By Fauna

Introduction
Many developers don’t have the time or experience to set up and manage infrastructure for their applications. To keep up with deadlines and reduce costs, developers need to find solutions that allow them to deploy their apps to the cloud as quickly and efficiently as possible to focus on writing the code and delivering new features to their customers. Together, DigitalOcean’s App Platform and Fauna provide that ability.
DigitalOcean App Platform is a Platform-as-a-Service (PaaS) that abstracts the infrastructure that runs your apps. It also lets you deploy applications by pushing your code to a Git branch.
Fauna is a powerful data layer for applications of any size. As you’ll see in this tutorial, with Fauna, you can get a database up and running quickly without having to worry about the database operations.
Together, these two solutions let you focus on your application instead of managing your infrastructure.
In this tutorial, you’ll integrate Fauna with Python by writing a minimal REST API using the Flask framework. You’ll then deploy the API to DigitalOcean’s App Platform from a Git repository.The API will consist of:
- A public
/signupPOST endpoint for creating users in theUserscollection. - A public
/loginPOST endpoint for authenticating with the documents in theUserscollection. - A private
/thingsGET endpoint for fetching a list of Fauna documents from theThingscollection.
The finished Python project is available at this Github repository.
Prerequisites
Before starting this tutorial, you will need:
- A Fauna account.
- A DigitalOcean account with a payment method configured.
- A Github account to be able to deploy your project to App Platform.
- Python 3 and
pipinstalled on your development machine. Follow How To Install and Set Up a Local Programming Environment for Python 3 to set this up. - Git installed on your local machine. You can follow the tutorial How To Contribute to Open Source: Getting Started with Git to install and set up Git on your computer.
- A text editor. You can use Visual Studio Code or your favorite text editor.
Step 1 — Setting Up the Fauna Database
In the first step, you will configure a Fauna database and create the collections for the API. Fauna is a document-based database rather than a traditional table-based relational database. Fauna stores your data in documents and collections, which are groups of documents.
To create the collections, you will execute queries using FQL, Fauna’s native query language. FQL is an expressive and powerful query language that gives you access to the full power of Fauna.
To get started, log into Fauna’s dashboard. After logging in, click on the Create Database button at the top.
In the New Database form, use PYTHON_API for the database name:
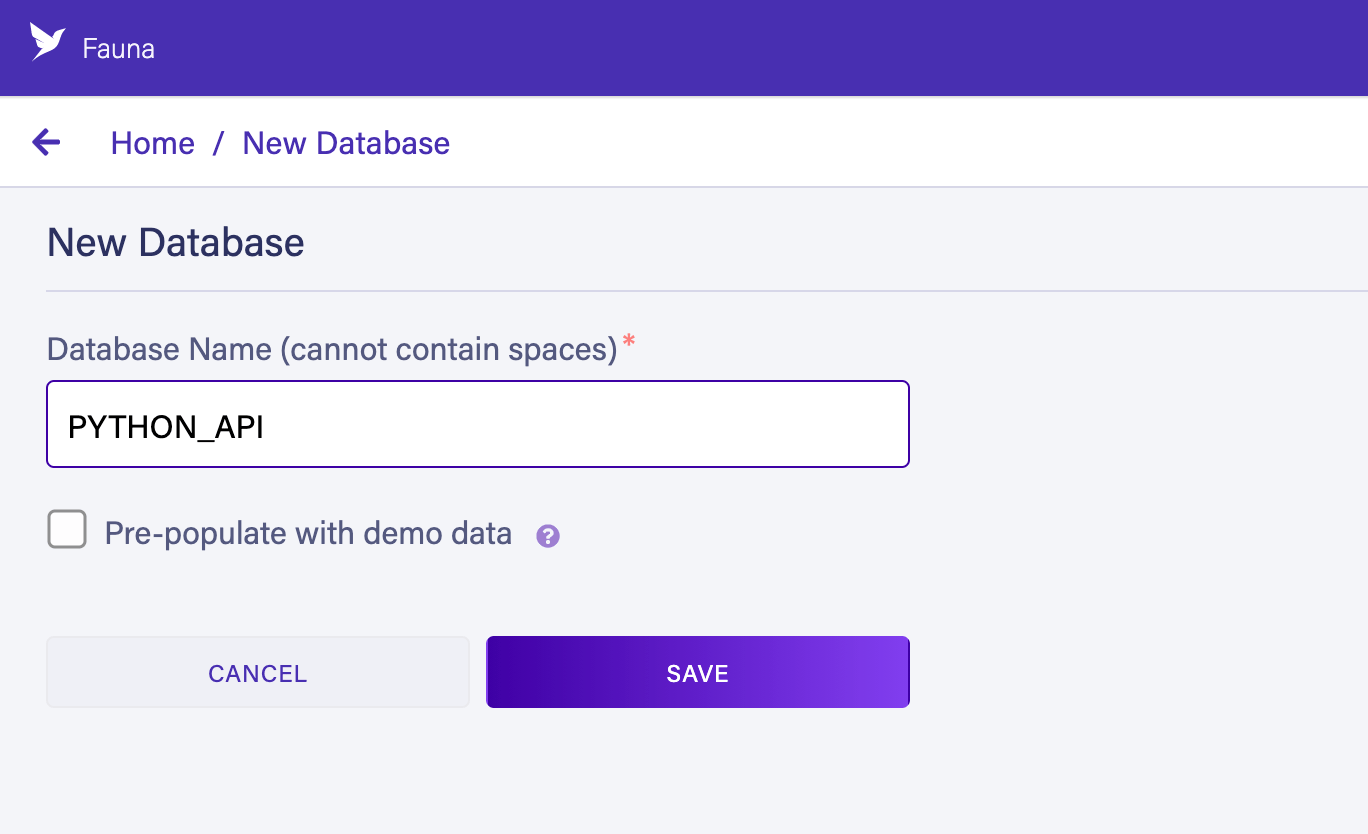
Leave Pre-populate with demo data unchecked. Press the Save button.
