By Gbadebo Bello and Matt Abrams

Автор выбрал фонд Free and Open Source Fund для получения пожертвования в рамках программы Write for DOnations.
Введение
Веб-скрейпинг — это процесс автоматизации сбора данных из сети. В ходе данного процесса обычно используется «поисковый робот», который выполняет автоматический серфинг по сети и собирает данные с выбранных страниц. Существует много причин, по которым вам может потребоваться скрейпинг. Его главное достоинство состоит в том, что он позволяет выполнять сбор данных значительно быстрее, устраняя необходимость в ручном сборе данных. Скрейпинг также является отличным решением, когда собрать данные желательно или необходимо, но веб-сайт не предоставляет API для выполнения этой задачи.
В этом руководстве вы создадите приложение для веб-скрейпинга с помощью Node.js и Puppeteer. Ваше приложение будет усложняться по мере вашего прогресса. Сначала вы запрограммируете ваше приложение на открытие Chromium и загрузку специального сайта, который вы будете использовать для практики веб-скрейпинга: books.toscrape.com. В следующих двух шагах вы выполните скрейпинг сначала всех книг на отдельной странице books.toscrape, а затем всех книг на нескольких страницах. В ходе остальных шагов вы сможете отфильтровать результаты по категориям книг, а затем сохраните ваши данные в виде файла JSON.
Предупреждение: этичность и законность веб-скрейпинга являются очень сложной темой, которая постоянно подвергается изменениям. Ситуация зависит от вашего местонахождения, расположения данных и рассматриваемого веб-сайта. В этом руководстве мы будем выполнять скрейпинг специального сайта books.toscrape.com, который предназначен непосредственно для тестирования приложений для скрейпинга. Скрейпинг любого другого домена выходит за рамки темы данного руководства.
Предварительные требования
- Node.js, установленный на вашем компьютере для разработки. Данное руководство было протестировано с Node.js версии 12.18.3 и npm версии 6.14.6. Вы можете воспользоваться этим руководством для установки Node.js на macOS или Ubuntu 18.04, либо воспользоваться руководством по установке Node.js в Ubuntu 18.04 с помощью PPA.
Шаг 1 — Настройка веб-скрейпера
После установки Node.js вы можете начать настройку вашего веб-скрейпера. Сначала вам нужно будет создать корневой каталог проекта, а затем установить необходимые зависимости. Данное руководство требует только одной зависимости, и вы установите эту зависимость с помощью npm, стандартного диспетчера пакетов Node.js. npm предоставляется вместе с Node.js, поэтому вам не придется устанавливать его отдельно.
Создайте папку для данного проекта, а затем перейдите в эту папку:
- mkdir book-scraper
- cd book-scraper
Вы будете запускать все последующие команды из этого каталога.
Нам нужно установить один пакет с помощью npm (node package manager). Сначала инициализируйте npm для создания файла packages.json, который будет управлять зависимостями вашего проекта и метаданными.
Инициализация npm для вашего проекта:
- npm init
npm отобразит последовательность запросов. Вы можете нажать ENTER в ответ на каждый запрос или добавить персонализированные описания. Нажмите ENTER и оставьте значения по умолчанию при запросе значений для точки входа: и тестовой команды:. В качестве альтернативы вы можете передать флаг y для npm— npm init -y— в результате чего npm добавит все значения по умолчанию.
Полученный вами вывод будет выглядеть примерно следующим образом:
Output{
"name": "sammy_scraper",
"version": "1.0.0",
"description": "a web scraper",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "sammy the shark",
"license": "ISC"
}
Is this OK? (yes) yes
Введите yes и нажмите ENTER. После этого npm сохранит этот результат в виде вашего файла package.json.
Теперь вы можете воспользоваться npm для установки Puppeteer:
- npm install --save puppeteer
Эта команда устанавливает Puppeteer и версию Chromium, которая, как известно команде Puppeteer, будет корректно работать с их API.
На компьютерах с Linux для работы Puppeteer может потребоваться установка дополнительных зависимостей.
Если вы используете Ubuntu 18.04, ознакомьтесь с данными в выпадающем списке «Зависимости Debian» в разделе «Chrome Headless не запускается в UNIX» документации Puppeteer по устранению ошибок. Вы можете воспользоваться следующей командой для поиска любых недостающих зависимостей:
- ldd chrome | grep not
После установки npm, Puppeteer и любых дополнительных зависимостей ваш файл package.json потребует одной последней настройки, прежде чем вы сможете начать писать код. В этом руководстве вы будете запускать ваше приложение из командной строки с помощью команды npm run start. Вы должны добавить определенную информацию об этом скрипте start в package.json. В частности, вы должны добавить одну строку под директивой scripts для вашей команды start.
