AI/ML Technical Content Strategist

One of the rising use cases for AI technologies is audio and music generation. Projects like ElevenLabs and Suno, respectively, are dominant in this space with their closed-source technologies, for good reason. They have so many different applications for creating audio of different types that the limit is really the user’s imagination. Open source technologies have lagged behind these private companies’ models for some time, though.
Not any longer! With ACE Studio’s new Ace-Step-1.5 model, users can now generate custom music in just moments & create their own LoRA models to customize the outputs even further.
This incredible step forward for the open source music world was released last week, and has immediately made an impact on the community. Follow along with this tutorial to learn step-by-step how to fine-tune your own LoRA model on ACE Studio’s Ace-Step-1.5 LoRA training GUI and use it to generate custom music.
Key Takeaways
- Open-source reaches commercial quality. ACE-Step 1.5 delivers music generation that rivals proprietary platforms while remaining fully open and safe for professional use.
- Fast, lightweight, and affordable. Full songs can be created in seconds and the model runs locally on GPUs with under 4GB of VRAM, making high-end generation accessible to small teams and individual creators.
- Personalize with your own style. With built-in LoRA training tools, you can fine-tune the model on just a handful of tracks to capture specific voices, genres, or artistic identities.
ACE-Step 1.5
ACE-Step 1.5 is the latest audio generation model from ACE Studio. a highly efficient open-source music foundation model, this latest release in their ACE-Step model series brings commercial-grade generation to consumer hardware. “On commonly used evaluation metrics, ACE- Step v1.5 achieves quality beyond most commercial music models while remaining extremely fast—under 2 seconds per full song on an A100 and under 10 seconds on an RTX 3090.” The model runs locally with less than 4GB of VRAM, and supports lightweight personalization: users can train a LoRA from just a few songs to capture their own style.
At the heart of the system is a hybrid design in which the language model acts as a universal planner, converting straightforward prompts into detailed musical blueprints that can range from brief motifs to full ten-minute tracks. Through chain-of-thought style reasoning, it generates the structure, metadata, lyrics, and captions that steer the diffusion transformer during audio synthesis. Rather than depending on human feedback or external reward models, alignment is driven by intrinsic reinforcement learning rooted entirely in the model’s internal signals, reducing bias while preserving flexibility. Beyond generation, ACE-Step v1.5 combines granular stylistic steering with powerful editing functions — including cover creation, repainting, and vocal-to-instrumental transformation — and maintains strong prompt fidelity across more than fifty languages, enabling seamless integration into professional creative workflows for musicians, producers, and content creators.
How it works
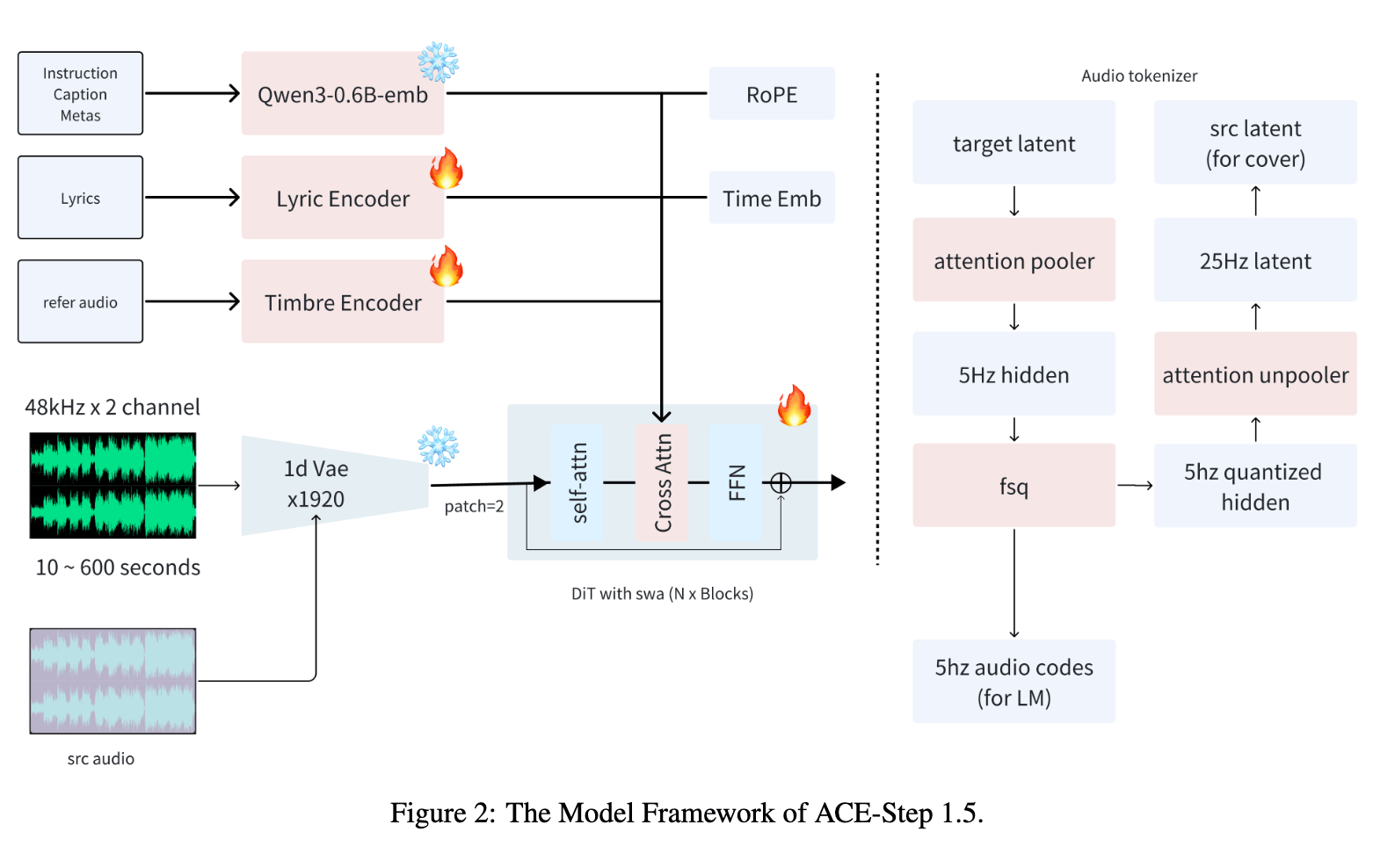
ACE-Step 1.5 is built like a digital music studio run by two cooperating brains. One part is designed to hear and rebuild sound with extremely high quality, compressing raw audio into a smaller form so the system can work fast while still keeping details like crisp vocals and punchy drums. Another part acts as the sound generator, turning instructions about style, mood, instruments, and lyrics back into full music. What makes the system special is that it doesn’t just create songs from text — it can also remake a track in a new style, fix or replace sections, pull instruments apart, add new layers, or expand a small idea into a full arrangement (Source). A separate language model plays the role of a composer and planner. Before any sound is produced, it thinks through the request and writes a structured plan: things like tempo, key, song layout, and captions. Depending on how it’s used, it can invent a plan from a vague idea, describe music it hears, help a user build a richer composition, or clean up messy instructions so the audio generator can perform better. Because everything follows a shared format, the model’s output can plug easily into other music tools, making it practical for real creative workflows (Source).
