By Benjamin Tan

Introducing Unicorn

If you are a Rails developer, you’ve probably heard of Unicorn, a HTTP server that can handle multiple requests concurrently.
Unicorn uses forked processes to achieve concurrency. Since forked processes are essentially copies of each other, this means that the Rails application need not be thread safe.
This is great because it is difficult to ensure that our own code is thread safe. If we cannot ensure that our code is thread safe, then concurrent web servers such as Puma and even alternative Ruby implementations that exploit concurrency and parallelism such as JRuby and Rubinius would be out of the question.
Therefore, Unicorn gives our Rails apps concurrency even when they are not thread safe. However, this comes at a cost. Rails apps running on Unicorn tend to consume much more memory. Without paying any heed to the memory consumption of your app, you may well find yourself with an overburdened cloud server.
In this article, we will explore a few ways to exploit Unicorn’s concurrency, while at the same time control the memory consumption.
Use Ruby 2.0!
If you are using Ruby 1.9, you should seriously consider switching to Ruby 2.0. To understand why, we need to understand a little bit about forking.
Forking and Copy-on-Write (CoW)
When a child process is forked, it is the exact same copy as the parent process. However, the actual physical memory copied need not be made. Since they are exact copies, both child and parent processes can share the same physical memory. Only when a write is made-- then we copy the child process into physical memory.
So how does this relate to Ruby 1.9/2.0 and Unicorn?
Recall the Unicorn uses forking. In theory, the operating system would be able to take advantage of CoW. Unfortunately, Ruby 1.9 does not make this possible. More accurately, the garbage collection implementation of Ruby 1.9 does not make this possible. An extremely simplified version is this — when the garbage collector of Ruby 1.9 kicks in, a write would have been made, thus rendering CoW useless.
Without going into too much detail, it suffices to say that the garbage collector of Ruby 2.0 fixes this, and we can now exploit CoW.
Tuning Unicorn’s Configuration
There are a few settings that we can tune in config/unicorn.rb to squeeze as much performance as we can from Unicorn.
worker_processes
This sets the number of worker processes to launch. It is important to know how much memory does one process take. This is so that you can safely budget the amount of workers, in order not to exhaust the RAM of your VPS.
timeout
This should be set to a small number: usually 15 to 30 seconds is a reasonable number. This setting sets the amount of time before a worker times out. The reason you want to set a relatively low number is to prevent a long-running request from holding back other requests from being processed.
preload_app
This should be set to true. Setting this to true reduces the start up time for starting up the Unicorn worker processes. This uses CoW to preload the application before forking other worker processes. However, there is a big gotcha. We must take special care that any sockets (such as database connections) are properly closed and reopened. We do this using before_fork and after_fork.
Here’s an example:
before_fork do |server, worker|
# Disconnect since the database connection will not carry over
if defined? ActiveRecord::Base
ActiveRecord::Base.connection.disconnect!
end
if defined?(Resque)
Resque.redis.quit
Rails.logger.info('Disconnected from Redis')
end
end
after_fork do |server, worker|
# Start up the database connection again in the worker
if defined?(ActiveRecord::Base)
ActiveRecord::Base.establish_connection
end
if defined?(Resque)
Resque.redis = ENV['REDIS_URI']
Rails.logger.info('Connected to Redis')
end
end
In this example, we make sure that the connection is closed and reopened when workers are forked. In addition to database connections, we need to make sure that other connections that require sockets are treated similarly. The above includes the configuration for Resque.
Taming Your Unicorn Workers Memory Consumption
Obviously, it’s not all rainbows and unicorns (pun intended!). If your Rails app is leaking memory - Unicorn will make it worse.
Each of these forked processes consume memory, since they are copies of the Rails application. Therefore, while having more workers would mean that our application could handle more incoming requests, we are bound by the amount of physical RAM we have on our system.
It is easy for a Rails application to leak memory. Even if we manage to plug all memory leaks, there is still the less than ideal garbage collector to contend with (I am referring to the MRI implementation).
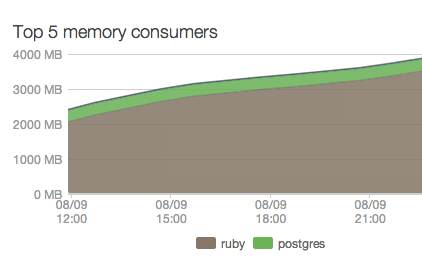
The above shows a Rails application running Unicorn with memory leaks.
Over time, the memory consumption will continue growing. Using multiple Unicorn workers would simply accelerate the rate at which memory is consumed, to the point when there is no more RAM to spare. The application would then grind to a halt — leading to hordes of unhappy users and customers.
It is important to note that this is not Unicorn’s fault. However, this is a problem that you would face sooner or later.
Enter the Unicorn Worker Killer
One of the easiest solutions I’ve come across is the unicorn-worker-killer gem.
From the README:
unicorn-worker-killergem provides automatic restart of Unicorn workers based on
- max number of requests, and
- process memory size (RSS), without affecting any requests.
This will greatly improve the site’s stability by avoiding unexpected memory exhaustion at the application nodes.
Note that I am assuming that you already have Unicorn set up and running.
Step 1:
Add unicorn-worker-killer to your Gemfile. Put this below the unicorn gem.
group :production do
gem 'unicorn'
gem 'unicorn-worker-killer'
end
Step 2:
Run bundle install.
Step 3:
Here comes the fun part. Locate and open your config.ru file.
