AI/ML Technical Content Strategist

3 years ago, the Audio Speech Recognition (ASR) world of deep learning was rocked with the release of the first, true foundation models in OpenAI’s Whisper suite. Whisper Large in particular has continued to be iterated upon, and Whisper Large v3 is the foundation model of a plethora of different open source tools, web applications, and business use cases.
For so long now, Whisper has topped the ASR leaderboards in terms of fidelity, word-error-rate, and ease of use. But now, there is a new top competitor - NVIDIA’s Parakeet v3. Parakeet v3 rivals and even outperforms Whisper Large v3, and other models like Seamless M4T, on several benchmarks for word-error-rate in English transcription tasks. Furthermore, it is incredibly easy to implement, and has a low compute cost to run.
In this tutorial, we are excited to announce the release of Parakeet AutoCaption here and on HuggingFace. This script and web app family uses Parakeet v3 to create overlaid English captions on videos with corresponding output .srt files to a high degree of success. In this tutorial, we show how to use these web applications to their full potential! Readers can expect to learn how to create this application from scratch after following the tutorial.
Key Takeaways
- Parakeet AutoCaption leverages Parakeet v3 to power the translation and transcription of any video sample in up to 25 european languages into english language subtitling with timestamps
- We release Parakeet AutoCaption open-source on HuggingFace, and encourage others to iterate on the design
Parakeet v3
Per their documentation, “parakeet-tdt-0.6b-v3 is a 600-million-parameter multilingual automatic speech recognition (ASR) model designed for high-throughput speech-to-text transcription.” In practice, the v3 version of this model works to extend the parakeet-tdt-0.6b-v2 model. It expands language support from English to 25 European languages, including Bulgarian (bg), Croatian (hr), Czech (cs), Danish (da), Dutch (nl), English (en), Estonian (et), Finnish (fi), French (fr), German (de), Greek (el), Hungarian (hu), Italian (it), Latvian (lv), Lithuanian (lt), Maltese (mt), Polish (pl), Portuguese (pt), Romanian (ro), Slovak (sk), Slovenian (sl), Spanish (es), Swedish (sv), Russian (ru), Ukrainian (uk). Streamlining everything, the model actually is able to automatically detect the input language of the audio and transcribes it without requiring additional prompting. It is notably part of a series of models that leverage the Granary multilingual corpus as their primary training dataset.
