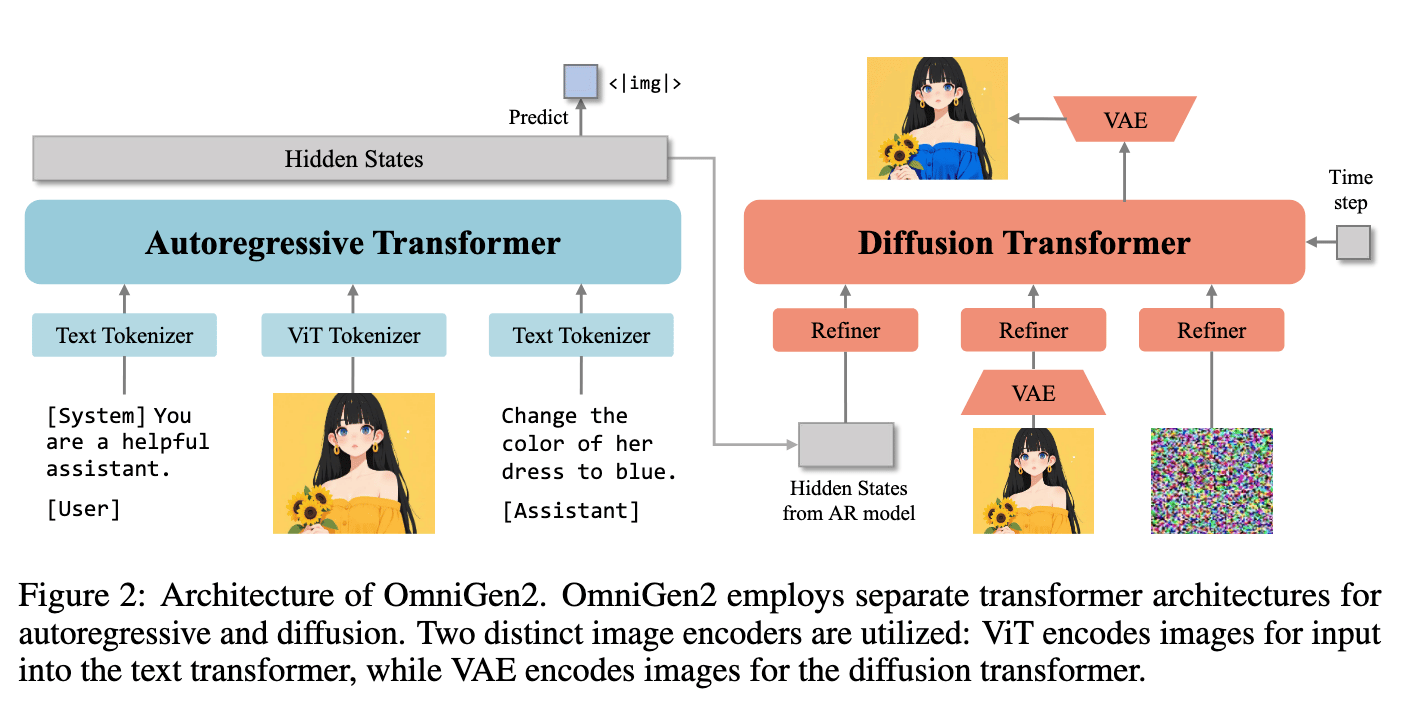
The architecture of OmniGen2 is an evolution from its predecessor in a number of ways. First, unlike OmniGen, OmniGen2 relies on a decoupled diffusion process with randomly initialized parameters. In practice, the image and text data are input to an autoregressive transformer module. The hidden states from the AR model are then input to a separate diffusion transformer to generate the output. To facilitate this, they use distinct, separate image encoders for each stage. The Vision Transformer (ViT) Tokenizer encodes images for input into the text transformer, while the Variational AutoEncoder (VAE) simultaneously encodes the images for the diffusion transformer. It leverages the hidden states of the multi-modal interleaved conditions produced by the Multimodal LLM, instead of relying on a fixed set of learnable query tokens, as input to the diffusion decoder.

To facilitate this encoding, they use Omni-RoPE for Multimodal Rotary Position Embedding, illustrated above. “It decomposes position information into three components: (1) a Sequence and Modality Identifier (idseq) that is constant for all tokens within a single image (treating it as a semantic unit) but unique across different images; and (2) and (3) 2D spatial coordinates (h, w) that are locally computed from (0,0) for each image entity.” (Source) In practice, this is what allows the model to edit the image input by modifying the spatial coordinates.
Now let’s look at how to run OmniGen2 on a DigitalOcean GPU Droplet.
