By Keshav Aggarwal and Shaoni Mukherjee

Introduction
If you are building deep learning models, you may need to sit for hours (or even days) before you can see any real results. You may need to stop model training to change the learning rate, push training logs to the database for future use, or show the training progress in TensorBoard. We may need to do a lot of work to achieve these basic tasks—that’s where TensorFlow callbacks come into the picture.
Prerequisites
- Basic Understanding of Python and TensorFlow: Familiarity with Python programming and experience in using TensorFlow for building and training deep learning models.
- Knowledge of Deep Learning Concepts: Understanding concepts like epochs, batches, training/validation loss, and accuracy.
- Experience with Model Training in TensorFlow: Prior experience training models using TensorFlow’s Model.fit() function, including specifying training and validation data.
- Familiarity with TensorFlow’s Keras API: Understanding Keras as a high-level API for TensorFlow, including model definition, compilation, and training processes.
- Installation of TensorFlow: Ensure TensorFlow is installed in your environment (e.g., via pip install tensorflow).
What’s a Callback Function?
Callbacks are special functions executed at specific stages during the training process. They can help you prevent overfitting, visualize training progress, debug your code, save checkpoints, generate logs, and create TensorBoard visualizations, among other tasks. TensorFlow offers many built-in callbacks, and you can use multiple callbacks concurrently. In this discussion, we will explore the various callbacks available and provide examples of how to use them.
When a Callback is Triggered
Callbacks are called when a certain event is triggered. There are a few types of events during training that can lead to the trigger of a callback, such as:
- on_epoch_begin: As the name suggests, this event is triggered when a new epoch starts. on_epoch_end: This is triggered when an epoch ends.
- on_batch_begin: This is triggered when a new batch is passed for training.
- on_batch_end: When a batch is finished with training.
- on_train_begin: When the training starts.
- on_train_end: When the training ends.
To use any callback in the model training, you just need to pass the callback object in the model.fit() call, for example:
model.fit(x, y, callbacks=list_of_callbacks)
Available Callbacks in TensorFlow 2.0
Let’s take a look at the callbacks which are available under the tf.keras.callbacks module.
1. EarlyStopping if the accuracy is not improving
This callback is used very often. This allows us to monitor our metrics and stop model training when it stops improving. For example, assume that you want to stop training if the accuracy is not improving by 0.05; you can use this callback. This is useful in preventing the overfitting of a model to some extent.
tf.keras.callbacks.EarlyStopping(monitor='val_loss',
min_delta=0,
patience=0,
verbose=0,
mode='auto',
baseline=None,
restore_best_weights=False)
- monitor: The names of the metrics we want to monitor.
- min_delta: The minimum amount of improvement we expect in every epoch.
- patience: The number of epochs to wait before stopping the training.
- verbose: Whether or not to print additional logs.
- mode: Defines whether the monitored metrics should be increasing, decreasing, or inferred from the name; possible values are ‘min,’ ‘max,’ or ‘auto.’
- baseline: Values for the monitored metrics.
- restore_best_weights: If this value is set to True, the model will get the weights of the epoch with the best value for the monitored metrics; otherwise, it will get the weights of the last epoch.
The EarlyStopping callback is executed via the on_epoch_end trigger for training.
2. ModelCheckpoint to save the model regularly during training
This callback allows us to save the model periodically during training. It’s particularly beneficial for deep learning models that require a significant amount of time to train. The callback monitors the training process and saves model checkpoints at regular intervals, based on specific metrics.
tf.keras.callbacks.ModelCheckpoint(filepath,
monitor='val_loss',
verbose=0,
save_best_only=False,
save_weights_only=False,
mode='auto',
save_freq='epoch')
- filepath: Path for saving the model. You can pass the file path with formatting options like model-{epoch:02d}-{val_loss:0.2f}; This saves the model with the mentioned values in the name.
- monitor: Name of the metrics to monitor.
- save_best_only: If set to True, the best model will not be overridden.
- mode: Defines whether the monitored metrics should be increasing, decreasing, or inferred from the name; possible values are ‘min,’ ‘max,’ or ‘auto.’
- save_weights_only: If set to True, only the models’ weights will be saved. Otherwise, the full model will be saved.
- save_freq: If ‘epoch,’ is mentioned as the value, the model will be saved after every epoch. If an integer value is passed, the model will be saved after the integer number of batches (not to be confused with epochs).
The ModelCheckpoint callback is executed via the on_epoch_end trigger of training.
3. TensorBoard to visualize the training summary
This is one of the best callbacks if you want to visualize your model’s training summary. This callback generates the logs for TensorBoard, which you can later launch to visualize your training progress. We will cover the details of TensorBoard in a separate article.
> tf.keras.callbacks.TensorBoard(log_dir='logs',
histogram_freq=0,
write_graph=True,
write_images=False,
update_freq='epoch',
profile_batch=2,
embeddings_freq=0,
embeddings_metadata=None,
**kwargs)
For now we will see only one parameter, log_dir, which is the path of the folder where you need to store the logs. To launch the TensorBoard you need to execute the following command:
tensorboard --logdir=path_to_your_logs
You can launch the TensorBoard before or after starting your training.
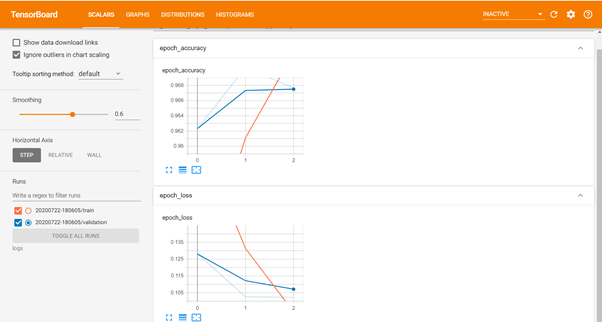
TensorBoard
The TensorBoard callback is also triggered at on_epoch_end.
4. LearningRateScheduler to update the learning rate
This callback is handy when the user wants to update the learning rate as training progresses. For instance, you may want to decrease the learning rate after a certain number of epochs. The LearningRateScheduler will let you do exactly that.
tf.keras.callbacks.LearningRateScheduler(schedule, verbose=0)
- schedule: This function takes the epoch index and returns a new learning rate.
- verbose: Whether or not to print additional logs.
Below is an example of reducing the learning rate after three epochs.
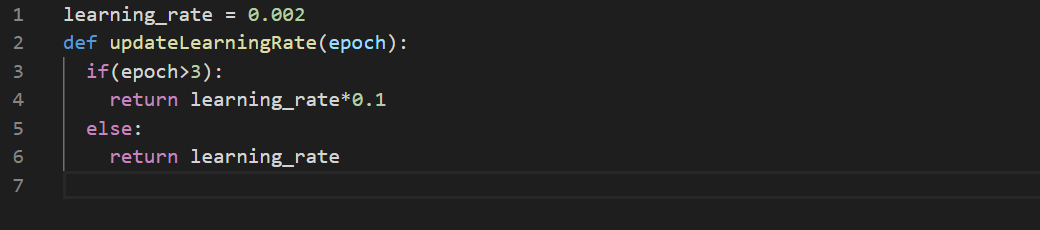
Function to pass to the ‘schedule’ parameter for the LearningRateScheduler callback. As you can see in the output below, after the fourth epoch, the learning rate has been reduced. verbose has been set to 1 to keep tabs on the learning rate.