After creating the database, you will see the home section for your database:
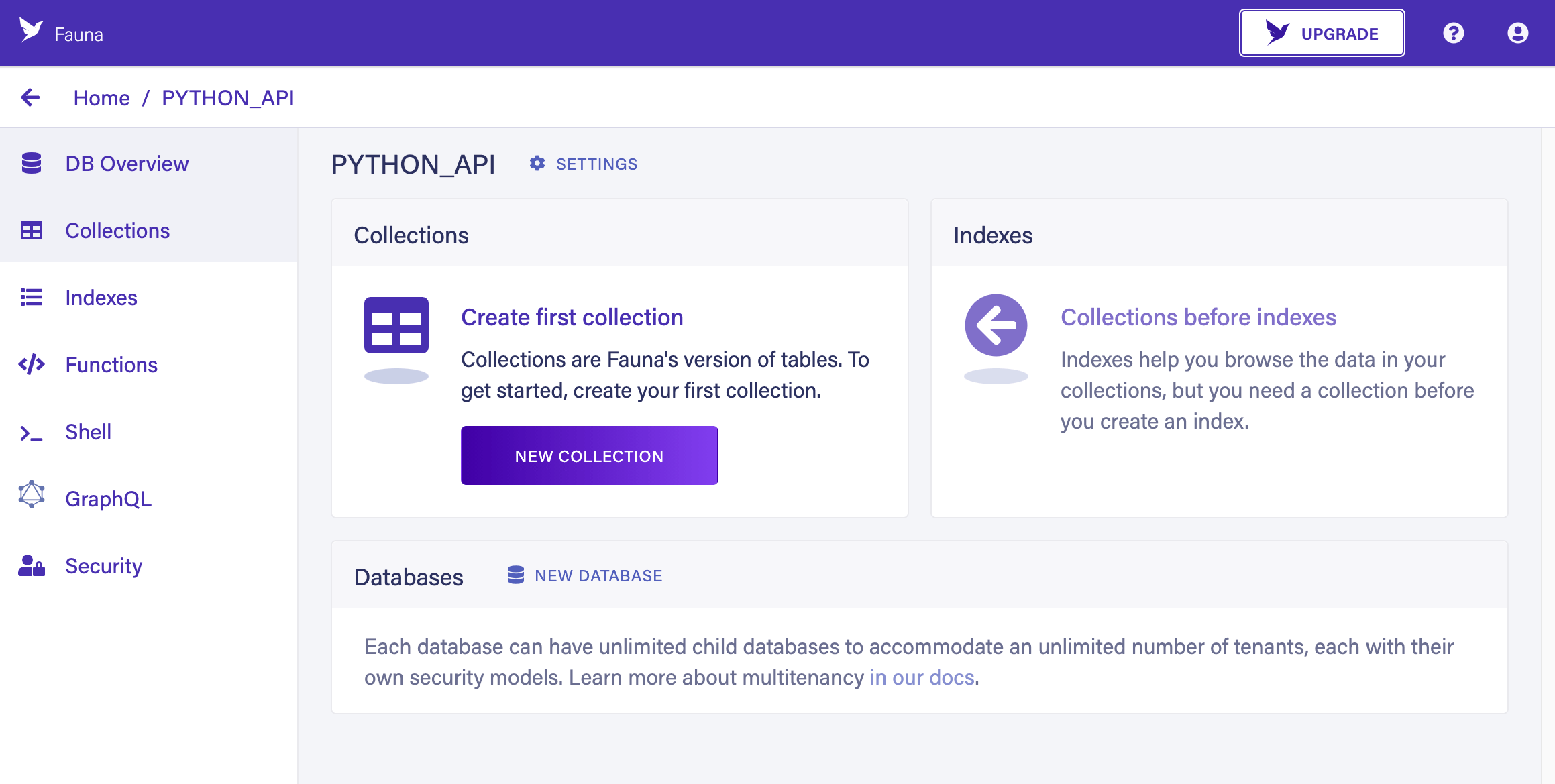
You’re now going to create two collections:
- The
Userscollection that will store documents with authentication information. - The
Thingscollection to store some mock data to test your API.
To create these collections, you’ll execute some FQL queries in the dashboard’s shell. Access the shell from the main dashboard menu on the left:
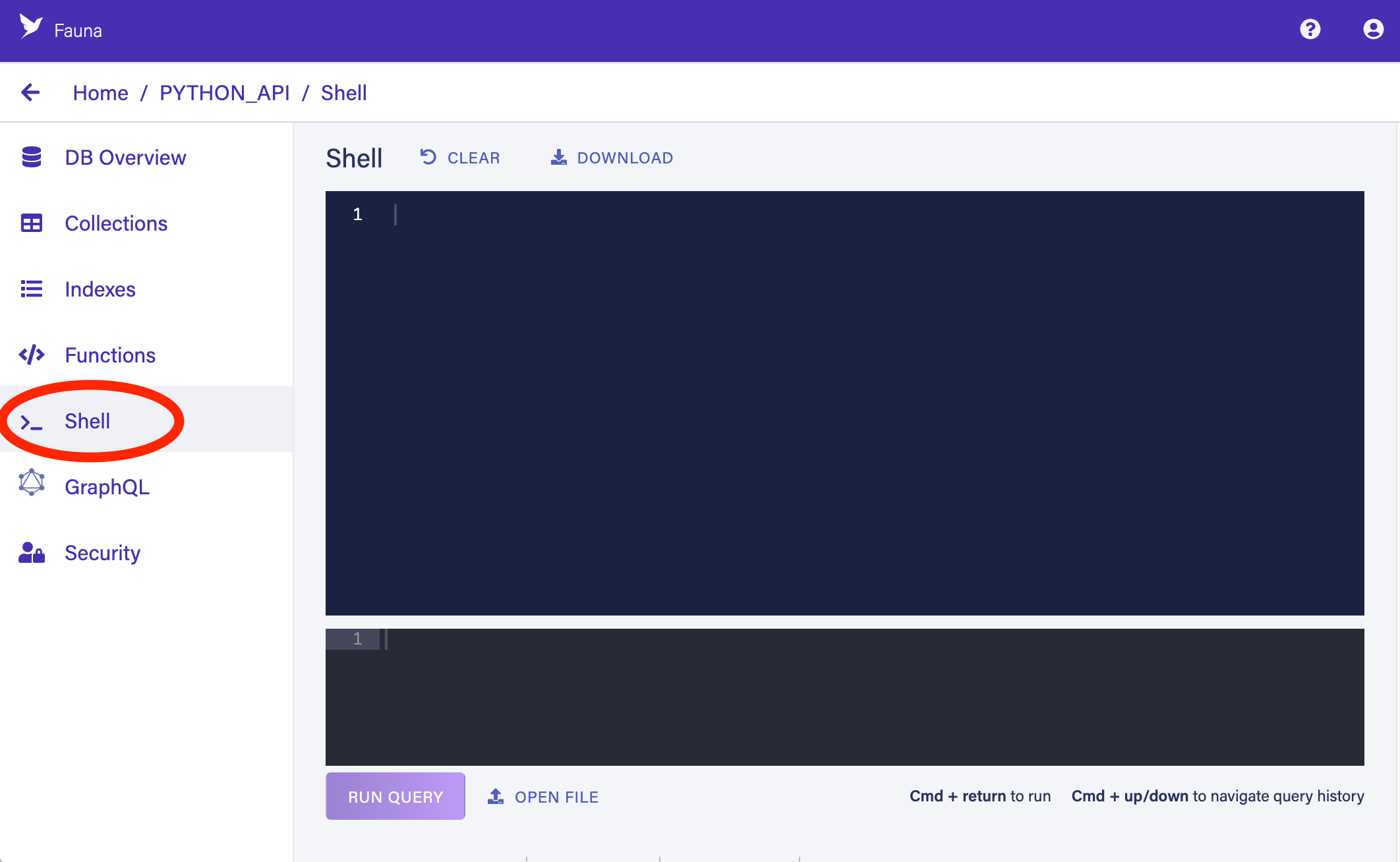
Write the following FQL query in the bottom panel of the shell to create a collection called Things by using the CreateCollection function:
CreateCollection({name: "Things"})
Press the RUN QUERY button. You will get a result similar to this in the shell’s top panel:
{
ref: Collection("Things"),
ts: 1614805457170000,
history_days: 30,
name: "Things"
}
The result shows four fields:
refis a reference to the collection itself.tsis the timestamp of its creation in microseconds.history_daysis how long Fauna will retain changes on documents’ changes.nameis the collection name.
Next, create the Users collection with the following query:
CreateCollection({name: "Users"})
Now that both collections are in place, you will create your first document.