Откройте в файл в предпочитаемом вами текстовом редакторе:
- nano package.json
Найдите раздел scripts: и добавьте следующие конфигурации. Не забудьте поместить запятую в конце строки test скрипта, иначе ваш файл не будет интерпретироваться корректно.
Output{
. . .
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node index.js"
},
. . .
"dependencies": {
"puppeteer": "^5.2.1"
}
}
Также вы можете заметить, что puppeteer сейчас появляется под разделом dependencies в конце файла. Ваш файл package.json больше не потребует изменений. Сохраните изменения и закройте редактор.
Теперь вы можете перейти к программированию вашего скрейпера. В следующем шаге вы настроите экземпляр браузера и протестируете базовый функционал вашего скрейпера.
Шаг 2 — Настройка экземпляра браузера
Когда вы открываете традиционный браузер, то можете выполнять такие действия, как нажатие кнопок, навигация с помощью мыши, печать, открытие инструментов разработчик и многое другое. Браузер без графического интерфейса, например, Chromium, позволяет вам выполнять эти же вещи, но уже программным путем без использования пользовательского интерфейса. В этом шаге вы настроите экземпляр браузера для вашего скрейпера. Когда вы запустите ваше приложение, оно автоматически откроет Chromium и перейдет на сайт books.toscrape.com. Эти первоначальные действия будут служить основой вашей программы.
Вашему веб-скрейперу потребуется четыре файла .js: browser.js, index.js, pageController.js и pageScraper.js. В этом шаге вы создадите все четыре файла, а затем постепенно будете обновлять их по мере того, как ваша программа будет усложняться. Начнем с browser.js; этот файл будет содержать скрипт, который запускает ваш браузер.
В корневом каталоге вашего проекта создайте и откройте файл browser.js в текстовом редакторе:
- nano browser.js
Во-первых, необходимо подключить Puppeteer с помощью require, а затем создать асинхронную функцию с именем startBrowser(). Эта функция будет запускать браузер и возвращать его экземпляр. Добавьте следующий код:
const puppeteer = require('puppeteer');
async function startBrowser(){
let browser;
try {
console.log("Opening the browser......");
browser = await puppeteer.launch({
headless: false,
args: ["--disable-setuid-sandbox"],
'ignoreHTTPSErrors': true
});
} catch (err) {
console.log("Could not create a browser instance => : ", err);
}
return browser;
}
module.exports = {
startBrowser
};
Puppeteer имеет метод launch(), который запускает экземпляр браузера. Этот метод возвращает промис, поэтому вам нужно гарантировать, что промис исполняется, воспользовавшись для этого блоком .then или await.
Вы будете использовать await для гарантии исполнения промиса, обернув этот экземпляр в блок try-catch, а затем вернув экземпляр браузера.
Обратите внимание, что метод .launch() принимает в качестве параметра JSON с несколькими значениями:
- headless -
falseозначает, что браузер будет запускаться с интерфейсом, чтобы вы могли наблюдать за выполнением вашего скрипта, а значениеtrueдля данного параметра означает, что браузер будет запускаться в режиме без графического интерфейс. Обратите внимание, что, если вы хотите развернуть ваш скрейпер в облаке, задайте значениеtrueдля параметраheadless. Большинство виртуальных машин не имеют пользовательского интерфейса, поэтому они могут запускать браузер только в режиме без графического интерфейса. Puppeteer также включает режимheadful, но его следует использовать исключительно для тестирования. - ignoreHTTPSerrors -
trueпозволяет вам посещать веб-сайты, доступ к которым осуществляется не через защищенный протокол HTTPS, и игнорировать любые ошибки HTTPS.
Сохраните и закройте файл.
Теперь создайте ваш второй файл .js – index.js:
- nano index.js
Здесь вы подключаете файлы browser.js и pageController.js с помощью require. Затем вы вызовете функцию startBrowser() и передадите созданный экземпляр браузера в контроллер страницы, который будет управлять ее действиями. Добавьте следующий код:
const browserObject = require('./browser');
const scraperController = require('./pageController');
//Start the browser and create a browser instance
let browserInstance = browserObject.startBrowser();
// Pass the browser instance to the scraper controller
scraperController(browserInstance)
Сохраните и закройте файл.
Создайте ваш третий файл .js – pageController.js:
- nano pageController.js
pageController.js контролирует процесс скрейпинга. Он использует экземпляр браузера для управления файлом pageScraper.js, где выполняются все скрипты скрейпинга. В конечном итоге вы будете использовать его для указания категории, скрейпинг которой вы хотите выполнить. Однако сейчас вам нужно только убедиться, что вы можете открыть Chromium и перейти на веб-страницу:
const pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
await pageScraper.scraper(browser);
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Этот код экспортирует функцию, которая принимает экземпляр браузера и передает его в функцию scrapeAll(). Эта функция, в свою очередь, передает этот экземпляр в pageScraper.scraper() в качестве аргумента, который использует его при скрейпинге страниц.
