By Gbadebo Bello and Matt Abrams

L’auteur a choisi le Free and Open Source Fund comme récipiendaire d’un don dans le cadre du programme Write for DOnations.
Introduction
Le moissonnage est une technique d’automatisation de la collecte des données depuis le web. Le processus déploie généralement un « collecteur » qui surfe automatiquement le web et moissonne les données des pages sélectionnées. Il existe de nombreuses raisons pour lesquelles vous pouvez vouloir extraire des données. En premier lieu, en éliminant le processus manuel de recueil de données, la collecte des données est beaucoup plus rapide. Vous pouvez également utiliser le moissonnage si vous souhaitez ou avez besoin de collecter des données mais que le site web ne dispose pas d’une API pour le faire.
Au cours de ce tutoriel, vous allez créer une application de grattage web en utilisant Node.js et Puppeteer. Votre application deviendra de plus en plus complexe à mesure que vous progresserez. Vous allez tout d’abord coder votre application pour ouvrir Chromium et charger un site web spécial conçu comme un bac à sable de moissonnage : books.toscrape.com. Les deux prochaines étapes consisteront à extraire tous les livres sur une seule page (books.toscrape), puis tous les livres qui se trouvent sur plusieurs pages. Au cours des étapes restantes, vous allez filtrer votre moissonnage par catégorie de livres. Vous enregistrerez vos données en tant que fichier JSON.
Avertissement : le moissonnage est éthiquement et légalement très complexe et en constante évolution. À ce titre, il est également très différent en fonction de votre région, de l’emplacement des données et du site web en question. Ce tutoriel moissonne un site web spécifique, books.toscrape.com, qui a été spécialement conçu pour tester des applications de moissonage. Le fait de remplacer ce domaine par un autre domaine ne relève pas de la portée de ce tutoriel.
Conditions préalables
- Node.js installé sur votre machine de développement. Ce tutoriel a été testé sur Node.js version 12.18.3 et npm version 6.14.6. Vous pouvez suivre ce guide pour installer Node.js sur macOS ou Ubuntu 18.04, ou bien suivre ce guide pour installer Node.js sur Ubuntu 18.04 en utilisant un PPA.
Étape 1 — Configuration de l’application de Web Scraping
Une fois Node.js installé, vous pouvez commencer à configurer votre application de moissonnage. Tout d’abord, vous allez créer un répertoire root de projet. Ensuite vous installerez les dépendances requises. Ce tutoriel ne nécessite qu’une seule dépendance que vous installerez en utilisant le gestionnaire de paquets npm par défaut de Node.js. npm est préinstallé avec Node.js, il est donc inutile de l’installer.
Créez un dossier pour ce projet. Ensuite vous pouvez y entrer :
- mkdir book-scraper
- cd book-scraper
Vous exécuterez toutes les commandes ultérieures depuis ce répertoire.
Nous devons installer un paquet en utilisant npm ou le gestionnaire de paquets de nœuds. Tout d’abord, initialisez npm afin de créer un fichier packages.json qui permettra de gérer les dépendances et les métadonnées de votre projet.
Initialisez npm pour votre projet :
- npm init
npm présentera une série d’invites. Vous pouvez appuyer sur ENTRÉE pour chaque invite ou ajouter des descriptions personnalisées. Veillez à bien appuyer sur ENTRÉE et à laisser les valeurs par défaut lorsqu’on vous y invite pour entry point: et test command:. Sinon, vous pouvez également faire transmettre le drapeau y sur npm—npm init -y—. Cela soumettra toutes les valeurs par défaut.
Vous obtiendrez un résultat similaire à ceci :
Output{
"name": "sammy_scraper",
"version": "1.0.0",
"description": "a web scraper",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "sammy the shark",
"license": "ISC"
}
Is this OK? (yes) yes
Tapez yes et appuyez sur ENTER. npm pour enregistrer ce résultat en tant que votre fichier package.json.
Maintenant, utilisez npm pour installer Puppeteer :
- npm install --save puppeteer
Cette commande installe à la fois Puppeteer et une version de Chromium validée par l’équipe de Puppeteer comme compatible avec son API.
Sur les machines Linux, il se peut que Puppeteer nécessite des dépendances supplémentaires.
Si vous utilisez Ubuntu 18.04, vérifiez la liste déroulante « Dépendances Debian » de la section « Chrome headless ne se lance pas sur UNIX » des documents de dépannage de Puppeteer. Vous pouvez utiliser la commande suivante pour trouver toutes les dépendances manquantes :
- ldd chrome | grep not
Une fois npm, Puppeteer et toute dépendance supplémentaire installés, vous devrez procéder à une dernière configuration sur votre fichier package.json avant de commencer le codage. Au cours de ce tutoriel, vous allez lancer votre application depuis la ligne de commande avec npm run start. Vous devez ajouter des informations sur ce script start dans package.json. Vous devez tout particulièrement ajouter une ligne sous la directive script liée à votre commande start.
