
Introduction
Large Language Models (LLMs) and Vision-Language Models (VLMs) face a persistent challenge: the computational cost of processing long documents. As the length of the text increases, so too does the number of tokens, leading to higher memory usage, slower inference, and more dollars spent.
DeepSeek-OCR is a proof-of-concept that proposes to inprove efficiency by using optical context compression to encode document pages as visual tokens, significantly reducing the token count compared to a text-only representation. To evaluate performance, the technique is tested on OCR (Optical Character Recognition) - which the paper describes as the “ideal testbed for for this vision-text compression paradigm, as [OCR] establishes a natural compression-decompression mapping between visual and textual representations while offering quantitative evaluation metrics.” The approach taken by DeepSeek-OCR reduces token counts by 7–20x while still exhibiting strong performance on benchmarks and therefore presents itself as a viable solution for efficient large-scale document processing and training data generation.
DeepSeek-OCR consists of two main components: DeepEncoder, which compresses document images into a small set of visual tokens, and DeepSeek-3B-MoE, a decoder that reconstructs the original text from these tokens. The model is designed to balance efficiency and accuracy, achieving competitive results on benchmarks such as OmniDocBench and Fox while using fewer tokens than existing solutions.
We’ve covered OCR models on DigitalOcean including Dolphin, olm-OCR, rolm-OCR, smoldocling, etc.
Key Takeaways
- Optical Context Compression for lower computational cost: DeepSeek-OCR introduces ‘optical context compression’, a technique that encodes document pages as visual tokens. By reducing the token count by 7–20x compared to traditional text tokens,there is a reduction in computational cost.