Сохраните и закройте файл.
В заключение создайте ваш последний файл .js – pageScraper.js:
- nano pageScraper.js
Здесь вы создаете литерал со свойством url и методом scraper(). url — это URL-адрес веб-страницы, скрейпинг которой вы хотите выполнить, а метод scraper() содержит код, который будет непосредственно выполнять скрейпинг, хотя на этом этапе он будет просто переходить по указанному URL-адресу. Добавьте следующий код:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
await page.goto(this.url);
}
}
module.exports = scraperObject;
Puppeteer имеет метод newPage(), который создает новый экземпляр страницы в браузере, а эти экземпляры страниц могут выполнять несколько действий. В методе scraper() вы создали экземпляр страницы, а затем использовали метод page.goto() для перехода на домашнюю страницу books.toscrape.com.
Сохраните и закройте файл.
Теперь файловая структура вашей программы готова. Первый уровень дерева каталогов вашего проекта будет выглядеть следующим образом:
Output.
├── browser.js
├── index.js
├── node_modules
├── package-lock.json
├── package.json
├── pageController.js
└── pageScraper.js
Теперь запустите команду npm run start и следите за выполнением вашего приложения для скрейпинга:
- npm run start
Приложение автоматически загрузит экземпляр браузера Chromium, откроет новую страницу в браузере и перейдет на адрес books.toscrape.com.
В этом шаге вы создали приложение Puppeteer, которое открывает Chromium и загружает домашнюю страницу шаблона книжного онлайн-магазина—books.toscrape.com. В следующем шаге вы будете выполнять скрейпинг данных для каждой книги на этой домашней странице.
Шаг 3 — Скрейпинг данных с одной страницы
Перед добавлением дополнительных функций в ваше приложение для скрейпинга, откройте предпочитаемый веб-браузер и вручную перейдите на домашнюю страницу с книгами для скрейпинга. Просмотрите сайт и получите представление о структуре данных.
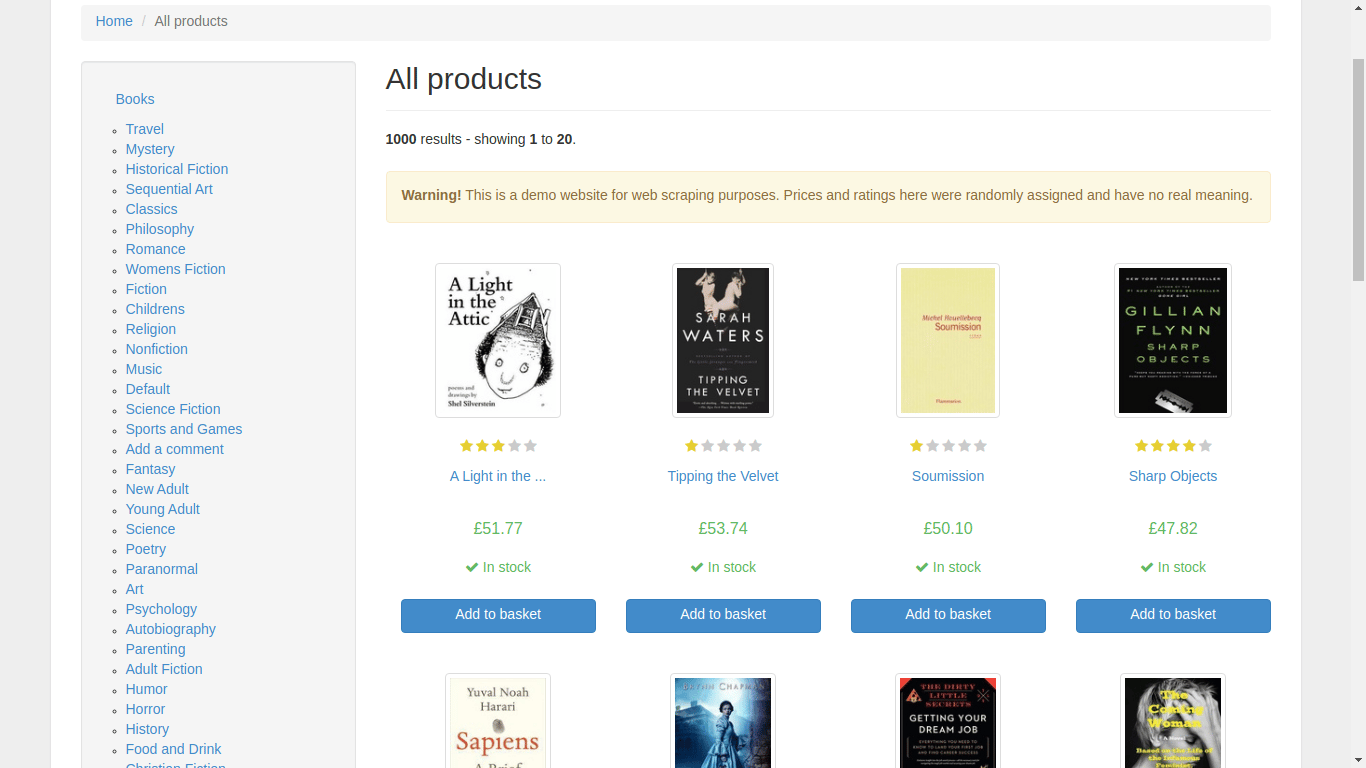
Слева вы найдете раздел категорий, а справа располагаются книги. При нажатии на книгу браузер переходит по новому URL-адресу, который отображает соответствующую информацию об этой конкретной книге.
