By Gbadebo Bello and Matt Abrams

Der Autor wählte den Free and Open Source Fund, um eine Spende im Rahmen des Programms Write for DOnations zu erhalten.
Einführung
Web Scraping ist ein Prozess zur Automatisierung der Erfassung von Daten aus dem Web. Der Prozess stellt in der Regel einen „Crawler“ bereit, der automatisch im Web surft und Daten von ausgewählten Seiten ausliest. Es gibt viele Gründe dafür, Daten auslesen zu wollen. In erster Linie macht das die Erfassung von Daten wesentlich schneller, da der manuelle Datenerfassungsprozess eliminiert wird. Zudem ist Scraping eine Lösung, wenn Datenerfassung gewünscht oder benötigt wird, die Website jedoch keine API bereitstellt.
In diesem Tutorial erstellen Sie mit Node.js und Puppeteer eine Web-Scraping-Anwendung. Ihre Anwendung wird mit dem Fortschreiten komplexer. Zuerst werden Sie Ihre Anwendung so codieren, dass sie Chromium öffnet und eine spezielle Website lädt, die als Web-Scraping-Sandbox konzipiert ist: books.toscrape.com. In den nächsten beiden Schritten werden Sie alle Bücher auf einer Seite von books.toscrape und dann alle Bücher über mehrere Seiten hinweg auslesen. In den verbleibenden Schritten filtern Sie Ihr Scraping nach Buchkategorie und speichern Ihre Daten dann als JSON-Datei.
Warnung: Die Ethik und Legalität von Web Scraping sind sehr komplex und entwickeln sich ständig weiter. Sie unterscheiden sich außerdem je nach Ihrem Standort, dem Standort der Daten und der entsprechenden Website. Dieses Tutorial wird eine spezielle Website (books.toscrape.com) ausgelesen, die speziell zum Testen von Scraper-Anwendungen entwickelt wurde. Das Scraping anderer Domänen geht über den Umfang dieses Tutorials hinaus.
Voraussetzungen
- Node.js, auf Ihrem Entwicklungs-Rechner installiert. Dieses Tutorial wurde unter Node.js Version 12.18.3 und npm Version 6.14.6 getestet. Sie können diesem Leitfaden folgen, um Node.js unter macOS oder Ubuntu 18.04 zu installieren, bzw. diesem Leitfaden folgen, um Node.js unter Ubuntu 18.04 mit einem PPA zu installieren.
Schritt 1 — Einrichten des Web Scrapers
Wenn Node.js installiert ist, können Sie mit dem Einrichten Ihres Web Scrapers beginnen. Zuerst erstellen Sie ein root-Verzeichnis für das Projekt und installieren dann die erforderlichen Abhängigkeiten. Dieses Tutorial erfordert nur eine Abhängigkeit. Sie installieren sie mit dem standardmäßigen Paketmanager npm von Node.js. Bei npm ist Node.js vorinstalliert, sodass Sie keine Installation mehr vornehmen müssen.
Erstellen Sie einen Ordner für dieses Projekt und öffnen Sie ihn:
- mkdir book-scraper
- cd book-scraper
Sie werden alle folgenden Befehle aus diesem Verzeichnis ausführen.
Wir müssen mit npm oder dem Node-Paketmanager ein Paket installieren. Initialisieren Sie zunächst npm, um eine Datei namens packages.json zu erstellen, die Abhängigkeiten und Metadaten Ihres Projekts verwalten wird.
Initialisieren Sie npm für Ihr Projekt:
- npm init
npm wird eine Sequenz von Eingabeaufforderungen anzeigen. Sie können bei jeder Eingabeaufforderung auf ENTER drücken oder personalisierte Beschreibungen hinzufügen. Stellen Sie sicher, dass Sie ENTER drücken und die Standardwerte lassen, wie sie sind, wenn Sie zur Eingabe von entry point und test command aufgefordert werden. Alternativ können Sie das y-Flag an npm — npm init -y — übergeben; damit werden alle Standardwerte für Sie übergeben.
Ihre Ausgabe wird etwa wie folgt aussehen:
Output{
"name": "sammy_scraper",
"version": "1.0.0",
"description": "a web scraper",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "sammy the shark",
"license": "ISC"
}
Is this OK? (yes) yes
Geben Sie yes ein und drücken Sie ENTER. npm speichert diese Ausgabe als Ihre package.json-Datei.
Verwenden Sie nun npm zum Installieren von Puppeteer:
- npm install --save puppeteer
Dieser Befehl installiert sowohl Puppeteer als auch eine Version von Chromium, von der das Puppeteer-Team weiß, dass sie mit der API funktionieren wird.
Auf Linux-Rechnern kann Puppeteer möglicherweise zusätzliche Abhängigkeiten benötigen.
