By Alex Garnett
Senior DevOps Technical Writer

Introduction
Meilisearch is an open-source, standalone search engine written in the Rust programming language. Compared with other popular search engines, Meilisearch deployments require very few steps, and you can run a Meilisearch server and query it using a single command-line binary. Meilisearch has features like fuzzy matching and schema-less indexing and includes a web frontend for demo purposes. More complex deployments support integration with the InstantSearch javascript library.
In this tutorial, you will first run Meilisearch on a Ubuntu 22.04 server using Docker to experiment with it. You’ll populate it with sample data and query it from both the command line and the built-in web frontend. You’ll also explore how to change search weighting and other configuration details. Then you’ll use docker compose to set up a production-ready Meilisearch service that stores persistent data and restarts automatically with your server
Prerequisites
To follow this tutorial, you will need:
-
A Ubuntu 22.04 server set up by following the Ubuntu 22.04 initial server setup guide, including a sudo non-root user and a firewall.
-
Docker and Docker-compose installed following How To Install and Use Docker on Ubuntu 22.04 and the first step of How To Install and Use Docker-Compose on Ubuntu 22.04
Step 1 — Installing Meilisearch and Loading Sample Data
Meilisearch provides installation packages for many environments. Because it is under active development, and its internal data structure is still being updated, it is a good idea to install Meilisearch via Docker. This way, you can pin a specific Meilisearch configuration for your system and upgrade gracefully as needed.
Begin by pulling the latest Meilisearch image (0.26.1 as of this writing) from Docker Hub:
- docker pull getmeili/meilisearch:v0.26.1
You can now launch the Meilisearch docker image by providing some parameters to docker run:
- docker run --rm -p 127.0.0.1:7700:7700 getmeili/meilisearch:v0.26.1
This command can be broken down as follows:
docker run –rmuses the--rmflag to ensure the container will clean up after itself when it exits.-p 127.0.0.1:7700:7700forwards traffic on your server’s localhost interface on port 7700 to Meilisearch’s default port7700inside the Docker container, so you can access it as normal.127.0.0.1is synonymous withlocalhostwhen using IPv4 addresses.getmeili/meilisearch:v0.26.1runs the image you just downloaded.
When you run Meilisearch it will automatically generate some configuration details and include them in the output. Note that the Meilisearch index directory of ./data.ms has been automatically generated inside of the container. You will change the location later in this tutorial. Also note that Meilisearch defaults to running in a development rather than a production configuration environment.
…
[secondary_label Output]
Database path: "./data.ms"
Server listening on: "http://0.0.0.0:7700"
Environment: "development"
Commit SHA: "unknown"
Commit date: "unknown"
Package version: "0.26.1"
…
You now have a running Meilisearch instance with no data in it. You’ll need to load some sample data to begin working with Meilisearch. The meilisearch process will block the shell it was started in as long as it is running, so you will also want to open a separate connection to your server to continue running other commands.
