By Mark Drake
Manager, Developer Education

Introduction
When designing a database, there may be times when you want to put limits on what data is allowed in certain columns. For example, if you’re creating a table that will hold information on skyscrapers, you may want the column holding each building’s height to prohibit negative values.
Relational database management systems (RDBMSs) allow you to control what data gets added to a table with constraints. A constraint is a special rule that applies to one or more columns — or to an entire table — that restricts what changes can be made to a table’s data, whether through an INSERT, UPDATE, or DELETE statement.
This article will review in detail what constraints are and how they’re used in RDBMSs. It will also walk through each of the five constraints defined in the SQL standard and explain their respective functions.
What Are Constraints?
In SQL, a constraint is any rule applied to a column or table that limits what data can be entered into it. Any time you attempt to perform an operation that changes that data held in a table — such as an INSERT, UPDATE, or DELETE statement — the RDBMS will test whether that data violates any existing constraints and, if so, return an error.
Database administrators often rely on constraints to ensure that a database follows a set of defined business rules. In the context of a database, a business rule is any policy or procedure that a business or other organization follows and that its data must adhere to as well. For instance, say you’re building a database that will catalog a client’s store inventory. If the client specifies that each product record should have a unique identification number, you could create a column with a UNIQUE constraint that will ensure no two entries in that column are the same.
Constraints are also helpful with maintaining data integrity. Data integrity is a broad term that’s often used to describe the overall accuracy, consistency, and rationality of data held in a database, based on its particular use case. Tables in a database are often closely related, with columns in one table being dependent on the values in another. Because data entry is often prone to human error constraints are useful in cases like this, as they can help ensure that no incorrectly entered data could impact such relationships and thus harm the database’s data integrity.
Imagine you’re designing a database with two tables: one for listing current students at a school and another for listing members of that school’s basketball team. You could apply a FOREIGN KEY constraint to a column in the basketball team table which refers to a column in the school table. This will establish a relationship between the two tables by requiring any entry to the team table to refer to an existing entry in the students table.
Users define constraints when they first create a table, or they can add them later on with an ALTER TABLE statement as long as it doesn’t conflict with any data already in the table. When you create a constraint, the database system will generate a name for it automatically, but in most SQL implementations you can add a custom name for any constraint. These names are used to refer to constraints in ALTER TABLE statements when changing or removing them.
The SQL standard formally defines just five constraints:
PRIMARY KEYFOREIGN KEYUNIQUECHECKNOT NULL
Note: Many RDBMSs include the DEFAULT keyword, which is used to define a default value for a column other than NULL if no value is specified when inserting a row. The documentation of some of these database management systems refer to DEFAULT as a constraint, as their implementations of SQL use a DEFAULT syntax similar to that of constraints like UNIQUE or CHECK. However, DEFAULT technically is not a constraint since it doesn’t restrict what data can be entered into a column.
Now that you have a general understanding of how constraints are used, let’s take a closer look at each of these five constraints.
PRIMARY KEY
PRIMARY KEYThe
PRIMARY KEYconstraint requires every entry in the given column to be both unique and notNULL, and allows you to use that column to identify each individual row in the table
In the relational model, a key is a column or set of columns in a table in which every value is guaranteed to be unique and to not contain any NULL values. A primary key is a special key whose values are used to identify individual rows in a table, and the column or columns that comprise the primary key can be used to identify the table throughout the rest of the database.
This is an important aspect of relational databases: with a primary key, users don’t need to know where their data is physically stored on a machine and their DBMS can keep track of each record and return them on an ad hoc basis. In turn, this means that records have no defined logical order, and users have the ability to return their data in whatever order or through whatever filters they wish.
You can create a primary key in SQL with the PRIMARY KEY constraint, which is essentially a combination of the UNIQUE and NOT NULL constraints. After defining a primary key, the DBMS will automatically create an index associated with it. An index is a database structure that helps to retrieve data from a table more quickly. Similar to an index in a textbook, queries only have to review entries from the indexed column to find the associated values. This is what allows the primary key to act as an identifier for each row in the table.
A table can only have one primary key but, like regular keys, a primary key can comprise more than one column. With that said, a defining feature of primary keys is that they use only the minimal set of attributes needed to uniquely identify each row in a table. To illustrate this idea, imagine a table that stores information about students at a school using the following three columns:
studentID: used to hold each student’s unique identification numberfirstName: used to hold each student’s first namelastName: used to hold each student’s last name
It’s possible that some students at the school could share a first name, making the firstName column a poor choice of a primary key. The same is true for the lastName column. A primary key consisting of both the firstName and lastName columns could work, but there’s still a possibility that two students could share a first and last name.
A primary key consisting of the studentID and either the firstName or lastName columns could work, but since each student’s identification number is already known to be unique, including either of the name columns in the primary key would be superfluous. So in this case the minimal set of attributes that can identify each row, and would thus be a good choice for the table’s primary key, is just the studentID column on its own.
If a key is made up of observable application data (that is, data that represents real world entities, events, or attributes) it’s referred to as a natural key. If the key is generated internally and doesn’t represent anything outside the database, it’s known as a surrogate or synthetic key. Some database systems recommend against using natural keys, as even seemingly constant data points can change in unpredictable ways.
