Technical Evangelist // AI Arcanist

One of the greatest challenges any new user of large scale LLM technology needs to consider is always going to be computation. From the VRAM to the throughput to the underlying technology and software, there are so many differences between different machines that it can be genuinely dizzying. When deploying LLMs, this can be even more apparent. At the end of the day, we want to get the best quality at a low cost, and it’s striking the balance where we find the true source of the challenge.
Today we are going to examine this more closely with a look at AMD Instinct’s MI300X GPU running GPT-OSS 120b. This powerful machine is one of the flagship processing units from AMD, and it is truly beefy and fast. With a whopping 192 GB of HBM3 memory, it is capable of processing 653.7 TFLOPs to create an overall, max, theoretical throughput of 5.3 TB/s. This awesome power makes it an ideal machine for testing LLMs, and we are going to use OpenAI’s GPT-OSS 120b for the example. This powerful language model has made big waves recently for its robust agentic and coding capabilities, making it perfect for demonstrating the awesome power of the machine.
Follow along in this tutorial for a deep dive into using vLLM with AMD GPUs. Readers can expect to leave with a full understanding of vLLM, GPT-OSS, and each step required to run GPT-OSS 120b using vLLM on a Gradient AMD powered GPU Droplet.
Key Takeaways
- vLLM is a powerful open source tool for serving LLMs at scale using AMD GPUs on the Gradient cloud
- GPT-OSS 120b is perhaps the most powerful open-source agentic coding LLM, and we recommend using it with vLLM to efficiently serve the model
- Gradient GPU Droplets powered by the AMD MI300X GPU are ideal for serving GPT-OSS 120b at scale
What is vLLM
vLLM is an open-source, high-performance inference engine designed to serve large language models (LLMs) with exceptional speed and memory efficiency. By optimizing GPU memory utilization, vLLM delivers faster responses, higher throughput, and reduced latency than many competitive resources. Its core innovations include the PagedAttention algorithm, support for continuous batching, and smooth compatibility with popular model ecosystems such as Hugging Face. We recommend VLLM because of these features.
