AI/ML Technical Content Strategist

Wan2.1 has been probably the most widespread open-source model to be adopted by the AI community. This is largely thanks to its incredible versatility, day one releases of both text-to-video and image-to-video models, and widespread integration into open-source tools. Not only that, recently Wan2.1 has been making waves as an image generation model, garnering direct comparisons with leading models like Flux.1 from Black Forest Labs.
On July 28th, Wan2.2 was open-sourced and released to the public, offering the first successor to the popular video model suite. Wan2.2 boasts several improvements over its predecessor, including but not limited to:
- Effective MoE Architecture: Wan2.2 is the first Mixture-of-Experts video generation model, expanding the capability and versatility of the model without affecting computational cost.
- Cinematic-level Aesthetics: using hand-crafted and curated data, Wan2.2 claims a higher cinematic aesthetic and quality over its predecessor
- Complex Motion Generation: thanks to a significantly larger training corpus, they have improved the model’s now SOTA “generalization across multiple dimensions such as motions, semantics, and aesthetics”
- Efficient High-Definition Hybrid TI2V: in addition to the 27B (14B activated) MoE model, they open-source a dense 5B version capable of both text-to-video and image-to-video generation, and is designed to run on consumer grade graphics cards Source
Now that the model has been released, we are very excited to bring you this tutorial for Wan2.2 using the ComfyUI on a DigitalOcean GPU Droplet. Follow along for step by step instructions for setting up the environment for ComfyUI, downloading and organizing the model files in their correct directories, and a demo showing how to run the new Wan2.2 MoE A14B model to generate a video from a text input.
Setting up the GPU Droplet
Setting up the environment for the ComfyUI on a GPU Droplet is quick and simple!
First, make sure you have created a GPU Droplet with sufficient resources to run this demo. We recommend the NVIDIA H100 or AMD MI300X for optimal performance. Once it has spun up, access the machine through your local computer’s terminal window with your machine’s IP address and SSH.
Ssh root@<your ip address>
Once that’s complete, and you now have access to your GPU Droplet, we can get started setting up the remote environment. Note that you may want to exit the root directory before continuing. Otherwise, our first step is to clone the ComfyUI Github repo onto our machine, and install relevant packages onto a virtual environment.
Git clone https://github.com/comfyanonymous/ComfyUI
Cd ComfyUI
Python -m venv venv_comfy
Source venv_comfy/bin/activate
Pip install -r requirements.txt
This should only take a couple of minutes to complete. Next, we are going to download all the necessary model files. For this example, we are going to use the text to video models. Paste the following code in to download all the model files to the correct directories.
wget -O models/diffusion_models/wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors
wget -O models/diffusion_models/wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/diffusion_models/wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors
wget -O models/text_encoders/umt5_xxl_fp16.safetensors https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/text_encoders/umt5_xxl_fp16.safetensors
wget -O models/vae/wan_2.1_vae.safetensors https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/vae/wan_2.1_vae.safetensors
wget -O models/vae/wan2.2_vae.safetensors https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/resolve/main/split_files/vae/wan2.2_vae.safetensors
This should take around 10 minutes to complete, but it can be accelerated by opening new terminal windows for your remote machine, changing to the ComfyUI directory, and pasting the above code with one line per window.
With that complete, we are ready to run the ComfyUI! Paste the following code into the terminal:
python main.py
On your local machine, open up VS Code, and tunnel into your remote machine using the SSH. You can do this by clicking on the “Connect To” button in the central window, and using the Remote-SSH to access your machine from VS Code.
Next, take the output from your remote terminal window, something like http://127.0.0.1:8188, and paste it into the newly connected VS Code window’s simple browser. You can access this with command+p and searching for the simple browser. Click the button on the top right of the URL bar to open up the ComfyUI in your local browser window.
