By Ahmed Fawzy Gad

Bayesian Decision Theory is the statistical approach to pattern classification. It leverages probability to make classifications and measures the risk (i.e., cost) of assigning an input to a given class.
In this article, we’ll begin by exploring prior probability and why relying on it alone is not the most effective approach for making predictions. We’ll then introduce Bayesian Decision Theory, which improves predictions by combining prior probability, likelihood, and evidence to compute the posterior probability. Each of these concepts will be explained in detail. Finally, we’ll connect the principles of Bayesian Decision Theory to their applications in machine learning. Here’s a breakdown of the article’s outline:
- Prior Probability
- Likelihood Probability
- Prior and Likelihood Probabilities
- Bayesian Decision Theory
- The sum of All Prior Probabilities Must be 1
- Sum of All Posterior Probabilities Must be 1
- Evidence
- Machine Learning & Bayesian Decision Theory
- Conclusion
After completing this article, you will have a strong foundation in applying Bayesian Decision Theory to real-world classification problems, including both binary and multi-class scenarios. We’ll also cover how to evaluate the performance of a classifier by examining key concepts like loss functions and prediction risk. In situations where a classifier is uncertain and produces low-confidence predictions, a special “reject” class can be introduced. This class allows the model to withhold decisions on samples it finds too ambiguous, improving overall reliability. We’ll dive into when it’s appropriate to assign a sample to the reject class, why it’s important for minimizing costly errors, and how it enhances decision-making in uncertain environments.
Prerequisites
- Classical machine learning theory: The mathematics used in this tutorial may require additional research to be understood if the reader does not have experience working with logical theory and notation.
- Python: Basic understanding of Python programming.
Prior Probability
Understanding Prior Probability and Its Limitations
Imagine someone asks you to predict the winner of an upcoming match between two teams, Team A and Team B.
In the last 10 cup matches, Team A won 4 times, while Team B won 6 times.
Based solely on this historical data, the probability that Team A will win the next match — known as the prior probability — is:
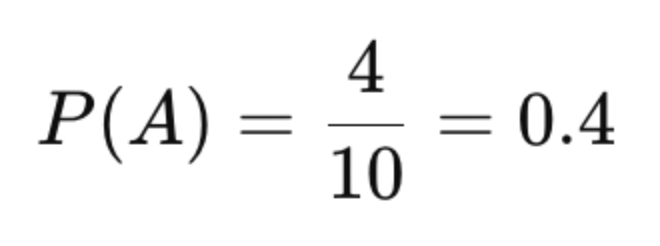
The prior probability is calculated purely from past outcomes without considering the current situation.
Why Prior Probability Can Be Misleading
However, relying only on prior probability may not always lead to accurate predictions because conditions can change over time.
For instance, Team A might have won fewer matches previously because key players were injured.
Now, for the upcoming match, all injured players have recovered. This change in circumstance could significantly increase Team A’s chances of winning — a factor that prior probability alone does not account for.
Thus, the prior probability represents a prediction based only on historical events, ignoring any new observations or updated information.
It’s similar to diagnosing a patient based only on general statistics from previous doctor visits, without considering their current symptoms or condition.
Moving Beyond Prior Probability: The Role of Likelihood
Since prior probability does not incorporate present context, it can degrade the quality of predictions when the situation has evolved.
Past outcomes occurred under certain conditions, but those conditions may no longer apply.
To address this, we introduce the concept of likelihood.
Likelihood allows us to update our predictions based on current observations, offering a more accurate and dynamic way to estimate outcomes.
Likelihood Probability
Understanding Likelihood in Predictions
The likelihood helps answer an important question:
Given certain conditions, what is the probability that a specific outcome occurs?
It is denoted as:
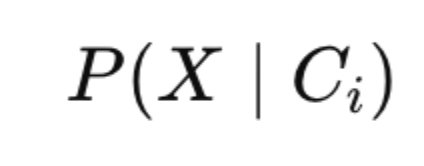
Where:
-
X represents the set of current conditions.
-
C i represents the i-th possible outcome (since there can be multiple outcomes).