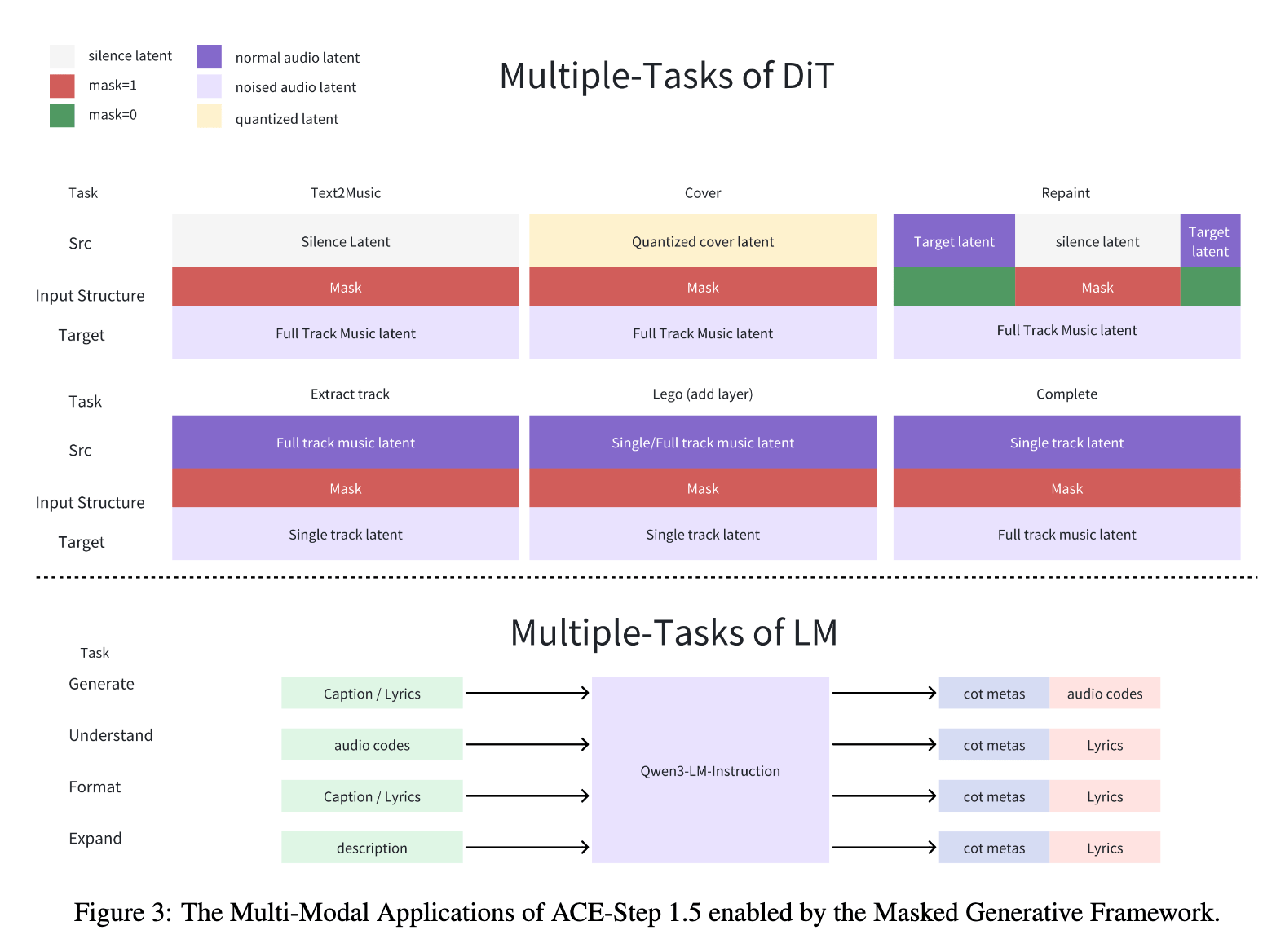
The model is capable of using this process to complete a number of tasks: Text-to-music, covering an artist, and “repainting” a song (which is essentially remixing a portion of a single track). It can achieve this versatility by altering the masking used to generate the song. Now that we are familiar with what ACE-Step 1.5 can do, we are ready to start the demo.
