Engineer & Writer

AI has significantly reduced the time taken to build projects from scratch. At DigitalOcean, we are constantly working on code-first projects that can help you build production-ready applications and also extend them to your own needs.
Last month we announced the SeaNotes Starter Kit, and this month we are excited to introduce agent templates.
In this article, you will learn how you can extend the SQL agent template to enable synthetic query generation that creates safe mock datasets and suggests insert scripts without touching production data.
Here’s how it works:

Key-takeaways
After reading this article you will learn how to:
- Use agent templates and extend it for your own use-case
- How you can add agentic capabilities to your applications using DigitalOcean’s Gradient AI platform.
What are agent templates?
Agent Templates are code-first, plug-and-play starter kits built for use on DigitalOcean’s Gradient AI Platform. Each template is a Python-project you can clone, configure, and deploy within minutes.
Here are the templates that are available currently:
| Template | Capabilities | Key Technical Features |
|---|---|---|
| LLM Auditor Agent | Adds a verification or fact-checking layer to an LLM, by searching the web (via the Tavily API) and optionally grounding using structured external knowledge. | • Integrates with Tavily API • Supports optional knowledge-base (KB) grounding for more reliable responses |
| Product Documentation Agent | Builds a support chatbot using your product docs so users can ask questions and get accurate answers from documentation. | • Embedding-based document retrieval • Chat history / conversation context support • Works off arbitrary product docs you supply |
| SQL Agent | Translates natural language prompts into SQL queries (read-only) against a MySQL database, retrieving schema dynamically and executing safe queries. | • Schema introspection to know table/column structure • Guards to enforce read-only queries • Natural language to SQL translation with safety checks |
| Twilio API Agent | Facilitates sending SMS (marketing or transactional) via Twilio, with logic to automate messaging flows. | • Twilio SDK/API integration • Pluggable messaging logic • |
You can either use these templates as it is or extend it for your own use.
How the Synthetic Data Generation Service Works
The synthetic data generation service is built to create realistic mock datasets for testing and development. It uses the following four layers in an orchestrated microservices architecture: When someone clicks the “Generate Data” button or types a natural language request like “Generate 10 mock users”, here’s what happens:
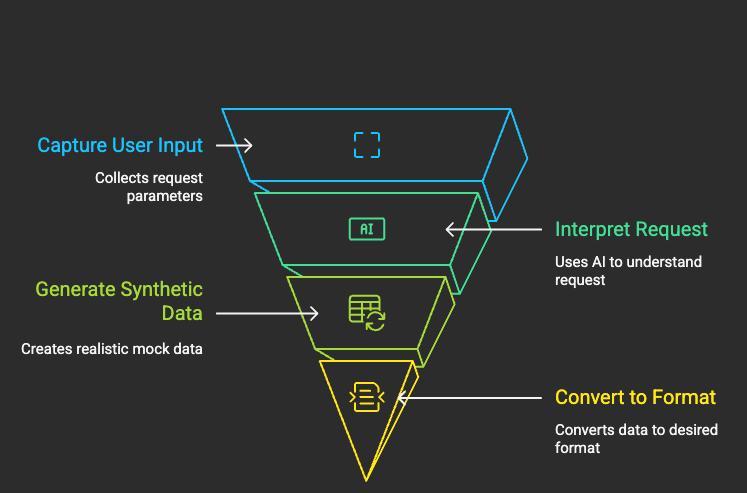
1. User Input Processing Layer: Captures the user’s request through either the chat interface or manual configuration, extracting parameters like data type, record count, and output format.
2. AI-Powered Request Interpretation Layer: Uses DigitalOcean’s Gradient AI Platform to understand natural language requests and determine the appropriate data generation strategy, including safety validation to ensure no production data is accessed.
3. Synthetic Data Generation Engine: Takes the interpreted request and uses the Faker library to create realistic mock data with proper field types, relationships, and constraints. This engine can generate users, orders, payments, products, and custom schemas.
4. Multi-Format Output Layer: Converts the generated data into the requested format (SQL INSERT statements, CSV, or JSON) and presents it to the user with download options and real-time preview.
Detailed Data Flow
Here’s exactly what happens when a user requests “Generate 10 mock users with random names and emails”:
1. User Input Processing: The Streamlit interface captures the request and extracts parameters (count=10, data_type=users, fields=[‘name’, ‘email’])
2. AI Request Interpretation: The Gradient AI agent processes the natural language request and determines it needs to generate user data with specific field requirements
3. Data Generation Engine: The SyntheticDataGenerator creates 10 realistic user records using Faker: - Generates realistic names like “John Smith”, “Sarah Johnson” - Creates valid email addresses like john.smith@email.com - Adds phone numbers, addresses, and timestamps - Ensures data relationships and constraints are maintained
4. Format Conversion: The system converts the generated data into the requested output format: - SQL: Creates INSERT statements ready for database execution - CSV: Formats data for spreadsheet import - JSON: Structures data for API consumption
5. Safety Validation: All generated data is validated to ensure: - No production data is accessed - SQL injection prevention - Record count limits are respected - Data integrity is maintained
6. User Presentation: The final data is displayed in the web interface with: - Real-time preview table - Download buttons for each format - Copy-to-clipboard functionality - Success confirmation messages
Build the generator
Step 1 - Setting Up DigitalOcean Gradient AI Credentials
Before extending the SQL Agent template, you need to set up your DigitalOcean Gradient AI credentials. This is essential for the AI-powered natural language processing capabilities.
- Sign up for a DigitalOcean account at cloud.digitalocean.com
- Go to Agent Platform section in your DigitalOcean dashboard
- Create a new workspace or use an existing one and create an agent. You can follow the steps mentioned in this guide to creating an agent.
- After the agent has been created, go to your Gradient AI workspace settings, get the access token for API access and note down your workspace ID
This is what the DigitalOcean Gradient AI agent looks like in the console:

Step 2 - Extending the SQL Agent Template
Next up, we extend the DigitalOcean SQL Agent template with synthetic data generation capabilities. The base template provides safe SQL query execution and schema introspection, which we enhance with data generation features.
Core Extension Architecture:
The enhanced SQL agent extends the base template by integrating a synthetic data generator and updating the system prompt to handle data generation requests. It maintains all original SQL capabilities while adding natural language processing for data generation commands. Find the entire code in src/agent.py.
Step 3 - Building the Synthetic Data Generation Engine
The heart of our extension is the SyntheticDataGenerator class, which creates realistic mock data using the Faker library. It supports multiple data types (users, orders, payments, products) with configurable parameters and realistic field generation.
class SyntheticDataGenerator:
def __init__(self, locale='en_US'):
self.fake = Faker(locale)
def generate_users(self, count=10, fields=None):
users = []
for i in range(count):
user = {
'id': i + 1,
'name': self.fake.name(),
'email': self.fake.email(),
'phone': self.fake.phone_number(),
'address': self.fake.address(),
'created_at': self.fake.date_time_between(start_date='-2y', end_date='now')
}
users.append(user)
return users
def generate_orders(self, count=10, amount_range=(10, 1000), year=2024):
orders = []
for i in range(count):
order = {
'id': i + 1,
'user_id': self.fake.random_int(min=1, max=count),
'amount': self.fake.random_int(min=amount_range[0], max=amount_range[1]),
'status': self.fake.random_element(elements=('pending', 'completed', 'cancelled', 'shipped')),
'order_date': self.fake.date_between(start_date=f'{year}-01-01', end_date=f'{year}-12-31'),
'product_name': self.fake.catch_phrase(),
'quantity': self.fake.random_int(min=1, max=10)
}
orders.append(order)
return orders
Find the entire code in src/synthetic_data_generator.py.
How the data generation works:
1. Faker Library Integration: Uses the Faker library which provides over 200+ data providers for generating realistic fake data including names, addresses, emails, phone numbers, dates, and more.
2. Configurable Field Generation: Each data type (users, orders, payments, products) has specific field generators that create realistic relationships and constraints.
3. Locale Support: Supports multiple locales (en_US, en_GB, etc.) to generate region-appropriate data.
4. Parameterized Generation: Accepts parameters like count, date ranges, amount ranges, and field selections to customize the generated data.
Step 4 - Implementing Multi-Format Output Support
The system converts generated data into multiple formats for different use cases. Here’s how the SQL conversion works:
def to_sql_inserts(self, data, table_name):
if not data:
return []
columns = list(data[0].keys())
column_str = ', '.join(columns)
insert_statements = []
for record in data:
values = []
for col in columns:
value = record[col]
if value is None:
values.append('NULL')
elif isinstance(value, str):
escaped_value = value.replace("'", "''")
values.append(f"'{escaped_value}'")
elif isinstance(value, datetime):
values.append(f"'{value.strftime('%Y-%m-%d %H:%M:%S')}'")
else:
values.append(str(value))
values_str = ', '.join(values)
insert_stmt = f"INSERT INTO {table_name} ({column_str}) VALUES ({values_str});"
insert_statements.append(insert_stmt)
return insert_statements
def to_csv(self, data):
df = pd.DataFrame(data)
return df.to_csv(index=False)
def to_json(self, data):
return json.dumps(data, indent=2, default=str)
How the output generation works:
1. SQL INSERT Generation: Converts each data record into a properly formatted SQL INSERT statement with escaped values and proper data type handling.
2. CSV Export: Uses pandas DataFrame to convert data into CSV format with proper encoding and formatting.
3. JSON Export: Converts data to JSON format with proper serialization of datetime objects and other complex types.
4. Safety Validation: All output formats include safety checks to prevent SQL injection and ensure data integrity.
Example Output:
INSERT INTO users (id, name, email, phone, address, created_at) VALUES (1, 'John Smith', 'john.smith@email.com', '+1-555-123-4567', '123 Main St, Anytown, ST 12345', '2023-06-15 14:30:22');
INSERT INTO users (id, name, email, phone, address, created_at) VALUES (2, 'Jane Doe', 'jane.doe@email.com', '+1-555-987-6543', '456 Oak Ave, Somewhere, ST 67890', '2023-07-22 09:15:45');
Step 5 - Creating the Enhanced Agent Interface
The enhanced agent combines the base SQL agent’s capabilities with synthetic data generation. It parses natural language requests, extracts parameters, and routes them to the appropriate data generation functions.
You can find the code to this section in the src/agent.py file
The final part that stitches the entire application together is putting it all in a simple Streamlit UI, and the code for that can be found in the GitHub repository.
This is a very simple example of how you can extend the SQL agent template. You can either use the integration as it is, or extend it to build something like I did in this tutorial.
Before we end
This tutorial was a quick way to show how you can use the ready-made templates for your company and project needs.
The beauty of these templates is that they give you a solid foundation, you just need to identify what specific problem you’re trying to solve and add that functionality on top.
Here are some ideas that you can build on top of the other templates:
- LLM Auditor Agent: Add fact-checking for your own content or integrate with your company’s knowledge base
- Product Documentation Agent: Extend it to handle multiple document types (PDFs, videos, internal wikis) or add multi-language support
- Twilio API Agent: Build automated customer support flows or marketing campaign automation
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
A Developer Advocate by profession. I like to build with Cloud, GenAI and can build beautiful websites using JavaScript.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