Ouvrez le fichier dans votre éditeur de texte préféré :
- nano package.json
Trouvez la section scripts et ajoutez les configurations suivantes. N’oubliez pas de placer une virgule à la fin de la ligne de script test. Dans le cas contraire, l’analyse de votre fichier ne se fera pas correctement.
Output{
. . .
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node index.js"
},
. . .
"dependencies": {
"puppeteer": "^5.2.1"
}
}
Vous remarquerez également que, maintenant puppeteer apparaît sous dependencies près de la fin du fichier. Il ne sera pas nécessaire d’effectuer de révisions supplémentaires sur votre fichier package.json. Enregistrez vos modifications et fermez votre éditeur.
Vous êtes maintenant prêt à commencer à coder votre application de moissonnage. Au cours de l’étape suivante, vous allez configurer une instance de navigateur et tester la fonctionnalité de base de votre application de moissonnage.
Étape 2 — Configuration de l’instance de navigateur
Lorsque vous ouvrez un navigateur traditionnel, vous pouvez cliquer sur des boutons, naviguer avec votre souris, utiliser votre clavier, ouvrir des outils de développement et bien plus encore. Avec un navigateur headless comme Chromium vous pouvez faire exactement ces mêmes choses, mais par programmation, sans interface utilisateur. Au cours de cette étape, vous allez configurer l’instance de navigateur de votre application de Web Scraping. Au lancement de votre application, elle ouvrira Chromium automatiquement et se rendra sur books.toscrape.com. Ces actions initiales constitueront la base de votre programme.
Votre application de moissonnage aura besoin de quatre fichiers .js : browser.js, index,js, pageController.js, et pageScraper.js. Au cours de cette étape, vous allez créer les quatre fichiers. Ensuite, à mesure que votre programme deviendra de plus en plus sophistiqué, vous devrez les mettre continuellement à jour. Commencez par browser.js. Ce fichier contiendra le script qui démarre votre navigateur.
Depuis le répertoire root de votre projet, créez et ouvrez browser.js dans un éditeur de texte :
- nano browser.js
Tout d’abord, vous aurez besoin de Puppeteer. Vous devrez ensuite créer une fonction async appelée startBrowser(). Cette fonction lancera le navigateur et renverra une instance de celui-ci. Ajoutez le code suivant :
const puppeteer = require('puppeteer');
async function startBrowser(){
let browser;
try {
console.log("Opening the browser......");
browser = await puppeteer.launch({
headless: false,
args: ["--disable-setuid-sandbox"],
'ignoreHTTPSErrors': true
});
} catch (err) {
console.log("Could not create a browser instance => : ", err);
}
return browser;
}
module.exports = {
startBrowser
};
Puppeteer dispose d’une méthode .launch() qui lance une instance d’un navigateur. Cette méthode renvoie une Promise. Vous devez donc vous assurer que la promesse est résolue en utilisant un bloc .then ou await.
Utilisez await pour vous assurer que la promesse se résout, en enveloppant cette instance autour d’un bloc de code try-catch, puis en renvoyant une instance du navigateur.
Notez que la méthode .launch() utilise un paramètre JSON avec plusieurs valeurs :
- headless -
falsesignifie que le navigateur s’exécutera avec une Interface qui vous permet de regarder votre script s’exécuter, tandis quetruesignifie que le navigateur s’exécutera en mode headless. Notez bien que, si vous souhaitez déployer votre application de moissonnage vers le cloud, reconfigurezheadlesssurtrue. La plupart des machines virtuelles sont headless et ne disposent pas d’une interface utilisateur. Elles peuvent donc exécuter le navigateur uniquement en mode headless. Puppeteer comprend également un modeheadfulmais il doit être uniquement utilisé pour réaliser des tests. - ignoreHTTPSErrors -
truevous permet de consulter des sites web qui ne sont pas hébergés sur un protocole HTTPS sécurisé et ignorent les erreurs liées à HTTPS.
Enregistrez et fermez le fichier.
Maintenant, créez votre deuxième fichier .js, index.js :
- nano index.js
Ici, vous aurez besoin de browser.js et de pageController.js. Ensuite, appelez la fonction startBrowser() et transmettez l’instance du navigateur créée à notre contrôleur de page, qui dirigera ses actions. Ajoutez le code suivant :
const browserObject = require('./browser');
const scraperController = require('./pageController');
//Start the browser and create a browser instance
let browserInstance = browserObject.startBrowser();
// Pass the browser instance to the scraper controller
scraperController(browserInstance)
Enregistrez et fermez le fichier.