ACE-Step 1.5 LoRA Training Demo
To get started, spin up a GPU Droplet on the DigitalOcean AI Platform. We recommend an NVIDIA H100 or NVIDIA H200 for this demo, but any GPU on DO will be sufficiently powerful to run this demo. Follow this tutorial to get started setting up your Droplet for the demo. Once you’ve spun it up and accessed the GPU Droplet via SSH, paste the following into the terminal.
# 1. Install uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 2. Clone & install
git clone https://github.com/ACE-Step/ACE-Step-1.5.git
cd ACE-Step-1.5
uv sync
# 3. Launch Gradio UI (models auto-download on first run)
uv run acestep
This will install all the required packages using UV, and then launch the ACE Step Studio GUI for us to access on our local machine. Use VS Code/Cursor’s simple browser feature to access the web application in your local browser.
Generating Music
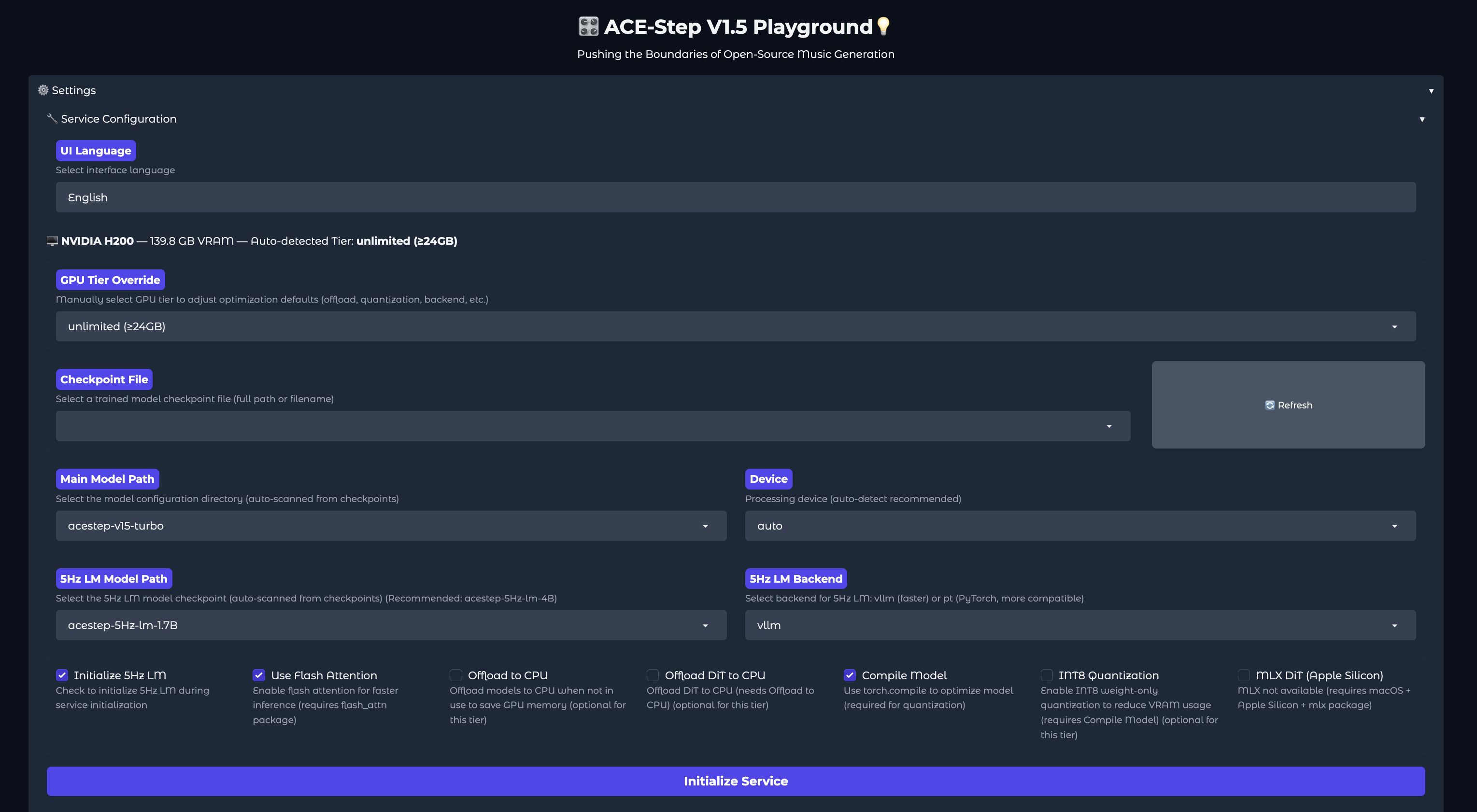
Now that we have our GUI open, we can click “Initialize Service” to load the application’s model into memory. Scroll down, and you should find the tab separated section for song generation and lora training.