Wenn Sie Ubuntu 18.04 verwenden, lesen Sie das Dropdown ‘Debian Dependencies’ im Abschnitt ‘Chrome headless doesn’t launch on UNIX’ in den Fehlerbehebungsdokumenten von Puppeteer. Sie können folgenden Befehl nutzen, um fehlende Abhängigkeiten zu finden:
- ldd chrome | grep not
Nachdem npm, Puppeteer und weitere Abhängigkeiten installiert sind, erfordert Ihre package.json-Datei eine letzte Konfiguration, bevor Sie mit dem Codieren beginnen. In diesem Tutorial starten Sie Ihre Anwendung mit npm run start aus der Befehlszeile. Sie müssen einige Informationen über dieses start-Skript zu package.json hinzufügen. Vor allem müssen Sie unter der scripts-Anweisung eine Zeile in Bezug auf Ihren start-Befehl hinzufügen.
Öffnen Sie die Datei in Ihrem bevorzugten Texteditor:
- nano package.json
Suchen Sie nach dem Abschnitt scripts: und fügen Sie die folgenden Konfigurationen hinzu. Denken Sie daran, am Ende der test-Skriptzeile ein Komma zu platzieren; sonst wird Ihre Datei wird nicht korrekt analysiert.
Output{
. . .
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node index.js"
},
. . .
"dependencies": {
"puppeteer": "^5.2.1"
}
}
Sie werden auch feststellen, dass puppeteer nun unter dependencies am Ende der Datei erscheint. Ihre package.json-Datei wird keine weiteren Überarbeitungen mehr benötigen. Speichern Sie Ihre Änderungen und schließen Sie den Editor.
Sie sind nun bereit, Ihren Scraper zu codieren. Im nächsten Schritt werden Sie eine Browserinstanz einrichten und die grundlegende Funktionalität Ihres Scrapers testen.
Schritt 2 — Einrichten der Browserinstanz
Wenn Sie einen traditionellen Browser öffnen, können Sie auf Schaltflächen klicken, mit Ihrer Maus navigieren, Text eingeben, dev-Tools öffnen und mehr. Ein Headless-Browser wie Chromium ermöglicht Ihnen, dasselbe zu tun, aber programmatisch und ohne Benutzeroberfläche. In diesem Schritt werden Sie die Browserinstanz Ihres Scrapers einrichten. Wenn Sie Ihre Anwendung starten, öffnet sie Chromium automatisch und navigiert zu books.toscrape.com. Diese anfänglichen Aktionen werden die Grundlage Ihres Programms bilden.
Ihr Web Scraper wird vier .js-Dateien benötigen: browser.js, index,js, pageController.js und pageScraper.js. In diesem Schritt erstellen Sie alle vier Dateien und aktualisieren sie dann weiter, sobald Ihr Programm komplexer wird. Beginnen Sie mit browser.js; diese Datei enthält das Skript, das Ihren Browser startet.
Erstellen und öffnen Sie browser.js in einem Texteditor aus dem root-Verzeichnis Ihres Projekts:
- nano browser.js
Zuerst werden Sie Puppeteer erfordern und dann eine async-Funktion namens startBrowser() erstellen. Diese Funktion startet den Browser und gibt eine Instanz davon zurück. Fügen Sie folgenden Code hinzu:
const puppeteer = require('puppeteer');
async function startBrowser(){
let browser;
try {
console.log("Opening the browser......");
browser = await puppeteer.launch({
headless: false,
args: ["--disable-setuid-sandbox"],
'ignoreHTTPSErrors': true
});
} catch (err) {
console.log("Could not create a browser instance => : ", err);
}
return browser;
}
module.exports = {
startBrowser
};
Puppeteer bietet eine .launch()-Methode, mit der eine Instanz eines Browsers gestartet wird. Diese Methode gibt eine Zusage zurück; Sie müssen also sicherstellen, dass die Zusage mit einem .then- oder await-Block aufgelöst wird.
Sie verwenden await um sicherzustellen, dass die Zusage aufgelöst wird, indem diese Instanz um einen try-catch-Codeblock eingeschlossen und dann eine Instanz des Browsers zurückgeben wird.
Beachten Sie, dass die Methode .launch() einen JSON-Parameter mit mehreren Werten nutzt:
- headless -
falsebedeutet, dass der Browser mit einer Oberfläche ausgeführt wird, sodass Sie Ihr Skript bei der Ausführung sehen können;truehingegen bedeutet, dass der Browser im headless-Modus ausgeführt wird. Beachten Sie unbedingt, dass Sie bei Bereitstellen Ihres Scrapers in der Cloudheadlessauftruezurücksetzen müssen. Die meisten virtuellen Rechner sind headless und enthalten keine Benutzeroberfläche; daher kann der Browser nur im headless-Modus ausgeführt werden. Puppeteer umfasst auch einenheadful-Modus, der aber ausschließlich für Testzwecke verwendet werden sollte. - **ignoreHTTPSErrors **-
trueermöglicht Ihnen, Websites zu besuchen, die nicht über ein sicheres HTTPS-Protokoll gehostet werden, und jegliche HTTPS-Fehler zu ignorieren.
Speichern und schließen Sie die Datei.