Créez votre troisième fichier .js, pageController.js :
- nano pageController.js
pageController.js contrôle votre processus de moissonnage. Il utilise l’instance du navigateur pour contrôler le fichier pageScraper.js sur lequel tous les scripts de moissonnage s’exécutent. Vous l’utiliserez éventuellement pour spécifier la catégorie de livres que vous souhaitez moissonner. Cependant, pour le moment, votre objectif est de pouvoir seulement ouvrir Chromium et naviguer vers une page web :
const pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
await pageScraper.scraper(browser);
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Ce code exporte une fonction qui prend l’instance de navigateur et la transmet à une fonction appelée scrapeAll(). À son tour, cette fonction transmet cette instance à pageScraper.scraper() en tant qu’argument qui l’utilise pour moissonner des pages.
Enregistrez et fermez le fichier.
Enfin, créez votre dernier fichier .js, pageScraper.js :
- nano pageScraper.js
Ici, vous allez créer un objet littéral avec une propriété url et une méthode scraper(). L’url est l’URL web de la page web que vous souhaitez moissonner. De son côté, la méthode scraper() contient le code qui exécutera votre moissonnage, même si à ce stade, elle se contente de se rendre sur une URL. Ajoutez le code suivant :
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
await page.goto(this.url);
}
}
module.exports = scraperObject;
Puppeteer dispose d’une méthode newPage() qui crée une nouvelle instance de page dans le navigateur. Ces instances de page peuvent faire plusieurs choses. Avec notre méthode scraper(), vous avez créé une instance de page puis utilisé la méthode page.goto() pour naviguer vers la page d’accueil de books.toscrape.com.
Enregistrez et fermez le fichier.
Maintenant, la structure des fichiers de votre programme est achevée. Le premier niveau de l’arborescence de répertoire de votre projet ressemblera à ceci :
Output.
├── browser.js
├── index.js
├── node_modules
├── package-lock.json