- Architecture: The model consists of DeepEncoder (for visual tokenization and compression via SAM and CLIP) and DeepSeek-3B-MoE-A570M (a highly efficient Mixture-of-Experts (MoE) decoder that reconstructs the text).
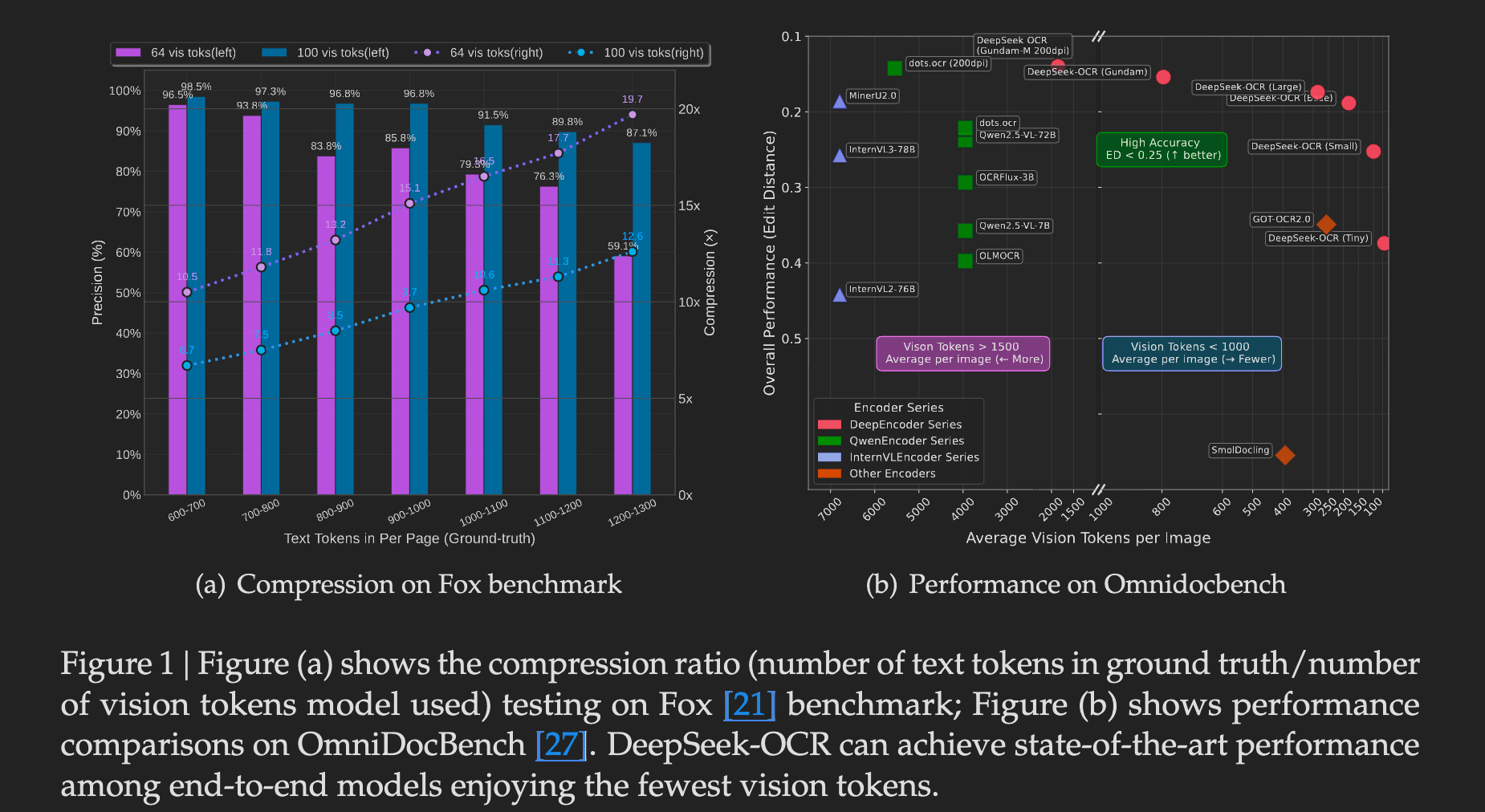
- Efficiency and Accuracy: It offers a strong balance, achieving high ~97% OCR precision at compression ratios less than 10x (i.e., the number of text tokens is within 10 times the number of vision tokens) and outperforming existing models on benchmarks like OmniDocBench with significantly fewer tokens.
- Training Data: Trained on over 30 million PDF pages in 100+ languages and specialized OCR 2.0 data (charts, formulas, figures), giving it robust capabilities across diverse document types and complex visual elements.
- Use Cases: Ideal for large-scale document digitization, AI training data generation for LLMs/VLMs, multilingual processing, and structured data extraction from technical documents.
DeepSeek-OCR Architecture
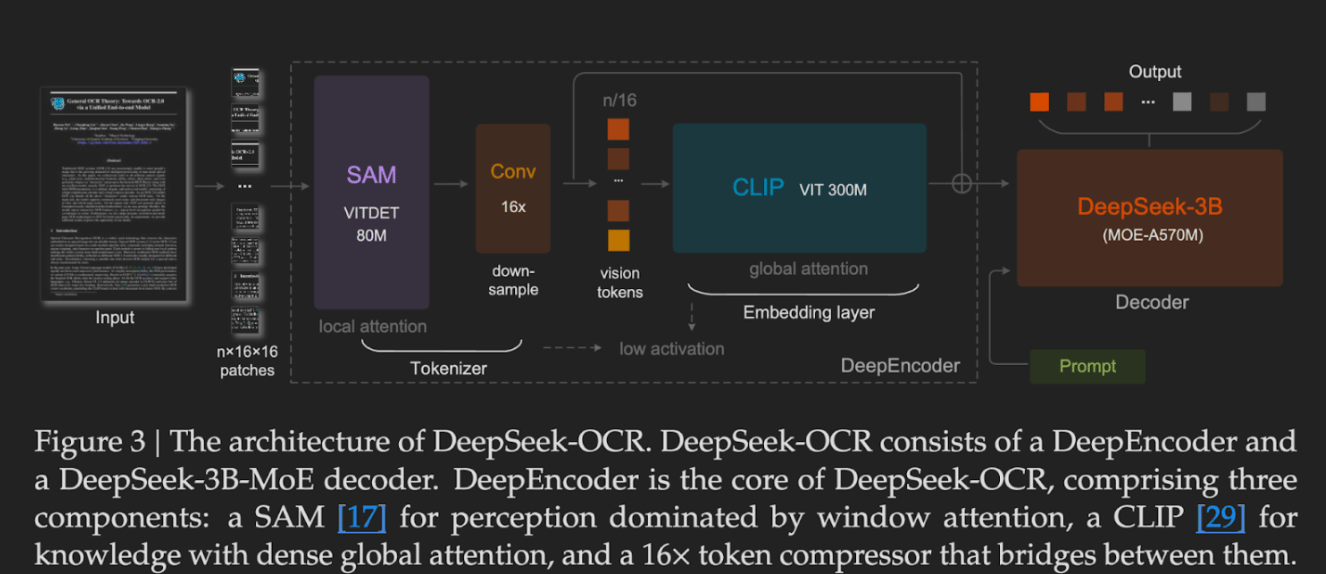
DeepEncoder: Visual Tokenization
DeepEncoder is a vision encoder designed to maintain low activation memory even with inputs of high resolution.
- Local attention via SAM (Segment Anything Model): (80M parameters) Captures fine-grained visual details and layout information.
- Global attention via CLIP (Contrastive Language–Image Pre-training): (300 M parameters) Extracts semantic features from the compressed visual tokens.
Decoder: DeepSeek3B-MoE-A570M
The decoder is based on DeepSeek’s Mixture-of-Experts (MoE) architecture, which activates only a subset of its 3B parameters during inference (approximately 570M). The strength of MoE is its efficiency while delivering comparable performance to larger models. The decoder reconstructs the original text from the compressed visual tokens, preserving layout and content where possible.
Training Data