Erstellen Sie nun Ihre zweite .js-Datei, index.js:
- nano index.js
Hier werden Sie browser.js und pageController.js erfordern. Dann werden Sie die Funktion startBrowser() aufrufen und die erstellte Browserinstanz an den Seitencontroller übergeben, der die Aktionen steuern wird. Fügen Sie folgenden Code hinzu:
const browserObject = require('./browser');
const scraperController = require('./pageController');
//Start the browser and create a browser instance
let browserInstance = browserObject.startBrowser();
// Pass the browser instance to the scraper controller
scraperController(browserInstance)
Speichern und schließen Sie die Datei.
Erstellen Sie Ihre dritte .js-Datei, pageController.js:
- nano pageController.js
pageController.js steuert Ihren Scraping-Prozess. Es verwendet die Browserinstanz zum Steuern der Datei pageScraper.js, in der alle Scraping-Skripte ausgeführt werden. Schließlich werden Sie sie verwenden, um anzugeben, welche Buchkategorie Sie auslesen möchten. Sie wollen jedoch zunächst sicherstellen, dass Sie Chromium öffnen und zu einer Webseite navigieren können:
const pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
await pageScraper.scraper(browser);
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Dieser Code exportiert eine Funktion, die die Browserinstanz nimmt und an eine Funktion namens scrapeAll() übergibt. Diese Funktion wiederum übergibt diese Instanz an pageScraper.scraper() als Argument, das sie zum Auslesen von Seiten verwendet wird.
Speichern und schließen Sie die Datei.
Erstellen Sie schließlich Ihre letzte .js-Datei, pageScraper.js:
- nano pageScraper.js
Hier erstellen Sie ein Objektliteral mit einer url-Eigenschaft und einer scraper()-Methode. Die url ist die Web-URL der Webseite, die Sie auslesen möchten, während die Methode scraper() den Code enthält, der das tatsächliche Scraping ausführt; in diesem Stadium navigiert sie jedoch lediglich zu einer URL. Fügen Sie folgenden Code hinzu:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
await page.goto(this.url);
}
}
module.exports = scraperObject;
Puppeteer hat eine newPage()-Methode, die eine neue Seiteninstanz im Browser erstellt. Diese Seiteninstanzen können einiges erledigen. In unserer scraper()-Methode haben Sie eine Seiteninstanz erstellt und dann die Methode page.goto() verwendet, um zur Homepage books.toscrape.com zu navigieren.
Speichern und schließen Sie die Datei.
Die Dateistruktur Ihres Programms ist nun fertig. Die erste Ebene der Verzeichnisstruktur Ihres Projekts wird wie folgt aussehen:
Output.
├── browser.js
├── index.js
├── node_modules
├── package-lock.json
├── package.json
├── pageController.js
└── pageScraper.js
Führen Sie nun den Befehl npm run start aus und sehen Sie, wie Ihre Scraper-Anwendung ausgeführt wird:
- npm run start
Dadurch wird automatisch eine Chromium-Browserinstanz geöffnet, im Browser eine neue Seite geöffnet und zu books.toscrape.com navigiert.
In diesem Schritt haben Sie eine Puppeteer-Anwendung erstellt, die Chromium geöffnet und die Homepage für einen Dummy-Online-Buchladen (books.toscrape.com) geladen hat. Im nächsten Schritt werden Sie die Daten für jedes einzelne Buch auf dieser Homepage auslesen.
Schritt 3 — Auslesen von Daten von einer einzelnen Seite
Bevor Sie Ihrer Scraper-Anwendung mehr Funktionen hinzufügen, öffnen Sie Ihren bevorzugten Webbrowser und navigieren Sie manuell zur Books-to-scrape-Homepage. Durchsuchen Sie die Website und finden Sie heraus, wie die Daten strukturiert sind.