In simple terms, likelihood measures:
Under the present conditions X, how likely is it that outcome C i will occur?
Applying Likelihood to Our Example
Continuing with the example of predicting a match outcome:
Previously, we considered only historical data to estimate the probability of Team A winning.
However, the likelihood approach also factors in current conditions.
Suppose:
-
Team A now has no injured players.
-
Team B is missing several key players due to injury.
Given these updated conditions, Team A is now more likely to win, even though the prior probability (based on past matches) might have suggested Team B had better odds.
Thus, the likelihood connects the current situation to the probability of an outcome, offering a more accurate prediction at the time of decision-making.
Real-World Analogy: Medical Diagnosis
A similar idea applies in medicine.
Rather than diagnosing a patient solely based on their past health records (prior information), doctors prioritize current symptoms to make more accurate diagnoses.
This reflects the use of likelihood: adjusting predictions based on the present state.
Why Likelihood Alone Isn’t Enough
While likelihood improves prediction by incorporating present observations, it ignores the experience encoded in prior probability.
Past events still hold valuable information, especially when current data is noisy or incomplete.
Therefore, the best approach is to combine both:
-
Prior probability (historical knowledge)
-
Likelihood (current observations)
This combination leads to more reliable and informed predictions — a principle at the heart of Bayesian Decision Theory.
Prior and Likelihood Probabilities
Using only the prior probability, the prediction is made based on experience. Using only the likelihood, the prediction depends only on the current situation. When either of these two probabilities is used alone, the result is not accurate enough. It is better to use both the experience and the current situation together in predicting the next outcome.
The new probability would be calculated as follows:
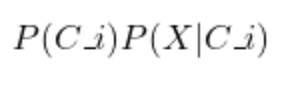
For the example of diagnosing a patient, the outcome would then be selected based on their medical history as well as their current symptoms.
Using both the prior and likelihood probabilities together is an important step towards understanding Bayesian Decision Theory.
Bayesian Decision Theory
Bayesian Decision Theory (i.e., the Bayesian Decision Rule) predicts the outcome not only based on previous observations, but also by taking into account the current situation. The rule describes the most reasonable action to take based on an observation.
The formula for Bayesian (Bayes) decision theory is given below:
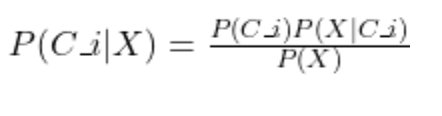
The elements of the theory are:
- P(Ci): Prior probability. This accounts for how many times the class C_i occurred independently from any conditions (i.e., regardless of the input X).
- P(X∣Ci): Likelihood. Under some conditions X, this is how many times the outcome C_i occurred.
- P(X): Evidence. The number of times the condition X occurred.
- P(Ci∣X): Posterior. The probability that the outcome Ci occurs given some conditions X.
Bayesian Decision Theory gives balanced predictions, as it takes into consideration the following:
- P(X): How often do the conditions X occur?
- P(C_i): How often does the outcome C_i occur?
- P(X∣C_i): How often do both the conditions X and the outcome C_i occur together?
If any of the previous factors were not used, the prediction would be hindered. Let’s explain the effect of excluding any of these factors, and mention a case where using each factor might help.
- P(C_i): Assume that the prior probability P(C_i) is not used; then we cannot know whether the outcome C_i occurs frequently or not. If the prior probability is high, then the outcome C_i frequently occurs, and it is an indication that it may occur again.
- P(X∣C_i): If the likelihood probability P(X∣C_i) is not used, then there is no information to associate with the current input X with the outcome C_i. For example, the outcome C_i may have occurred frequently, but it rarely occurs with the current input X.
- P(X): If the evidence probability P(X) is excluded, then there is no information to reflect the frequency of X occurring. Assuming that both the outcome C_i and the input X occur frequently together, the probability of predicting C_i given X should be high.
- If X occurs frequently, then the outcome is probably C_i when the input is X.
When there is information about the frequency of the occurrence of C_i alone, X alone, and both C_i and X together, then a better prediction can be made.
There are some things to note about the theory/rule:
- The sum of all prior probabilities must be 1.