Documents in Fauna are somewhat similar to JSON objects. Documents can store strings, numbers, and arrays, but they can also use Fauna data types. A common Fauna type is Ref, which represents a reference to a document in a collection.
The Create function creates a new document into the specified collection. Run the following query to create a document in the Things collection with two fields:
Create(
Collection("Things"),
{
data: {
name: "Banana",
color: "Yellow"
}
}
)
After running that query, Fauna will return the created document:
{
ref: Ref(Collection("Things"), "292079274901373446"),
ts: 1614807352895000,
data: {
name: "Banana",
color: "Yellow"
}
}
The result shows the following fields:
refof typeRefis a reference to this document in theThingscollection with the ID292079274901373446. Do note that your document will have a different ID.tsis the timestamp of its creation in microseconds.datais the actual content of the document.
This result looks similar to the result you got when you created a collection. That’s because all entities in Fauna (collections, indexes, roles, etc) are actually stored as documents.
To read documents, use the Get function which accepts a reference of a document. Run the Get query using the reference for your document:
Get(Ref(Collection("Things"), "292079274901373446"))
The result is the full document:
{
ref: Ref(Collection("Things"), "292079274901373446"),
ts: 1614807352895000,
data: {
name: "Banana",
color: "Yellow"
}
}
To get all references for documents stored in a collection, use the Documents function with the Paginate function:
Paginate(Documents(Collection("Things")))
This query returns a page with an array of references:
{
data: [Ref(Collection("Things"), "292079274901373446")]
}
To get actual documents instead of references, iterate over the references using Map. Then use a Lambda (an anonymous function) to iterate over the array of references and Get each reference:
Map(
Paginate(Documents(Collection("Things"))),
Lambda("ref", Get(Var("ref")))
)
The result is an array containing full documents:
{
data: [
{
ref: Ref(Collection("Things"), "292079274901373446"),
ts: 1614807352895000,
data: {
name: "Banana",
color: "Yellow"
}
}
]
}
You’re now going to create the Users_by_username index. You typically use indexes in Fauna to catalog, filter, and sort data, but you can also use them for other purposes like enforcing unique constraints.
The Users_by_username index will find users by their username, and also enforce a unique constraint to prevent two documents from having the same username.
Execute this code in the shell to create the index:
CreateIndex({
name: "Users_by_username",
source: Collection("Users"),
terms: [{ field: ["data", "username"] }],
unique: true
})
The CreateIndex function will create an index with the configured settings:
nameis the name of the index.sourceis the collection (or collections) the index will index data from.termsis the search/filter terms you’ll pass to this index when using it to find documents.uniquemeans that the indexed values will be unique. In this example, theusernameproperty of the documents in theUserscollection will be enforced as unique.
To test the index, create a new document inside the Users collection by running the following code in the Fauna shell:
Create(
Collection("Users"),
{
data: {
username: "sammy"
}
}
)
You’ll see a result like the following:
{
ref: Ref(Collection("Users"), "292085174927098368"),
ts: 1614812979580000,
data: {
username: "sammy"
}
}
Now try to create a document with the same username value:
Create(
Collection("Users"),
{
data: {
username: "sammy"
}
}
)
You’ll receive an error now:
Error: [
{
"position": [
"create"
],
"code": "instance not unique",
"description": "document is not unique."
}
]
Now that the index is in place, you can query it and fetch a single document. Run this code in the shell to fetch the sammy user using the index:
Get(
Match(
Index("Users_by_username"),
"sammy"
)
)
Here’s how it works:
- Index returns a reference to the
Users_by_usernameindex. - Match returns a reference to the matched document (the one that has a
usernamewith the value ofsammy). Gettakes the reference returned byMatch, and fetches the actual document.
The result of this query will be:
{
ref: Ref(Collection("Users"), "292085174927098368"),
ts: 1614812979580000,
data: {
username: "sammy"
}
}
Delete this testing document by passing its reference to the Delete function:
Delete(Ref(Collection("Users"), "292085174927098368"))
Next you’ll configure security settings for Fauna so you can connect to it from your code.
Step 2 — Configuring a Server Key and Authorization Rules
In this step you’ll create a server key that your Python application will use to communicate with Fauna. Then you’ll configure access permissions.
To create a key, go to the Security section of the Fauna dashboard by using the main menu on the left. Once there:
- Press the New Key button.
- Select the Server role.
- Press Save.
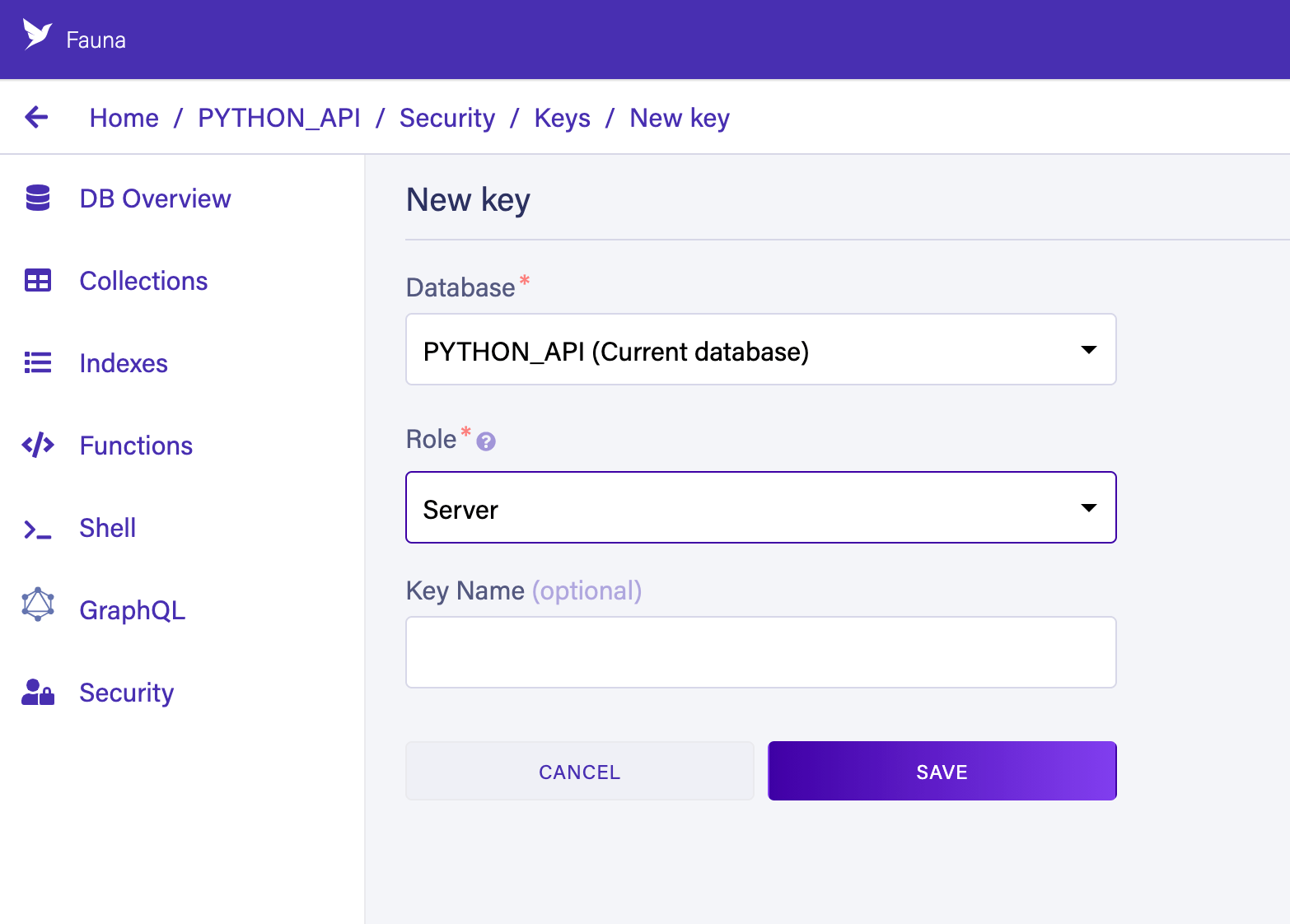
After saving, the dashboard will show you the key’s secret. Save the secret somewhere safe and never commit it to your Git repository.
