By Safa Mulani

Hello, readers! In this article, we will be focusing on one of the most important pre-processing techniques in Python - Standardization using StandardScaler() function.
So, let us begin!!
Need for Standardization
Before getting into Standardization, let us first understand the concept of Scaling.
Scaling of Features is an essential step in modeling the algorithms with the datasets. The data that is usually used for the purpose of modeling is derived through various means such as:
- Questionnaire
- Surveys
- Research
- Scraping, etc.
So, the data obtained contains features of various dimensions and scales altogether. Different scales of the data features affect the modeling of a dataset adversely.
It leads to a biased outcome of predictions in terms of misclassification error and accuracy rates. Thus, it is necessary to Scale the data prior to modeling.
This is when standardization comes into picture.
Standardization is a scaling technique wherein it makes the data scale-free by converting the statistical distribution of the data into the below format:
- mean - 0 (zero)
- standard deviation - 1
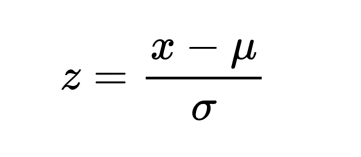
By this, the entire data set scales with a zero mean and unit variance, altogether.
Let us now try to implement the concept of Standardization in the upcoming sections.
Python sklearn StandardScaler() function
Python sklearn library offers us with StandardScaler() function to standardize the data values into a standard format.
Syntax:
object = StandardScaler()
object.fit_transform(data)
According to the above syntax, we initially create an object of the StandardScaler() function. Further, we use fit_transform() along with the assigned object to transform the data and standardize it.
Note: Standardization is only applicable on the data values that follows Normal Distribution.
Standardizing data with StandardScaler() function
Have a look at the below example!
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
dataset = load_iris()
object= StandardScaler()
# Splitting the independent and dependent variables
i_data = dataset.data
response = dataset.target
# standardization
scale = object.fit_transform(i_data)
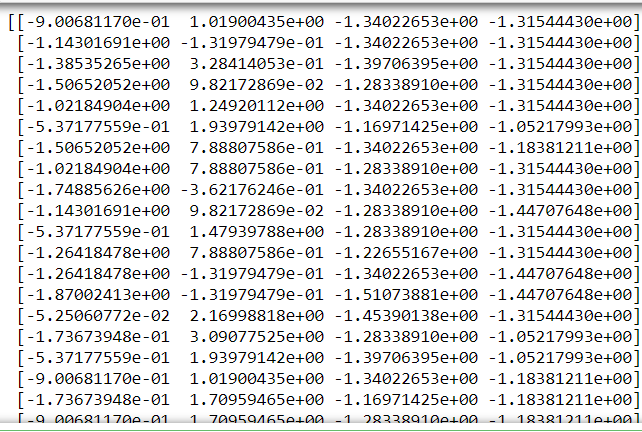
print(scale)
Explanation:
- Import the necessary libraries required. We have imported sklearn library to use the StandardScaler function.
- Load the dataset. Here we have used the IRIS dataset from sklearn.datasets library. You can find the dataset on the UCI website.
- Set an object to the
StandardScaler()function. - Segregate the independent and the target variables as shown above.
- Apply the function onto the dataset using the
fit_transform()function.
Output:
Conclusion
By this, we have come to the end of this topic. Feel free to comment below, in case you come across any question.
For more posts related to Python, Stay tuned @ Python with JournalDev and till then, Happy Learning!! :)
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