В этом шаге вы будете воспроизводить данное поведение, но уже с помощью кода, т.е. вы автоматизируете процесс навигации по веб-сайту и получения данных.
Во-первых, если вы просмотрите исходный код домашней страницы с помощью инструментов разработчика в браузере, то сможете заметить, что страница содержит данные каждой книги внутри тега section. Внутри тега section каждая книга находится внутри тега list (li), и именно здесь вы найдете ссылку на отдельную страницу книги, цену и информацию о наличии.
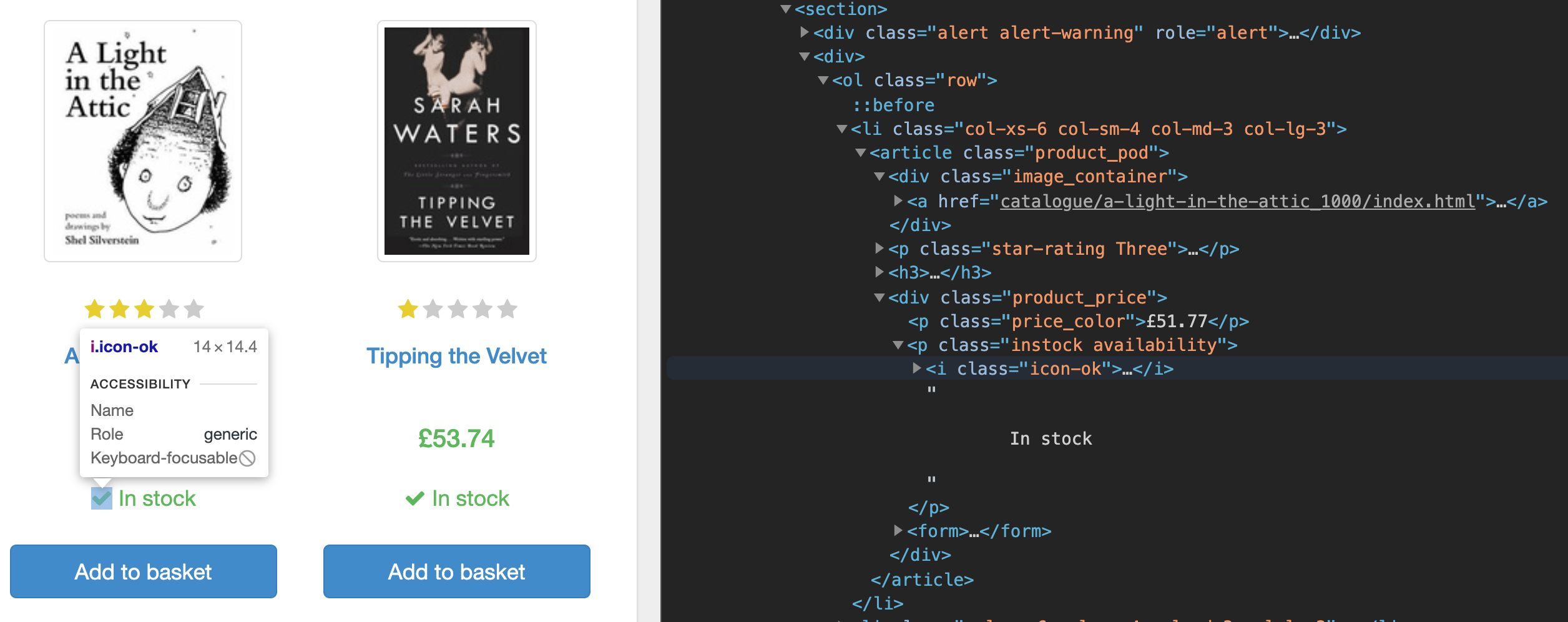
Вы будете выполнять скрейпинг URL-адресов книг, фильтровать книги, имеющиеся в наличии, переходить на отдельную страницу каждой книги и потом выполнять уже скрейпинг данных этой книги.