Warning: The Server role is omnipotent and anyone with this secret would have full access to your database. As its name implies, this is the role typically used by trusted server applications, although it is also possible to create a key with a custom role with limited privileges. When you create production applications, you’ll want to make a more restrictive role.
By default, everything in Fauna is private, so you’re now going to create a new role to allow the logged-in users to read documents from the Things collection.
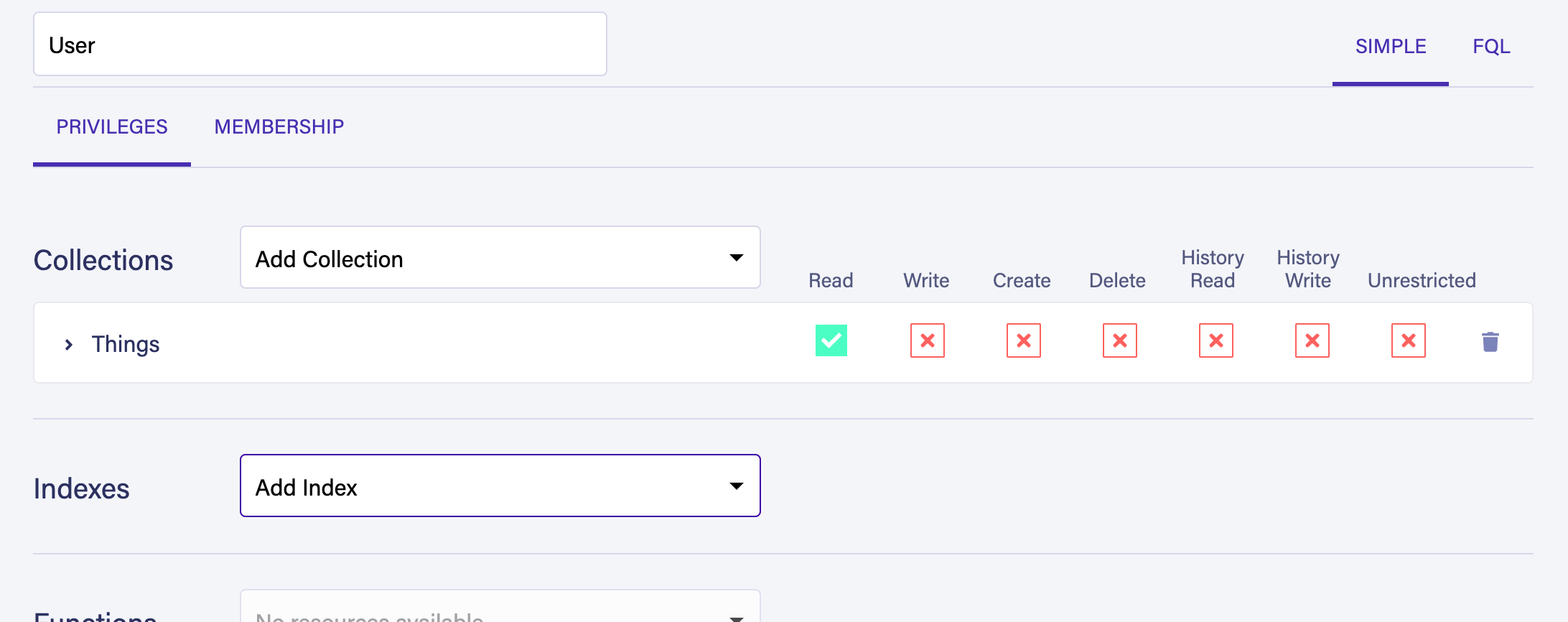
In the Security section of the dashboard, go to Roles, and create a new custom role with the name User.
In the Collections dropdown, add the Things collection and press the Read permission so that it shows a green check mark:
Before saving the role, go to the Membership tab and add the Users collection to the role:
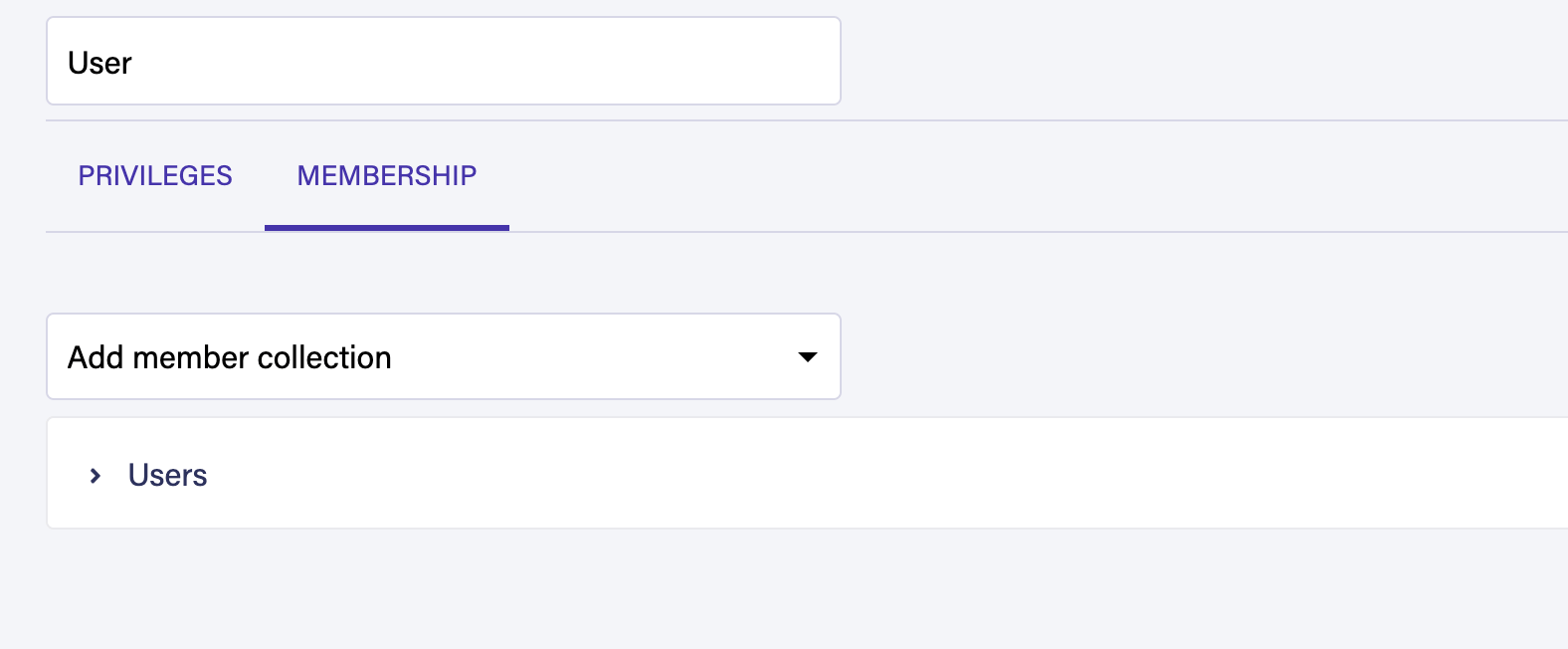
You can now save your User custom role by pressingthe Save button.