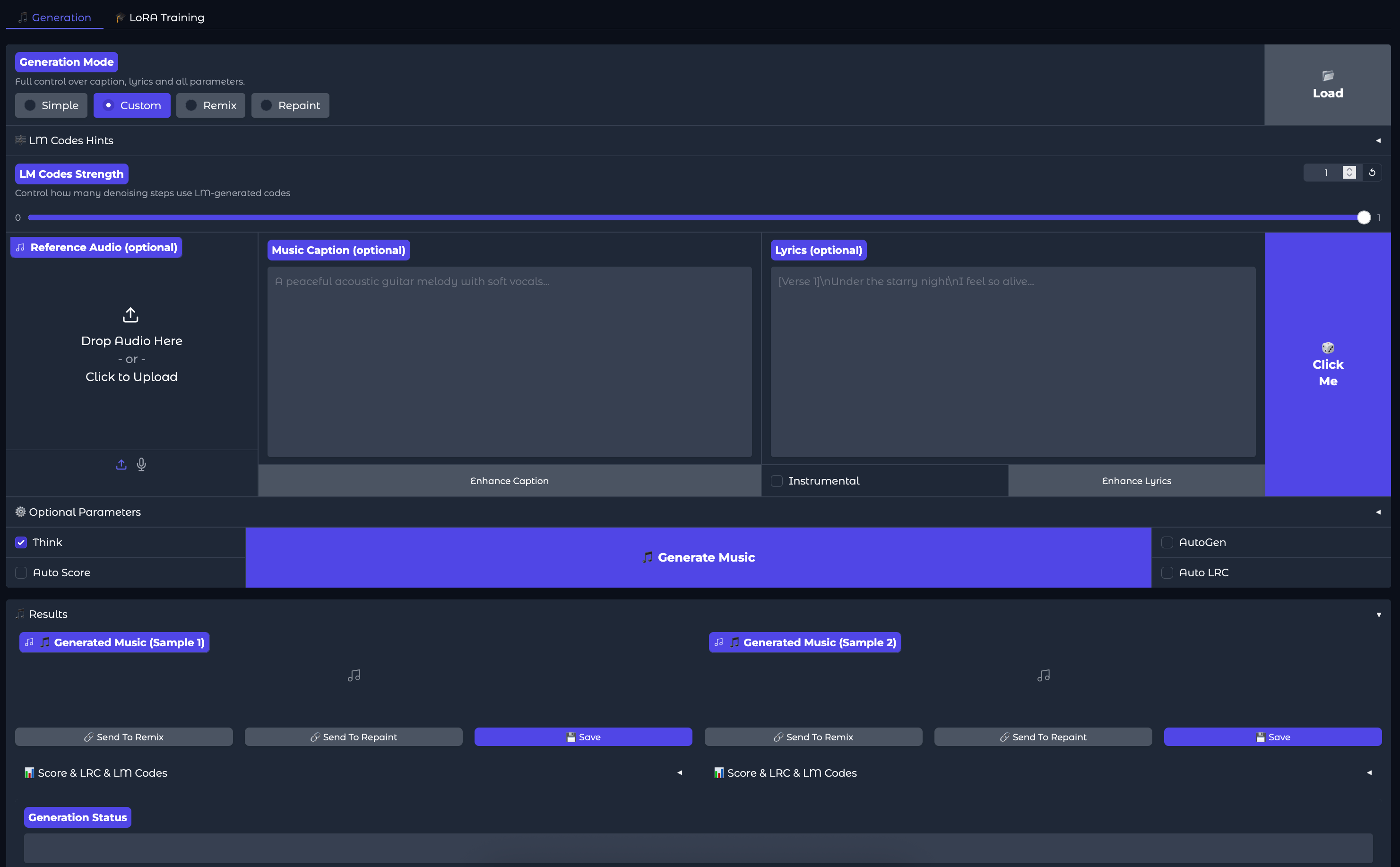
We can now generate music using the default settings. We recommend raising the number of steps taken from 8 to 20 to get better results from the default settings. Click on the button that says “Click Me” with the Dice emoji to get a random song sample description and lyrics, and then hit “Generate Music” to generate the songs. Below, we can see an example we made using this exact setup:
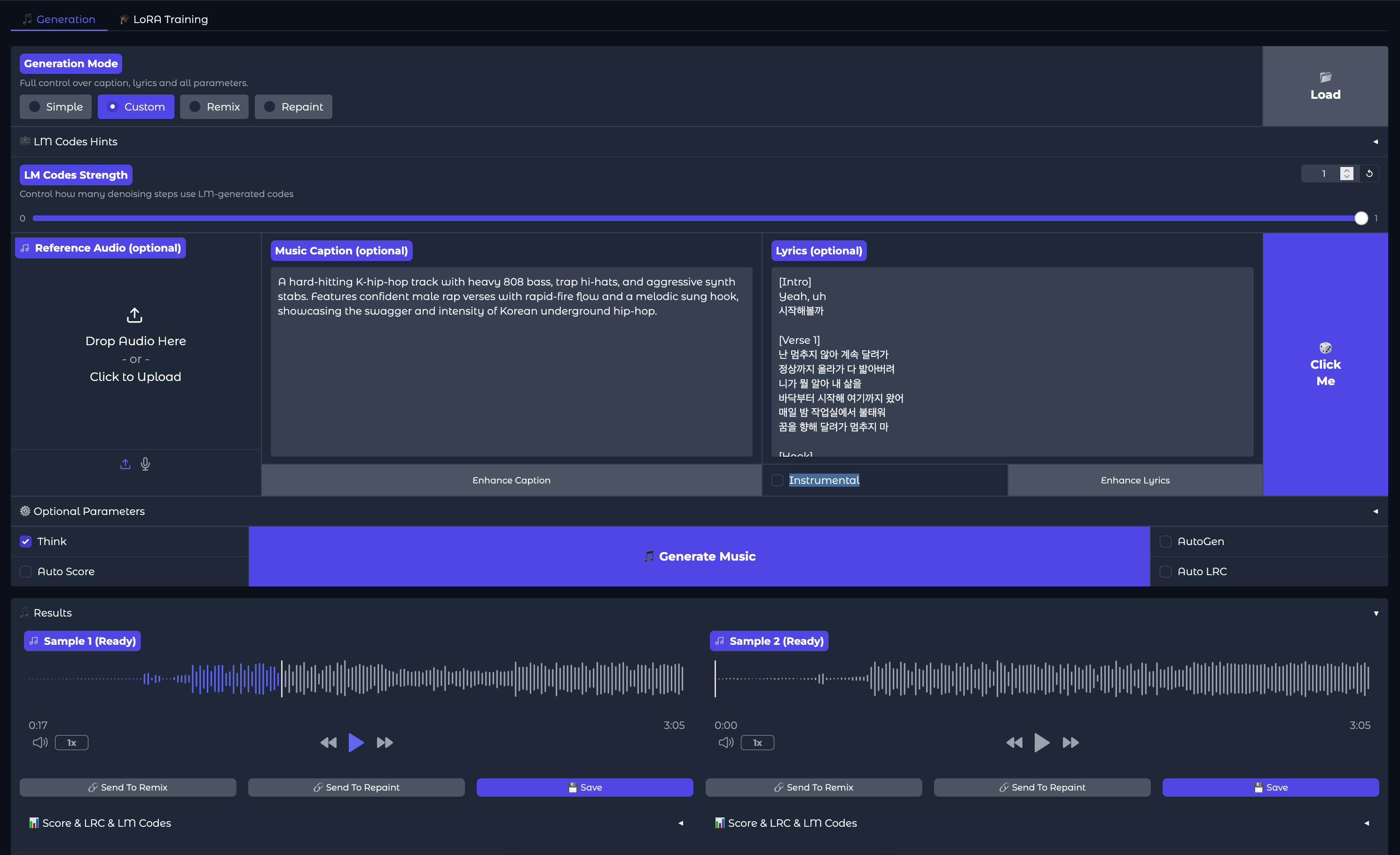