Повторно откройте ваш файл pageScraper.js:
- nano pageScraper.js
Добавьте следующие выделенные строки. Вы поместите еще один блок await внутри блока await page.goto(this.url);:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Wait for the required DOM to be rendered
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
console.log(urls);
}
}
module.exports = scraperObject;
Внутри этого блока кода вы вызываете метод page.waitForSelector(). Он ожидает, когда блок, содержащий всю информацию о книге, будет преобразован в DOM, после чего вы вызываете метод page.$$eval(). Этот метод получает элемент URL-адреса с селектором section ol li (убедитесь, что методы page.$eval() и page.$$eval() возвращают только строку или число).
Каждая книга имеет два статуса: In Stock (В наличии) или Out of stock (Распродано). Вам нужно выполнить скрейпинг книг со статусом In Stock. Поскольку page.$$eval() возвращает массив всех подходящих элементов, вы выполнили фильтрацию этого массива, чтобы гарантировать работу исключительно с книгами в наличии. Эта задача выполняется путем поиска и оценки класса .instock.availability. Затем вы вычленили свойство href в ссылках книг и вернули его с помощью метода.
Сохраните и закройте файл.
Повторно запустите ваше приложение:
- npm run start
Приложение откроет браузер, перейдет на веб-страницу, а затем закроет его, когда задача будет выполнена. Теперь проверьте вашу консоль; она будет содержать все полученные URL-адреса:
Output> book-scraper@1.0.0 start /Users/sammy/book-scraper
> node index.js
Opening the browser......
Navigating to http://books.toscrape.com...
[
'http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html',
'http://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html',
'http://books.toscrape.com/catalogue/soumission_998/index.html',
'http://books.toscrape.com/catalogue/sharp-objects_997/index.html',
'http://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html',
'http://books.toscrape.com/catalogue/the-requiem-red_995/index.html',
'http://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html',
'http://books.toscrape.com/catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html',
'http://books.toscrape.com/catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html',
'http://books.toscrape.com/catalogue/the-black-maria_991/index.html',
'http://books.toscrape.com/catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html',
'http://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html',
'http://books.toscrape.com/catalogue/set-me-free_988/index.html',
'http://books.toscrape.com/catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html',
'http://books.toscrape.com/catalogue/rip-it-up-and-start-again_986/index.html',
'http://books.toscrape.com/catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html',
'http://books.toscrape.com/catalogue/olio_984/index.html',
'http://books.toscrape.com/catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html',
'http://books.toscrape.com/catalogue/libertarianism-for-beginners_982/index.html',
'http://books.toscrape.com/catalogue/its-only-the-himalayas_981/index.html'
]
Это отличное начало, но вам нужно выполнить скрейпинг всех подходящих данных для конкретной книги, а не только ее URL-адреса. Теперь вы будете использовать эти URL-адреса для открытия каждой страницы и скрейпинга названия, автора, цены, наличия, универсального товарного кода, описания и URL-адреса изображения.
Повторно откройте pageScraper.js:
- nano pageScraper.js
Добавьте следующий код, который будет проходить по каждой полученной ссылке, открывать новый экземпляр страницы, а затем получать подходящие данные:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Wait for the required DOM to be rendered
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
// scrapedData.push(currentPageData);
console.log(currentPageData);
}
}
}
module.exports = scraperObject;
Вы получили массив всех URL-адресов. Вам нужно пробежаться по этому массиву, открыть URL-адрес в новой странице, выполнить скрейпинг данных на этой странице, закрыть эту страницу и открыть новую страницу для следующего URL-адреса в массиве. Обратите внимание, что вы обернули этот код в промис. Это связано с тем, что вам нужно иметь возможность ожидать завершения выполнения каждого действия в вашем цикле. Поэтому каждый промис открывает новый URL-адрес и не будет выполнен, пока программа не выполнит скрейпинг всех данных для этого URL-адреса, и только после этого данный экземпляр страницы закроется.
Предупреждение: обратите внимание, что вы реализовали ожидание выполнения промиса с помощью цикла for-in. Вы можете использовать любой цикл, но рекомендуется избегать итерации по вашим массивам с URL-адресами с помощью метода итерации по массивам, например, forEach, или любого другого метода, который использует функцию обратного вызова. Это связано с тем, что функция обратного вызова должна будет сначала пройти через очередь обратного вызова и цикл событий, в результате чего будет одновременно открываться несколько экземпляров страницы. Это будет накладывать заметно большую нагрузку на вашу память.