Now any logged-in user from a document in the Users collection will be able to read any document from the Things collection.
With authentication and authorization in place, let’s now create the Python API that will talk to Fauna.
Step 3 — Building the Python Application
In this step you will build a small REST API using the Flask framework, and you’ll write FQL queries in Python, connecting to your Fauna database using the the Fauna driver.
To get started, create a project folder and access it from your terminal.
First install Flask with:
- pip install flask
Then install the Fauna Python driver with:
- pip install faunadb
In your project folder, create the file main.py and add the following code to the file, which adds the necessary imports, the FAUNA_SECRET environment variable, and the basic configuration of the Flask application:
import os
FAUNA_SECRET = os.environ.get('FAUNA_SECRET')
import flask
from flask import request
import faunadb
from faunadb import query as q
from faunadb.client import FaunaClient
app = flask.Flask(__name__)
app.config["DEBUG"] = True
The FAUNA_SECRET environment variable will carry the server secret you created earlier. To be able to run this application, locally or in the cloud, this variable needs to be injected. Without it, the application won’t be able to connect to Fauna. You’ll provide this environment variable when you launch the app.
Now add the the /signup route to the main.py file. This will create new documents in the Users collection:
@app.route('/signup', methods=['POST'])
def signup():
body = request.json
client = FaunaClient(secret=FAUNA_SECRET)
try:
result = client.query(
q.create(
q.collection("Users"),
{
"data": {
"username": body["username"]
},
"credentials": {
"password": body["password"]
}
}
)
)
return {
"userId": result['ref'].id()
}
except faunadb.errors.BadRequest as exception:
error = exception.errors[0]
return {
"code": error.code,
"description": error.description
}, 409
Note that the Fauna client is being instantiated on every request using the server secret:
...
client = FaunaClient(secret=FAUNA_SECRET)
...
Once users are logged in, the API will execute queries on behalf of each user using different secrets, which is why it makes sense to instantiate the client on every request.
Unlike other databases, the Fauna client does not maintain a persistent connection. From the outside world, Fauna behaves like an API; every query is a single HTTP request.
After the client is ready, the FQL query executes, which creates a new document in the Users collection. Each Fauna driver translates idiomatic syntax to FQL statements. In this route, you added this query:
...
q.create(
q.collection("Users"),
{
"data": {
"user": json["user"]
},
"credentials": {
"password": json["password"]
}
}
)
...
This is what this query would look like in native FQL:
Create(
Collection("Users"),
{
"data": {
"user": "sammy"
},
"credentials": {
"password": "secretpassword"
}
}
)
In addition to the document data, you’re adding a credentials configuration with the user’s password. This part of the document is completely private. You will never be able to read a document’s credentials afterwards. When using Fauna’s authentication system, it’s not possible to expose users’ passwords by mistake.
Finally, if there’s already a user with the same username, a faunadb.errors.BadRequest exception will be raised, and a 409 response with the error information will be returned to the client.
Next, add the /login route in the main.py file to authenticate the user and password. This follows a similar pattern as the previous example; you execute a query using the Fauna connection and if the authentication fails, you raise a faunadb.errors.BadRequest exception and return a a 401 response with the error information. Add this code to main.py:
@app.route('/login', methods=['POST'])
def login():
body = request.json
client = FaunaClient(secret=FAUNA_SECRET)
try:
result = client.query(
q.login(
q.match(
q.index("Users_by_username"),
body["username"]
),
{"password": body["password"]}
)
)
return {
"secret": result['secret']
}
except faunadb.errors.BadRequest as exception:
error = exception.errors[0]
return {
"code": error.code,
"description": error.description
}, 401
This is the FQL query used to authenticate users with Fauna:
q.login(
q.match(
q.index("Users_by_username"),
body["username"]
),
{"password": body["password"]}
)
This is what this query would look like in native FQL:
Login(
Match(
Index("Users_by_username"),
"sammy"
),
{"password": "secretpassword"}
)
Match returns a reference to a document using the Users_by_username index that we created previously.
If the provided password matches the referenced document, Login will create a new token and return a dictionary with the following keys:
refwith a reference to the token for the new document.tswith the timestamp of the transaction.instancewith a reference to the document that was used to do the authentication.secretwith the token’s secret that will be used to make further queries to Fauna.
If you run that FQL query into your Fauna dashboard’s shell you will see something similar to this:
{
ref: Ref(Ref("tokens"), "292001047221633538"),
ts: 1614732749110000,
instance: Ref(Collection("Users"), "291901454585692675"),
secret: "fnEEDWVnxbACAgQNBIxMIAIIKq1E5xvPPdGwQ_zUFH4F5Dl0neg"
}
Depending on the security requirements of the project, you have to decide how to handle the token’s secret. If this API was meant to be consumed by browsers, you might return the secret inside a secure cookie or an encrypted JSON Web Token (JWT). Or you might store it as session data somewhere else, like a Redis instance. For the purpose of this demo, you return it in the body of the HTTP response:
Finally, add this bit of code to main.py, which will start the Flask application:
app.run(host=os.getenv('IP', '0.0.0.0'), port=int(os.getenv('PORT', 8080)))
It’s important to specify the 0.0.0.0 address. Once deployed to the cloud, this application will run in a Docker container. It won’t be able to receive requests from remote clients if it is running on 127.0.0.1, which is the default address for Flask applications.
This is the complete main.py file so far:
import os
FAUNA_SECRET = os.environ.get('FAUNA_SECRET')
import flask
from flask import request
import faunadb
from faunadb import query as q
from faunadb.client import FaunaClient
app = flask.Flask(__name__)
app.config["DEBUG"] = True
@app.route('/signup', methods=['POST'])
def signup():
body = request.json
client = FaunaClient(secret=FAUNA_SECRET)
try:
result = client.query(
q.create(
q.collection("Users"),
{
"data": {
"username": body["username"]
},
"credentials": {
"password": body["password"]
}
}
)
)
return {
"userId": result['ref'].id()
}
except faunadb.errors.BadRequest as exception:
error = exception.errors[0]
return {
"code": error.code,
"description": error.description
}, 409
@app.route('/login', methods=['POST'])
def login():
body = request.json
client = FaunaClient(secret=FAUNA_SECRET)
try:
result = client.query(
q.login(
q.match(
q.index("Users_by_username"),
body["username"]
),
{"password": body["password"]}
)
)
return {
"secret": result['secret']
}
except faunadb.errors.BadRequest as exception:
error = exception.errors[0]
return {
"code": error.code,
"description": error.description
}, 401
app.run(host=os.getenv('IP', '0.0.0.0'), port=int(os.getenv('PORT', 8080)))
Save the file.