Why Use GPT-OSS
GPT-OSS (20b and 120b) is the flagship open source LLM release from OpenAI, released earlier this year. The two variants are each some of the most powerful agentic and coding models released in their size class. Notably, at the time of release, GPT-OSS 120b was competitive with the o4 Mini model on established benchmarks for reasoning, and the 20b variant was comparable with o3 mini on common benchmarks while running on edge devices with only 16gb of virtual memory.
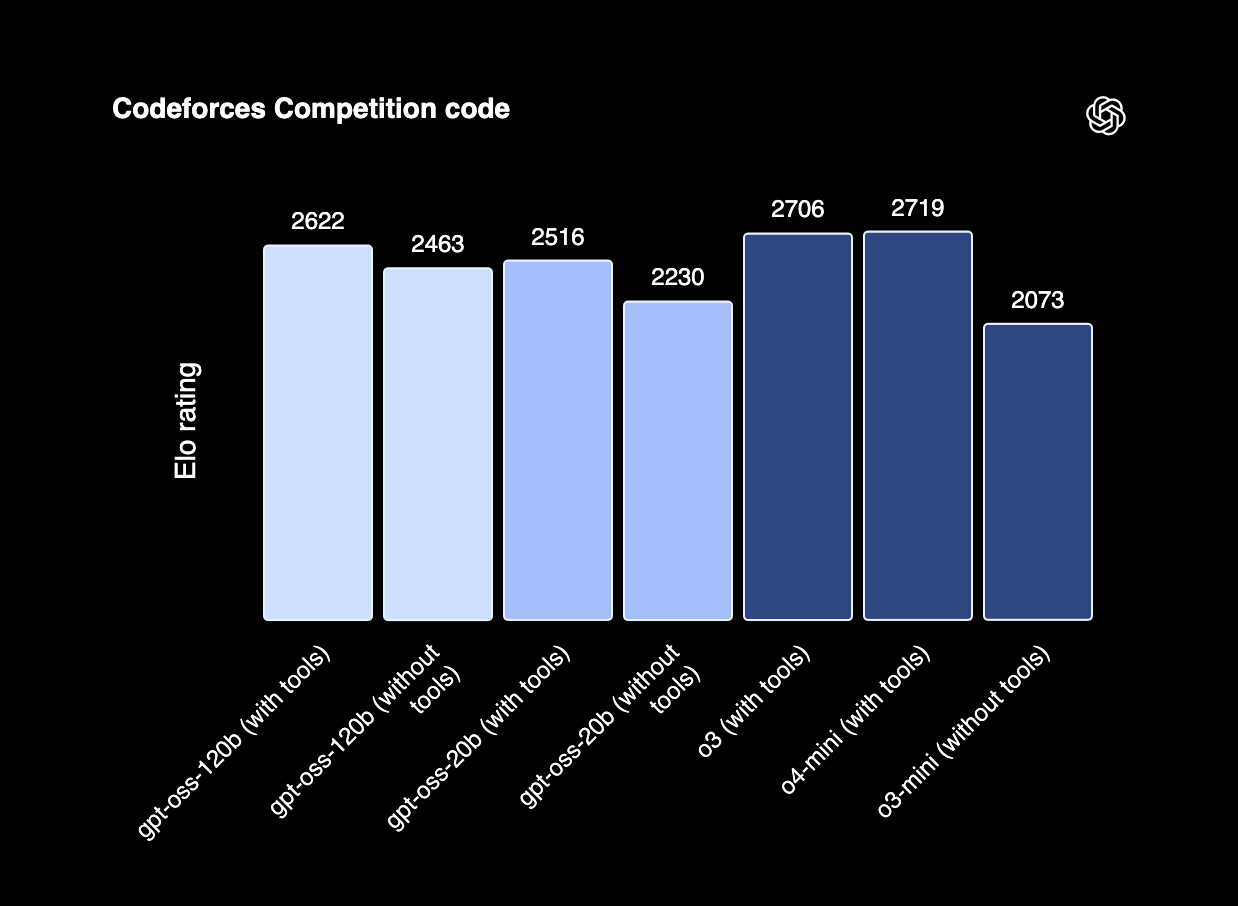
The reasons we recommend using GPT-OSS 120b are its open-source, Apache 2.0 license, making it easy to fine-tune for various tasks and use in any context, and its SOTA capabilities in reasoning and coding tasks. As we can see from the results above, the model scores comparably with the flagship o3 reasoning model and o4-Mini reasoning models with tools in the codeforces benchmark. For these reasons, GPT-OSS 120b is a great starting place for any user on running coding models with VLLM.
Running vLLM on an AMD Powered GPU Droplet
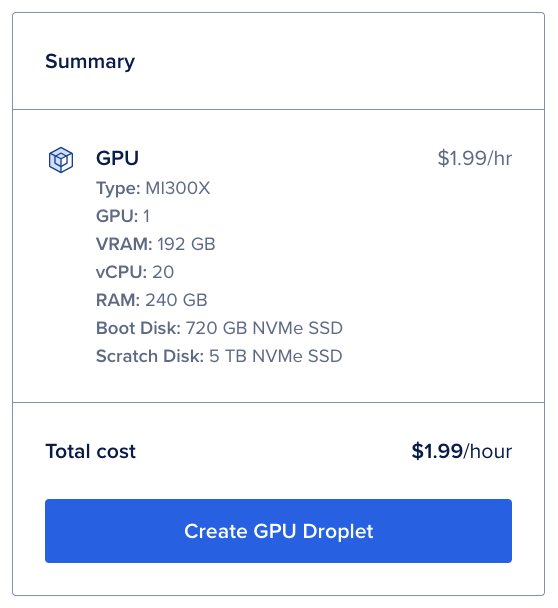
To get started, we are going to spin up our MI300x powered GPU Droplet. Log into your DigitalOcean account, and select the GPU Droplets link on the left-hand sidebar. Once in the creation window, select the ATL datacenter. This is currently the only resource with the AMD GPUs at the moment. Scroll down, and select “AMD” under GPU Platform. Then, select the single MI300X GPU. Finally, select your SSH key from the listed ones available for your team. With that, you are ready to create the droplet!
Click “Create GPU Droplet” in the top right corner to launch the GPU Droplet. It may take a few moments for the GPU Droplet to spin up.
Setting Up the Environment for on vLLM with Docker
Once the GPU Droplet is ready to go, SSH into your machine using your local terminal. From there, you want to navigate to the directory of your choice to work in. We can then get started with VLLM using Docker.