Приглядитесь внимательней к вашей функции pagePromise. Ваше приложение для скрейпинга сначала создало новую страницу для каждого URL-адреса, а затем вы использовали функцию page.$eval() для настройки селекторов на получение подходящих данных, которые вы хотите собрать с новой страницы. Некоторые тексты содержат пробелы, символы табуляции, переносы строки и прочие специальные символы, которые вы удалили с помощью регулярного выражения. Затем вы добавили значение всех элементов данных, которые были получены во время скрейпинга страницы, в объект и зарезолвили этот объект.
Сохраните и закройте файл.
Запустите скрипт еще раз:
- npm run start
Браузер открывает домашнюю страницу, затем переходит на страницу каждой книги и записывает данные скрейпинга для каждой из этих страниц. Следующий вывод будет отображен в консоли:
OutputOpening the browser......
Navigating to http://books.toscrape.com...
{
bookTitle: 'A Light in the Attic',
bookPrice: '£51.77',
noAvailable: '22',
imageUrl: 'http://books.toscrape.com/media/cache/fe/72/fe72f0532301ec28892ae79a629a293c.jpg',
bookDescription: "It's hard to imagine a world without A Light in the Attic. [...]',
upc: 'a897fe39b1053632'
}
{
bookTitle: 'Tipping the Velvet',
bookPrice: '£53.74',
noAvailable: '20',
imageUrl: 'http://books.toscrape.com/media/cache/08/e9/08e94f3731d7d6b760dfbfbc02ca5c62.jpg',
bookDescription: `"Erotic and absorbing...Written with starling power."--"The New York Times Book Review " Nan King, an oyster girl, is captivated by the music hall phenomenon Kitty Butler [...]`,
upc: '90fa61229261140a'
}
{
bookTitle: 'Soumission',
bookPrice: '£50.10',
noAvailable: '20',
imageUrl: 'http://books.toscrape.com/media/cache/ee/cf/eecfe998905e455df12064dba399c075.jpg',
bookDescription: 'Dans une France assez proche de la nôtre, [...]',
upc: '6957f44c3847a760'
}
...
В этом шаге вы выполнили скрейпинг подходящих данных для каждой книги на домашней странице books.toscrape.com, но вы можете добавить гораздо больше функций. Например, если каждая страница с книгами имеет пагинацию, как вы получите книги со следующих страниц? Также в левой части веб-сайта указаны категории книг; что, если вам не нужны все книги, а только книги конкретного жанра? Теперь вы можете добавить эти функции.
Шаг 4 — Скрейпинг данных с нескольких страниц
Страницы на сайте books.toscrape.com с пагинацией имеют кнопку Next (Далее) под основным содержанием, а на страницах без пагинации этой кнопки нет.
Вы будете использовать эту кнопку, чтобы определять, имеет ли страница пагинацию или нет. Поскольку данные на каждой странице имеют одну и ту же структуру и разметку, вам не придется писать скрейпер для каждой возможной страницы. Вместо этого вы будете использовать рекурсию.
Сначала вам нужно немного изменить структуру вашего кода, чтобы выполнять навигацию по нескольким страницам рекурсивно.
Повторно откройте pagescraper.js:
- nano pagescraper.js
Вы добавите новую функцию с именем scrapeCurrentPage() в ваш метод scraper(). Эта функция будет содержать весь код, который будет выполнять скрейпинг данных с отдельной страницы, а затем нажимать кнопку next, если она присутствует. Добавьте следующий выделенный код:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
let scrapedData = [];
// Wait for the required DOM to be rendered
async function scrapeCurrentPage(){
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
scrapedData.push(currentPageData);
// console.log(currentPageData);
}
// When all the data on this page is done, click the next button and start the scraping of the next page
// You are going to check if this button exist first, so you know if there really is a next page.
let nextButtonExist = false;
try{
const nextButton = await page.$eval('.next > a', a => a.textContent);
nextButtonExist = true;
}
catch(err){
nextButtonExist = false;
}
if(nextButtonExist){
await page.click('.next > a');
return scrapeCurrentPage(); // Call this function recursively
}
await page.close();
return scrapedData;
}
let data = await scrapeCurrentPage();
console.log(data);
return data;
}
}
module.exports = scraperObject;
Первоначально вы задаете для переменной nextButtonExist значение false, а затем проверяете, присутствует ли кнопка. Если кнопка next существует, вы задаете для nextButtonExists значение true и переходите к нажатию кнопки next, после чего вызываете эту функцию рекурсивно.
Если для nextButtonExists задано значение false, функция просто возвращает массив scrapedData.
Сохраните и закройте файл.
Запустите скрипт еще раз:
- npm run start
На завершение работы скрипта может потребоваться время; ваше приложение теперь выполняет скрейпинг данных для более чем 800 книг. Вы можете закрыть браузер, либо нажать CTRL + C для завершения процесса.