The Meilisearch project provides a sample JSON-formatted data set scraped from TMDB, The Movie Database. Download the data from docs.meilisearch.com using the wget command:
- wget https://docs.meilisearch.com/movies.json
You can run tail to see a snippet of this file’s contents:
Output…
{"id":"289239","title":"Mostly Ghostly: Have You Met My Ghoulfriend?","poster":"https://image.tmdb.org/t/p/w500/eiVY4kKpbo1f7wyNubgJX5ILpxg.jpg","overview":"Bella Thorne, Madison Pettis and Ryan Ochoa lead an ensemble cast in this spook-tacular adventure with new ghosts, new thrills, and the return of some old friends. Max (Ochoa) only has eyes for Cammy (Thorne), the smart, popular redhead at school. When Max finally scores a date with Cammy on Halloween, Phears, an evil ghost with plans on taking over the world, unleashes his ghouls and things go haywire. With the help of his ghostly pals, Tara and Nicky, can Max thwart Phears' evil plot, help reunite his ghost friends with their long-lost parents and still make his date with Cammy on Halloween? R.L. Stine's Mostly Ghostly: Have You Met My Ghoulfriend? is a frightful family delight!","release_date":1409619600,"genres":["Family","Fantasy","Horror"]},
{"id":"423189","title":"Right Here Right Now","poster":"https://image.tmdb.org/t/p/w500/sCo1excKlzhKas681CTSe1ujcOa.jpg","overview":"Hamburg, St. Pauli, New Year's Eve. Oskar Wrobel runs a music club in an old hospital at the edge of the Reeperbahn. While fireworks go off in the streets of St. Pauli, he prepares the big final party - the club has to close. Thankfully there is no time to think about it because the chaos is breaking into his living room, all while hell break loose at the club. The film, based on the novel by Tino Hanekamp, was filmed with hundreds of extras attending a real-life three-night-long party.","release_date":1530579600,"genres":["Documentary","Music"]},
{"id":"550315","title":"Fireman Sam - Set for Action!","poster":"https://image.tmdb.org/t/p/w500/2atmRsuSA4tX6sbOEgFzquFWcCV.jpg","overview":"","release_date":1538010000,"genres":["Family","Animation"]}
]
Each entry contains an id, a title, a link to a poster image, optionally an overview of the film, a release date in timestamp format, and a list of genres.
You can load the data into Meilisearch by using curl to construct an HTTP POST request. curl is a powerful, ubiquitous tool for creating web requests on the command line, and HTTP POST is one of a few common HTTP verbs (along with PUT and GET, used by web browsers), used to send formatted data to API endpoints.
- curl \
- -X POST 'http://localhost:7700/indexes/movies/documents' \
- -H 'Content-Type: application/json' \
- --data-binary @movies.json
The various arguments to the curl command are:
-X POST http://urlspecifies that you will be performing a POST request and sending data.-H 'Content-Type: application/json'provides a h header, specifying the file type.--data-binary @movies.jsonincludes the file itself.- The
\characters at the end of each line are standard for when you want to split a shell command over multiple lines without splitting the command itself.
Meilisearch runs on port 7700 by default, and 127.0.0.1 reflects a localhost IP. In this case, you’re creating a new Meilisearch index at /indexes/movies/documents, and providing the necessary formatting in your request to upload a JSON file. This is a standard way of uploading JSON with CURL.
The command should return output stating that your request was successfully enqueued. Meilisearch processes all requests asynchronously rather than waiting for them to complete.
Output{"uid":0,"indexUid":"movies","status":"enqueued","type":"documentAddition","enqueuedAt":"2022-03-09T17:23:18.233702815Z"}
You can check on the status of this request by performing a curl -X GET request to the new /tasks/ endpoint created on the same index. This data should be processed very quickly, so the response should include the finishedAt parameter:
- curl -X GET 'http://localhost:7700/indexes/movies/tasks/0'
Output{"uid":0,"indexUid":"movies","status":"succeeded","type":"documentAddition","details":{"receivedDocuments":19547,"indexedDocuments":19546},"duration":"PT29.866920116S","enqueuedAt":"2022-03-09T17:23:18.233702815Z","startedAt":"2022-03-09T17:23:18.241475424Z","finishedAt":"2022-03-09T17:23:48.108395540Z"}
You now have a Meilisearch index populated with sample data. In the next step, you’ll try some example queries to explore the data.
Step 2 – Searching with Meilisearch
To search a Meilisearch index, you can either send individual queries via the API, or search with a web interface.