In epoch 5 learning rate drops to 0.0002 from 0.002.
This callback is also triggered at on_epoch_end.
5. CSVLogger to log the training details
As the name suggests, this callback logs the training details in a CSV file. The logged parameters are epoch, accuracy, loss, val_accuracy, and val_loss. One thing to keep in mind is that you need to pass accuracy as a metric while compiling the model. Otherwise, you will get an execution error.
tf.keras.callbacks.CSVLogger(filename,
separator=',',
append=False)
The logger accepts the filename and separator and appends them as parameters. append variable defines whether or not to append to an existing file or write in a new file instead. The CSVLogger callback is executed via the on_epoch_end trigger of training. When an epoch ends, the logs are put into a file.
6. LambdaCallback
This callback is required when you need to call some custom function on any of the events, but the provided callbacks do not suffice. For instance, say you want to put your logs into a database.
tf.keras.callbacks.LambdaCallback(on_epoch_begin=None,
on_epoch_end=None,
on_batch_begin=None,
on_batch_end=None,
on_train_begin=None,
on_train_end=None,
**kwargs)
The tf.keras.callbacks.LambdaCallback is a flexible Keras callback that allows users to define custom actions at specific points during training by passing lambda functions to its parameters. It provides hooks for different stages of training, including on_epoch_begin and on_epoch_end for executing actions at the start and end of each epoch, on_batch_begin and on_batch_end for actions at the start and end of each batch, and on_train_begin and on_train_end for operations before and after the entire training process. This callback is particularly useful for logging, modifying training behavior dynamically, or implementing custom monitoring functions without defining a full-fledged callback class. The **kwargs parameter allows passing additional arguments, making it highly customizable.
Let’s see an example:

Function to put logs in a file at end of a batch.
This callback will put the logs into a file after a batch is processed. The output which you can see in the file is:

The generated Logs
This callback is called for all the events, and executes the custom functions based on the parameters passed.
7. ReduceLROnPlateau to change the learning rate
This callback is used to change the learning rate when the metrics have stopped improving. As opposed to LearningRateScheduler, it reduces the learning based on the metric (not epoch).
tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss',
factor=0.1,
patience=10,
verbose=0,
mode='auto',
min_delta=0.0001,
cooldown=0,
min_lr=0,
**kwargs)
Several parameters resemble those of the EarlyStoppingCallback, so let’s highlight the ones that differ.
monitor, patience, verbose, mode, min_delta: These are similar to EarlyStopping. factor this is the factor by which the learning rate should be decreased (new learning rate = old learning rate * factor). cooldown: The number of epochs to wait before restarting the metrics monitoring. min_lr: The minimum bound for the learning rate (the learning rate can’t go below this). This callback is also called at the on_epoch_end event.
8. RemoteMonitor
This callback is useful when posting logs to an API and can be mimicked using LambdaCallback.
tf.keras.callbacks.RemoteMonitor(root='http://localhost:9000',
path='/publish/epoch/end/',
field='data',
headers=None,
send_as_json=False)
- root: This is the URL.
- path: This is the endpoint name/path.
- field: This is the name of the key which will have all the logs.
- header: The header which needs to be sent.
- send_as_json: If True, the data will be sent in JSON format.
For example:

Callback
To see if the callback is working, you need an endpoint hosted on localhost:8000. You can use Node.js. Save the code in the file server.js:
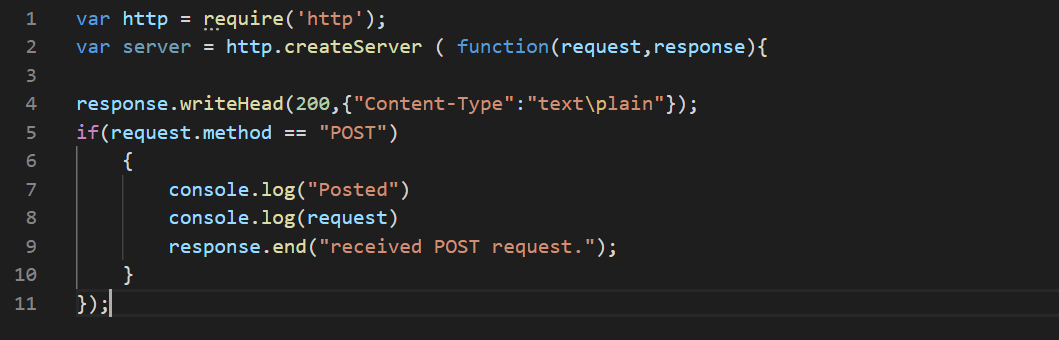
Then start the server by typing node server.js (you should have node installed). At the end of the epoch you will see the log in the node console. If the server is not running then you will receive a warning at the end of the epoch.
This callback is also called at the on_epoch_end event.
9. BaseLogger & History
These two callbacks are automatically applied to all Keras models. The history object is returned by model.fit, and contains a dictionary with the average accuracy and loss over the epochs. The parameters property contains the dictionary with the parameters used for training (epochs, steps, verbose). If you have a callback for changing the learning rate, that will also be part of the history object.

Output of model_history.history
BaseLogger accumulates an average of your metrics across epochs. So, the metrics you see at the end of the epoch are an average of all the metrics over all the batches.
10. TerminateOnNaN
This callback terminates the training if the loss becomes NaN.
tf.keras.callbacks.TerminateOnNaN()
Conclusion
You can choose callbacks based on your specific needs, and in many cases, combining multiple callbacks enhances the training efficiency. For example, TensorBoard helps monitor training progress visually, while EarlyStopping and LearningRateScheduler prevent overfitting by stopping training early or adjusting the learning rate dynamically. Additionally, ModelCheckpoint ensures that model checkpoints are saved periodically, preventing data loss. If you’re running deep learning workloads on the cloud, DigitalOcean’s GPU Droplets provide a powerful and cost-effective environment for training models efficiently. Furthermore, you can use the DigitalOcean’s 1-Click AI Models to streamline your workflow and integrate TensorFlow callbacks seamlessly into your training process.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