Generating Videos with Wan2.2 Text-to-Video
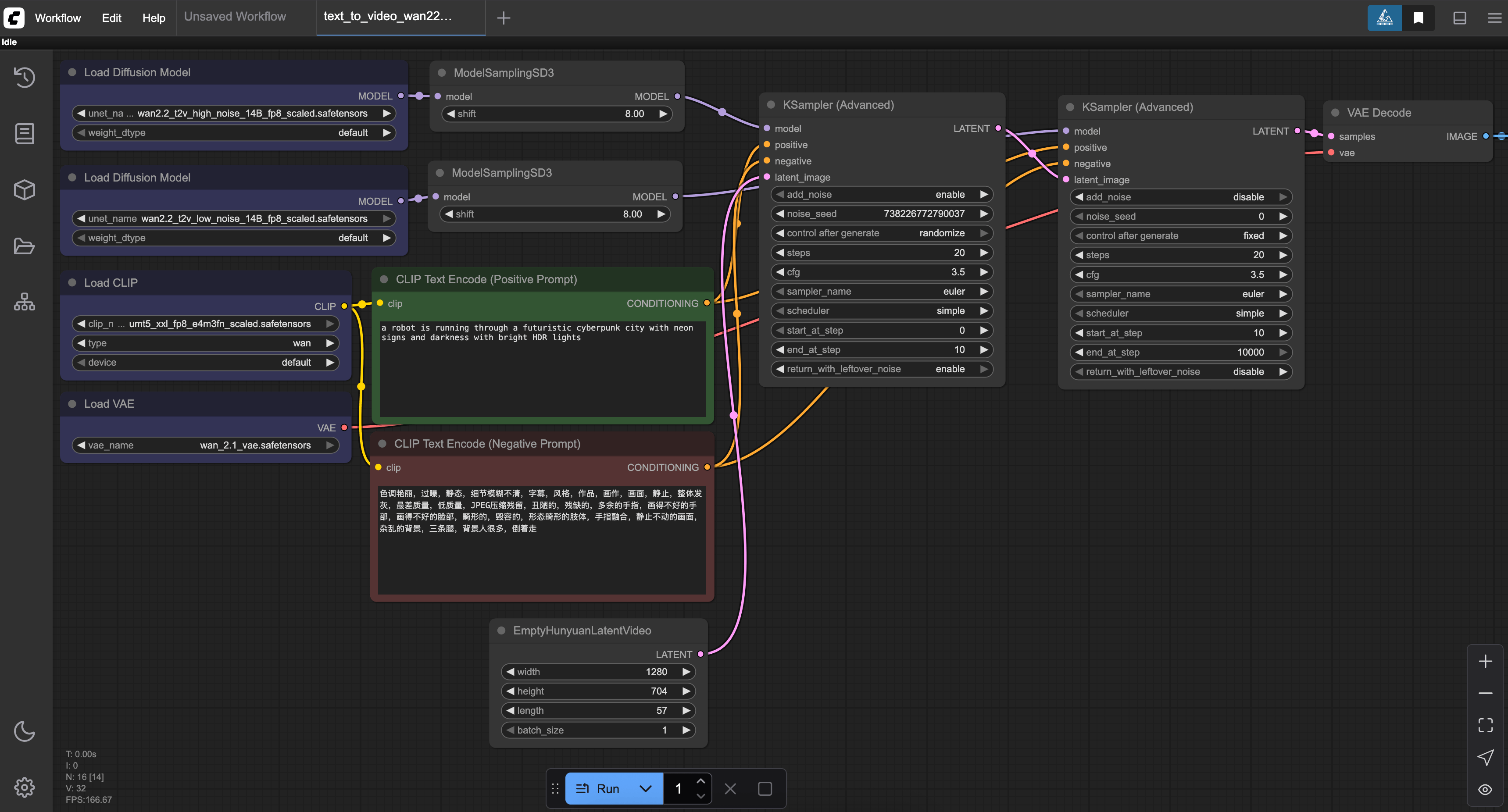
Above is an example workflow for the ComfyUI provided by ComfyAnonymous at their website, here. Download the image or json file, and open it in your ComfyUI window in the browser.
Since we have already downloaded all the required model files, we can hit run to generate an example video like the one below:
We recommend navigating through the various nodes to familiarize yourself with each of them. In particular, we recommend knowing how to adjust the following nodes:
- Clip Text Encode (Positive Prompt): This node controls the text input for the model. We can edit it using human-like language to alter our output as desired
- Clip Text Encode (Negative Prompt): This node controls the negative input for the model. Adjust this to remove unwanted traits, objects, or characteristics of your video
- EmptyHunyuanLatentVideo: This affects the size of our video. Change the height and width to control these pixel values directly
- KSampler (Advanced): these two control the sampling of the model. Here we can change the noise seed (though you should not do so to the latter KSampler node), the number of steps taken for diffusion, and the strength of the prompt
How does Wan2.2 perform?
In our experience so far, Wan2.2 is a step-forward in every direction for Wan Video Modeling. First, the overall quality is much improved, especially when capturing motion. Second, the variety of styles and objects the model knows and understands have grown significantly. And Thirdly, the computational cost was not increased from Wan2.1. Together, these improvements make Wan2.2 the best open-source video model available! Let’s look at how the model does with some images we generated.
Here are a couple examples we made using the default settings with their prompts:
Prompt: “A World War 2-style propaganda video depicts a dramatic encounter between a bewildered hillbilly and extraterrestrial beings. The hillbilly, wearing denim overalls with a ripped flannel shirt underneath, stands with mouth agape and eyes wide in an expression of shock. Three grey aliens in metallic silver naval uniforms with polished brass buttons stand before him on the curved metallic floor of a UFO’s command deck. The hillbilly is freaking out, while the aliens try to calm him down. The bridge features glowing control panels with blinking lights and a large circular window showing stars and Earth visible in space. The scene is rendered in brilliant detail, intricate details 4k footage hd high definition”
Prompt: a 3d animation of a baby toddler dressed as a ninja fighting a battle fight with a chicken rooster. they fight with kicks and punches, and the rooster flaps its wings.
As we can see, Wan2.2 is incredibly versatile. It can mix photorealistic concepts with fantasy as shown in the first video, and performs extremely well at recreating animation styles like 3d animation. We are also very impressed with the prompt adherence achieved by these models.
Overall, Wan2.2 is a standout video model, and we encourage you to try it out today on the DigitalOcean Gradient Platform!
Closing Thoughts
In our experience, Wan2.2 is an amazing video model. Furthermore, it is very quick to access and setup Wan2.2 generation with the ComfyUI on a Gradient GPU Droplet. From photorealism to animation, Wan2.2 seems to be capable of doing it all in a way we haven’t seen before in the open-source world. We look forward to seeing how the Wan-Video team keep taking this model series forward.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