FOREIGN KEY
FOREIGN KEYThe
FOREIGN KEYconstraint requires that every entry in the given column must already exist in a specific column from another table.
If you have two tables that you’d like to associate with one another, one way you can do so is by defining a foreign key with the FOREIGN KEY constraint. A foreign key is a column in one table (the “child” table) whose values come from a key in another table (the “parent”). This is a way to express a relationship between two tables: the FOREIGN KEY constraint requires that values in the column on which it applies must already exist in the column that it references.
The following diagram highlights such a relationship between two tables: one used to record information about employees at a company and another used to track the company’s sales. In this example, the primary key of the EMPLOYEES table is referenced by the foreign key of the SALES table:
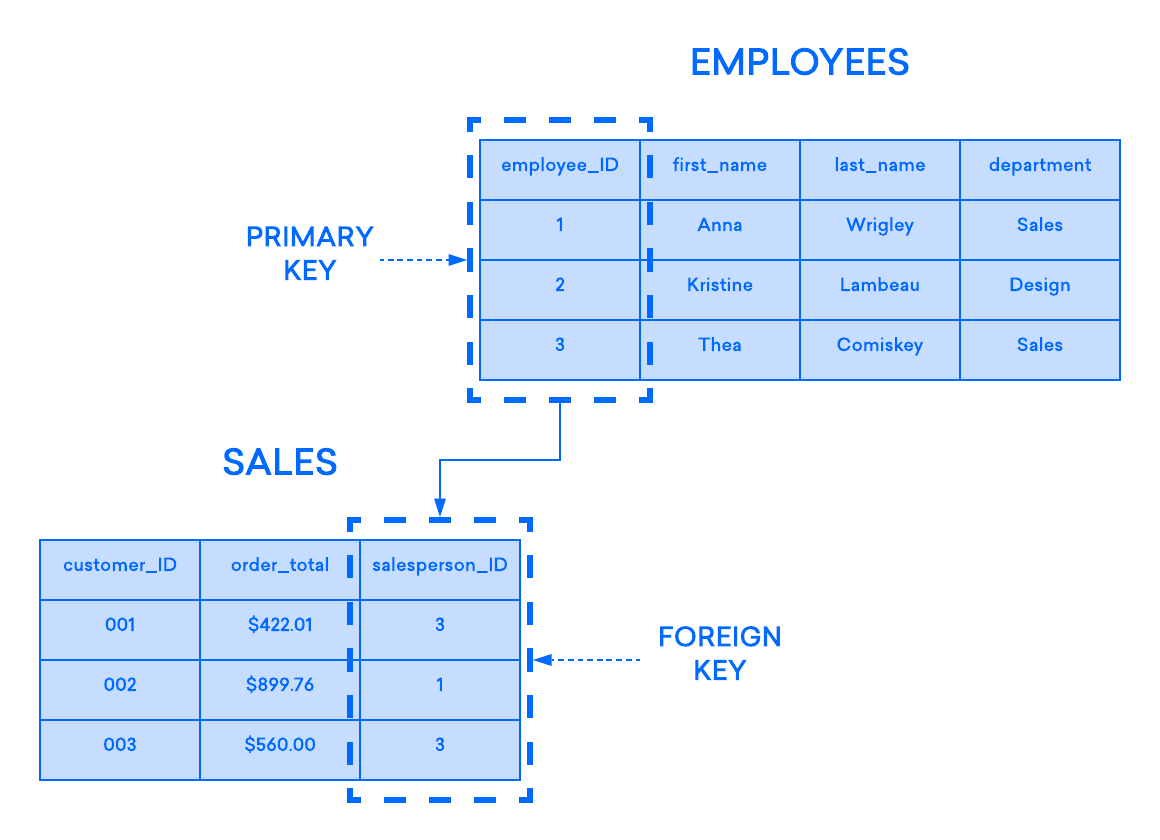
If you try to add a record to the child table and the value entered into the foreign key column doesn’t exist in the parent table’s primary key, the insertion statement will be invalid. This helps to maintain relationship-level integrity, as the rows in both tables will always be related correctly.
Oftentimes, a table’s foreign key is the parent table’s primary key, but this isn’t always the case. In most RDBMSs, any column in the parent table that has a UNIQUE or PRIMARY KEY constraint applied to it can be referenced by the child table’s foreign key.
UNIQUE
UNIQUEThe
UNIQUEconstraint prohibits any duplicate values from being added to the given column.
As its name implies, a UNIQUE constraint requires every entry in the given column to be a unique value. Any attempt to add a value that already appears in the column will result in an error.