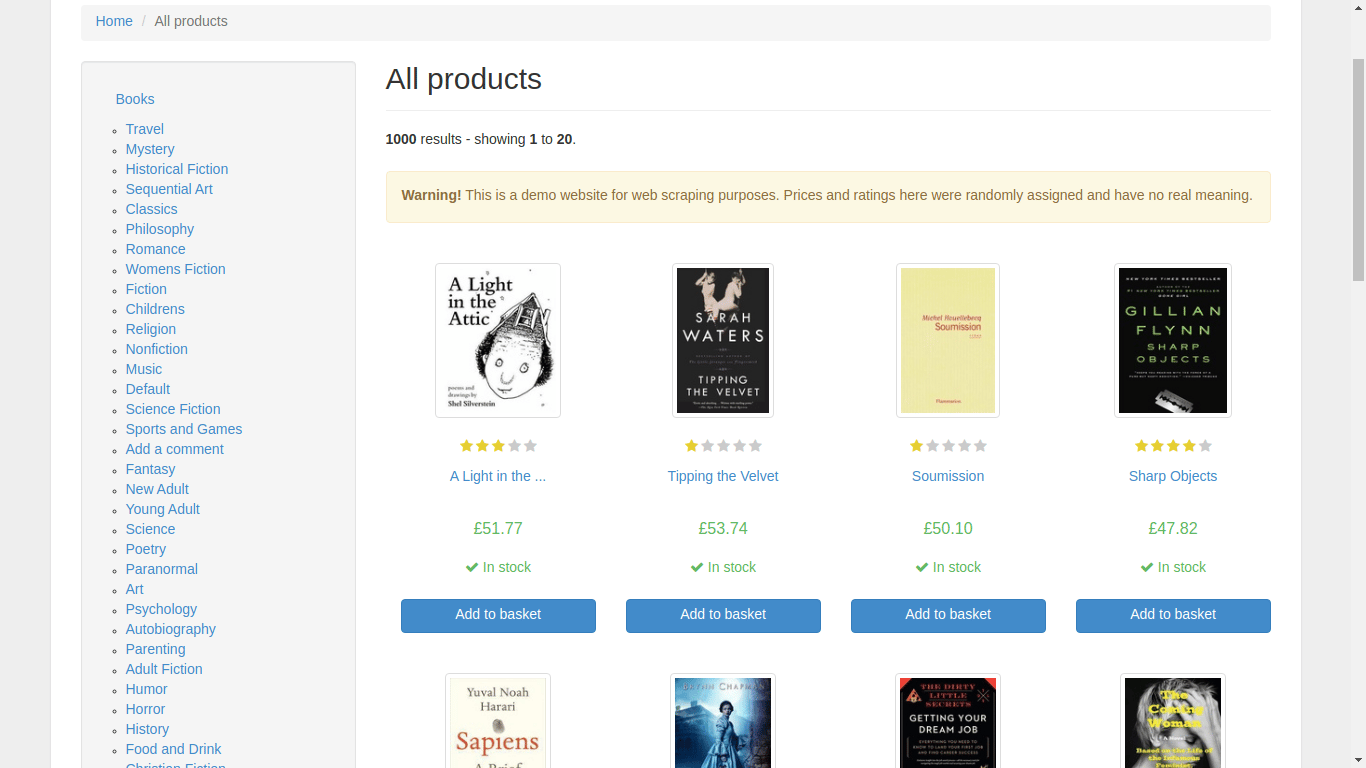
Sie finden links einen Kategorienabschnitt und rechts Bücher. Wenn Sie auf ein Buch klicken, navigiert der Browser zu einer neuen URL, die relevante Informationen zu diesem bestimmten Buch anzeigt.
In diesem Schritt werden Sie dieses Verhalten replizieren, aber mit Code; Sie werden das Navigieren der Website automatisieren und deren Daten konsumieren.
Wenn Sie zunächst mithilfe der Dev-Tools in Ihrem Browser den Quellcode für die Homepage prüfen, werden Sie feststellen, dass die Seite Daten der einzelnen Bücher unter einem section Tag auflistet. Im Inneren des section-Tags befindet sich jedes Buch unter einem list (li)-Tag; hier finden Sie den Link zur Seite des jeweiligen Buchs, den Preis und die Verfügbarkeit.
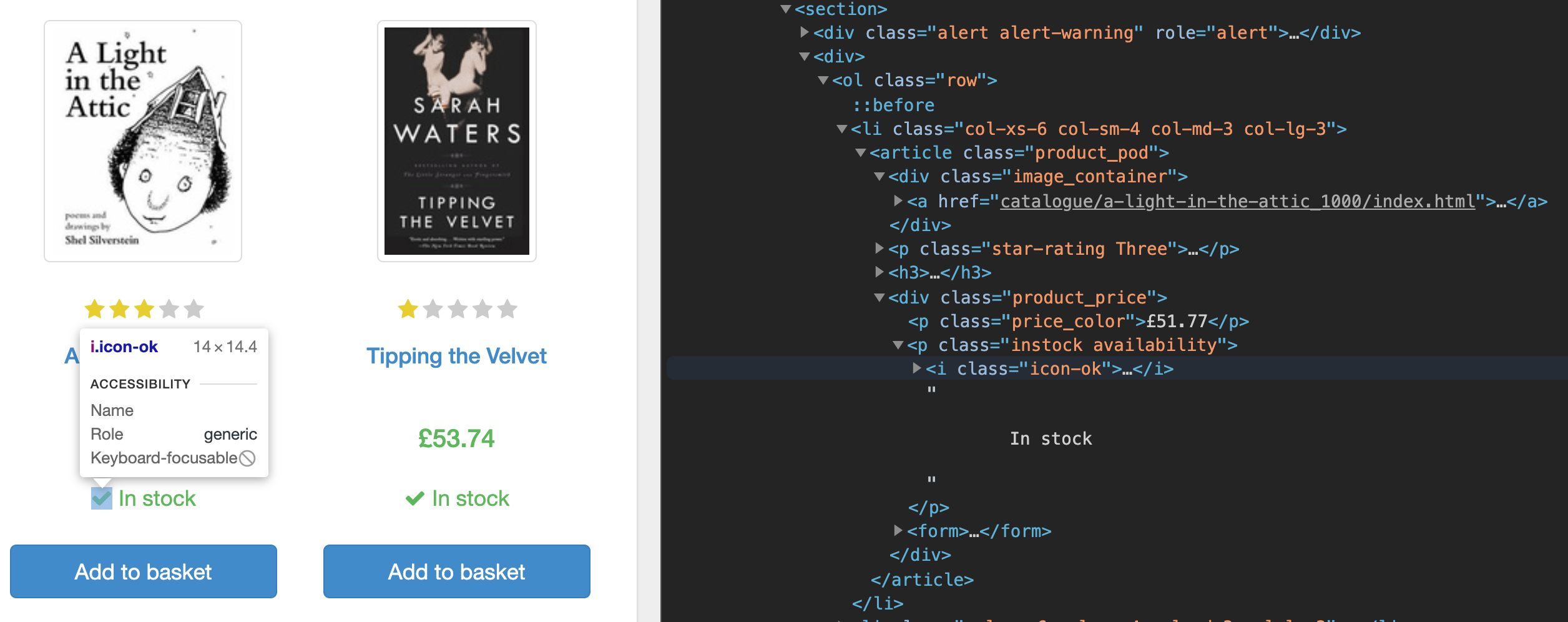
Sie werden diese Buch-URLs auslesen, nach vorrätigen Büchern filtern, zur Seite des jeweiligen Buchs navigieren und Daten des Buchs auslesen.