├── package.json
├── pageController.js
└── pageScraper.js
Maintenant, exécutez la commande npm run start et regardez votre application de moissonnage s’exécuter :
- npm run start
Elle ouvrira automatiquement une instance de navigateur Chromium, ouvrira une nouvelle page dans le navigateur et naviguera vers books.toscrape.com.
Au cours de cette étape, vous avez créé une application Puppeteer qui a ouvert Chromium et chargé la page d’accueil d’une librairie en ligne factice—books.toscrape.com. Au cours de l’étape suivante, vous allez moissonner les données de chaque livre qui se trouve sur cette page d’accueil.
Étape 3 — Scraping des données à partir d’une seule page
Avant d’ajouter plus de fonctionnalités à votre application de moissonnage, ouvrez votre navigateur web préféré et naviguez manuellement à la page d’accueil de books to scrape. Parcourez le site et faites-vous une idée sur la manière dont les données sont structurées.
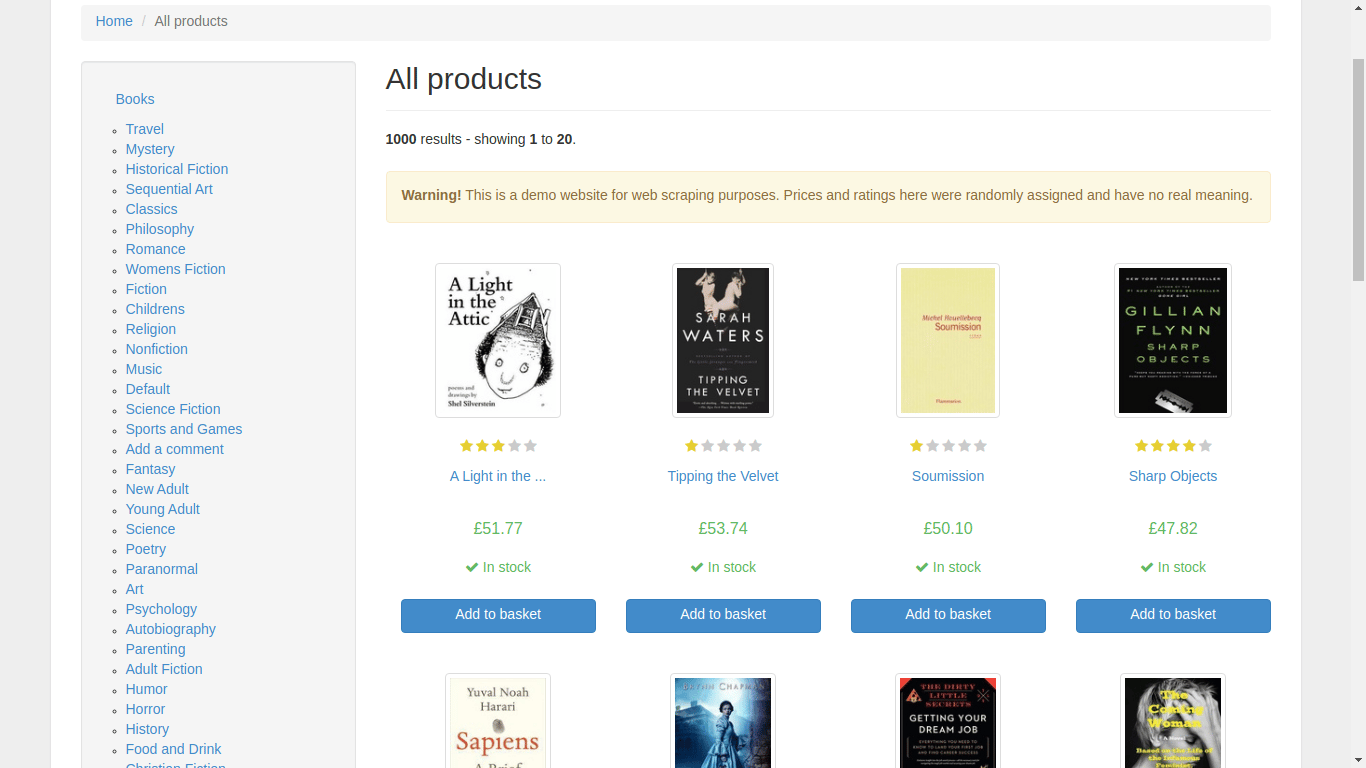
Vous trouverez une section de catégories à gauche et les livres affichés à droite. Lorsque vous cliquez sur un livre, le navigateur se dirige vers une nouvelle URL qui affiche les informations concernant ce livre spécifique.
Au cours de cette étape, vous allez reproduire ce comportement, mais avec un code. Vous automatiserez l’activité de navigation sur le site web et la consommation de ses données.
Tout d’abord, si vous inspectez le code source de la page d’accueil en utilisant les outils de développement de votre navigateur, vous remarquerez que la page répertorie les données de chaque livre sous une balise section. À l’intérieur de la balise section, chaque livre se trouve sous une balise list (li). Vous trouverez ici le lien vers la page dédiée du livre, le prix et le stock disponible.
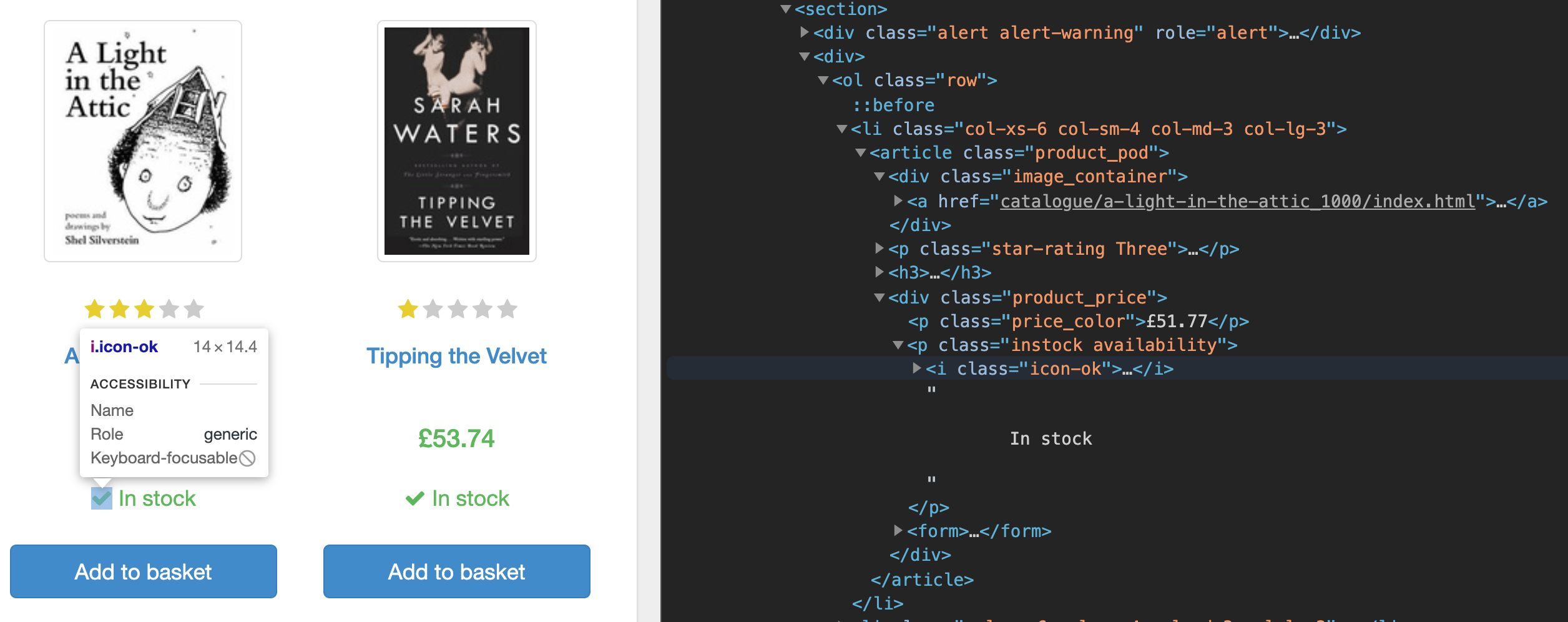
Vous effectuerez le scraping de ces URL de livres, appliquerez un filtre pour voir les livres en stock, naviguerez vers chaque page du livre et en réalisant le scraping de ses données.