UNIQUE constraints are useful for enforcing one-to-one relationships between tables. As mentioned previously, you can establish a relationship between two tables with a foreign key, but there are multiple kinds of relationships that can exist between tables:
- one-to-one: Two tables are said to have a one-to-one relationship if rows in the parent table are related to one and only one row in the child table
- one-to-many: In a many-to-any relationship, a row in the parent table can relate to multiple rows in the child table, but each row in the child table can only relate to one row in the parent
- many-to-many: If rows in the parent table can relate to multiple rows in the child table, and vice versa, the two are said to have a many-to-many relationship
By adding a UNIQUE constraint to a column on which a FOREIGN KEY constraint has been applied, you can ensure that each entry in the parent table appears only once in the child, thereby establishing a one-to-one relationship between the two tables.
Note that you can define UNIQUE constraints at the table level as well as the column level. When defined at the table level, a UNIQUE constraint can apply to more than one column. In cases like this, each column included in the constraint can have duplicate values but every row must have a unique combination of values in the constrained columns.
CHECK
CHECKA
CHECKconstraint defines a requirement for a column, known as a predicate, that every value entered into it must meet.
CHECK constraint predicates are written in the form of an expression that can evaluate to either TRUE, FALSE, or potentially UNKNOWN. If you attempt to enter a value into a column with a CHECK constraint and the value causes the predicate to evaluate to TRUE or UNKNOWN (which happens for NULL values), the operation will succeed. However, if the expression resolves to FALSE, it will fail.
CHECK predicates often rely on a mathematical comparison operator (like <, >, <=, OR >=) to limit the range of data allowed into the given column. For instance, one common use for CHECK constraints is to prevent certain columns holding negative values in cases where a negative value wouldn’t make sense, as in the following example.
This CREATE TABLE statement creates a table named productInfo with columns for each product’s name, identification number, and price. Because it wouldn’t make sense for a product to have a negative price, this statement imposes a CHECK constraint on the price column to ensure that it only contains positive values:
- CREATE TABLE productInfo (
- productID int,
- name varchar(30),
- price decimal(4,2)
- CHECK (price > 0)
- );
Not every CHECK predicate must use a mathematical comparison operator. Typically, you can use any SQL operator that can evaluate to TRUE, FALSE, or UNKNOWN in a CHECK predicate, including LIKE, BETWEEN, IS NOT NULL, and others. Some SQL implementations, but not all, even allow you to include a subquery in a CHECK predicate. Be aware, though, that most implementations do not allow you to reference another table in a predicate.
NOT NULL
NOT NULLThe
NOT NULLconstraint prohibits anyNULLvalues from being added to the given column.
In most implementations of SQL, if you add a row of data but don’t specify a value for a certain column, the database system will by default represent the missing data as NULL. In SQL, NULL is a special keyword used to represent an unknown, missing, or otherwise unspecified value. However, NULL is not a value itself but instead the state of an unknown value.
To illustrate this difference, imagine a table used to track clients at a talent agency that has columns for each client’s first and last names. If a client goes by a mononym — like “Cher”, “Usher”, or “Beyoncé” — the database administrator might only enter the mononym in the first name column, causing the DBMS to enter NULL in the last name column. The database doesn’t consider the client’s last name to literally be “Null.” It just means that the value for that row’s last name column is unknown or the field doesn’t apply for that particular record.
As its name implies, the NOT NULL constraint prevents any values in the given column from being NULL. This means that for any column with a NOT NULL constraint, you must specify a value for it when inserting a new row. Otherwise, the INSERT operation will fail.
Conclusion
Constraints are essential tools for anyone looking to design a database with a high level of data integrity and security. By limiting what data gets entered into a column, you can ensure that relationships between tables will be maintained correctly and that the database adheres to the business rules that define its purpose.
For more detailed information on how to create and manage SQL constraints, you can review our guide on How To Use Constraints in SQL. If you’d like to learn more about SQL in general, we encourage you to check out our series on How To Use SQL.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
Tutorial Series: How To Use SQL
Series Description
Structured Query Language — commonly known as SQL — is a language used to define, control, manipulate, and query data held in a relational database. SQL has been widely adopted since it was first developed in the 1970s, and today it’s the predominant language used to manage relational database management systems.
Ideal for managing structured data (data that can fit neatly into an existing data model), SQL is an essential tool for developers and system administrators in a wide variety of contexts. Also, because of its maturity and prevalence, candidates with SQL experience are highly sought after for jobs across a number of industries.
This series is intended to help you get started with using SQL. It includes a mix of conceptual articles and tutorials which provide introductions to various SQL concepts and practices. You can also use the entries in this series for reference while you continue to hone your skills with SQL.
Note: Please be aware that the tutorials in this series use MySQL in examples, but many RDBMSs use their own unique implementations of SQL. Although the commands outlined in this tutorial will work on most RDBMSs, the exact syntax or output may differ if you test them on a system other than MySQL.
Browse Series: 27 tutorials
Tutorial Series: Getting Started With Cloud Computing
This curriculum introduces open-source cloud computing to a general audience along with the skills necessary to deploy applications and websites securely to the cloud.
Browse Series: 39 tutorials
About the author
Former Technical Writer at DigitalOcean. Focused on SysAdmin topics including Debian 11, Ubuntu 22.04, Ubuntu 20.04, Databases, SQL and PostgreSQL.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
I’d like to say it’s one of the best articles I’ve ever seen in this topic of constraints in sql , keep it up authors
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