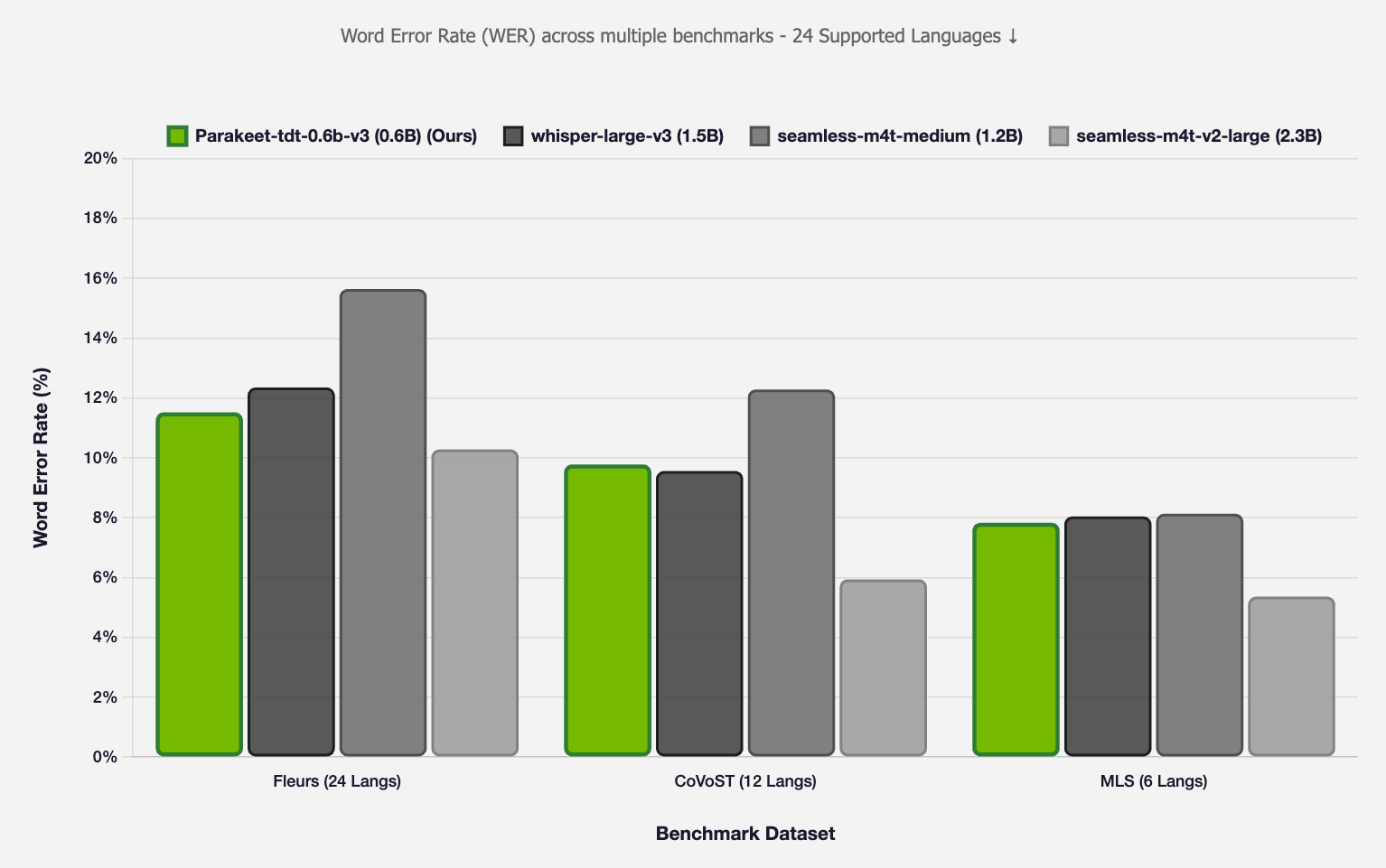
As we can see from the graphic they provided for the model’s release, Parakeet outperformed whisper-large-v3, seamless-m4t-medium, and seamless-m4t-large in terms of Word Error Rate across multiple benchmarks on the 24 supported languages.
Parakeet AutoCaption
Now that we have introduced Parakeet v3 and discussed its incredible utility as an ASR model, let’s take a look at the web application’s script. We can use this to generate the .srt file and captions used in the examples shown above.
First, let’s break down the installs and imports.
Pip3 install torch torchvision moviepy pydub opencv-python-headless gradio braceexpand editdistance einops jiwer>=3.1.0,<4.0.0 kaldi-python-io lhotse!=1.31.0 librosa>=0.10.1 marshmallow optuna packaging pyannote.core pyannote.metrics pydub pyloudnorm resampy ruamel.yaml scipy>=0.14 soundfile sox<=1.5.0 texterrors<1.0.0 hydra-core pytorch-lightning flash-attn cuda-python spaces git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr]
This will install everything required to run Parakeet AutoCaption! Next, let’s look at how we import them.
## Imports: helpers
from __future__ import unicode_literals
import cv2
import pandas as pd
import os
import csv, re, sys
from pathlib import Path
import urllib.request
## import moviepy
from moviepy.video.tools.subtitles import SubtitlesClip
from moviepy.video.io.VideoFileClip import VideoFileClip
from moviepy import CompositeVideoClip
from moviepy import TextClip
#import nemo asr library and gradio
import nemo.collections.asr as nemo_asr
import gradio as gr
import spaces
## get font
urllib.request.urlretrieve("https://github.com/Jameshskelton/fonts/raw/refs/heads/main/P052-Roman.ttf", "P052-Roman.ttf")
All the required packages being installed ensures that we can import them successfully for the application. Make sure that all these installs are successful before continuing.
In the next section, we have a series of helper functions.