Searching via the API works similarly to uploading data via HTTP POSTs. To search, you make a request to the /search endpoint, and you can include your entire query JSON on the command line. Try searching for saint to see which movies are returned using the following curl command:
- curl \
- -X POST 'http://localhost:7700/indexes/movies/search' \
- -H 'Content-Type: application/json' \
- --data-binary '{ "q": "saint" }'
It will return a JSON object containing a list of hits:
Output{
"hits": [
{
"id": "45756",
"title": "Saint",
"poster": "https://image.tmdb.org/t/p/w500/pEPd4mgMwvz6aRhuWkmPUv98P1O.jpg",
"overview": "A horror film that depicts St. Nicholas as a murderous bishop who kidnaps and murders children when there is a full moon on December 5.",
"release_date": 1288486800,
"genres": []
},
{
"id": "121576",
"title": "Saint Philip Neri I Prefer Heaven",
"poster": "https://image.tmdb.org/t/p/w500/z9OsQoM343WsIrP0zMEE06pO1vH.jpg",
"overview": "An epic feature film on the famous 'Apostle of Rome' and great friend of youth in the 16th century. One of the most popular saints of all time, St. Philip Neri was widely known for his great charity, deep prayer life, and tremendous humor. Hoping to join St. Ignatius of Loyola's new order of Jesuits and be a missionary to India, Philip was instead guided by Providence to seek out the poor and abandoned youth of Rome to catechize them in the faith and help them find a better life. He became the founder of the religious congregation, the Oratory, that worked with the youth and also labored to re-evangelize a decadent Rome.",
"release_date": 1284944400,
"genres": [
"Drama"
]
},
{
"id": "221667",
"title": "Saint Laurent",
"poster": "https://image.tmdb.org/t/p/w500/ekpT7mTk4t5PjRYZfiyh0sTKpY5.jpg",
"overview": "1967-1976. As one of history's greatest fashion designers entered a decade of freedom, neither came out of it in one piece.",
"release_date": 1411434000,
"genres": [
"Drama"
]
},
...
Note: To achieve more readable command-line JSON formatting, you can install another tool named jq using sudo apt install jq. Then use shell pipes to pass the Meilisearch JSON output through jq, by appending | jq to the command.
For example, to only list the titles for the example saint query, install jq and then run the following command:
- curl \
- -X POST 'http://localhost:7700/indexes/movies/search' \
- -H 'Content-Type: application/json' \
- --data-binary '{ "q": "saint" }' | jq -r '.hits [] .title'
You will receive a list of titles like this:
[secondary_label Output
Saint
Saint Philip Neri I Prefer Heaven
Saint Laurent
. . .
To demonstrate Meilisearch’s fuzzy matching functionality, you can also try searching for seint, on the assumption that a user may have made a typo:
- curl \
- -X POST 'http://localhost:7700/indexes/movies/search' \
- -H 'Content-Type: application/json' \
- --data-binary '{ "q": "seint" }'
Results will be slightly different due to the particulars of query ranking, but you will still see many entries containing “saint”.
Output{
"hits": [
{
"id": "10105",
"title": "Saints and Soldiers",
"poster": "https://image.tmdb.org/t/p/w500/efhqxap8fLi4v1GEXVvakey0z3S.jpg",
"overview": "Five American soldiers fighting in Europe during World War II struggle to return to Allied territory after being separated from U.S. forces during the historic Malmedy Massacre.",
"release_date": 1063242000,
"genres": [
"War",
"Action",
"Drama"
]
},
{
"id": "121576",
"title": "Saint Philip Neri I Prefer Heaven",
"poster": "https://image.tmdb.org/t/p/w500/z9OsQoM343WsIrP0zMEE06pO1vH.jpg",
"overview": "An epic feature film on the famous 'Apostle of Rome' and great friend of youth in the 16th century. One of the most popular saints of all time, St. Philip Neri was widely known for his great charity, deep prayer life, and tremendous humor. Hoping to join St. Ignatius of Loyola's new order of Jesuits and be a missionary to India, Philip was instead guided by Providence to seek out the poor and abandoned youth of Rome to catechize them in the faith and help them find a better life. He became the founder of the religious congregation, the Oratory, that worked with the youth and also labored to re-evangelize a decadent Rome.",
"release_date": 1284944400,
"genres": [
"Drama"
]
},
{
"id": "133558",
"title": "Saints and Soldiers: Airborne Creed",
"poster": "https://image.tmdb.org/t/p/w500/gwqR9UY0xqBZwP2qb8ZPmf9b2lq.jpg",
"overview": "A group of American GIs work their way through war-torn France during the final days of the Second World War.",
"release_date": 1345165200,
"genres": [
"Drama"
]
},
…
Now that you’ve experimented with command-line searching, if you’re running Meilisearch on a local machine, you can navigate to http://localhost:7700/ in a browser in order to view the web UI. If you’re running on a remote server and followed the prerequisites for this tutorial, your firewall configuration will prevent this URL from being accessible. You will need to create an SSH tunnel to access the search interface. To create a tunnel from your local machine to your server, run ssh with the -L flag. Provide the port number 7700 along with the IP address of your remote server:
- ssh -L 7700:127.0.0.1:7700 sammy@your_server_ip
You should then be able to access the dashboard in a browser at http://localhost:7700.
