
Introduction
Digital innovation has progressed significantly, starting with personal computing and advancing through the widespread adoption of email, social media, e-commerce, remote work, and most recently, Large Language Models (LLMs) and Agentic AI. This journey has fueled an unprecedented need to digitize and extract information into machine-readable formats. The practical impact of Optical Character Recognition (OCR) advancements extends beyond enabling entirely new workflows across industries still dependent on paper. OCR is critical for effectively leveraging world knowledge for developing smarter tools that can be tailored to our desired use-case and improve our ability to perform inefficient and/or difficult tasks.
History of OCR
The history of OCR is marked by a number of technological breakthroughs that have revolutionized how machines interpret and digitize printed and written text. Among these early innovations were Gustav Tauschek’s “Reading Machine,” a mechanical device designed to recognize characters, and Emmanuel Goldberg’s “Statistical Machine,” which utilized photoelectric cells and pattern matching and was later acquired by IBM.
OCR transitioned from being a hardware problem to a software one in the 90s, with commercial software becoming available from companies like Caere Corporation (with OmniPage), Adobe (with Acrobat), and ABBYY (with FineReader). In 2005, we saw the open-source release of Tesseract OCR from Hewlett-Packard and then sponsored by Google in 2006. The 2010s marked the Deep Learning Revolution, with Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) drastically increasing OCR accuracy.
Today, progress in Vision Language Models (VLMs) such as Qwen2-VL and Qwen2.5-VL as well as GPU inference optimizations has led to unprecedented breakthroughs in performing OCR at scale.

olmOCR, Document Conversion AT SCALE
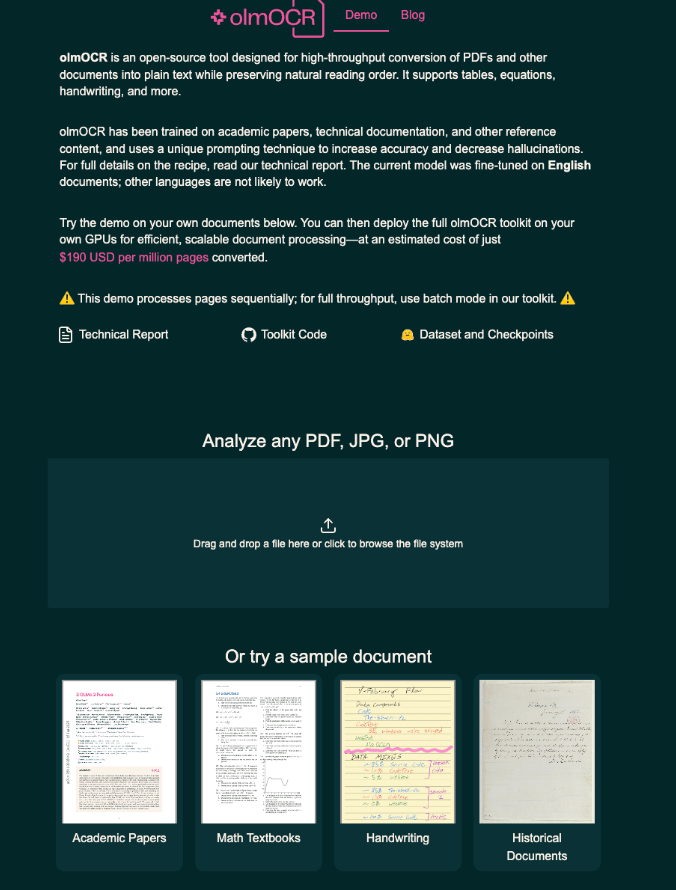
Developed by Allen AI, olmOCR presents itself as an affordable option for OCR capable of converting a million PDF pages for $190 USD.
olmOCR introduces a technique they call Document Anchoring, where the quality of the extracted text is enhanced with any text and metadata present in the PDF file.
The olmOCR-mix-0225 dataset was created by labeling 250,000 pages using this Document Anchoring technique and GPT-4o. Poppler was used to transform pages in a PDF to images, and PyPDF was used to extract text blocks, images, and their positions. In Section 3.1 of the paper, the researchers explain why GPT-4o was chosen as the teacher model over GPT-4o mini, Gemini 1.5, and Claude Sonnet 3.5.
The figure below is the prompt used to create the olmOCR-mix-0225 dataset. Just look at how explicit this prompt is. *Do not hallucinate.*