Öffnen Sie erneut Ihre pageScraper.js-Datei:
- nano pageScraper.js
Fügen Sie den folgenden hervorgehobenen Inhalt hinzu: Sie werden einen weiteren await-Block in der Datei await page.goto(this.url); schachteln:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Wait for the required DOM to be rendered
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
console.log(urls);
}
}
module.exports = scraperObject;
In diesem Codeblock haben Sie die Methode page.waitForSelector() aufgerufen. Diese hat , bis div alle buchbezogenen Daten enthält, die im DOM dargestellt werden sollen; dann haben Sie die Methode page.$$eval() aufgerufen. Diese Methode ruft das URL-Element mit dem Selektor section ol li ab (Sie sollten sicherstellen, dass Sie aus den Methoden page.$$eval() und page.$eval() immer nur eine Zeichenfolge oder Zahl zurückgeben.
Jedes Buch verfügt über zwei Status; ein Buch ist entweder In Stock (Vorrätig) oder Out of stock (Nicht vorrätig). Sie möchten nur Bücher auslesen, die In Stock sind. Da page.$$eval() ein Array aller übereinstimmenden Elemente zurückgibt, haben Sie dieses Array gefiltert, um sicherzustellen, dass Sie nur mit vorrätigen Büchern arbeiten. Sie haben dazu die Klasse .instock.availability gesucht und ausgewertet. Sie haben dann die Eigenschaft href der Buchlinks zugeordnet und aus der Methode zurückgegeben.
Speichern und schließen Sie die Datei.
Führen Sie Ihre Anwendung neu aus:
- npm run start
Der Browser öffnet sich, navigiert zur Webseite und schließt nach Abschluss der Aufgabe. Überprüfen Sie nun Ihre Konsole; sie enthält alle ausgelesenen URLs:
Output> book-scraper@1.0.0 start /Users/sammy/book-scraper
> node index.js
Opening the browser......
Navigating to http://books.toscrape.com...
[
'http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html',
'http://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html',
'http://books.toscrape.com/catalogue/soumission_998/index.html',
'http://books.toscrape.com/catalogue/sharp-objects_997/index.html',
'http://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html',
'http://books.toscrape.com/catalogue/the-requiem-red_995/index.html',
'http://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html',
'http://books.toscrape.com/catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html',
'http://books.toscrape.com/catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html',
'http://books.toscrape.com/catalogue/the-black-maria_991/index.html',
'http://books.toscrape.com/catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html',
'http://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html',
'http://books.toscrape.com/catalogue/set-me-free_988/index.html',
'http://books.toscrape.com/catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html',
'http://books.toscrape.com/catalogue/rip-it-up-and-start-again_986/index.html',
'http://books.toscrape.com/catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html',
'http://books.toscrape.com/catalogue/olio_984/index.html',
'http://books.toscrape.com/catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html',
'http://books.toscrape.com/catalogue/libertarianism-for-beginners_982/index.html',
'http://books.toscrape.com/catalogue/its-only-the-himalayas_981/index.html'
]
Das ist ein guter Anfang; Sie möchten jedoch alle relevanten Daten für ein bestimmtes Buch und nicht nur dessen URL auslesen. Sie werden nun diese URLs verwenden, um die einzelnen Seiten zu öffnen und Titel, Autor, Preis, Verfügbarkeit, UPC, Beschreibung und Bild-URL auszulesen.
Öffnen Sie pageScraper.js neu:
- nano pageScraper.js
Fügen Sie den folgenden Code hinzu, der die einzelnen ausgelesenen Links durchläuft, eine neue Seiteninstanz öffnen und dann die entsprechenden Daten abruft:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Wait for the required DOM to be rendered
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
// scrapedData.push(currentPageData);
console.log(currentPageData);
}
}
}
module.exports = scraperObject;
Sie verfügen über ein Array mit allen URLs. Sie möchten dieses Array durchlaufen, die URL in einer neuen Seite öffnen, Daten auf dieser Seite auslesen, diese Seite schließen und eine neue Seite für die nächste URL im Array öffnen. Beachten Sie, dass Sie diesen Code in einer Zusage eingeschlossen haben. Das liegt daran, dass Sie warten möchten, bis jede Aktion in Ihrer Schleife abgeschlossen ist. Daher wird jede Zusage eine neue URL öffnen und erst aufgelöst, wenn das Programm alle Daten in der URL ausgelesen hat und die Seiteninstanz geschlossen wurde.