To launch this server locally from your terminal, use the following command with the FAUNA_SECRET environment variable with the secret you obtained when creating the server key:
- FAUNA_SECRET=your_fauna_server_secret python main.py
After triggering that command, Flask will show a warning informing you it is running with a development WSGI server. This is fine for the purpose of this demo so you can safely ignore this warning.
Test your API by making HTTP requests using the curl command. Open a new terminal window and run the following command:
Create a user with the following command:
- curl -i -d '{"user":"sammy", "password": "secretpassword"}' -H 'Content-Type: application/json' -X POST http://0.0.0.0:8080/signup
You’ll see the following response, indicating a successful user creation:
HTTP/1.0 200 OK
Content-Type: application/json
Content-Length: 37
Server: Werkzeug/1.0.1 Python/3.9.2
Date: Thu, 04 Mar 2021 01:00:47 GMT
{
"userId": "292092166117786112"
}
Now authenticate that user with this command:
- curl -i -d '{"user":"sammy", "password": "secretpassword"}' -H 'Content-Type: application/json' -X POST http://0.0.0.0:8080/login
You’ll get this successful response:
HTTP/1.0 200 OK
Content-Type: application/json
Content-Length: 70
Server: Werkzeug/1.0.1 Python/3.9.2
Date: Thu, 04 Mar 2021 01:01:19 GMT
{
"secret": "fnEEDbhO3jACAAQNBIxMIAIIOlDxujk-VJShnnhkZkCUPKIHxbc"
}
Close the terminal window where you ran your curl commands and switch back to the terminal where your Python server is running. Stop your server by pressing CTRL+C.
Now that the application is working, we’re going to add a private endpoint that requires users to be authenticated.
Step 4 — Adding a Private Endpoint
In this step, you’ll add a private endpoint to the API, which will require the user to be authenticated first.
First, create a new route in the main.py file. This route will respond to the /things endpoint. Place it above the line that starts the server with the app.run() method:
@app.route('/things', methods=['GET'])
def things():
Next, in the /things route, instantiate the Fauna client:
userSecret = request.headers.get('fauna-user-secret')
client = FaunaClient(secret=userSecret)
Instead of using the server secret, this route is using the user’s secret from the fauna-user-secret HTTP header which is used to instantiate the Fauna client. By using the users’ secrets instead of the server secret, FQL queries will now be subject to the authorization rules we’ve configured previously in the dashboard.
Then add this try block to the route to execute the query:
try:
result = client.query(
q.map_(
q.lambda_("ref", q.get(q.var("ref"))),
q.paginate(q.documents(q.collection("Things")))
)
)
things = map(
lambda doc: {
"id": doc["ref"].id(),
"name": doc["data"]["name"],
"color": doc["data"]["color"]
},
result["data"]
)
return {
"things": list(things)
}
This executes an FQL query and parses the Fauna response into a serializable type that is then returned as a JSON string in the body of the HTTP response.
Finally, add this except block to the route:
except faunadb.errors.Unauthorized as exception:
error = exception.errors[0]
return {
"code": error.code,
"description": error.description
}, 401
If the request doesn’t contain a valid secret, a faunadb.errors.Unauthorized exception will be raised and a 401 response with the error information will be returned.
This is the full code for the /things route:
@app.route('/things', methods=['GET'])
def things():
userSecret = request.headers.get('fauna-user-secret')
client = FaunaClient(secret=userSecret)
try:
result = client.query(
q.map_(
q.lambda_("ref", q.get(q.var("ref"))),
q.paginate(q.documents(q.collection("Things")))
)
)
things = map(
lambda doc: {
"id": doc["ref"].id(),
"name": doc["data"]["name"],
"color": doc["data"]["color"]
},
result["data"]
)
return {
"things": list(things)
}
except faunadb.errors.Unauthorized as exception:
error = exception.errors[0]
return {
"code": error.code,
"description": error.description
}, 401
Save the file and run your server again:
- FAUNA_SECRET=your_fauna_server_secret python main.py
To test this endpoint, first obtain a secret by authenticating with valid credentials. Open a new terminal window and execute this curl command:
- curl -i -d '{"username":"sammy", "password": "secretpassword"}' -H 'Content-Type: application/json' -X POST http://0.0.0.0:8080/login
This command returns a succesful response, although the value for secret will be different:
HTTP/1.0 200 OK
Content-Type: application/json
Content-Length: 70
Server: Werkzeug/1.0.1 Python/3.9.2
Date: Thu, 04 Mar 2021 01:01:19 GMT
{
"secret": "fnEEDb...."
}
Now hen do a GET request to /things using the secret:
curl -i -H 'fauna-user-secret: fnEEDb...' -X GET http://0.0.0.0:8080/things
You’ll get another successful response:
HTTP/1.0 200 OK
Content-Type: application/json
Content-Length: 118
Server: Werkzeug/1.0.1 Python/3.9.2
Date: Thu, 04 Mar 2021 01:14:49 GMT
{
"things": [
{
"color": "Yellow",
"id": "292079274901373446",
"name": "Banana"
}
]
}
Close your terminal window where you ran the curl commands. Return to your window where your server is running and stop the server with CTRL+C.
Now that you have a working app, you’re ready to deploy it.
Step 4 — Deploying to DigitalOcean
In the final step of this tutorial, you will create an app on App Platform and deploy it from a GitHub repository.
Before pushing the project to a Git repository, be sure to run the following command in the project’s folder:
- pip freeze > requirements.txt
This will create a requirements.txt file with the list of dependencies that need to be installed once the application is deployed.
Now initialize your project directory as a Git repository:
- git init
Now execute the following command to add files to your repository:
- git add .
This adds all the files in the current directory.
With the files added, make your initial commit:
- git commit -m "Initial version of the site"
Your files will commit.
Open your browser and navigate to GitHub, log in with your profile, and create a new repository called sharkopedia. Create an empty repository without a README or license file.
Once you’ve created the repository, return to the command line to push your local files to GitHub.
First, add GitHub as a remote repository:
- git remote add origin https://github.com/your_username/sharkopedia
Next, rename the default branch main, to match what GitHub expects:
- git branch -M main
Finally, push your main branch to GitHub’s main branch:
- git push -u origin main
Your files will transfer. You’re now ready to deploy your app.
Note: To be able to create an app on App Platform, you’ll first need to add a payment method to your DigitalOcean account.
The application will run on a container which costs $5 per month, although only a few cents will be needed to test it out. Don’t forget to delete the application once you’re done or you’ll continue to be charged.