The two songs below can then be listened to and downloaded using the web UI.
Training a LoRA
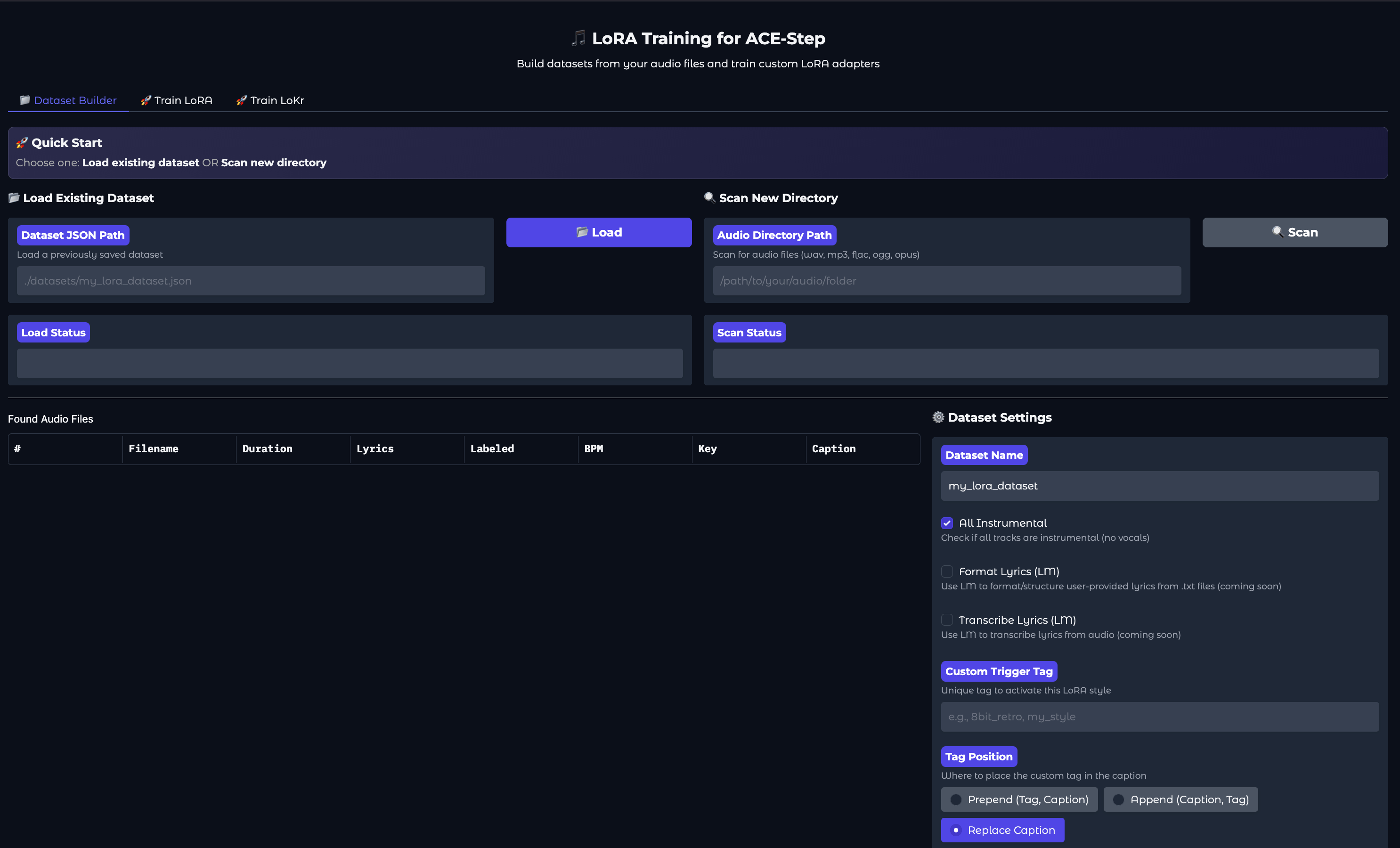
Training a LoRA is obviously a bit more involved. Click the Lora Training” tab to get started. Then, source your music data. The higher-quality the better. We recommend getting music with the same singer if your goal is to emulate their voice and style, and to limit tracks with featured additional artists that may muddy the training waters.