Running OmniGen2 on a DigitalOcean GPU Droplet
To run OmniGen2, we need an appropriately powerful GPU. For this, we recommend using a GPU Droplet powered by either an NVIDIA H100 or AMD MI300X GPU. For this tutorial, we will rely on the CUDA infrastructure for installation. There may be some different steps required for installing the required libraries with AMD and ROCm.
To get started, spin up your GPU Droplet and set up the environment according to the instructions laid out in this article. Once that’s completed, clone the repo into the repository and install the required packages. You can do this using the following shell commands in the terminal.
git clone https://github.com/VectorSpaceLab/OmniGen2
cd OmniGen2
python3 -m venv venv_omnigen2
source venv_omnigen2/bin/activate
pip install -r requirements.txt
Once that is completed, we can use the OmniGen2 Gradio application to get started! Simply run the code below to launch the application.
python3 app.py --share
This process will take a few minutes as it downloads and loads the model. Use the outputted shared URL link to continue into the web demo on any browser with web access. This will take you to a page that looks like this:
From here, we are ready to get started!
Using OmniGen2 to Edit photos
OmniGen2 is incredibly capable with single and multi-photo inputs at generating high quality images with respect to both the original input image and text prompt. It can edit single images, combine images, unify concepts and objects across multiple images, and much more.
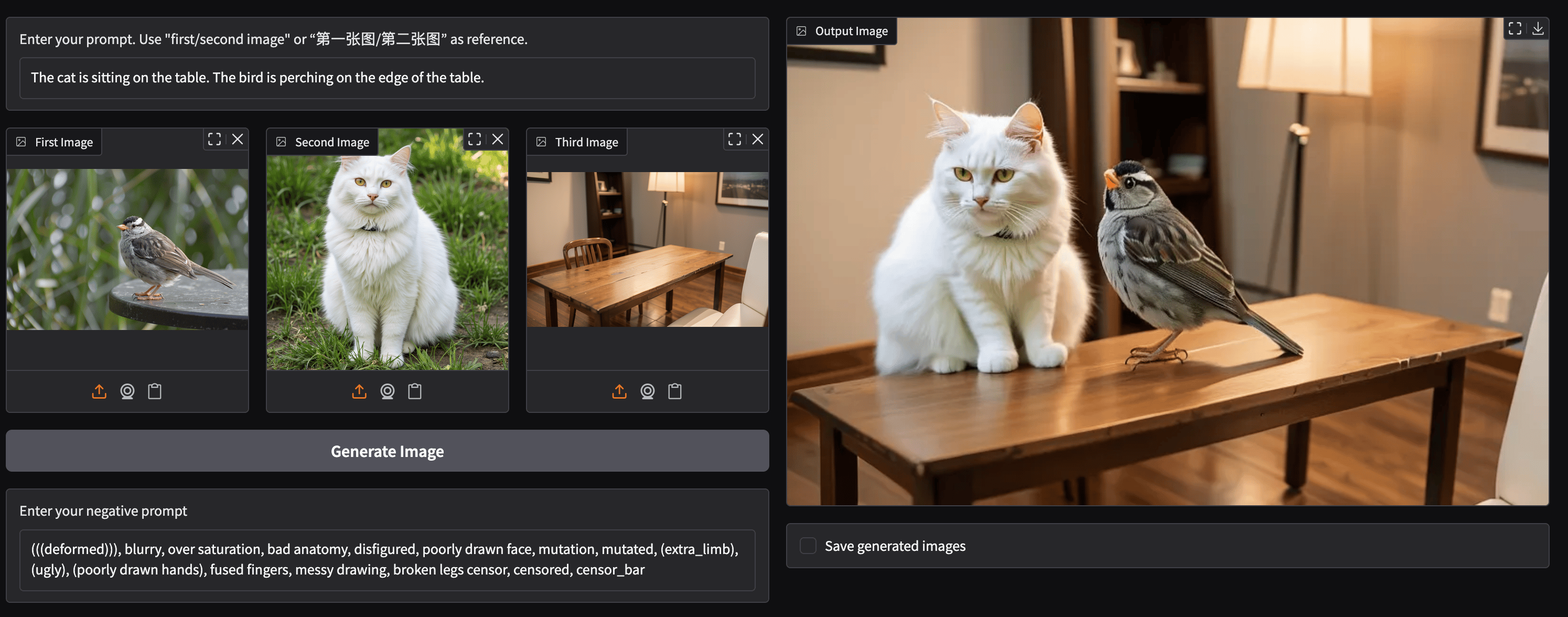
We recommend using any of the 4 pages of provided examples to really showcase the capability of OmniGen2. For example, the very final example combines concepts from three images into a single output, and impressed us very much.