Rouvrez votre fichier pageScraper.js:
- nano pageScraper.js
Ajoutez le contenu en surbrillance suivant. Vous imbriquerez un autre bloc await à l’intérieur de await page.goto(this.url); :
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Wait for the required DOM to be rendered
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
console.log(urls);
}
}
module.exports = scraperObject;
Dans ce bloc de code, vous avez appelé la méthode page.waitForSelector(). Cette méthode a attendu que le div qui contient toutes les informations liées à des livres soit rendu dans le DOM. Ensuite, vous avez appelé la méthode page.$$eval(). Cette méthode obtient l’élément URL avec le sélecteur section ol li (veillez à toujours renvoyer une chaîne ou un nombre à partir des méthodes page.$eval() et page.$$eval()).
Chaque livre peut avoir deux statuts, il est soit En stock ou En rupture de stock. Vous allez extraire les livres qui sont En Stock. Étant donné que page.$$eval() renvoie un tableau de tous les éléments correspondants, filtrez ce tableau pour avoir la certitude de bien travailler qu’avec des livres en stock. Pour cela, recherchez et évaluez la catégorie .instock.availability. Ensuite, mappez la propriété href des liens du livre et renvoyez-la à partir de la méthode.
Enregistrez et fermez le fichier.
Ré-exécutez votre application :
- npm run start
Le navigateur s’ouvrira, ira sur la page web, puis se fermera une fois la tâche achevée. Maintenant, vérifiez votre console. Elle contiendra toutes les URL moissonnées :
Output> book-scraper@1.0.0 start /Users/sammy/book-scraper
> node index.js
Opening the browser......
Navigating to http://books.toscrape.com...
[
'http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html',
'http://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html',
'http://books.toscrape.com/catalogue/soumission_998/index.html',
'http://books.toscrape.com/catalogue/sharp-objects_997/index.html',
'http://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html',
'http://books.toscrape.com/catalogue/the-requiem-red_995/index.html',
'http://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html',
'http://books.toscrape.com/catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html',
'http://books.toscrape.com/catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html',
'http://books.toscrape.com/catalogue/the-black-maria_991/index.html',
'http://books.toscrape.com/catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html',
'http://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html',
'http://books.toscrape.com/catalogue/set-me-free_988/index.html',
'http://books.toscrape.com/catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html',
'http://books.toscrape.com/catalogue/rip-it-up-and-start-again_986/index.html',
'http://books.toscrape.com/catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html',
'http://books.toscrape.com/catalogue/olio_984/index.html',
'http://books.toscrape.com/catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html',
'http://books.toscrape.com/catalogue/libertarianism-for-beginners_982/index.html',
'http://books.toscrape.com/catalogue/its-only-the-himalayas_981/index.html'
]
C’est un excellent début, mais en réalité, vous souhaitez extraire toutes les données pertinentes d’un livre spécifique, pas seulement son URL. Maintenant, utilisez ces URL pour ouvrir chaque page et moissonner le titre, l’auteur, le prix, la disponibilité, l’UPC, la description et l’URL d’image.