Next, upload the music data to your GPU Droplet, and enter the path to the directory holding the files where prompted in the UI. Once your files are uploaded, click the “Auto-Label All” button in the section below. This will automatically caption and create meta-data for the dataset as needed.
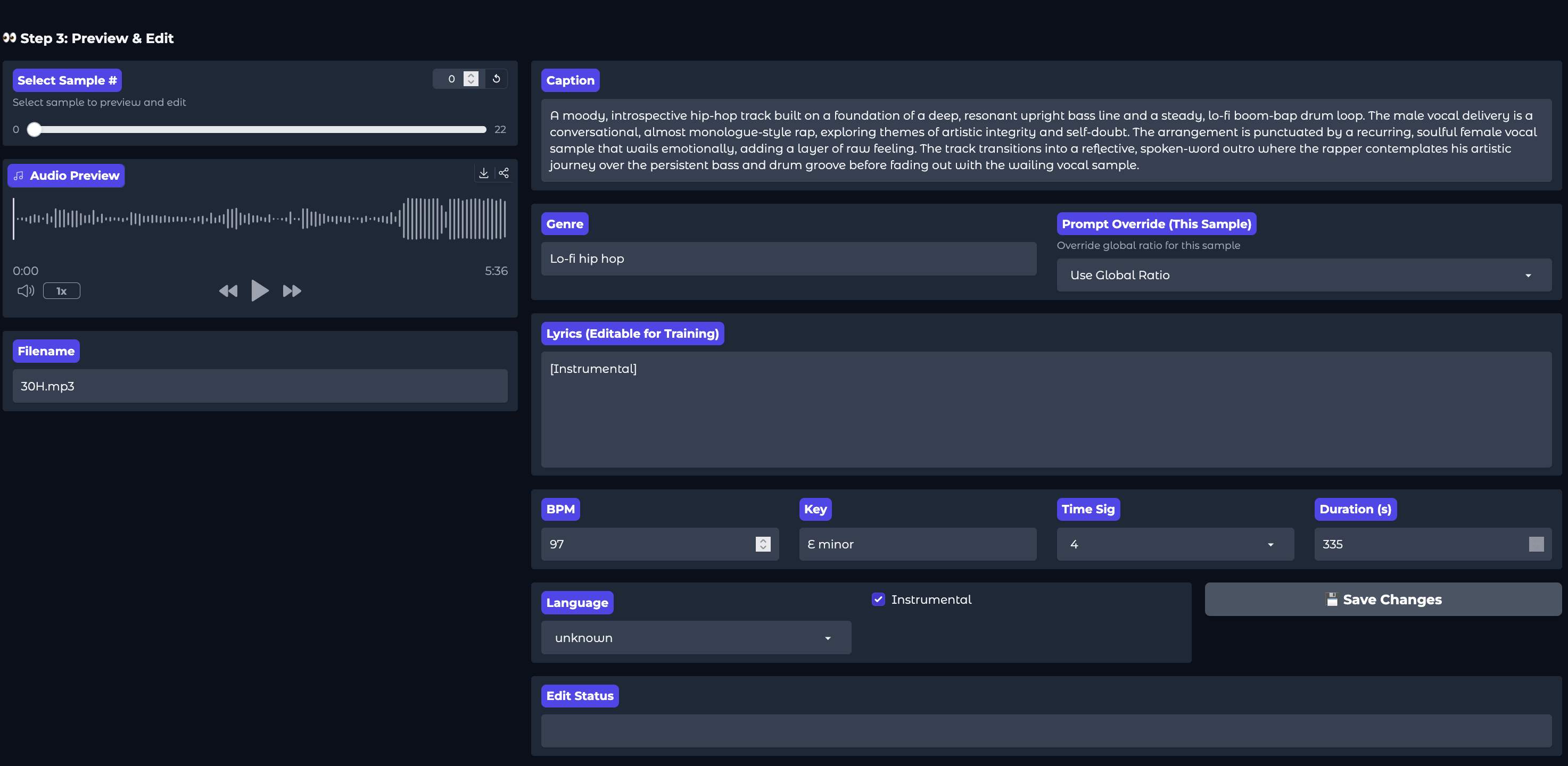
Then, go through each song using the slider on the left. Make appropriate edits to the caption and lyrics where necessary. As of right now, you need to manually add all lyrics if you wish to get the best results.