Go to the Apps section of the DigitalOcean dashboard, and click on Launch Your App:
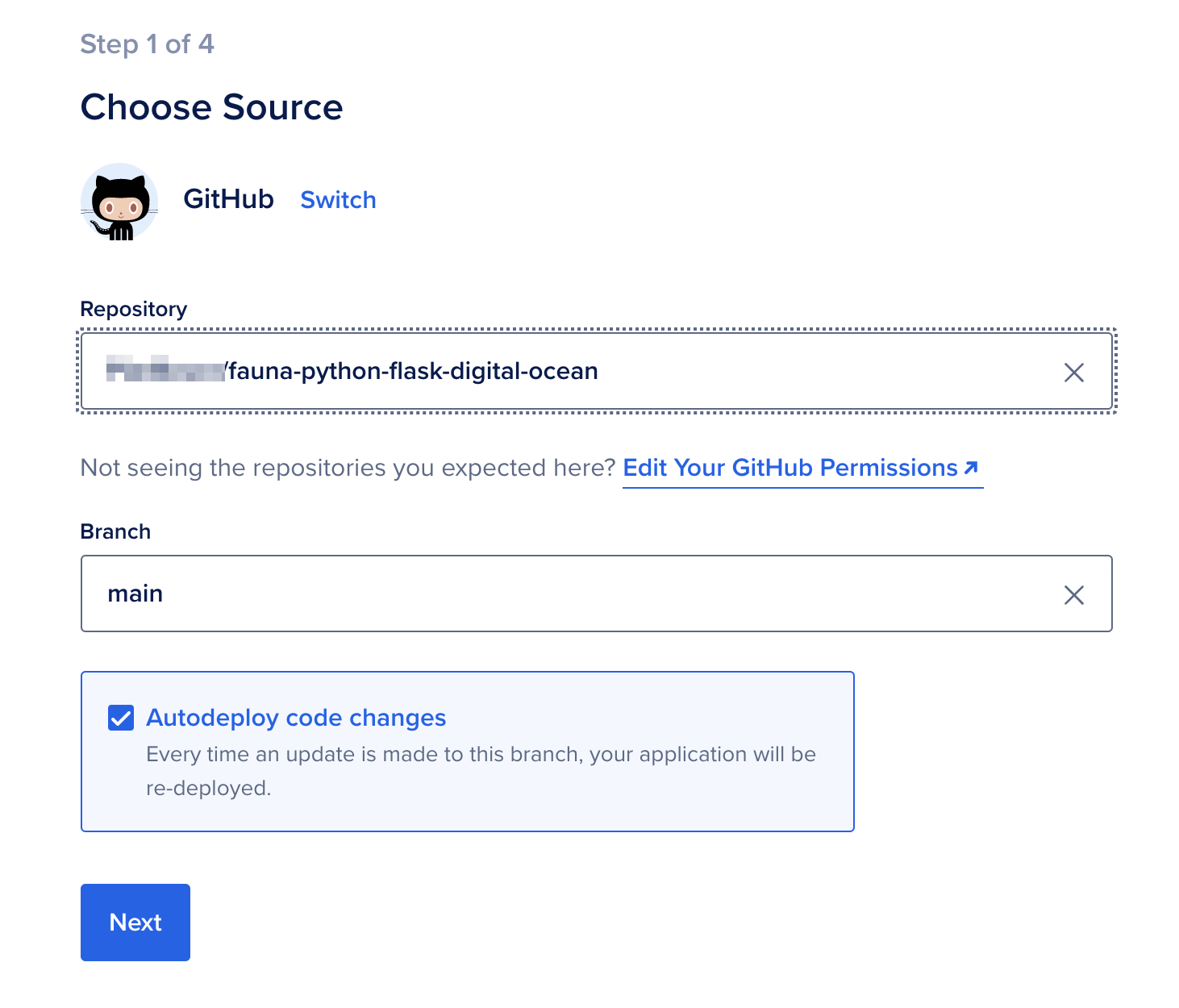
Select the source for deployment. You will need to authorize DigitalOcean to read your Github repositories. Once you’ve authorized access, select the repository with your Python project and the branch that contains the version of the app you want to deploy:
At this point, App Platform will determine that your project uses Python and will let you configure some application options:
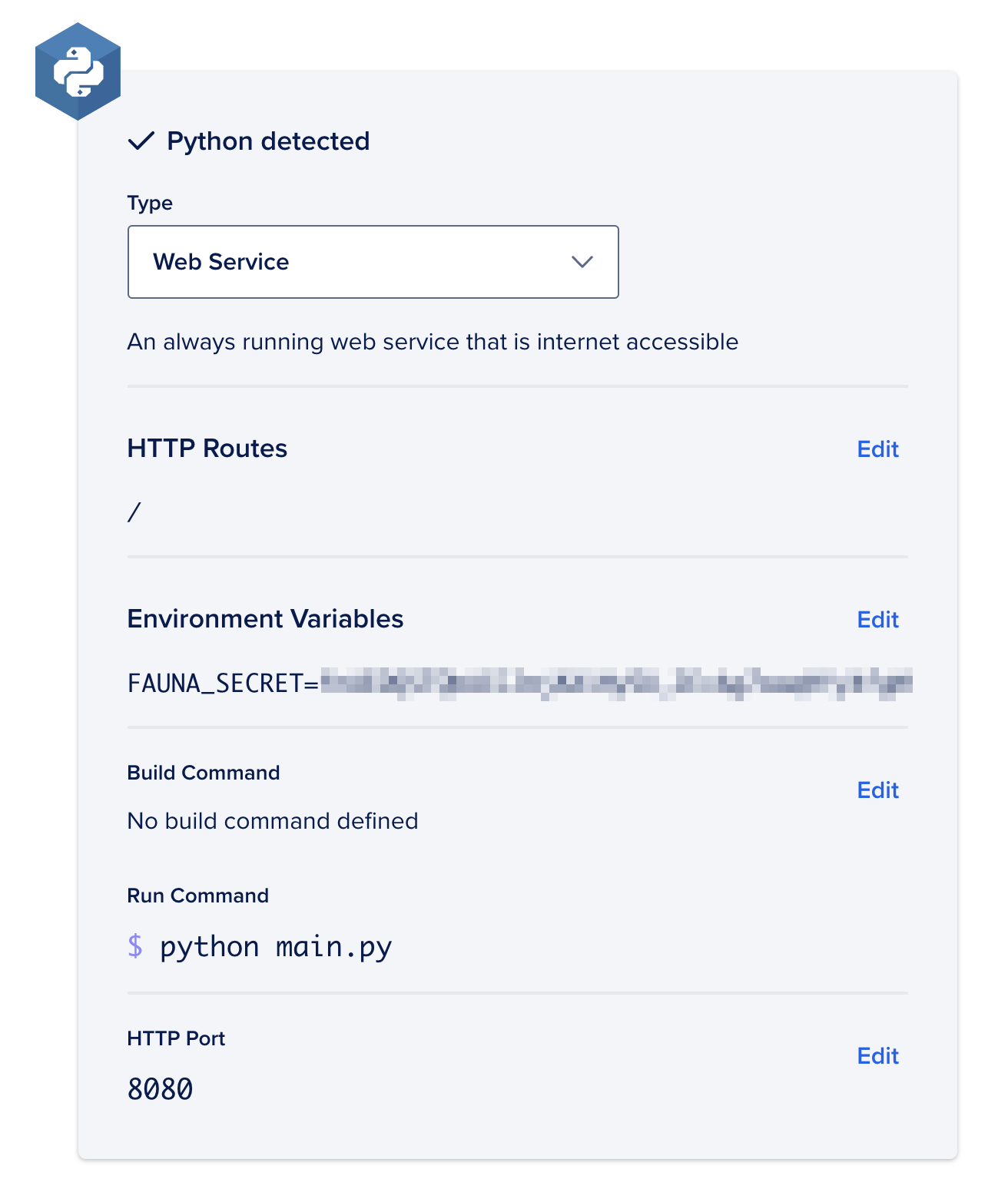
Set the following options
- Ensure the Type is Web Service.