Rouvrez pageScraper.js:
- nano pageScraper.js
Ajoutez le code suivant. Il parcourra chaque lien moissonné, ouvrira une nouvelle instance de page, puis récupéra les données pertinentes :
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Wait for the required DOM to be rendered
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
// scrapedData.push(currentPageData);
console.log(currentPageData);
}
}
}
module.exports = scraperObject;
Vous obtenez un tableau contenant toutes les URL. Parcourez ce tableau, ouvrez l’URL dans une nouvelle page, moissonnez les données de cette page, fermez-la et ouvrez une nouvelle page pour la prochaine URL du tableau. Notez que vous avez enveloppé ce code dans une promesse, car vous souhaitez avoir la possibilité d’attendre que chaque action de votre boucle s’achève. Par conséquent, chaque promesse ouvre une nouvelle URL et ne se résoudra pas tant que le programme n’aura pas moissonné toutes les données de l’URL. Ensuite, l’instance de la page se ferme.
Avertissement : notez que vous avez attendu que la promesse s’exécute en utilisant une boucle for-in. Toute autre boucle sera suffisante. Évitez cependant d’itérer vos tableaux d’URL en utilisant une méthode d’itération de tableau comme forEach ou toute autre méthode qui utilise une fonction de rappel. En effet, la fonction de rappel devra tout d’abord passer par une file d’attente de rappels ainsi qu’une boucle d’événements, ce qui générera l’ouverture simultanée de plusieurs instances de page. Votre mémoire sera alors soumise à une plus forte contrainte.
Regardez votre fonction pagePromise de plus près. Tout d’abord, votre application de moissonage a créé une nouvelle page pour chaque URL. Ensuite, vous avez utilisé la fonction page.$eval() pour cibler les sélecteurs des détails pertinents que vous avez voulu moissonner sur la nouvelle page. Certains textes contiennent des espaces, des onglets, de nouvelles lignes et d’autres caractères non alphanumériques que vous avez éliminés en utilisant une expression régulière. Ensuite, vous avez annexé la valeur de chaque partie de données moissonnée dans cette page à un objet et résolu l’objet en question.
Enregistrez et fermez le fichier.
Exécutez le script à nouveau :
- npm run start
Le navigateur ouvre la page d’accueil puis chaque page du livre. Il enregistre ensuite les données moissonnées de chacune de ces pages. Le résultat suivant s’affichera sur votre console :
OutputOpening the browser......
Navigating to http://books.toscrape.com...
{
bookTitle: 'A Light in the Attic',
bookPrice: '£51.77',
noAvailable: '22',
imageUrl: 'http://books.toscrape.com/media/cache/fe/72/fe72f0532301ec28892ae79a629a293c.jpg',
bookDescription: "It's hard to imagine a world without A Light in the Attic. [...]',
upc: 'a897fe39b1053632'
}
{
bookTitle: 'Tipping the Velvet',
bookPrice: '£53.74',
noAvailable: '20',
imageUrl: 'http://books.toscrape.com/media/cache/08/e9/08e94f3731d7d6b760dfbfbc02ca5c62.jpg',
bookDescription: `"Erotic and absorbing...Written with starling power."--"The New York Times Book Review " Nan King, an oyster girl, is captivated by the music hall phenomenon Kitty Butler [...]`,
upc: '90fa61229261140a'
}
{
bookTitle: 'Soumission',
bookPrice: '£50.10',
noAvailable: '20',
imageUrl: 'http://books.toscrape.com/media/cache/ee/cf/eecfe998905e455df12064dba399c075.jpg',
bookDescription: 'Dans une France assez proche de la nôtre, [...]',
upc: '6957f44c3847a760'
}
...
Au cours de cette étape, vous avez moissonné les données pertinentes pour chaque livre qui se trouve sur la page d’accueil de books.toscrape.com, mais vous pouvez ajouter beaucoup plus de fonctionnalités. Si, par exemple, chacune des pages des livres est paginée, comment pouvez-vous obtenir des livres depuis ces autres pages ? En outre, sur le côté gauche du site web, vous avez trouvé les catégories de livres. Que faire si vous ne voulez pas de tous les livres, mais seulement ceux d’un genre particulier ? Vous allez maintenant ajouter ces fonctionnalités.
Étape 4 — Moissonnage de données à partir de plusieurs pages
Sur les pages paginées de books.toscrape.com, un bouton next apparaît sous leur contenu, tandis que les pages qui ne sont pas paginées n’en ont pas.
La présence de ce bouton vous permettra de déterminer si la page est paginée ou non. Étant donné que les données de chaque page ont la même structure et le même marquage, vous n’aurez pas à écrire une application de Scraping pour chaque page. Au contraire, vous pourrez utiliser la pratique récurrente.
Tout d’abord, vous devez quelque peu modifier la structure de votre code pour pouvoir naviguer sur plusieurs pages de manière récurrente.