def parse_time_to_srt(t):
s = str(t).strip()
if re.fullmatch(r"\d+(\.\d+)?", s):
total_ms = int(round(float(s) * 1000))
else:
parts = s.split(':')
if len(parts) == 2:
mm, ss = parts
sec = float(ss)
total_ms = int(round((int(mm) * 60 + sec) * 1000))
elif len(parts) == 3:
hh, mm, ss = parts
sec = float(ss)
total_ms = int(round(((int(hh) * 3600) + (int(mm) * 60) + sec) * 1000))
else:
raise ValueError(f"Unrecognized time format: {s}")
hours = total_ms // 3_600_000
rem = total_ms % 3_600_000
minutes = rem // 60_000
rem = rem % 60_000
seconds = rem // 1000
millis = rem % 1000
return f"{hours:02}:{minutes:02}:{seconds:02},{millis:03}"
def map_position_to_tag(pos):
if not pos:
return ""
s = str(pos).strip().lower()
m = re.search(r"\\?an([1-9])", s)
if m:
return "{\\an" + m.group(1) + "}"
if "top left" in s or ("top" in s and "left" in s):
return "{\\an7}"
if "top right" in s or ("top" in s and "right" in s):
return "{\\an9}"
if "bottom left" in s or ("bottom" in s and "left" in s):
return "{\\an1}"
if "bottom right" in s or ("bottom" in s and "right" in s):
return "{\\an3}"
if "top" in s:
return "{\\an8}"
if "middle" in s or "center" in s or "centre" in s:
return "{\\an5}"
if "bottom" in s:
return "{\\an2}"
return ""
def looks_like_header(row):
joined = ",".join(c.strip().lower() for c in row[:4])
header_words = ["position", "pos", "align", "start", "begin", "end", "stop", "subtitle", "text", "caption"]
return any(w in joined for w in header_words)
def csv_to_srt(csv_path: Path, srt_path: Path):
with open(f'{csv_path}',"r", encoding="utf-8-sig", newline="") as f:
reader = csv.reader(f)
rows = [row for row in reader if any(cell.strip() for cell in row)]
if not rows:
raise ValueError("CSV is empty.")
start_index = 1 if looks_like_header(rows[0]) else 0
normalized = []
for i, row in enumerate(rows[start_index:], start=start_index+1):
if len(row) < 4:
raise ValueError(f"Row {i} has fewer than 4 columns: {row}")
position, start, end, text = row[0].strip(), row[1].strip(), row[2].strip(), row[3]
normalized.append((position, start, end, text))
with open(f"{srt_path}", "w", encoding="utf-8") as out:
for idx, (position, start, end, text) in enumerate(normalized, start=1):
start_srt = parse_time_to_srt(start)
end_srt = parse_time_to_srt(end)
pos_tag = map_position_to_tag(position)
final_text = f"{pos_tag}{text}" if pos_tag else text
out.write(f"{idx}\n")
out.write(f"{start_srt} --> {end_srt}\n")
out.write(f"{final_text}\n\n")
from pydub import AudioSegment
def convert_audio_to_mono_16khz(input_path, output_path):
"""
Converts an audio file to mono and resamples it to 16 kHz.
Args:
input_path (str): The path to the input audio file.
output_path (str): The path to save the converted audio file.
"""
try:
audio = AudioSegment.from_file(input_path)
# Set channels to 1 (mono)
audio = audio.set_channels(1)
# Set frame rate (sample rate) to 16000 Hz
audio = audio.set_frame_rate(16000)
audio.export(output_path, format="wav") # Export as WAV or desired format
print(f"Audio converted successfully to mono, 16kHz at: {output_path}")
except Exception as e:
print(f"Error converting audio: {e}")
These helpers are essential to making the core function run. parse_time_to_srt() reformats the time stamps used by Parakeet into a format readable as an SRT file. map_position_to_tag() locates and assigns a positional tag to the words. looks_like_header() confirms the position of a header word. Finally, csv_to_srt() uses these helper functions to create our core helper function, which converts the CSV we are creating with Parakeet to a SRT file. We have one additional helper function, convert_audio_to_mono_16khz(), which is essential for making sure our audio file can be read by Parakeet in the first place.
In the next section, we show the core function subtitle_video() in its entirety. Follow along with the hashed notes within the function for an explanation, line by line, of how the function works.
## instantiate the ASR model outside the function so it doesn’t have to be reloaded each run
asr_model = nemo_asr.models.ASRModel.from_pretrained(model_name="nvidia/parakeet-tdt-0.6b-v3")
@spaces.GPU
def subtitle_video(input_file):
#------------------------------------------------------------------------------------------------------------------------------
# Params:
#------------------------------------------------------------------------------------------------------------------------------
# input_file: str, path to video file for MoviePy to caption
#------------------------------------------------------------------------------------------------------------------------------
# Returns:
# output_video: An annotated video with translated captions into english
# output_subs: Subtitles in csv format, displayed as table on web app
# output_subs_srt_file: path to srt file containing timestamped subtitles
#------------------------------------------------------------------------------------------------------------------------------
## First, this checks if your experiment name is taken. If not, it will create the directory.
## Otherwise, we will be prompted to retry with a new name
name = 'run'
try:
os.mkdir(f'experiments/{name}')
print('Starting AutoCaptioning...')