Deploying GPT-OSS on vLLM
First, we are going to use an alias for the deployment to download and start running the Docker container. Paste the following command into the terminal to get started. This container will only work on an MI300X GPU.
alias drun='sudo docker run -it --network=host --device=/dev/kfd --device=/dev/dri --group-add=video --ipc=host --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --shm-size 32G -v /data:/data -v $HOME:/myhome -w /myhome'
drun rocm/vllm-dev:open-mi300-08052025
This will take a little while to download and get started. Once done, you should be inside the container. From here, we can deploy our GPT-OSS 120b model on VLLM. Paste the following into the terminal to serve the model on our AMD MI300X powered GPU Droplet.
export VLLM_ROCM_USE_AITER=1
export VLLM_USE_AITER_UNIFIED_ATTENTION=1
export VLLM_ROCM_USE_AITER_MHA=0
vllm serve openai/gpt-oss-120b --compilation-config '{"full_cuda_graph": true}'
This will launch the VLLM deployment, starting by downloading the model files onto the container. If everything is running correctly when it is done, then we should get a message saying so that corresponds to the screenshot above. From there, we can interact with the served model at “0.0.0.0:8000” or “localhost:8000” using OpenAI’s Python library.
Interacting with the Deployed GPT-OSS 120b model
From here, we need to figure out how we can interact with our deployed model to actually make use of it. There are a few clear methods, but we are going to outline two in this section: using cURL and OpenAI’s Python library. First, let’s look at cURL. Open a new terminal window, and SSH into the remote machine. Once inside, paste the following code into the terminal. We are going to use this example to ask the model for a simple task: telling a joke.
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-oss-120b",
"messages": [
{ "role": "system", "content": "You are a helpful assistant." },
{ "role": "user", "content": "Tell me a joke." }
],
"temperature": 0.7,
"max_tokens": 100
}'
This should return something like:
{"id":"[anonymized]","object":"chat.completion","created":1762542942,"model":"openai/gpt-oss-120b","choices":[{"index":0,"message":{"role":"assistant","content":"analysisUser asks for a joke. Provide a joke. Keep it appropriate.assistantfinalSure, here's a classic one for you:\n\n**Why don’t scientists trust atoms?**\n\n*Because they make up everything!*","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning_content":null},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":85,"total_tokens":134,"completion_tokens":49,"prompt_tokens_details":null},"prompt_logprobs":null,"kv_transfer_params":null}root@ml-ai-ubuntu-gpu-mi300curl http://localhost:8000/v1/chat/completions \hat/completions \
We can use this methodology to do a number of different things, like code completion, tasks with tool calling, and complex function calling. Test this out with your own prompts to see how powerful the model is!
If you prefer working with Python code, we recommend using OpenAI’s Python library to do so. Using the separate window from our running VLLM server, launch a Jupyter Lab window. Paste the following code into your terminal to get started. It will install everything needed to run the next bit of code.
python3 -m venv venv
source venv/bin/activate
pip install openai jupyter
jupyter lab --allow-root
Use Cursor or VS Code’s simple browser feature to then access the window on your local browser (for more detailed instructions, see the tutorial guide inside). Once that’s spun up, open a new Jupyter Notebook and access it. Then, in the first coding cell, paste the following Python code.
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."},
]
)
print("Chat response:", chat_response)
Once again, if everything is working, you should get an output like the following:
Chat response: ChatCompletion(id='chatcmpl-b600ce13dfd041a4a934ebe7826c8a44', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='analysisThe user wants a joke. Provide a joke. Should be appropriate. Simple.assistantfinalWhy don’t scientists trust atoms?\n\nBecause they **make up** everything!', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=[], reasoning_content=None), stop_reason=None)], created=1762543674, model='openai/gpt-oss-120b', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=41, prompt_tokens=85, total_tokens=126, completion_tokens_details=None, prompt_tokens_details=None), prompt_logprobs=None, kv_transfer_params=None)
With this Python implementation, it’s possible to integrate VLLM interaction into any number of applications and workflows, including custom agents. We find this approach to be just as versatile and functional as cURL because we can take advantage of the wide variety of Python packages and tools available.
Closing Thoughts
vLLM with GPT-OSS is relatively straightforward to run on AMD MI300X powered GPU Droplets, thanks to the hard work of the vLLM and ROCm communities. With the simplicity of GPU Droplets, users can launch this powerful model in just minutes on the best hardware available.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and SMBs
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Get started for free
Sign up and get $200 in credit for your first 60 days with DigitalOcean.*

*This promotional offer applies to new accounts only.