Вы успешно реализовали максимум возможностей вашего приложения для скрейпинга, но получили новую проблему в ходе этого процесса. Теперь проблема состоит не в слишком малом, а в слишком большом объеме данных. В следующем шаге вы выполните тонкую настройку приложения для фильтрации скрейпинга по категории книг.
Шаг 5 — Скрейпинг данных по категории
Чтобы выполнить скрейпинг данных по категориям, вам нужно будет изменить содержание файлов pageScraper.js и pageController.js.
Откройте pageController.js в текстовом редакторе:
nano pageController.js
Вызовите скрейпер так, чтобы он выполнял скрейпинг исключительно книг о путешествиях. Добавьте следующий код:
const pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
await browser.close();
console.log(scrapedData)
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Теперь вы передаете два параметра в метод pageScraper.scraper(), где второй параметр — категория книг, которые вы хотите получить, в данном случае это Travel. Но ваш файл pageScraper.js еще не распознает этот параметр. Вам также нужно будет изменить этот файл.
Сохраните и закройте файл.
Откройте pageScraper.js:
- nano pageScraper.js
Добавьте следующий код, который будет добавлять параметр категории, переходить на страницу этой категории, а затем выполнять скрейпинг по страницам с пагинацией:
const scraperObject = {
url: 'http://books.toscrape.com',
async scraper(browser, category){
let page = await browser.newPage();
console.log(`Navigating to ${this.url}...`);
// Navigate to the selected page
await page.goto(this.url);
// Select the category of book to be displayed
let selectedCategory = await page.$$eval('.side_categories > ul > li > ul > li > a', (links, _category) => {
// Search for the element that has the matching text
links = links.map(a => a.textContent.replace(/(\r\n\t|\n|\r|\t|^\s|\s$|\B\s|\s\B)/gm, "") === _category ? a : null);
let link = links.filter(tx => tx !== null)[0];
return link.href;
}, category);
// Navigate to the selected category
await page.goto(selectedCategory);
let scrapedData = [];
// Wait for the required DOM to be rendered
async function scrapeCurrentPage(){
await page.waitForSelector('.page_inner');
// Get the link to all the required books
let urls = await page.$$eval('section ol > li', links => {
// Make sure the book to be scraped is in stock
links = links.filter(link => link.querySelector('.instock.availability > i').textContent !== "In stock")
// Extract the links from the data
links = links.map(el => el.querySelector('h3 > a').href)
return links;
});
// Loop through each of those links, open a new page instance and get the relevant data from them
let pagePromise = (link) => new Promise(async(resolve, reject) => {
let dataObj = {};
let newPage = await browser.newPage();
await newPage.goto(link);
dataObj['bookTitle'] = await newPage.$eval('.product_main > h1', text => text.textContent);
dataObj['bookPrice'] = await newPage.$eval('.price_color', text => text.textContent);
dataObj['noAvailable'] = await newPage.$eval('.instock.availability', text => {
// Strip new line and tab spaces
text = text.textContent.replace(/(\r\n\t|\n|\r|\t)/gm, "");
// Get the number of stock available
let regexp = /^.*\((.*)\).*$/i;
let stockAvailable = regexp.exec(text)[1].split(' ')[0];
return stockAvailable;
});
dataObj['imageUrl'] = await newPage.$eval('#product_gallery img', img => img.src);
dataObj['bookDescription'] = await newPage.$eval('#product_description', div => div.nextSibling.nextSibling.textContent);
dataObj['upc'] = await newPage.$eval('.table.table-striped > tbody > tr > td', table => table.textContent);
resolve(dataObj);
await newPage.close();
});
for(link in urls){
let currentPageData = await pagePromise(urls[link]);
scrapedData.push(currentPageData);
// console.log(currentPageData);
}
// When all the data on this page is done, click the next button and start the scraping of the next page
// You are going to check if this button exist first, so you know if there really is a next page.
let nextButtonExist = false;
try{
const nextButton = await page.$eval('.next > a', a => a.textContent);
nextButtonExist = true;
}
catch(err){
nextButtonExist = false;
}
if(nextButtonExist){
await page.click('.next > a');
return scrapeCurrentPage(); // Call this function recursively
}
await page.close();
return scrapedData;
}
let data = await scrapeCurrentPage();
console.log(data);
return data;
}
}
module.exports = scraperObject;
Этот блок кода использует категорию, которую вы передали, для получения URL-адреса страницы, где находятся книги этой категории.
page.$$eval() может принимать аргументы с помощью передачи этого аргумента в качестве третьего параметра для метода $$$eval() и определения его как третьего параметра в обратном вызове следующим образом:
page.$$eval('selector', function(elem, args){
// .......
}, args)
Вот что вы сделали в вашем коде: вы передали категорию книг, для которой вы хотите выполнить скрейпинг, выполнили маппинг по всем категориям, чтобы узнать, какая категория вам подходит, а затем вернули URL-адрес этой категории.