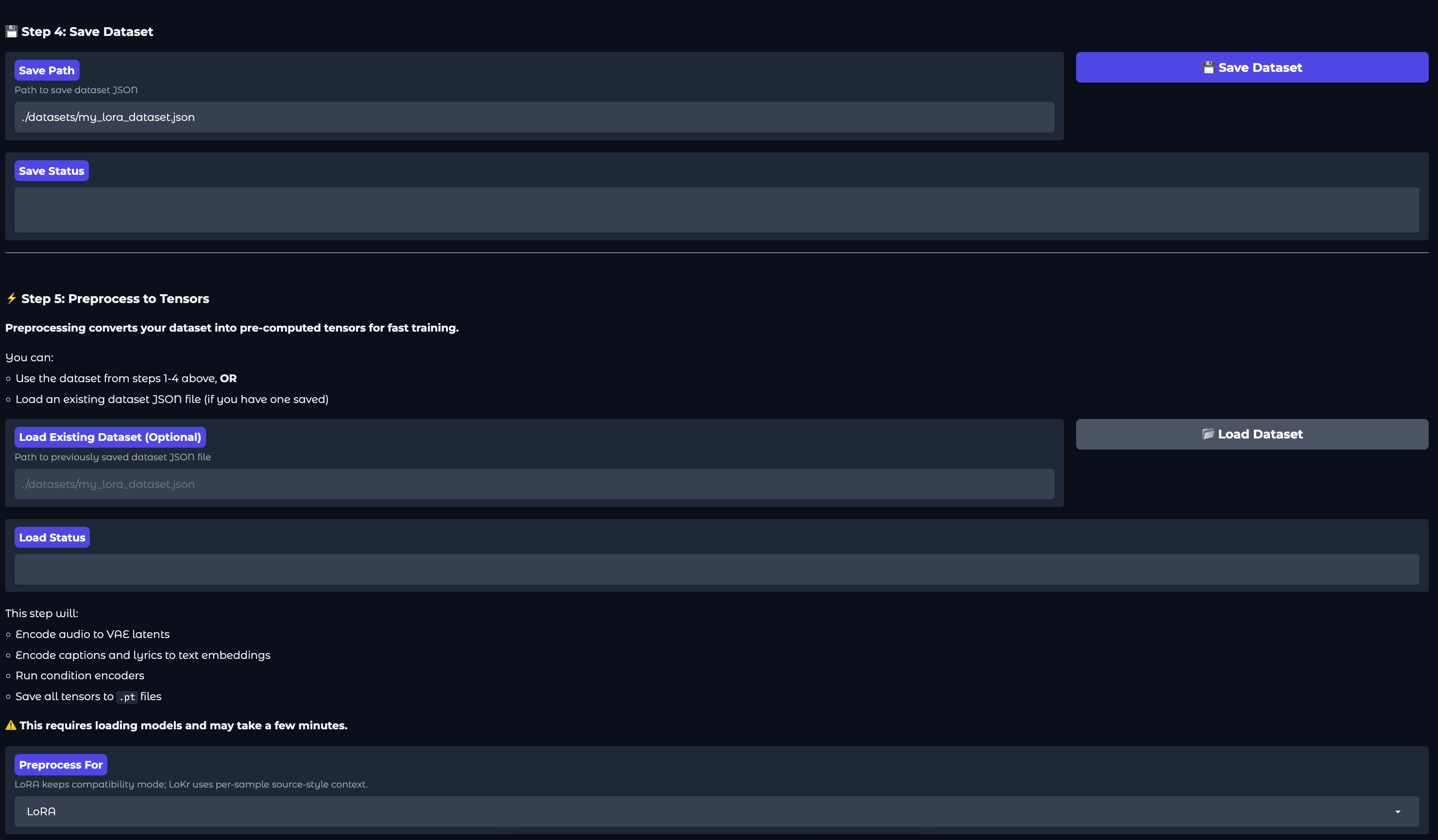
Finally, we create the dataset and preprocess the data into an appropriate tensor format. This effectively encodes the audio inputs to VAE latents, encodes captions and lyrics to text embeddings, runs condition encoders, and then saves all tensors to .pt files.
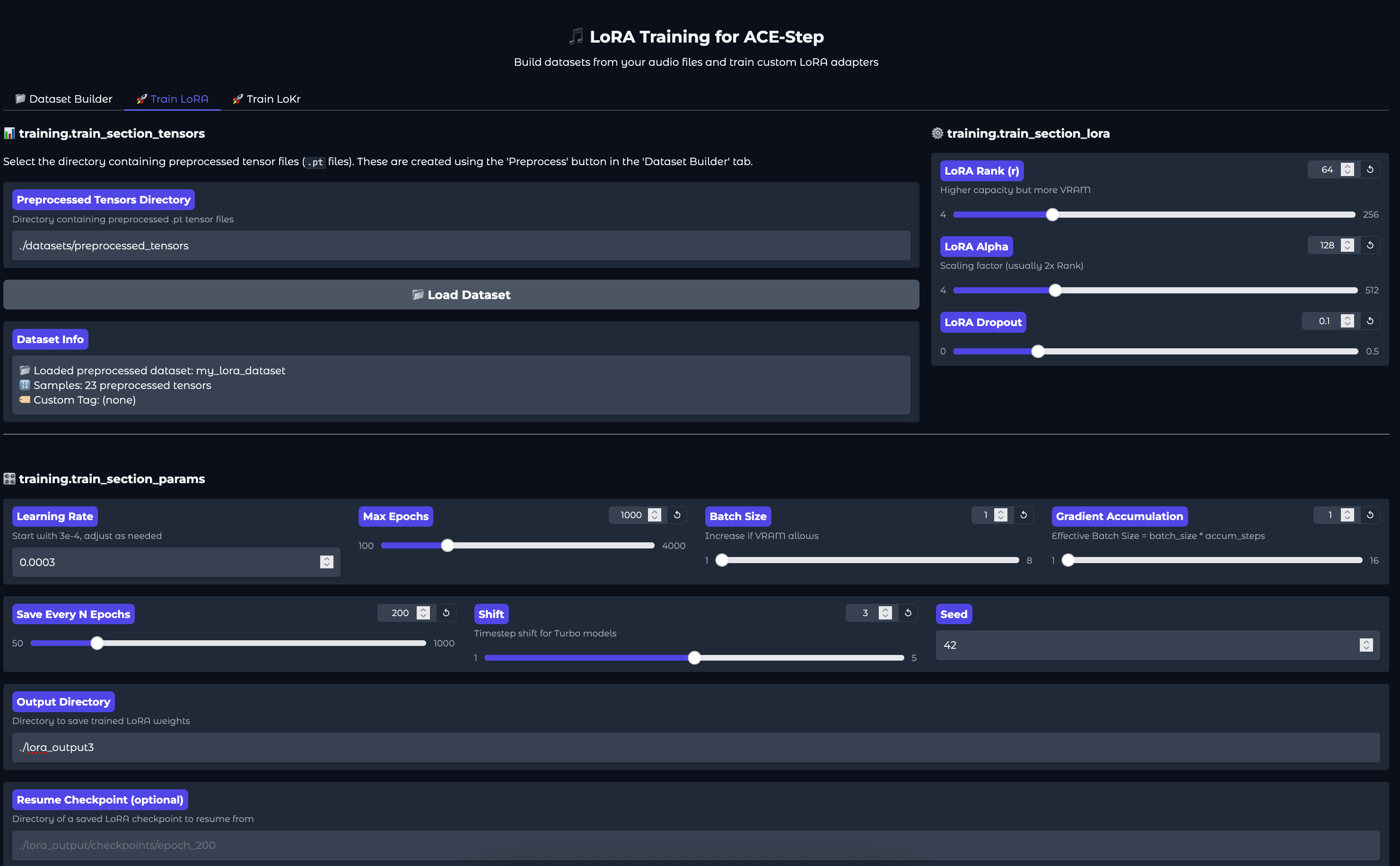
Navigate back to the top of this section, and click into the tab “Train Lora”. Load your dataset from the directory we saved it to, then scroll down to the bottom to adjust the training hyperparameters. We had good results running the defaults.