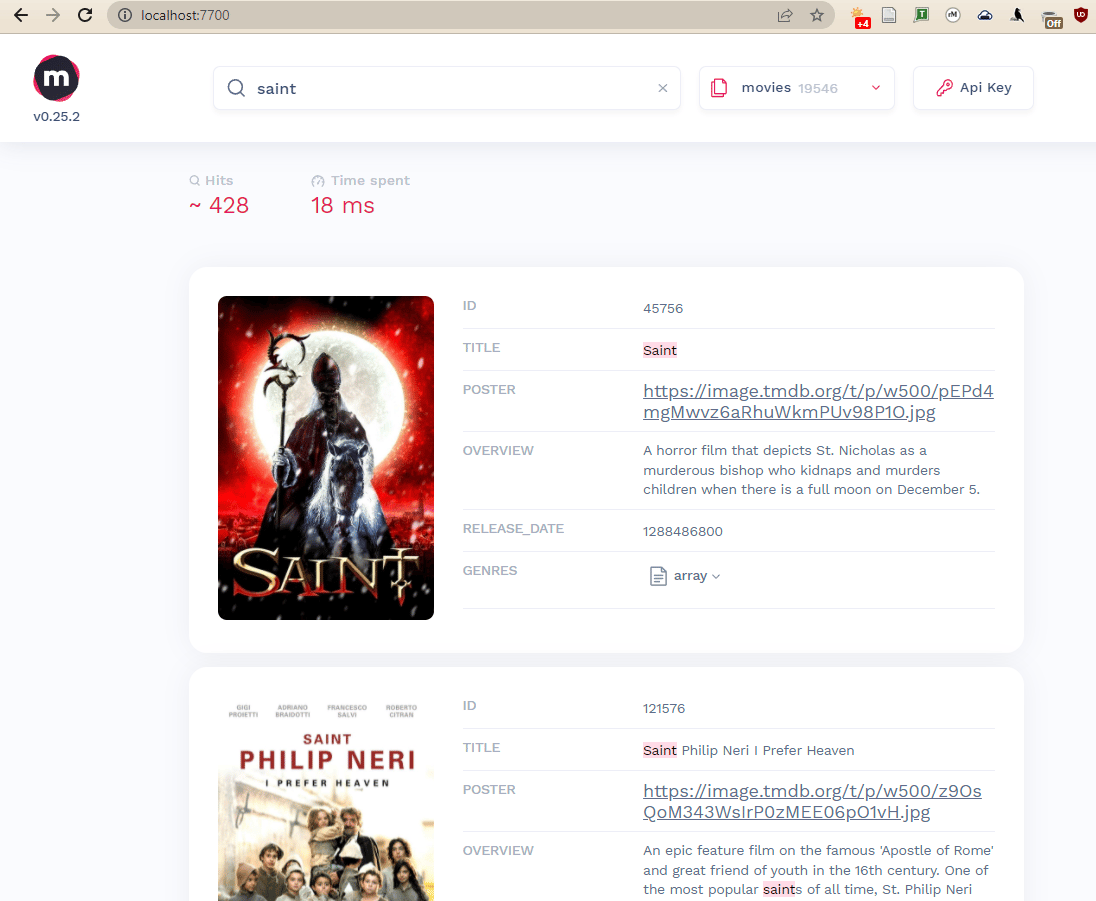
Searching in the Meilisearch demo interface is extremely fast, and should provide an exciting preview of production use. In the next step, you’ll find examples for tuning search ranking and filtering to bias certain parameters over others.