Rouvrez pagescraper.js :
- nano pagescraper.js
Ajoutez une nouvelle fonction appelée scrapeCurrentPage() à votre méthode scraper(). Cette fonction contiendra l’intégralité du code qui moissonne les données à partir d’une page donnée. Ensuite, cliquez sur le bouton suivant s’il est présent. Ajoutez le code en surbrillance suivant :
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
let scrapedData = [];
// Wait for the required DOM to be rendered
async function scrapeCurrentPage(){
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
scrapedData.push(currentPageData);
// console.log(currentPageData);
}
// When all the data on this page is done, click the next button and start the scraping of the next page
// You are going to check if this button exist first, so you know if there really is a next page.
let nextButtonExist = false;
try{
const nextButton = await page.$eval('.next > a', a => a.textContent);
nextButtonExist = true;
}
catch(err){
nextButtonExist = false;
}
if(nextButtonExist){
await page.click('.next > a');
return scrapeCurrentPage(); // Call this function recursively
}
await page.close();
return scrapedData;
}
let data = await scrapeCurrentPage();
console.log(data);
return data;
}
}
module.exports = scraperObject;
Initialement, configurez la variable nextButtonExist sur false, ensuite vérifiez si le bouton existe. Si le bouton next existe, configurez nextButtonExists sur true. Vous pouvez ensuite cliquer sur le bouton next et appeler cette fonction de manière récurrente.
Si nextButtonExists est configuré sur false, il renvoie le tableau scrapedData comme d’habitude.
Enregistrez et fermez le fichier.
Exécutez à nouveau votre script :
- npm run start
Il est possible que cela vous prenne un certain temps. Après tout, votre application est en train d’effectuer le Scraping des données de plus de 800 livres. N’hésitez pas à fermer le navigateur ou à appuyer sur CTRL+C pour annuler le processus.
Vous avez maintenant maximisé les capacités de votre application de moissonnage, mais vous avez créé un nouveau problème au cours du processus. En effet, plutôt que d’avoir trop peu de données, vous en avez trop. Au cours de l’étape suivante, vous allez affiner votre application afin de filtrer votre moissonnage par catégorie de livres.
Étape 5 — Moissonnage des données par catégorie
Pour moissonner des données par catégorie, vous devez modifier à la fois votre fichier pageScraper.js et votre fichier pageController.js.
Ouvrez pageController.js dans un éditeur de texte :
nano pageController.js
Appelez l’application de moissonnage afin qu’elle moissonne uniquement les livres de voyage. Ajoutez le code suivant :
const pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
await browser.close();
console.log(scrapedData)
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Maintenant, vous êtes en train de transmettre deux paramètres dans votre méthode pageScraper.scraper(). Le deuxième paramètre correspond à la catégorie des livres que vous souhaitez moissonner, qui dans cet exemple est Travel. Mais votre fichier pageScraper.js ne reconnaît pas encore ce paramètre. Vous devez également ajuster ce fichier.
Enregistrez et fermez le fichier.
Ouvrez pageScraper.js:
- nano pageScraper.js
Ajoutez le code suivant. Il ajoutera votre paramètre de catégorie. Naviguez sur cette page de catégories, puis commencez à moissonner vos données à partir des résultats paginés :
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser, category){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Select the category of book to be displayed
let selectedCategory = await page.$$eval('.side_categories > ul > li > ul > li > a', (links, _category) => {
// Search for the element that has the matching text
links = links.map(a => a.textContent.replace(/(\r\n\t|\n|\r|\t|^\s|\s$|\B\s|\s\B)/gm, "") === _category ? a : null);
let link = links.filter(tx => tx !== null)[0];
return link.href;
}, category);
// Navigate to the selected category
await page.goto(selectedCategory);
let scrapedData = [];
// Wait for the required DOM to be rendered
async function scrapeCurrentPage(){
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
scrapedData.push(currentPageData);
// console.log(currentPageData);
}
// When all the data on this page is done, click the next button and start the scraping of the next page
// You are going to check if this button exist first, so you know if there really is a next page.
let nextButtonExist = false;
try{
const nextButton = await page.$eval('.next > a', a => a.textContent);
nextButtonExist = true;
}
catch(err){
nextButtonExist = false;
}
if(nextButtonExist){
await page.click('.next > a');
return scrapeCurrentPage(); // Call this function recursively
}
await page.close();
return scrapedData;
}
let data = await scrapeCurrentPage();
console.log(data);
return data;
}
}
module.exports = scraperObject;
Ce bloc de code utilise la catégorie que vous avez transmise pour obtenir l’URL où se trouvent les livres de la catégorie en question.
Le page.$$eval() peut prendre des arguments en transmettant l’argument en tant que troisième paramètre à la méthode $$eval(), et en le définissant comme le troisième paramètre dans le rappel de la manière suivante :
page.$$eval('selector', function(elem, args){
// .......
