AI/ML Technical Content Strategist

Serverless inference is, rightfully, one of the hottest topics in both technical and non-technical circles of AI users, and for good reason. While controlling every aspect of a deployment is often necessary for deploying custom models, serverless takes away the headaches of maintaining and managing a model deployment and API endpoint. This can be incredibly useful for a myriad of different agentic LLM use cases.
In this tutorial, we will show how to get started with Serverless Inference on the DigitalOcean AI Platform using the DigitalOcean API. Afterwards, we will discuss some of the potential use cases for the methodology in production and daily workflows.
Accessing Serverless Inference on the AI Platform
To get started, we can either use the DigitalOcean API or the Cloud Console. Let’s look at each methodology.
Step 1a: Create a DigitalOcean API Key
To get started, you first need to create your own DigitalOcean account and login. Once you’ve done so, navigate to the team space of your choice. From here, we will create a DigitalOcean API key. This will help us create our model access token later on, so we can actually skip this step and go to the section “Step 2b: Create a Model Access key with the Cloud Console”.
Use the navigation bar on the left hand side of the homepage, and scroll down until you see “API”. Click in to open the API homepage. We can then use the button on the top right to create a new key.
In the key creation page, name your key as needed and give appropriate permissions. To do this, either give full permission or scroll down to “genai” in the custom scope selection and select all. Then, create the key. Save this value for later.
Step 2A: Create a Model Access key with the API
Next, we are going to make our model access key for Serverless Inference on the AI Platform. To do so, we can either use the console or API. To use the API, use the saved API key from earlier with the following curl request in your terminal. Replace the value for “$DIGITALOCEAN_TOKEN” with your own.
curl -X POST -H 'Authorization: Bearer $DIGITALOCEAN_TOKEN' https://api.digitalocean.com/v2/gen-ai/models/api_keys
This will output our model access key. Save this value for later. We will need it to query the model.
Step 2B: Create a Model Access key with the Cloud Console
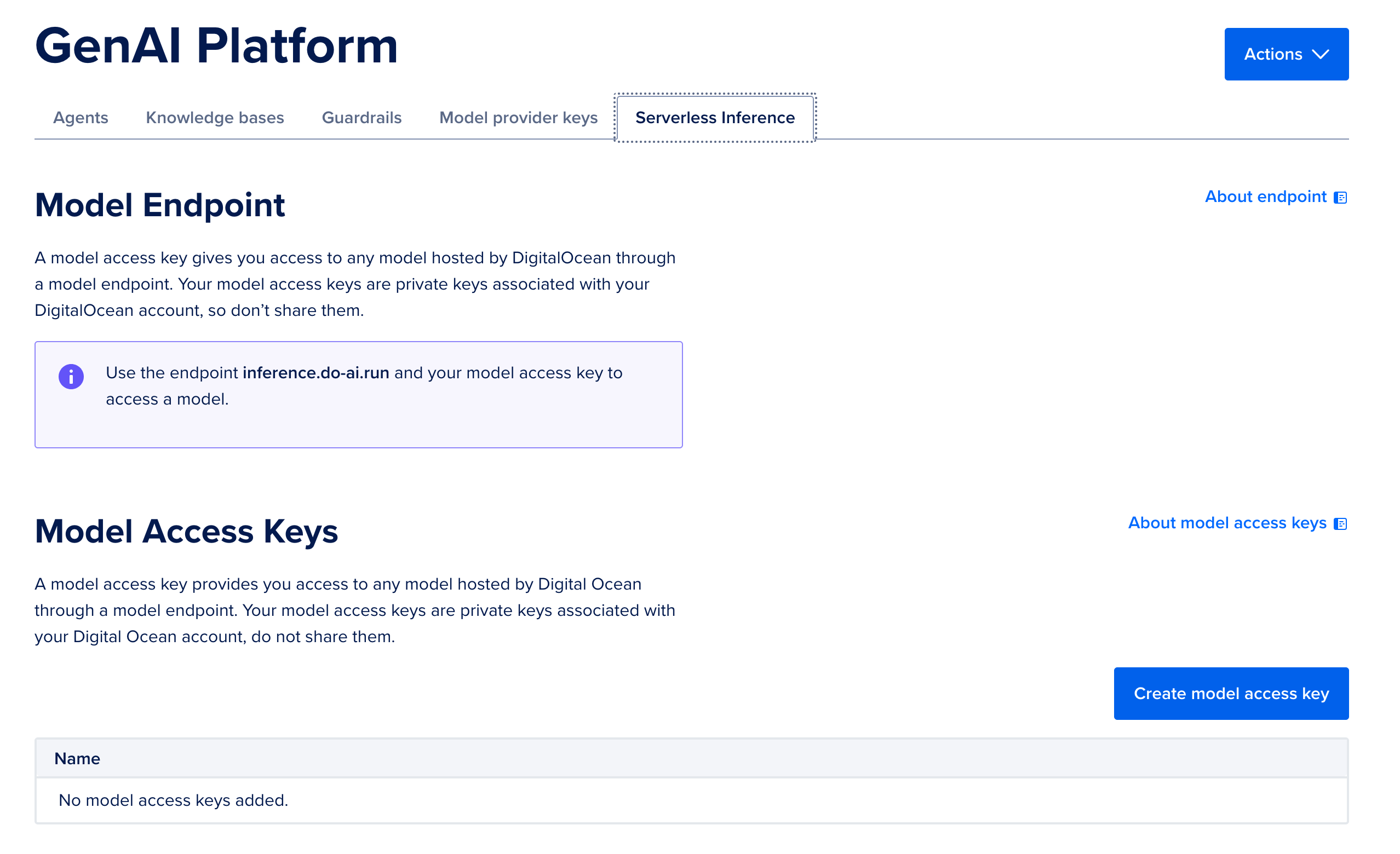
If we want to use the console, simply navigate to the AI Platform Serverless Inference tab in the Console. Once there, use the button on the bottom right to “Create model access key”.

Then, all we have to do is name our key. Save the output value for later! We will need it for Serverless Inference with Python.
