 function in R programming")
The unique() function in R is used to eliminate or delete the duplicate values or the rows present in the vector, data frame, or matrix as well.
The unique() function found its importance in the EDA (Exploratory Data Analysis) as it directly identifies and eliminates the duplicate values in the data.
In this article, we are going to unleash the various application of the unique() function in R programming. Let’s roll!!!
The idea of getting unique values
Well, before going into the topic, its good to know the idea behind it. In this case, it is unique values. The unique function will return the unique values by eliminating the duplicate counts.
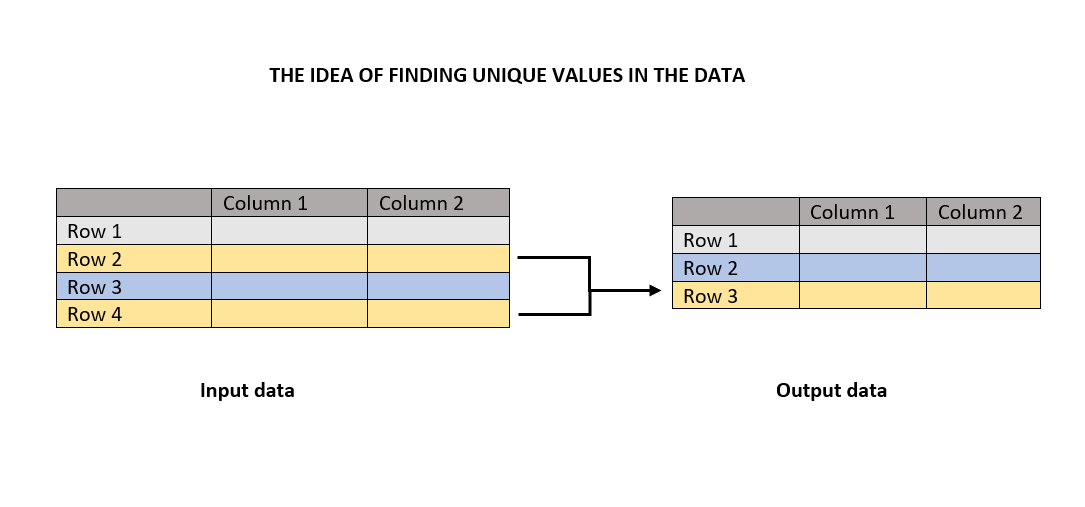
The diagram tells you that the unique function will look for duplicates and eliminates that to return the unique values. There are many illustrations coming your way in the following sections to teach something good.
The syntax of the Unique() function in R
Unique: The unique() function is used to identify and eliminate the duplicate counts present in the data.
unique(x)
Where:
X = It can be a vector, a data frame or a matrix.
A simple example of unique() function in R
If you have a vector that has duplicate values, then with the help of the unique() function you can easily eliminate those using a single line of code.
Let’s see how it works…
#An input vector having duplicate values
df<-c(1,2,3,2,4,5,1,6,8,9,8,6)
#elimnates the duplicate values in the vector
unique(df)
Output = 1 2 3 4 5 6 8 9
In the above illustration you may observe that, the input vector has many duplicate values.
After we passed that vector to unique function, it eliminates all the duplicate values and returns only the unique values as shown above.
Finding the unique values in a matrix
Now, we are going to find duplicate values present in a matrix and eliminate them using the unique function.
For this, we have to first create a matrix of ‘n’ rows and columns having the duplicate values.
To create a matrix, run the below code.
#creates a 6 x 4 matrix having 24 elements
df<-matrix(rep(1:20,length.out=24),nrow = 6,ncol=4,byrow = T)
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
[4,] 13 14 15 16
[5,] 17 18 19 20
[6,] 1 2 3 4
As you can easily notice that, the last row is entirely duplicated. All you need to do is by using the unique() function, eliminate these duplicate values.
#removes the duplicate values
unique(df)
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
[4,] 13 14 15 16
[5,] 17 18 19 20
YaY!
You did it! All the duplicate values present in the matrix were get removed by the unique function and it returned a matrix having unique values alone.
Finding the unique values in the dataframe
Till now, we worked on the vectors and the matrices to extract the unique values by eliminating the duplicate counts.
In this section, let’s focus on getting the unique values present in the data frame.
To create a data frame run the below code.
#creates a data frame
> Class_data<-data.frame(Student=c('Naman','Megh','Mark','Naman','Megh','Mark'),Age=c(22,23,24,22,23,24),Gender=c('Male','Female','Male','Male','Female','Male'))
#dataframe
Class_data
Student Age Gender
1 Naman 22 Male
2 Megh 23 Female
3 Mark 24 Male
4 Naman 22 Male
5 Megh 23 Female
6 Mark 24 Male
This is the data frame which has the duplicate counts as shown above. Let’s apply the unique function to get rid of the duplicate value present here.
unique(Class_data)
Student Age Gender
1 Naman 22 Male
2 Megh 23 Female
3 Mark 24 Male
Wow! The unique function returned all the unique values present in the dataframe by eliminating the duplicate values.
Just like this, by using the unique() function in R, you can easily get the unique values present in the data.
Finding the unique values of a particular column
Yes, what if you are required to get the unique values out of a specific column instead of data set?
Worry not, using the unique() function we can also get the unique values out of particular column as shown below.
#creates a data frame
> Class_data<-data.frame(Student=c('Naman','Megh','Mark','Naman','Megh','Mark'),Age=c(22,23,24,22,23,24),Gender=c('Male','Female','Male','Male','Female','Male'))
#dataframe
Class_data
Student Age Gender
1 Naman 22 Male
2 Megh 23 Female
3 Mark 24 Male
4 Naman 22 Male
5 Megh 23 Female
6 Mark 24 Male
Okay, I am taking the same data frame that we used in the last sections for easy understanding.
Let’s use unique function to get rid of duplicate values.
unique(Class_data$Student)
Output = "Naman" "Megh" "Mark"
In the same way, we can also get the unique values in the Age or Gender columns as well.
unique(Class_data$Gender)
"Male" "Female"
Finding the length of the unique values
In this section, we are going to get the count of the unique values in the data. This application is more useful to know your data better and get it ready for further analysis.
#importing the dataset
datasets::BOD
Time demand
1 1 8.3
2 2 10.3
3 3 19.0
4 4 16.0
5 5 15.6
6 7 19.8
well, we are using the BOD dataset here. Let’s find the unique values first which will be followed by the count.
#returns the unique value
unique(BOD$demand)
Output = 8.3 10.3 19.0 16.0 15.6 19.8
Okay, now we have the unique values present in the demand column in the BOD dataset.
Now, we are good to go to find the count of the unique values.
#returns the length of unique values
length(unique(BOD$demand))
Output = 6
Wrapping Up
Well, the unique() function in R is a very valuable one when it comes to EDA (Exploratory Data Analysis).
It helps you to get a better understanding of your data along with particular counts.
This article tells you about the multiple applications and use cases of the unique() function. Happy analyzing!!!
More read: R documentation
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