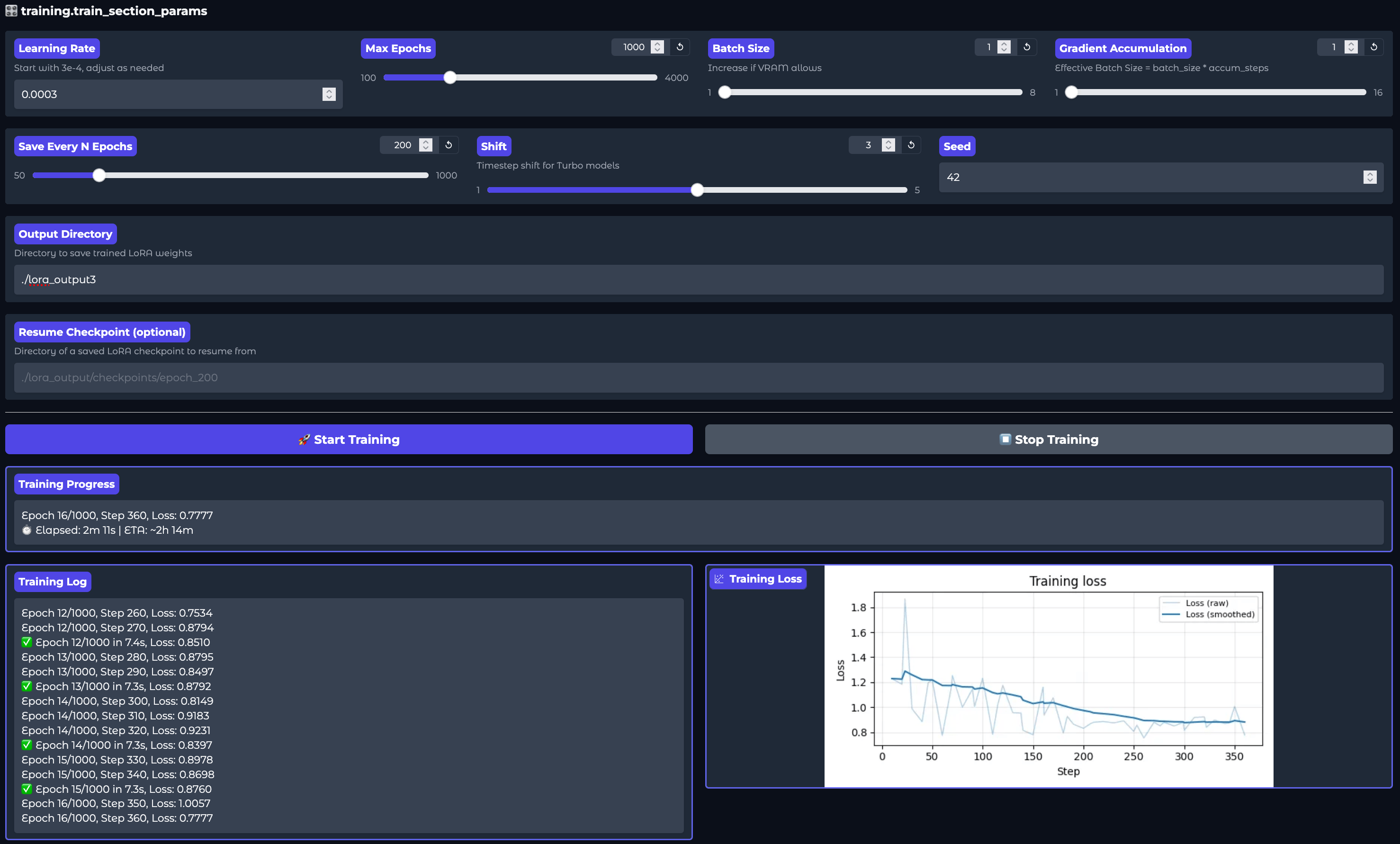
The training for a dataset with 23 songs takes about 2 and a half hours on an H200. We had great results mimicking the style, voice, and tone of the musical artist we tried training on, and were able to create new songs in their style using the LoRA.
Closing thoughts
ACE-Step 1.5 is seriously impressive, rivaling closed source models like Suno. We were able to create songs across a wide variety of genres, with different language singers in different styles. We highly recommend this model for tasks that involve music generation at scale, as the model can generate music in just moments with very little compute requirements.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
This comment has been deleted
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