# --- Start of unicorn worker killer code ---
if ENV['RAILS_ENV'] == 'production'
require 'unicorn/worker_killer'
max_request_min = 500
max_request_max = 600
# Max requests per worker
use Unicorn::WorkerKiller::MaxRequests, max_request_min, max_request_max
oom_min = (240) * (1024**2)
oom_max = (260) * (1024**2)
# Max memory size (RSS) per worker
use Unicorn::WorkerKiller::Oom, oom_min, oom_max
end
# --- End of unicorn worker killer code ---
require ::File.expand_path('../config/environment', __FILE__)
run YourApp::Application
First, we check that we are in the production environment. If so, we will go ahead and execute the code that follows.
unicorn-worker-killer kills workers given 2 conditions: Max requests and Max memory.
Max Requests
In this example, a worker is killed if it has handled between 500 to 600 requests. Notice that this is a range. This minimises the occurrence where more than 1 worker is terminated simultaneously.
Max Memory
Here, a worker is killed if it consumes between 240 to 260 MB of memory. This is a range for the same reason as above.
Every app has unique memory requirements. You should have a rough gauge of the memory consumption of your application during normal operation. That way, you could give a better estimate of the minimum and maximum memory consumption for your workers.
Once you have configured everything properly, upon deploying your app, you will notice a much lesser erratic memory behaviour:
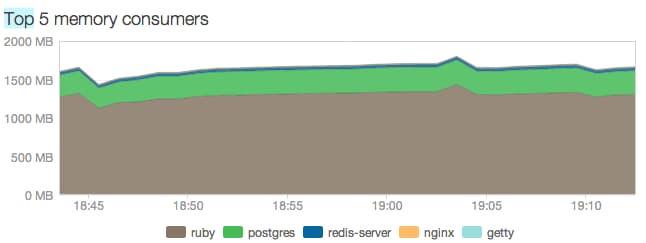
Notice the kinks in the graph. That is the gem doing its job!
Conclusion
Unicorn gives your Rails application a painless way to achieve concurrency, whether it is thread safe or not. However, it comes with a cost of increased RAM consumption. Balancing RAM consumption is absolutely essential to the stability and performance of your application.
We have seen 3 ways to tune your Unicorn workers for maximum performance:
-
Using Ruby 2.0 gives us a much improved garbage collector that allows us to exploit copy-on-write semantics.
-
Tuning the various configuration options in
config/unicorn.rb. -
Using
unicorn-worker-killerto solve the problem of gracefully by killing and restarting workers when they get too bloated.
Resources
-
A wonderful explanation of how the Ruby 2.0 garbage collector and copy-on-write semantics works.
-
The full list of Unicorn Configuration options.
<div class=“author”>Submitted by: <a href=“http://benjamintanweihao.github.io/”>Benjamin Tan</div>
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Nice article, but actually i don’t think is correct to speak about “memory leaks”. 99.99 out of 100 the problem is a “normal” memory bloating: Ruby GC allocate some more memory and the tipical linux malloc implementation will not release it.
Some related reading: https://blog.engineyard.com/2009/thats-not-a-memory-leak-its-bloat http://stackoverflow.com/questions/2215259/will-malloc-implementations-return-free-ed-memory-back-to-the-system
You’ll also want to use Unicorn’s out of band garbage collection.
require ‘unicorn/oob_gc’ use Unicorn::OobGC, 5
That will force Unicorn to GC after every 5th request before it does any more processing.
You don’t need to (and shouldn’t) disconnect from DB and Redis in before_fork.
Also, unicorn-worker-killer is great but it’s not enough - also there are chances that a single request bloats a tremendous amount of memory, and you don’t want the OOM killer to aim at PostgreSQL or sshd. My favorite is to tweak oom_adj to tell the kernel that it should kill those workers first before anything.
So your after_fork will look like this:
after_fork do |server, worker| ActiveRecord::Base.establish_connection Resque.redis.client.reconnect File.write “/proc/#{Process.pid}/oom_adj”, ‘12’ end
Hope this helps.
Can you elaborate on why “You don’t need to (and shouldn’t) disconnect from DB and Redis in before_fork.”?
re: no need to disconnect from DB and Redis in before_fork
By disconnecting in before_fork, you are closing the connection at the parent process every time you spawn a child, which is only needed once - you’re beating a dead horse. Connection handling is a child’s concern (after_fork) rather than a parent’s concern (before_fork).
ActiveRecord’s connection pool is now keyed by Process.pid, so it’s always safe to call ActiveRecord::Base.establish_connection in after_fork - the connection will never be shared with the parent, no need to disconnect at the master anyway.
On Unicorn, the master process is a singleton and can be used in many ways - spawn a thread and run EventMachine loop inside it to run scheduled / background jobs, etc. And there it’s useful to keep the AR connection open. Only main thread will be inherited to a child (on linux systems at least) so it’s safe to have threads.
Very interresting post mate. Can u explain one thign though about the license of unicorn-worker-killer: can i use it in my comercial application without being oblidged to open source my app?
much appreciated,
Personally I just run a cron command every few minutes that cycles through restarting each worker:
pkill -QUIT -of ‘unicorn_rails worker’
here is a rolling restart configuration: https://github.com/coletivoEITA/noosfero-cookbook/blob/master/templates/default/unicorn.conf.rb.erb
Another gotcha with preload_app true: if your deployment scripts do a restart with sig HUP, it will no longer reload application code. You must do an upgrade with sig USR2 and QUIT.
Good article.
Unicorn Worker Killer’s config.ru settings did not quite work for my setup as ENV[‘RAILS_ENV’] was not yet defined at this point of the code so everything inside the if statement was ignored.
I had to use ENV[‘RAKE_ENV’] instead, but on the gem’s documentation (https://github.com/kzk/unicorn-worker-killer) they don’t even put an if statement so that’s probably fine to get rid of it altogether.
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