Achtung: Beachten Sie, dass Sie mit einer for-in-Schleife auf die Zusage gewartet haben. Jede andere Schleife wird ausreichen; vermeiden Sie jedoch, mithilfe einer array-iteration-Methode wie forEach oder einer anderen Methode, die eine Callback-Funktion verwendet, über Ihre URL-Arrays zu iterieren. Die Callback-Funktion muss nämlich zunächst die Callback-Warteschlange und die Ereignisschleife durchlaufen; daher werden mehrere Seiteninstanzen auf einmal geöffnet. Dadurch wird Ihr Arbeitsspeicher deutlich stärker belastet.
Werfen Sie einen genaueren Blick auf Ihre pagePromise-Funktion. Ihr Scraper hat zunächst für jede URL eine neue Seite erstellt und dann die Funktion page.$eval() verwendet, um Selektoren für relevante Details auszuwählen, die Sie auf der neuen Seite auslesen möchten. Einige der Texte enthalten Leerzeichen, Tabs, Zeilenumbrüche und andere nicht-alphanumerische Zeichen, die Sie mit einem regulären Ausdruck verworfen haben. Sie haben dann den Wert für jedes Datenelement, das in dieser Seite ausgelesen wurde, einem Objekt angefügt und dieses Objekt aufgelöst.
Speichern und schließen Sie die Datei.
Führen Sie das Skript erneut aus:
- npm run start
Der Browser öffnet die Homepage, öffnet dann jede Buchseite und protokolliert die ausgelesenen Daten der einzelnen Seiten. Diese Ausgabe wird in Ihrer Konsole ausgedruckt:
OutputOpening the browser......
Navigating to http://books.toscrape.com...
{
bookTitle: 'A Light in the Attic',
bookPrice: '£51.77',
noAvailable: '22',
imageUrl: 'http://books.toscrape.com/media/cache/fe/72/fe72f0532301ec28892ae79a629a293c.jpg',
bookDescription: "It's hard to imagine a world without A Light in the Attic. [...]',
upc: 'a897fe39b1053632'
}
{
bookTitle: 'Tipping the Velvet',
bookPrice: '£53.74',
noAvailable: '20',
imageUrl: 'http://books.toscrape.com/media/cache/08/e9/08e94f3731d7d6b760dfbfbc02ca5c62.jpg',
bookDescription: `"Erotic and absorbing...Written with starling power."--"The New York Times Book Review " Nan King, an oyster girl, is captivated by the music hall phenomenon Kitty Butler [...]`,
upc: '90fa61229261140a'
}
{
bookTitle: 'Soumission',
bookPrice: '£50.10',
noAvailable: '20',
imageUrl: 'http://books.toscrape.com/media/cache/ee/cf/eecfe998905e455df12064dba399c075.jpg',
bookDescription: 'Dans une France assez proche de la nôtre, [...]',
upc: '6957f44c3847a760'
}
...
In diesem Schritt haben Sie für jedes Buch auf der Homepage von books.toscrape.com relevante Daten ausgelesen; Sie können jedoch noch viel mehr Funktionen hinzufügen. Jede Seite mit Büchern zum Beispiel ist paginiert; wie erhalten Sie Bücher von diesen anderen Seiten? Außerdem haben Sie auf der linken Seite der Website Buchkategorien gefunden; was ist, wenn Sie gar nicht alle Bücher sehen möchten, sondern lediglich Bücher aus einem bestimmten Genre? Sie werden nun die entsprechenden Funktionen hinzufügen.
Schritt 4 — Auslesen von Daten von verschiedenen Seiten
Seiten auf books.toscrape.com, die paginiert sind, verfügen unter ihrem Inhalt über eine next-Schaltfläche; Seiten, die nicht paginiert sind, haben das nicht.
Sie werden anhand der Anwesenheit dieser Schaltfläche erkennen, ob eine Seite paginiert ist oder nicht. Da die Daten auf jeder Seite dieselbe Struktur haben und das gleiche Markup aufweisen, müssen Sie nicht für jede mögliche Seite einen eigenen Scraper schreiben. Vielmehr werden Sie die Praxis der Rekursion nutzen.
Zuerst müssen Sie die Struktur Ihres Codes etwas ändern, um eine rekursive Navigation zu mehreren Seiten zu ermöglichen.