DeepSeek-OCR was trained on an extensive and diverse dataset to ensure robust performance across various document types and languages. The training data includes over 30 million PDF pages spanning more than 100 languages, with particular emphasis on Chinese and English. Additionally, the model was trained on OCR 2.0 data comprising 10 million synthetic charts, 5 million chemical formulas, and 1 million geometric figures, which extends its capabilities beyond standard text extraction to handle specialized content such as scientific diagrams and financial charts. This comprehensive training approach enables the model to effectively process a wide range of document types and languages while maintaining strong performance on complex visual elements.
Performance and Benchmarks
Compression vs. Accuracy
DeepSeek-OCR’s performance varies with compression ratio. At compression levels below 10x, the model achieves approximately 97% OCR precision, effectively reconstructing the original text with minimal loss. At 20x compression, accuracy drops to around 60%, which may still be sufficient for archival or secondary use cases.
Comparative Results
On the OmniDocBench benchmark, DeepSeek-OCR outperforms competing models while using fewer tokens. With 100 tokens per page, it surpasses GOT-OCR2.0, which typically uses 256 tokens per page. With fewer than 800 tokens per page, it outperforms MinerU2.0, which typically requires over 6,000 tokens per page.
Practical Applications
DeepSeek-OCR is suited for several use cases. For large-scale document digitization, libraries, legal firms, and research institutions can process high volumes of documents efficiently. AI labs can use the model for training data generation to create text-image pairs for LLM pretraining, addressing data scarcity issues. The model’s support for over 100 languages makes it versatile for multilingual document processing in global applications. Additionally, its capability to parse charts, tables, and formulas makes it particularly useful for structured data extraction in technical and financial documents.