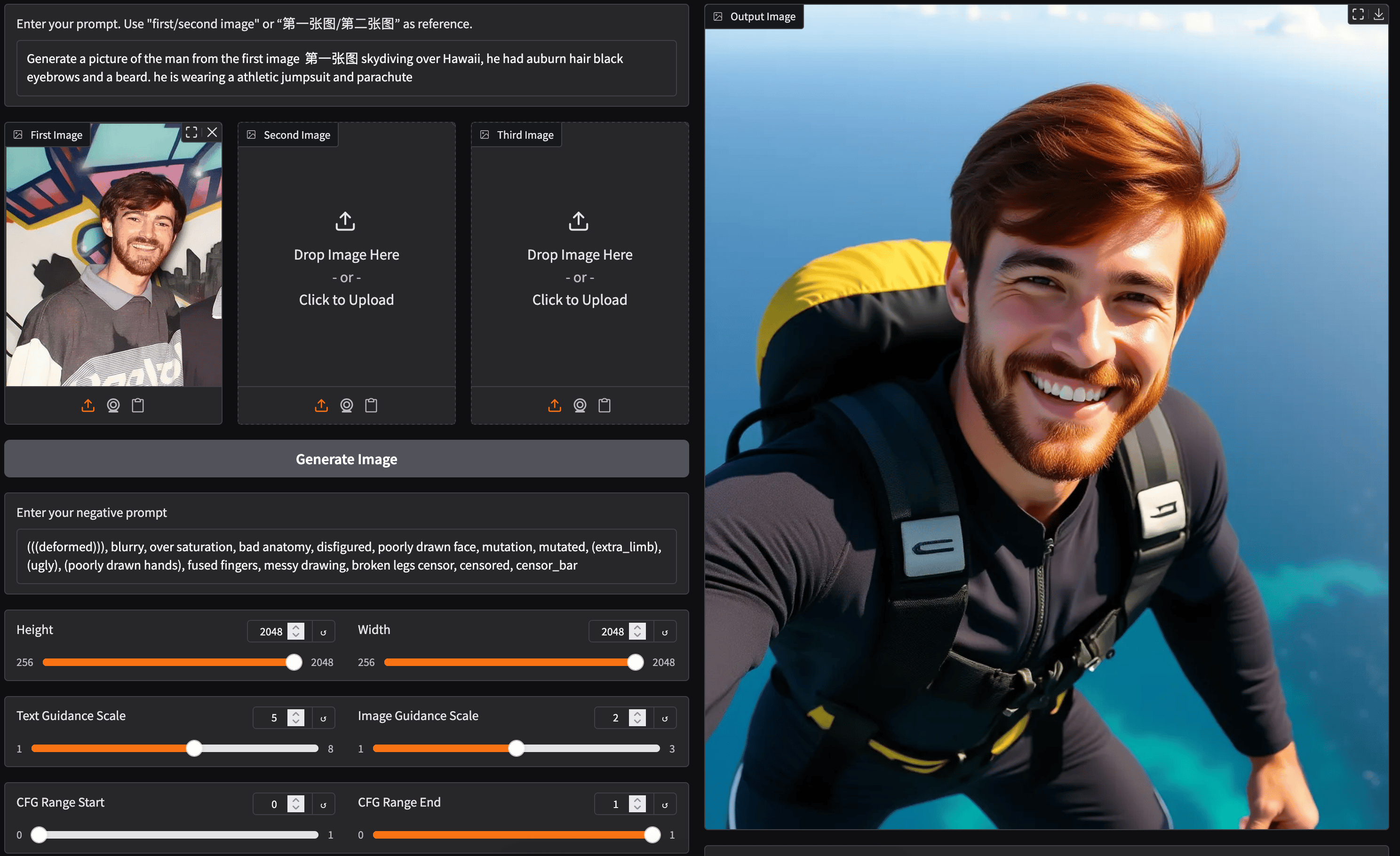
When working on our own images, we have a few suggestions for getting the best results. First, use the highest quality image inputs as possible. This will ensure that as many details from the original input are captured. Next, use the highest quality text inputs as possible. This may seem simple, but we recommend being as detailed as possible and using clear language. It will really make a noticeable difference. Finally, don’t hesitate to adjust the advanced settings. The model scales up to 2048 x 2048, but the graphical fidelity at that scale is noticeably reduced. We found 512 - 832 pixels to be the best range for width and height. We can also raise the number of inference steps (and adjust the Scheduler type) to get more accurate results, as needed.
Closing Thoughts
All together, OmniGen2 is an awesome image and text generation VLLM. In our experiments, it is more capable than even BAGEL at image editing tasks. We were very impressed with how it performed compared to premier editing models like Flux Kontext and GPT-4o, and look forward to the next iteration of this experiment as it develops.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