}, args)
C’est ce que vous avez fait dans votre code. Vous avez passé la catégorie des livres que vous avez voulu moissonner, mappé toutes les catégories pour vérifier celles qui y correspondent et êtes revenu ensuite à l’URL de cette catégorie.
Cette URL permet ensuite de naviguer vers la page qui affiche la catégorie des livres que vous souhaitez moissonner en utilisant la méthode page.goto(selectedCategory)
Enregistrez et fermez le fichier.
Exécutez votre application à nouveau. Vous remarquerez qu’elle se dirige vers la catégorie Travel, ouvre de manière récurrente les livres de cette catégorie, page par page, et journalise les résultats :
- npm run start
Au cours de cette étape, vous avez moissonné des données sur plusieurs pages, puis celles d’une catégorie particulière. Au cours de l’étape finale, vous allez modifier votre script pour moissonner des données sur plusieurs catégories et enregistrer ensuite ces données moissonnées sur un fichier JSON composé de chaines.
Étape 6 — Moissonnage des données de plusieurs catégories et sauvegarde des données en tant que JSON
Au cours de cette dernière étape, vous allez moissonner les données de votre script sur autant de catégories que vous le souhaitez, puis changer votre manière de gérer les résultats. Plutôt que d’enregistrer les résultats, vous allez les sauvegarder dans un fichier structuré appelé data.json.
Vous pouvez rapidement ajouter plus de catégories à extraire, ce qui nécessite uniquement une ligne supplémentaire par genre.
Ouvrez pageController.js :
- nano pageController.js
Ajustez votre code pour inclure des catégories supplémentaires. L’exemple ci-dessous vous permet d’ajouter HistoricalFiction et Mystery à notre catégorie Travel existante :
const pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
scrapedData['HistoricalFiction'] = await pageScraper.scraper(browser, 'Historical Fiction');
scrapedData['Mystery'] = await pageScraper.scraper(browser, 'Mystery');
await browser.close();
console.log(scrapedData)
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Enregistrez et fermez le fichier.
Exécutez le script à nouveau et regardez les données de ces trois catégories être moissonnées :
- npm run start
Lorsque votre application de moissonnage est entièrement fonctionnelle, la dernière étape consiste à sauvegarder vos données sous un format plus pratique. Vous allez maintenant les stocker dans un fichier JSON en utilisant le module fs dans Node.js.
Tout d’abord, rouvrez pageController.js :
- nano pageController.js
Ajoutez le code en surbrillance suivant :
const pageScraper = require('./pageScraper');
const fs = require('fs');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
scrapedData['HistoricalFiction'] = await pageScraper.scraper(browser, 'Historical Fiction');
scrapedData['Mystery'] = await pageScraper.scraper(browser, 'Mystery');
await browser.close();
fs.writeFile("data.json", JSON.stringify(scrapedData), 'utf8', function(err) {
if(err) {
return console.log(err);
}
console.log("The data has been scraped and saved successfully! View it at './data.json'");
});
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Tout d’abord, vous avez besoin du module fs de Node,js dans pageController.js. Vous pouvez ainsi enregistrer vos données en tant que fichier JSON. Ensuite, ajoutez un code de sorte que, une fois le Scraping achevé et le navigateur fermé, le programme créera un nouveau fichier appelé data.json. Notez que le contenu de data.json est stringified JSON. Par conséquent, lors de la lecture du contenu de data.json, analysez-le toujours en tant que JSON avant de réutiliser les données.
Enregistrez et fermez le fichier.
Vous avez maintenant développé une application de moissonnage qui moissonne les livres de plusieurs catégories et stocke ensuite les données que vous avez moissonnées dans un fichier JSON. Lorsque votre application devient plus complexe, vous pouvez stocker ces données moissonnées dans une base de données ou les utiliser avec une une API. Vous êtes ensuite libre d’utiliser ces données de la manière dont vous le souhaitez.
Conclusion
Vous avez développé un collecteur qui moissonne des données sur plusieurs pages de manière récurrente, puis les enregistre dans un fichier JSON. En résumé, vous avez appris à utiliser une nouvelle méthode d’automatiser la collecte des données à partir de sites web.
Puppeteer dispose d’un grand nombre de fonctionnalités qui ne se trouvent pas dans ce tutoriel. Pour en savoir plus, consultez Utiliser Puppeteer pour un meilleur contrôle de Headless Chrome. Vous pouvez également consulter la documentation officielle de Puppeteer.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
Gbadebo is a software engineer that is extremely passionate about JavaScript technologies, Open Source Development and community advocacy.
Supporting the open-source community one tutorial at a time. Former Technical Editor at DigitalOcean. Expertise in topics including Ubuntu 22.04, Ubuntu 20.04, CentOS, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