Step 3 – Tuning Search Ranking and Filtering
An important feature of search engines is that they all implement some method of weighting the importance of different fields. Another term for this weighting is bias. For example, suppose your search index contains multiple fields, and you search with a single word query. The search engine needs instructions on how to rank or bias its results based on the importance of a field.
Some open-source search engines do not allow you to configure biasing, and query results can be unhelpfully broad or skewed by trends in the data more than search term relevance. Meilisearch has a default set of bias rules that you can further configure. This customizability can help produce more intuitive and relevant results based on the particulars of your data.
To check your ranking rules, you can make an HTTP GET request using curl to the /settings/ranking-rules endpoint:
- curl -X GET 'http://localhost:7700/indexes/movies/settings/ranking-rules'
Output["words","typo","proximity","attribute","sort","exactness"]
These rules are explained in greater detail in the Meilisearch documentation. Essentially, they allow you to fine-tune the ways in which Meilisearch prioritizes resolving common typos, against prioritizing the proximity of words in phrases.
You can send an HTTP POST request with curl back to that endpoint with the same set of rules rearranged to change their priority order. If your dataset includes quantitative fields, you can also add ranking rules that will bias those fields in either ascending or descending order. In this dataset, release_date is one such field, which you could include like so:
- curl \
- -X POST 'http://localhost:7700/indexes/movies/settings/ranking-rules' \
- -H 'Content-Type: application/json' \
- --data-binary '[
- "words",
- "typo",
- "proximity",
- "release_date:asc",
- "attribute",
- "sort",
- "exactness",
- "rank:desc"
- ]'
This request will will return an enqueued response, similar to the first HTTP POST that you used to upload the movies.json file:
Output{"uid":1,"indexUid":"meteorites","status":"enqueued","type":"settingsUpdate","enqueuedAt":"2022-03-10T21:36:47.592902987Z"}
Meilisearch allows you to query and update rules that describe which attributes are searchable, which attributes are displayed in results, and which attributes can be filtered or sorted, using the same HTTP GET and HTTP POST approach.
For example, if you want only certain attributes to be searchable in the first place, and others (such as id, which likely has no value to an end user) to be excluded from results, you can POST a JSON list of searchableAttributes to the settings endpoint:
- curl \
- -X POST 'http://localhost:7700/indexes/movies/settings' \
- -H 'Content-Type: application/json' \
- --data-binary '{
- "searchableAttributes": [
- "title",
- "overview",
- "genres"
- ]
- }'
Now only the title, overview, and genres fields are searchable, and the rest are excluded from the indexing process.
You can also change which attributes are displayed or hidden from search results by POSTing a list of displayedAttributes:
- curl \
- -X POST 'http://localhost:7700/indexes/movies/settings' \
- -H 'Content-Type: application/json' \
- --data-binary '{
- "displayedAttributes": [
- "title",
- "overview",
- "genres",
- "release_date"
- ]
- }'
Now all the fields for a movie are hidden, except for the ones that you included in the list of displayedAttributes.
Finally, you can also provide a list of your data’s attributes to be filtered on or sorted. This list includes both quantitative filtering through the use of comparative operators (such as > for greater than or < for less than) and filtering through inclusion in a specified set, also known as faceted search.