print(f'Results will be stored in experiments/{name}')
except:
None
# Use VideoFileClip to instantiate video
my_clip = VideoFileClip(input_file)
my_clip.write_videofile(f"experiments/{name}/{input_file.split('/')[-1]}")
my_clip.audio.write_audiofile(f'experiments/{name}/audio_file.wav', codec="mp3")
# load parakeet model as model variable
model = asr_model
# convert to format parakeet can interpret
convert_audio_to_mono_16khz(f'experiments/{name}/audio_file.wav', f'experiments/{name}/audio_file.wav')
# transcribe audio with Parakeet
output = model.transcribe([f'experiments/{name}/audio_file.wav'], timestamps=True)
# Convert audio to text with timestamps, dump into dataframe
df = pd.DataFrame(output[0].timestamp['segment'])
df['text'] = df['segment']
df = df.drop(['start_offset', 'end_offset', 'segment'],axis = 1)
# save csv and srt files
df.to_csv(f'experiments/{name}/subs.csv')
csv_to_srt(f"experiments/{name}/subs.csv",f"experiments/{name}/subs.srt")
# Capture video
vidcap = cv2.VideoCapture(f'''experiments/{name}/{input_file}''')
success, image = vidcap.read()
# Instantiate MoviePy subtitle generator with TextClip, subtitles, and SubtitlesClip
generator = lambda txt: TextClip(
"./P052-Roman.ttf",
text = txt,
font_size = int(my_clip.w/50),
stroke_width=1,
color= "white",
stroke_color="black",
size = (my_clip.w, my_clip.h),
vertical_align = 'bottom',
horizontal_align = 'center',
method='caption')
subs = SubtitlesClip(f"experiments/{name}/subs.srt", make_textclip=generator)
## Write subs to video file and return
video = VideoFileClip(input_file)
final = CompositeVideoClip([video, subs])
final.write_videofile(f'experiments/{name}/output.mp4', fps=video.fps, remove_temp=True, codec="libx264", audio_codec="aac")
return f'experiments/{name}/output.mp4', df, f"experiments/{name}/subs.srt"
# web app code
with gr.Blocks() as demo:
gr.Markdown("<div style='display:flex;justify-content:center;align-items:center;gap:.5rem;font-size:24px;'>🦜 <strong>Parakeet AutoCaption Web App</strong></div>")
with gr.Column():
input_video = gr.Video(label = 'Input your video for captioning')
# input_name = gr.Textbox(label = 'Name of your experiment run')
with gr.Column():
run_button = gr.Button('Run Video Captioning')
with gr.Column():
output_video = gr.Video(label = 'Output Video')
output_subs = gr.Dataframe(label = 'Output Subtitles')
output_subs_srt_file = gr.DownloadButton(label = 'Download subtitles as SRT file')
gr.on(
triggers=[run_button.click],
fn=subtitle_video,
inputs=[
input_video,
],
outputs=[output_video, output_subs, output_subs_srt_file],
)
if __name__ == "__main__":
demo.launch(share=True)
Together, we construct the full Gradio web app for Parakeet AutoCaption. This will take in any video file, transcribe and, if necessary, translate the audio content, and subtitle the video in English.
This application is currently running as a HuggingFace Space, but can be easily deployed on a DigitalOcean GPU Droplet by cloning the HuggingFace repo to the machine. Simply install the requirements and run the web app with the following code.
git clone https://huggingface.co/spaces/JamesDigitalOcean/Parakeet-AutoCaption
cd Parakeet-AutoCaption
pip install -r requirements.txt
python3 app.py --share
Closing Thoughts
Parakeet v3 is an incredibly powerful ASR model from NVIDIA, and we are very excited to update the AutoCaption system to use it. With the release of Parakeet AutoCaption, we’re opening the door to a new generation of accessible, efficient, and multilingual video captioning. Whether you’re a developer looking to integrate cutting-edge ASR into your pipeline, a content creator aiming to make your videos more discoverable, or a researcher benchmarking the latest speech models, this tool provides a lightweight yet powerful starting point. We invite the community to test it, extend it, and share their own contributions.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Excellent guide. It’s impressive how well Parakeet-v3 handles SRT generation. I’ve been using Transcrisper for a similar ‘no-install’ experience, and the accuracy is spot on.
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