Öffnen Sie pagescraper.js erneut:
- nano pagescraper.js
Sie werden eine neue Funktion namens scrapeCurrentPage() zu Ihrer scraper()-Methode hinzufügen. Diese Funktion wird den gesamten Code enthalten, der Daten von einer bestimmten Seite ausliest, und dann auf die next-Schaltfläche klicken (so vorhanden). Fügen Sie den folgenden hervorgehobenen Code hinzu:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
let scrapedData = [];
// Wait for the required DOM to be rendered
async function scrapeCurrentPage(){
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
scrapedData.push(currentPageData);
// console.log(currentPageData);
}
// When all the data on this page is done, click the next button and start the scraping of the next page
// You are going to check if this button exist first, so you know if there really is a next page.
let nextButtonExist = false;
try{
const nextButton = await page.$eval('.next > a', a => a.textContent);
nextButtonExist = true;
}
catch(err){
nextButtonExist = false;
}
if(nextButtonExist){
await page.click('.next > a');
return scrapeCurrentPage(); // Call this function recursively
}
await page.close();
return scrapedData;
}
let data = await scrapeCurrentPage();
console.log(data);
return data;
}
}
module.exports = scraperObject;
Sie setzen die nextButtonExist-Variable zunächst auf false und überprüfen dann, ob die Schaltfläche vorhanden ist. Wenn die next-Schaltfläche vorhanden ist, haben Sie nextButtonExists auf true gesetzt; klicken Sie dann auf die next-Schaltfläche und rufen diese Funktion rekursiv auf.
Wenn nextButtonExists false ist, wird wie gewöhnlich das Array scrapedData zurückgegeben.
Speichern und schließen Sie die Datei.
Führen Sie Ihr Skript erneut aus:
- npm run start
Das kann eine Weile dauern; Ihre Anwendung liest nun schließlich Daten von über 800 Büchern aus. Sie können entweder den Browser schließen oder Strg+C drücken, um den Prozess zu beenden.
Sie haben nun die Funktionen Ihres Scrapers maximiert, dabei aber ein neues Problem geschaffen. Jetzt besteht das Problem nicht aus zu wenig Daten, sondern aus zu viel Daten. Im nächsten Schritt werden Sie Ihre Anwendung so anpassen, dass Ihr Scraping nach Buchkategorien gefiltert wird.
Schritt 5 — Auslesen von Daten nach Kategorie
Um Daten nach Kategorien auszulesen, müssen Sie sowohl Ihre pageScraper.js - als auch Ihre pageController.js-Datei ändern.
Öffnen Sie pageController.js in einem Texteditor:
nano pageController.js
Rufen Sie den Scraper so auf, dass nur Reisebücher ausgelesen werden. Fügen Sie folgenden Code hinzu:
const pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
await browser.close();
console.log(scrapedData)
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Sie übergeben nun zwei Parameter in Ihre pageScraper.scraper()-Methode, wobei der zweite Parameter die Kategorie von Büchern ist, die Sie auslesen möchten; in diesem Beispiel: Travel. Doch erkennt Ihre pageScraper.js-Datei diesen Parameter noch nicht. Sie müssen auch diese Datei anpassen.
Speichern und schließen Sie die Datei.
Öffnen Sie pageScraper.js:
- nano pageScraper.js
Fügen Sie den folgenden Code hinzu, der Ihren Kategorieparameter hinzufügen wird, navigieren zu dieser Kategorieseite und dann lesen Sie dann die paginierten Ergebnisse aus:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser, category){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Select the category of book to be displayed
let selectedCategory = await page.$$eval('.side_categories > ul > li > ul > li > a', (links, _category) => {
// Search for the element that has the matching text
links = links.map(a => a.textContent.replace(/(\r\n\t|\n|\r|\t|^\s|\s$|\B\s|\s\B)/gm, "") === _category ? a : null);
let link = links.filter(tx => tx !== null)[0];
return link.href;
}, category);
// Navigate to the selected category
await page.goto(selectedCategory);
let scrapedData = [];
// Wait for the required DOM to be rendered
async function scrapeCurrentPage(){
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
scrapedData.push(currentPageData);
// console.log(currentPageData);
}
// When all the data on this page is done, click the next button and start the scraping of the next page
// You are going to check if this button exist first, so you know if there really is a next page.
let nextButtonExist = false;
try{
const nextButton = await page.$eval('.next > a', a => a.textContent);
nextButtonExist = true;
}
catch(err){
nextButtonExist = false;
}
if(nextButtonExist){
await page.click('.next > a');
return scrapeCurrentPage(); // Call this function recursively
}
await page.close();
return scrapedData;
}
let data = await scrapeCurrentPage();
console.log(data);
return data;
}
}
module.exports = scraperObject;
Dieser Codeblock verwendet die von Ihnen übergebene Kategorie, um die URL zu erhalten, in der sich die Bücher dieser Kategorie befinden.
Die page.$$eval()-Methode kann Argumente übernehmen, indem das Argument als dritter Parameter an die $$eval()-Methode übergeben und so als dritter Parameter im Callback definiert wird:
page.$$eval('selector', function(elem, args){
// .......
}, args)
Genau das haben Sie in Ihrem Code getan; Sie haben die Kategorie von Büchern übergeben, die Sie auslesen möchten, sind alle Kategorien durchlaufen um zu überprüfen, welche übereinstimmt, und dann die URL dieser Kategorie zurückgegeben.