- The sum of all posterior probabilities must be 1.
- The evidence is the sum of the products of the prior and likelihood probabilities of all outcomes.
The next three sections discuss each of these points.
The sum of all prior probabilities must be 1
Assuming there are two possible outcomes, then the following must hold:
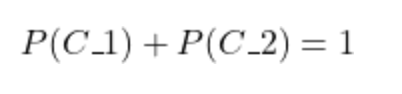
The reason is that for a given input, its outcome must be one of these two. There are no uncovered outcomes.
If there are K outcomes, then the following must hold:
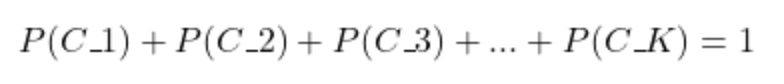
Here is how it is written using the summation operator, where i is the outcome index and K is the total number of outcomes:
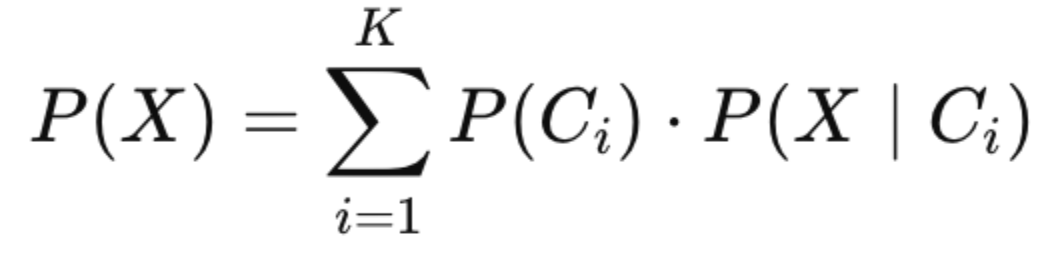
Note that the following condition must hold for all prior probabilities:
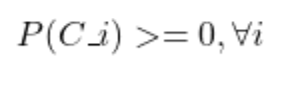
Sum of All Posterior Probabilities Must be 1
Similar to the prior probability, the sum of all posterior probabilities must be 1, according to the next equations.
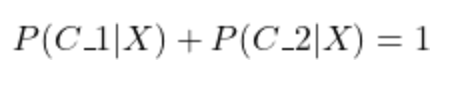
If the total number of outcomes is K, here is the sum using the summation operator:
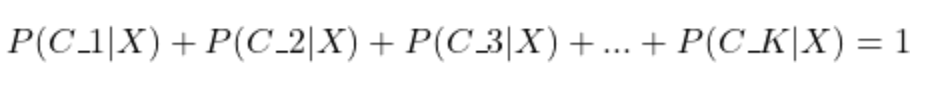
Here is how to sum all the posterior probabilities for K outcomes using the summation operator:
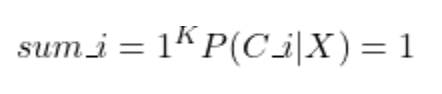
Evidence
Here is how the evidence is calculated when only two outcomes occur:
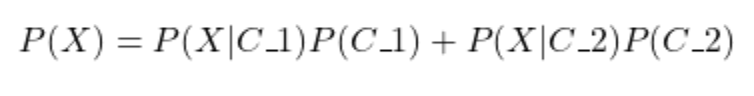
For K outcomes, here is how the evidence is calculated:
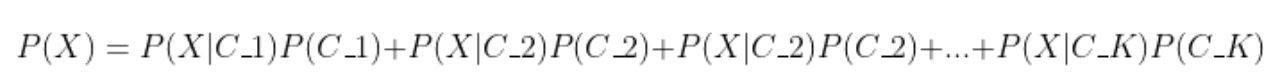
Here is how it is written using the summation operator:
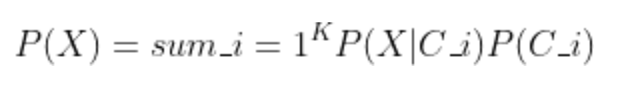
According to the latest equation of the evidence, the Bayesian Decision Theory (i.e., posterior) can be written as follows:
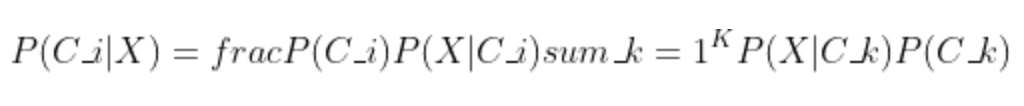
Machine Learning & Bayesian Decision Theory
This section matches the concepts in machine learning to Bayesian Decision Theory.