- curl \
- -X POST 'http://localhost:7700/indexes/movies/settings' \
- -H 'Content-Type: application/json' \
- --data-binary '{
- "filterableAttributes": [
- "genres",
- "release_date"
- ],
- "sortableAttributes": [
- "release_date"
- ]
- }'
Together, these rules permit you to create queries like the following:
- curl \
- -X POST 'http://localhost:7700/indexes/movies/search' \
- -H 'Content-Type: application/json' \
- --data-binary '{ "q": "house", "sort": ["release_date:desc"], "filter": "genres = Horror" }'
This query is the equivalent of the written phrase: “find all movies with genre Horror from newest to oldest, which also contain the word ‘house’ in the title”. You will receive output like the following:
Output{
"hits": [
{
"id": "82505",
"title": "House at the End of the Street",
"poster": "https://image.tmdb.org/t/p/w500/t9E3Inaar1CAn5Cwj0M8dTwtD8H.jpg",
"overview": "A mother and daughter move to a new town and find themselves living next door to a house where a young girl murdered her parents. When the daughter befriends the surviving son, she learns the story is far from over.",
"release_date": 1348189200,
"genres": [
"Horror",
"Thriller"
]
},
{
"id": "29293",
"title": "House of the Dead 2",
"poster": "https://image.tmdb.org/t/p/w500/r95UYIFeCjIVKZ1MPxZwEHITAhg.jpg",
"overview": "In Guesta Verde University, the deranged Professor Curien is trying to bring back the dead, killing students for the experiment. There is an outbreak of zombies in the campus, and the government sends a NSA medical research team, formed by Dr. Alexandra Morgan a.k.a. Nightingale and lieutenant Ellis, with a special force leaded by lieutenant Dalton, trying to get the zero sample from the first generation zombie. The team has a very short time to accomplish their mission and leave the place before missiles are sent to destroy the area. However, the place is crowded of hyper sapiens and the group has to fight to survive.",
"release_date": 1139616000,
"genres": [
"TV Movie",
"Horror"
]
},
{
"id": "10066",
"title": "House of Wax",
"poster": "https://image.tmdb.org/t/p/w500/r0v8qg78Ol9NIsRGe3DME27ORpd.jpg",
"overview": "A group of unwitting teens are stranded near a strange wax museum and soon must fight to survive and keep from becoming the next exhibit.",
"release_date": 1114822800,
"genres": [
"Horror",
"Drama"
]
},
…
Including and excluding fields in indexing, searching, and displaying documents are core features of document-based search engines. Enabling them conditionally allows you to both maintain search performance and to quickly and exhaustively customize your search engine to suit end-users.
Now that you have explored how to run, query, and configure Meilisearch, in the next step of this tutorial, you’ll create a docker-compose configuration for Meilisearch that will allow it to run in the background with a secure authentication key.
Step 4 – Creating a Docker-Compose Configuration and Using Key-based Authentication
Like any other server-side application, end users of a Meilisearch index should assume that it will be running and available at all times. To ensure that Meilisearch can be regularly rebooted with your server, and its logs tracked, you should create a docker-compose configuration that will allow it to be managed automatically.
First, create a directory in /var/local that can be used for Meilisearch to permanently store its search index and other configuration details:
- sudo mkdir /var/local/meilisearch
After that, make a directory in your existing work environment called meilisearch-docker, which will be used to store a Docker configuration for Meilisearch, and then cd into that directory:
- mkdir ~/meilisearch-docker
- cd ~/meilisearch-docker
Next, using nano or your favorite text editor, open a file called docker-compose.yml:
- nano docker-compose.yml
Copy the following contents into the file. This will become your Meilisearch Docker configuration.
version: "3.9"
services:
meilisearch:
image: "getmeili/meilisearch:v0.26.1"
restart: unless-stopped
ports:
- "127.0.0.1:7700:7700"
volumes:
- /var/local/meilisearch:/data.ms
env_file:
- ./meilisearch.env
Save and close the file. If you are using nano, press Ctrl+X, then when prompted, Y and then ENTER.