Затем этот URL-адрес был использован для перехода на страницу, которая отображает категорию книг, для которой вы хотите выполнить скрейпинг, с помощью метода page.goto(selectedCategory).
Сохраните и закройте файл.
Запустите ваше приложение еще раз. Вы заметите, что приложение переходит к категории Travel, рекурсивно открывает книги данной категории одну за одной и записывает результаты:
- npm run start
В этом шаге вы выполнили скрейпинг данных на нескольких страницах, а затем на нескольких страницах одной конкретной категории. В заключительном шаге вы внесете изменения в ваш скрипт для скрейпинга данных из нескольких категорий и последующего сохранения этих данных в имеющем строковый вид файле JSON.
Шаг 6 — Выполнение скрейпинга данных из нескольких категорий и сохранение данных в виде файла JSON
В этом заключительном шаге вы внесете изменения в скрипт, чтобы выполнять скрейпинг для нужного вам количества категорий, а затем измените порядок вывода результата. Вместо записи результатов вы будете сохранять их в структурированном файле data.json.
Вы сможете быстро добавлять дополнительные категории для скрейпинга; для этого вам потребуется добавлять одну дополнительную строку для каждого отдельного жанра.
Откройте pageController.js:
- nano pageController.js
Измените ваш код для включения дополнительных категорий. В примере ниже к существующей категории Travel добавляются категории HistoricalFiction и Mystery:
const pageScraper = require('./pageScraper');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
scrapedData['HistoricalFiction'] = await pageScraper.scraper(browser, 'Historical Fiction');
scrapedData['Mystery'] = await pageScraper.scraper(browser, 'Mystery');
await browser.close();
console.log(scrapedData)
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
Сохраните и закройте файл.
Запустите скрипт еще раз и посмотрите, как он выполняет скрейпинг данных для всех трех категорий:
- npm run start
После получения всего необходимого функционала скрейпера в качестве заключительного шага вы добавите сохранение данных в более полезном формате. Теперь вы сможете сохранять их в файле JSON с помощью модуля fs в Node.js.
Откройте pageController.js:
- nano pageController.js
Добавьте следующий выделенный код:
const pageScraper = require('./pageScraper');
const fs = require('fs');
async function scrapeAll(browserInstance){
let browser;
try{
browser = await browserInstance;
let scrapedData = {};
// Call the scraper for different set of books to be scraped
scrapedData['Travel'] = await pageScraper.scraper(browser, 'Travel');
scrapedData['HistoricalFiction'] = await pageScraper.scraper(browser, 'Historical Fiction');
scrapedData['Mystery'] = await pageScraper.scraper(browser, 'Mystery');
await browser.close();
fs.writeFile("data.json", JSON.stringify(scrapedData), 'utf8', function(err) {
if(err) {
return console.log(err);
}
console.log("The data has been scraped and saved successfully! View it at './data.json'");
});
}
catch(err){
console.log("Could not resolve the browser instance => ", err);
}
}
module.exports = (browserInstance) => scrapeAll(browserInstance)
В первую очередь вам потребуется добавить модуль fs из Node.js в файл pageController.js. Это гарантирует, что вы сможете сохранить ваши данные в виде файла JSON. Затем вы добавляете код, чтобы после завершения скрейпинга и закрытия браузера программа создавала новый файл с именем data.json. Обратите внимание, что data.json представляет собой строковый файл JSON. Следовательно, при чтении содержания data.json всегда необходимо парсить его в качестве JSON перед повторным использованием данных.
Сохраните и закройте файл.
Вы создали приложение для веб-скрейпинга, которое выполняет скрейпинг книг из нескольких категорий, а затем сохраняет полученные данные в файле JSON. По мере усложнения вашего приложения вам может потребоваться сохранять ваши данные в базе данных или работать с ними через API. То, как будут использованы эти данные, зависит от вас.
Заключение
В этом руководстве вы создали поискового робота, который рекурсивно скрейпит данные на нескольких страницах и затем сохраняет их в файле JSON. Коротко говоря, вы узнали новый способ автоматизации сбора данных с веб-сайтов.
Puppeteer имеет множество функций, которые выходят за рамки данного руководства. Дополнительную информацию можно найти в статье Использование Puppeteer для удобного управления Chrome без графического интерфейса. Также вы можете ознакомиться с официальной документацией Puppeteer.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
Gbadebo is a software engineer that is extremely passionate about JavaScript technologies, Open Source Development and community advocacy.
Supporting the open-source community one tutorial at a time. Former Technical Editor at DigitalOcean. Expertise in topics including Ubuntu 22.04, Ubuntu 20.04, CentOS, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Thank you for great article. And coould you supplement the guide with instruction of how to send the received .json file by email(with nodemailer for example)?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