Implementation
from transformers import AutoModel, AutoTokenizer
import torch
model_name = "deepseek-ai/DeepSeek-OCR"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation="flash_attention_2",
trust_remote_code=True,
use_safetensors=True
).eval().cuda().to(torch.bfloat16)
# Load an image and run OCR
from PIL import Image
image = Image.open("document.png").convert("RGB")
prompt = "<image>\nFree OCR."
inputs = tokenizer(prompt, images=[image], return_tensors="pt").to("cuda")
output = model.generate(**inputs)
print(tokenizer.decode(output[0]))
Selecting a Resolution Mode

| Mode | Resolution | Vision Tokens | Typical Use Case |
|---|---|---|---|
| Tiny | 512x512 | 64 | Quick previews, low-res documents |
| Small | 640x640 | 100 | Standard documents |
| Base | 1024x1024 | 256 | High-resolution pages |
| Large | 1280x1280 | 400 | Complex layouts |
| Gundam | Dynamic | 795+ | Multi-column, dense documents |
Limitations and Considerations
There are several important considerations when using DeepSeek-OCR. Regarding accuracy versus compression, compression ratios beyond 10x may reduce accuracy, particularly for dense or low-resolution documents. While the Gundam mode improves handling of multi-column layouts, highly complex documents such as newspapers may still require manual review for layout complexity. For optimal performance, the model requires NVIDIA GPUs with CUDA support as a hardware requirement.
Frequently Asked Questions (FAQs)
What is DeepSeek-OCR?
DeepSeek-OCR is an open-source Vision-Language Model (VLM) developed by DeepSeek-AI, designed for highly efficient document processing. It converts document images into text using a unique optical context compression method to significantly reduce the computational burden.
How does DeepSeek-OCR achieve high efficiency?
It uses optical context compression via its DeepEncoder component. Instead of converting an entire page into a long sequence of text tokens, it compresses the visual information into a small set of visual tokens (7–20x fewer than standard text tokens), which are then decoded by the DeepSeek-3B-MoE decoder. This token reduction leads to faster inference and lower memory usage.
What is the architecture of DeepSeek-OCR?
The model has a dual-component architecture:
- DeepEncoder: Compresses document images into visual tokens using both SAM (for local visual detail) and CLIP (for global semantic context).
- DeepSeek-3B-MoE-A570M: A highly efficient Mixture-of-Experts (MoE) decoder that reconstructs the text from the visual tokens. It has 3 billion total parameters but only activates about 570 million during inference.
What is the trade-off between compression and accuracy?
DeepSeek-OCR maintains high accuracy (around 97% OCR precision) at moderate compression ratios (up to 10x). As the compression ratio increases beyond 10x (e.g., to 20x), the accuracy drops to around 60%. Users must select a compression mode that balances their required precision with computational efficiency.
What kind of data was DeepSeek-OCR trained on?
The model was trained on an extensive dataset of over 30 million PDF pages in 100+ languages. Crucially, it was also trained on OCR 2.0 data, which includes millions of synthetic charts, chemical formulas, and geometric figures, enabling it to handle complex and specialized visual elements beyond plain text.
Can DeepSeek-OCR handle multilingual documents?
Yes. With training data spanning over 100 languages, including significant emphasis on Chinese and English, DeepSeek-OCR is well-suited for multilingual document processing and global applications.
What are the primary use cases for DeepSeek-OCR?
Key applications include:
- Large-scale Document Digitization: Efficiently processing high volumes of documents (e.g., in archives or legal firms).
- AI Training Data Generation: Creating high-quality text-image pairs for pretraining other LLMs and VLMs.
- Structured Data Extraction: Parsing complex elements like charts, tables, and scientific formulas from technical documents.
- Multilingual Processing: Handling documents across 100+ languages.
Conclusion
The model’s architecture, featuring DeepEncoder and DeepSeek3B-MoE-A570M, demonstrates practical value in generating training data for LLMs/VLMs. DeepSeek-OCR’s combination of optical context compression, multi-resolution support, and open-source availability makes it a valuable tool for applications ranging from archival digitization to AI training data generation.
For those interested in exploring its capabilities, the model is available on GitHub and Hugging Face and can be run on a DigitalOcean GPU Droplet. Its architecture and performance suggest potential for broader applications in AI efficiency and long-context processing.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