Step 3: Generating Text with Python and Serverless Inference
With our new model access key, we can begin running DigitalOcean Serverless Inference from any machine with internet access! We recommend working from a Jupyter Notebook. Follow the steps outlined in this tutorial for tips on setting up your environment for this article.
Once your env is set up, open a new .ipynb IPython Notebook file. Use the code snippet below to begin generating text, specifically answering what the capital of France is. Edit the snippet to reflect your changed API key value on line 5.
from openai import OpenAI
import os
client = OpenAI(
api_key= **“your_model_access_key_here”**,
base_url="https://inference.do-ai.run/v1"
)
stream = client.chat.completions.create(
model="llama3-8b-instruct",
messages=[
{
"role": "developer",
"content": "You are a helpful assistant.",
},
{
"role": "user",
"content": "What is the capital of France?",
},
],
stream=True,
max_completion_tokens=10
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
This should produce the output “The capital of France is Paris”. We recommend changing the values like max_completion_tokens to better suit your prompt as needed. We can also edit the model value on line 10 to be any of the available models listed in the DigitalOcean AI Platform model offerings. This model zoo is constantly being updated to reflect the growing industry, so check back frequently for updates.
Use cases for Serveless AI from DigitalOcean
Now that we have set up our environment to run Serverless Inference, we have a plethora of possible activities we can use the model for. From everything an LLM is capable of, we can create powerful agentic applications that leverage the strength of the AI model. Some possible use cases for this include:
- Event driven applications: Where a specific occurrence triggers the run of the LLM, this is common in agentic use cases
- Scalable backend services: When the inference on the backend may need to be scaled indefinitely, serverless can guarantee that your users will never be left waiting
- Data processing: batch jobs and data processing can be handled effectively and efficiently without requiring costly setup Source
- And much more!
Closing Thoughts
Serverless Inference is a true answer for companies seeking LLM based solutions without the hassle of hiring or learning the required steps to deploying your own server. With DigitalOcean’s AI Platform, accessing Serverless Inference from powerful NVIDIA GPUs just became easier than ever! We encourage everyone to try the new solution!
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