First, the word outcome should be replaced by class. Rather than saying the outcome is
C_i, it is more machine learning-friendly to say the class is C_i.
Here is a list that relates the factors in Bayesian Decision Theory to machine learning concepts:
- X is the feature vector.
- P(X) is the similarity between the feature vector X and the feature vectors used in training the model.
- C_i is the class label.
- P(C_i) is the number of times the model classified an input feature vector as the class C_i. The decision is independent of the feature vector X.
- P(X∣C_i) represents the experience of the previous machine learning model in associating feature vectors similar to X with the class C_i. In other words, it reflects how likely the input X is, given that the true class is C_i, thereby linking the current input to that specific class based on learned patterns.
When the following conditions apply, it is likely that the feature vector X is assigned to the class C_i:
- The model is trained on feature vectors that are close to the current input vector X. This increases P(X).
- The model is trained on some samples (i.e., feature vectors) that belong to the class C_i. This increases P(C_i).
- The model was trained to classify the samples close to X belongs to a class C_i. This increases P(X∣Ci).
When a classification model is trained, it learns how frequently each class C_i occurs in the training data. This frequency is captured as the prior probability P(C_i). Without this prior, the model loses valuable context about how common or rare each class is.
If the model were to rely solely on the prior probability P(C_i), it would make predictions based only on historical class frequencies—without considering the actual input X. In other words, it would assign a class label purely based on past data, even before analyzing the new input. This leads to uninformed and potentially inaccurate predictions.
On the other hand, the likelihood probability P(X∣C_i) represents how well the input sample X matches class P(C_i) based on patterns learned during training. This probability is crucial because it allows the model to evaluate the relationship between the current input and each possible class. Without it, the model cannot determine whether the features in X are actually associated with class P(C_i), thus making accurate classification impossible.
FAQ
Why is Bayesian Decision Theory important for pattern classification?
It provides a probabilistic framework that optimally combines prior knowledge and observed data for accurate decision-making.
How does Bayesian Decision Theory differ from classical decision-making methods?
It incorporates uncertainty and updates predictions using both past experience (priors) and current observations (likelihoods).
What is prior probability, and what does it represent?
Prior probability represents the likelihood of a class occurring based on past data, before observing the current input.
How are prior and likelihood probabilities combined in Bayesian Decision Theory?
They are multiplied and normalized by the evidence to compute the posterior probability, using Bayes’ theorem.
What role does evidence play in Bayesian predictions?
Evidence acts as a normalization factor, ensuring the posterior probabilities across all classes sum to one.
Conclusion
This article introduced Bayesian Decision Theory in the context of machine learning. It described all the elements of the theory, starting with prior probability P(C), the likelihood probability P(X∣C), the evidence P(X), and finally the posterior probability p(C∣X).
Bayesian Decision Theory offers a powerful and principled approach to pattern classification by systematically combining prior knowledge, current observations, and the overall evidence. Unlike classical decision-making methods that may overlook uncertainty or new information, Bayesian methods continuously update predictions to reflect both historical data and present conditions. Understanding the roles of prior probability, likelihood, and evidence is crucial for building more accurate and reliable classification models.
By applying these concepts, machine learning systems can make better-informed decisions, improving performance across a wide range of real-world applications.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
This is not Bayesian Decision Theory. It’s simply Bayesian classification. Bayesian Decision Theory goes a couple of steps further. Moreover there are a number of imprecisions. I would encourage you to hire or contract a true Bayesian, especially if you have to make decisions under uncertainty. Best of luck in any case.
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