The settings used in this file are similar to the original docker syntax you ran earlier in this tutorial, with a few additions:
restart:unless-stoppedmeans that this service will continue running in the background and persist through reboots unless you stop it manually.- Your Meilisearch index is now persistent and is stored in
/var/local/meilisearchon your local machine. env_filedeclares an environment file,./meilisearch.env, to configure Meilisearch options.
Environment variables allow you to run meilisearch with additional options, to effectively declare your configuration at runtime. Using environment variables is a consistent, system-wide way of configuring application parameters without needing to edit a configuration file specific to the application. docker-compose allows you to declare environment variables in a separate file to avoid having to include any secret information in the main docker-compse.yml configuration.
To run Meilisearch in production mode, you’ll need to configure an API key for secure use. You can create your own key, or generate one using the following openssl command:
- openssl rand -hex 30
Output173e95f077590ed33dad89247247be8d8ce8b6722ccc87829aaefe3207be
Make a note of this key someplace secure. Finally, using nano or your favorite text editor again, open that new file called meilisearch.env:
- nano meilisearch.env
Paste your key into the file as the MEILI_MASTER_KEY environment variable:
MEILI_MASTER_KEY="173e95f077590ed33dad89247247be8d8ce8b6722ccc87829aaefe3207be"
Save and close the file. If you still have an instance of Meilisearch running in another shell, you should now close it by navigating back to that terminal window and pressing Ctrl+C. Now, you can bring up the new Meilisearch Docker instance, using docker-compose up with --detach to run it in the background:
- docker compose up --detach
You can verify that it started successfully by using docker ps:
- docker compose ps
Output Name Command State Ports
------------------------------------------------------------------------------------------------------------
meilisearch-docker_meilisearch_1 tini -- /bin/sh -c ./meili ... Up 127.0.0.1:7700->7700/tcp
From now on, Meilisearch will automatically restart on server reboots. If you ever need to, you can stop the Docker container by navigating back to the ~/docker-meilisearch directory and running docker compose stop.
This docker-compose configuration will also create a new, empty search index which you will need to repopulate to continue working with the sample data. If you need to migrate any rules you’ve created with your existing index, you can follow the Meilisearch upgrade documentation.
Your Meilisearch instance is now also using key-based authentication, which requires an additional -H 'Authorization: Bearer 173e95f077590ed33dad89247247be8d8ce8b6722ccc87829aaefe3207be' header to be included with every API request. You can review the Meilisearch auth documentation to create multiple authentication keys with more granular levels of permission, if needed.
Conclusion
In this tutorial, you deployed and configured a Meilisearch index using Docker. You saw examples of its query parsing and its API response structures, as well as its web frontend search performance. You can query Meilisearch using JSON requests sent from any application, the same way you did by using curl. You experimented with changes to its search result weighting, and created a docker-compose.yml file to manage running your Meilisearch server.
You also created an API key and configured it as an environment variable for Meilisearch to prepare for a secure production deployment. However, the web-based search interface that you used in this tutorial is not designed to be used in production, as it has limited support for faceting and other advanced search features. In the next tutorial of this series, you will deploy a Meilisearch frontend using the InstantSearch library in a Node.js application.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Former Senior DevOps Technical Writer at DigitalOcean. Expertise in topics including Ubuntu 22.04, Linux, Rocky Linux, Debian 11, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Nice, many thanks.
On Meilisearch 0.28 (maybe before), and according to the official documentation (https://docs.meilisearch.com/learn/getting_started/quick_start.html#setup-and-installation > the -v argument), you need to change the volume line in the docker-compose file for:
volumes:
- /whatever/your/local/path:/meili_data
This will result to create a /whatever/your/local/path/data.ms folder (containing all your datas, that you can target to backup if needed) on your Docker server (so your local machine, or dev/prod server).
Hope it will clarify things :)
Best.
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