- Create a
FAUNA_SECRETenvironment variable with your server secret. - Set the Run Command to
python main.py. - Set the HTTP Port to
8080.
Next, enter a name for your app and select a deploy region:
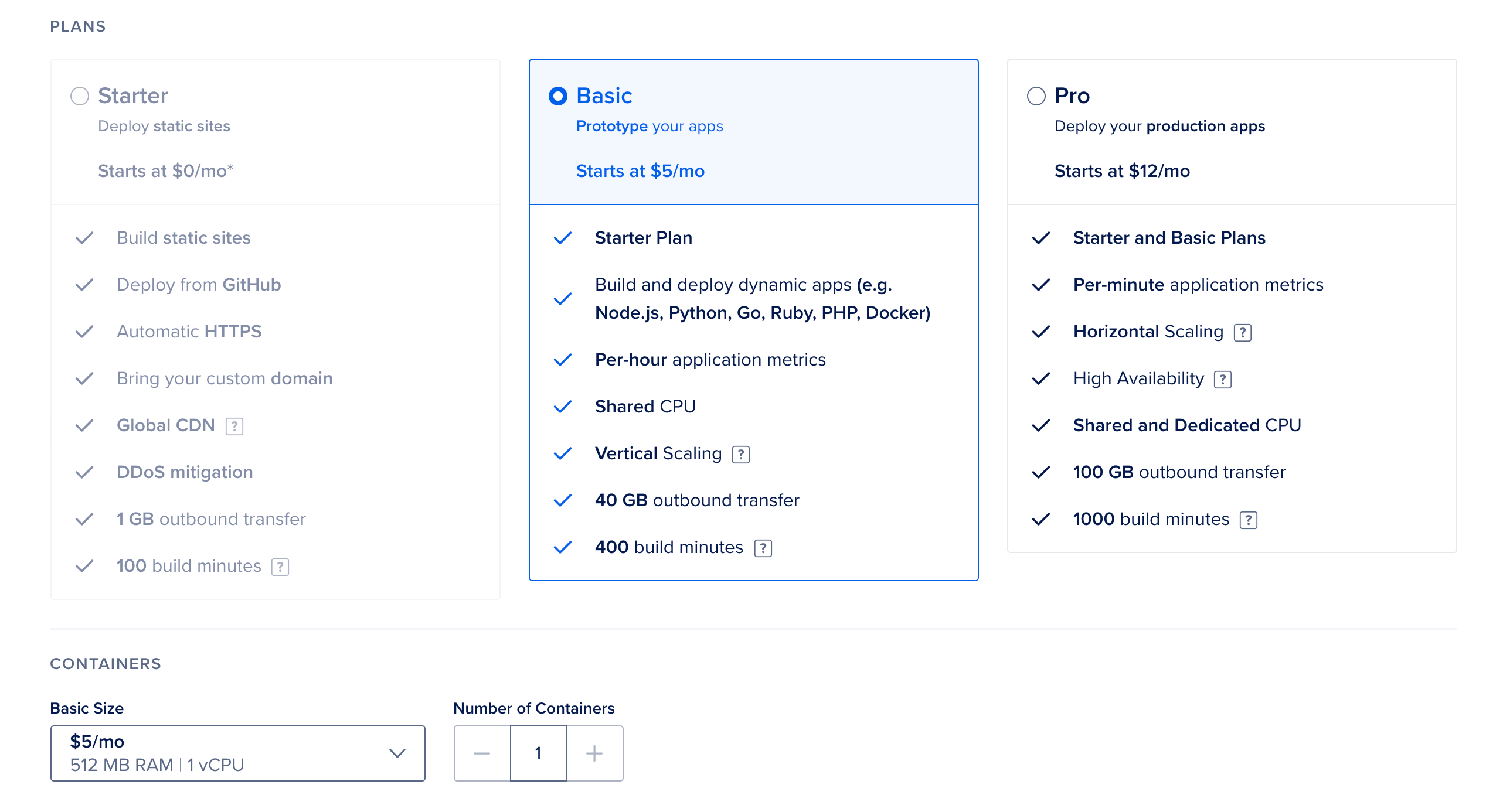
Next, choose the Basic plan and Basic Size that costs $5 per month:
After that, scroll down and click on Launch Your App.
Once you’ve finished configuring the app, a container will be created and deployed with your application. This first-time initialization will take a couple of minutes, but subsequent deploys will be much faster.
In the app’s dashboard you’ll see a green check mark to indicate the deploy process has finished successfully:

You will now be able to execute HTTP requests to the provided app domain. Execute the following command in your terminal, substituting your_app_name with your actual app name, to return a new secret for the sammy user:
- curl -i -d '{"user":"sammy", "password": "secretpassword"}' -H 'Content-Type: application/json' -X POST https://your_app_name.ondigitalocean.app/login
You’ll receive a response similar to the following:
HTTP/1.0 200 OK
Content-Type: application/json
Content-Length: 70
Server: Werkzeug/1.0.1 Python/3.9.2
Date: Thu, 04 Mar 2021 01:01:19 GMT
{
"secret": "fnAADbhO3jACEEQNBIxMIAOOIlDxujk-VJShnnhkZkCUPKIskdjfh"
}
Your application is now up and running on Digital Ocean.
Conclusion
In this tutorial you created a Python REST API using Fauna as the data layer, and you deployed it to DigitalOcean App Platform.
To keep learning about Fauna and dive deeper into FQL, check out the Fauna Documentation.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Errors trying to signup using curl curl -i -d ‘{“user”:“sammy”, “password”: “secretpassword”}’ -H ‘Content-Type: application/json’ -X POST http://0.0.0.0:8080/signup
Thanks, Alex
Traceback (most recent call last): File “/home/alex/.local/lib/python3.8/site-packages/flask/app.py”, line 2464, in call return self.wsgi_app(environ, start_response) File “/home/alex/.local/lib/python3.8/site-packages/flask/app.py”, line 2450, in wsgi_app response = self.handle_exception(e) File “/home/alex/.local/lib/python3.8/site-packages/flask/app.py”, line 1867, in handle_exception reraise(exc_type, exc_value, tb) File “/home/alex/.local/lib/python3.8/site-packages/flask/_compat.py”, line 39, in reraise raise value File “/home/alex/.local/lib/python3.8/site-packages/flask/app.py”, line 2447, in wsgi_app response = self.full_dispatch_request() File “/home/alex/.local/lib/python3.8/site-packages/flask/app.py”, line 1952, in full_dispatch_request rv = self.handle_user_exception(e) File “/home/alex/.local/lib/python3.8/site-packages/flask/app.py”, line 1821, in handle_user_exception reraise(exc_type, exc_value, tb) File “/home/alex/.local/lib/python3.8/site-packages/flask/_compat.py”, line 39, in reraise raise value File “/home/alex/.local/lib/python3.8/site-packages/flask/app.py”, line 1950, in full_dispatch_request rv = self.dispatch_request() File “/home/alex/.local/lib/python3.8/site-packages/flask/app.py”, line 1936, in dispatch_request return self.view_functionsrule.endpoint File “/home/alex/fauna-python-flask-digital-ocean/main.py”, line 26, in signup “username”: body[“username”] KeyError: ‘username’
Alex
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