Diese URL wird dann verwendet, um zu der Seite zu navigieren, die die Kategorie von Büchern anzeigt, die Sie mithilfe der Methode page.goto(selectedCategory) auslesen möchten.
Speichern und schließen Sie die Datei.
Führen Sie Ihre Anwendung erneut aus. Sie werden feststellen, dass sie zur Kategorie Travel navigiert, Bücher in dieser Kategorieseite nach Seite rekursiv öffnet und die Ergebnisse protokolliert:
- npm run start
In diesem Schritt haben Sie Daten über mehrere Seiten hinweg ausgelesen und dann Daten aus einer bestimmten Kategorie über mehrere Seiten hinweg ausgelesen. Im letzten Schritt werden Sie Ihr Skript so ändern, dass Daten über mehrere Kategorien hinweg ausgelesen und dann in einer Zeichenfolgen-förmigen JSON-Datei gespeichert werden.
Schritt 6 — Auslesen von Daten aus verschiedenen Kategorien und Speichern der Daten als JSON
In diesem letzten Schritt werden Sie dafür sorgen, dass Ihr Skript Daten aus so vielen Kategorien abliest, wie Sie möchten, und dann die Art der Ausgabe ändern. Anstatt die Ergebnisse zu protokollieren, speichern Sie sie in einer strukturierten Datei namens data.json.
Sie können schnell mehr Kategorien zum Auslesen hinzufügen; dazu ist nur eine zusätzliche Zeile pro Genre erforderlich.
Öffnen Sie pageController.js:
- nano pageController.js
Passen Sie Ihren Code so an, dass zusätzliche Kategorien enthalten sind. Das folgende Beispiel fügt HistoricalFiction und Mystery zu unserer vorhandenen Travel-Kategorie hinzu:
const pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
scrapedData['HistoricalFiction'] = await pageScraper.scraper(browser, 'Historical Fiction');
scrapedData['Mystery'] = await pageScraper.scraper(browser, 'Mystery');
await browser.close();
console.log(scrapedData)
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Speichern und schließen Sie die Datei.
Führen Sie das Skript erneut aus und sehen Sie, wie Daten für alle drei Kategorien ausgelesen werden:
- npm run start
Da der Scraper nun voll funktional ist, besteht Ihr letzter Schritt darin, Ihre Daten in einem nützlicheren Format zu speichern. Sie werden sie jetzt in einer JSON-Datei mit dem fs-Modul in Node.js speichern.
Öffnen Sie zunächst pageController.js neu:
- nano pageController.js
Fügen Sie den folgenden hervorgehobenen Code hinzu:
const pageScraper = require('./pageScraper');
const fs = require('fs');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
scrapedData['HistoricalFiction'] = await pageScraper.scraper(browser, 'Historical Fiction');
scrapedData['Mystery'] = await pageScraper.scraper(browser, 'Mystery');
await browser.close();
fs.writeFile("data.json", JSON.stringify(scrapedData), 'utf8', function(err) {
if(err) {
return console.log(err);
}
console.log("The data has been scraped and saved successfully! View it at './data.json'");
});
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Zuerst fordern Sie das fs-Modul von Node.js in pageController.js an. Dadurch wird sichergestellt, dass Sie Ihre Daten als JSON-Datei speichern können. Dann fügen Sie Code hinzu, damit das Programm eine neue Datei namens data.json erstellt, sobald das Scraping abgeschlossen ist und der Browser schließt. Beachten Sie, dass der Inhalt von data.json Zeichenfolgen-förmiges JSON ist. Wenn Sie den Inhalt von data.json lesen, analysieren Sie ihn also immer als JSON, bevor Sie die Daten erneut verwenden.
Speichern und schließen Sie die Datei.
Sie haben nun eine Web-Scraping-Anwendung erstellt, die Bücher über verschiedene Kategorien hinweg ausliest und die ausgelesenen Daten dann in einer JSON-Datei speichert. Wenn Ihre Anwendung komplexer wird, möchten Sie die ausgelesenen Daten möglicherweise in einer Datenbank speichern oder über eine API bereitstellen. Wie diese Daten verbraucht werden, liegt ganz bei Ihnen.
Zusammenfassung
In diesem Tutorial haben Sie einen Web Crawler erstellt, der Daten über mehrere Seiten rekursiv ausliest und dann in einer JSON-Datei speichert. Kurz gesagt: Sie haben eine neue Methode erlernt, um die Datenerfassung von Websites zu automatisieren.
Puppeteer hat eine Menge von Funktionen, die im Rahmen dieses Tutorials nicht abgedeckt wurden. Um mehr darüber zu erfahren, lesen Sie Verwenden von Puppeteer für einfache Kontrolle über Headless Chrome. Sie können auch die offizielle Dokumentation von Puppeteer besuchen.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
Gbadebo is a software engineer that is extremely passionate about JavaScript technologies, Open Source Development and community advocacy.
Supporting the open-source community one tutorial at a time. Former Technical Editor at DigitalOcean. Expertise in topics including Ubuntu 22.04, Ubuntu 20.04, CentOS, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