The labelled dataset is impressive; it is rich and varied, featuring a broad spectrum of document types. It includes 60% academic papers, 12% brochures, 11% legal documents, 6% diagrams, 5% slideshows, and 4% other document types, with some documents being originally digital and others being scanned copies. Using this data, the researchers fine-tuned a Qwen2-VL-7B-Instruct checkpoint.
Feel free to try the demo on your own!
RolmOCR, olmOCR but Better?
Reducto introduced RolmOCR, implementing three notable changes to olmOCR to enhance its performance and efficiency. A more recent version of the existing model, Qwen2.5-VL-7B, was integrated as the new base model. Secondly, Reducto’s version no longer utilizes metadata extracted from PDFs, a modification that significantly shortens prompt lengths. This reduction in prompt length leads to lower processing times and decreased VRAM usage, generally without negatively impacting accuracy. Lastly, to improve robustness in handling off-angle documents, about 15% of the training data was rotated, while the remainder of the original training set was maintained.
olmOCR on DigitalOcean GPU Droplets
The olmOCR repo contains a number of files that you can play with as well as a Readme file with implementation details. We were running into issues with the code, but we believe the repo is in the process of being updated.

To prompt this model manually (without the olmOCR toolkit), use the code provided in the model’s Hugging Face page by SSHing into your favourite code editor.
In terminal
pip3 install olmocr
In VSCode, cursor, or the code editor of your choice
import torch
import base64
import urllib.request
from io import BytesIO
from PIL import Image
from transformers import AutoProcessor, Qwen2VLForConditionalGeneration
from olmocr.data.renderpdf import render_pdf_to_base64png
from olmocr.prompts import build_finetuning_prompt
from olmocr.prompts.anchor import get_anchor_text
# Initialize the model
model = Qwen2VLForConditionalGeneration.from_pretrained("allenai/olmOCR-7B-0225-preview", torch_dtype=torch.bfloat16).eval()
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Grab a sample PDF
urllib.request.urlretrieve("https://www.w3.org/WAI/ER/tests/xhtml/testfiles/resources/pdf/dummy.pdf", "./paper.pdf")
# Render page 1 to an image
image_base64 = render_pdf_to_base64png("./paper.pdf", 1, target_longest_image_dim=1024)
# Build the prompt, using document metadata
anchor_text = get_anchor_text("./paper.pdf", 1, pdf_engine="pdfreport", target_length=4000)
prompt = build_finetuning_prompt(anchor_text)
# Build the full prompt
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{image_base64}"}},
],
}
]
# Apply the chat template and processor
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
main_image = Image.open(BytesIO(base64.b64decode(image_base64)))
inputs = processor(
text=[text],
images=[main_image],
padding=True,
return_tensors="pt",
)
inputs = {key: value.to(device) for (key, value) in inputs.items()}
# Generate the output
output = model.generate(
**inputs,
temperature=0.8,
max_new_tokens=50,
num_return_sequences=1,
do_sample=True,
)
# Decode the output
prompt_length = inputs["input_ids"].shape[1]
new_tokens = output[:, prompt_length:]
text_output = processor.tokenizer.batch_decode(
new_tokens, skip_special_tokens=True
)
print(text_output)
# ['{"primary_language":"en","is_rotation_valid":true,"rotation_correction":0,"is_table":false,"is_diagram":false,"natural_text":"Molmo and PixMo:\\nOpen Weights and Open Data\\nfor State-of-the']
Conclusion
Both olmOCR and RolmOCR are significant contributions to open-source OCR technology that seek to provide developers with a potential cost-effective and scalable solution to digitize various kinds of documents.
Looking for a smaller model? Check this article for implementation details on smoldocling
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
