By Hanif Jetha
 en Kubernetes")
Introducción
Cuando se ejecutan múltiples servicios y aplicaciones en un clúster de Kubernetes, una pila de registro centralizada de nivel de clúster puede servirle para clasificar y analizar rápidamente el gran volumen de datos de registro producidos por sus Pods. Una solución de registro centralizada popular es la pila de Elasticsearch, Fluentd y Kibana (EFK).
Elasticsearch es un motor de búsqueda en tiempo real, distribuido y escalable que permite una búsqueda completa de texto y estructurada, además de análisis. Se suele usar para indexaciones y búsquedas en grandes volúmenes de datos de registro, pero también se puede emplear para buscar muchos tipos diferentes de documentos.
Elasticsearch se suele implementar con Kibana, un poderoso frontend de visualización de datos y un panel de control para Elasticsearch. Kibana le permite explorar sus datos de registro de Elasticsearch a través de una interfaz web y crear paneles de control y consultas para responder rápidamente a preguntas y obtener información sobre sus aplicaciones de Kubernetes.
En este tutorial, usaremos Fluentd para recopilar, transformar y enviar datos de registro al backend de Elasticsearch. Fluentd es un recopilador de datos de código abierto popular que configuraremos en nuestros nodos de Kubernetes para seguir archivos de registro de contenedores, filtrar y transformar los datos de registro y entregarlos al clúster de Elasticsearch, donde se indexarán y almacenarán.
Comenzaremos configurando e iniciando un clúster escalable de Elasticsearch y luego crearemos el servicio y la implementación de Kubernetes de Kibana. Para finalizar, configuraremos Fluentd como DaemonSet para que se ejecute en todos los nodos de trabajo de Kubernetes.
Requisitos previos
Antes de comenzar con esta guía, asegúrese de contar con lo siguiente:
-
Un clúster de Kubernetes 1.10, o una versión posterior, con control de acceso basado en roles (RBCA) activado
- Compruebe que su clúster cuente con suficientes recursos para implementar la pila EFK y, si no es así, escale su clúster agregando nodos de trabajo. Implementaremos un clúster de 3 Pods de Elasticsearch (puede reducir el número a 1 si es necesario) y un único Pod de Kibana. En cada nodo de trabajo también se ejecutará un Pod de Fluentd. El clúster de esta guía consta de 3 nodos de trabajo y un panel de control administrado.
-
La herramienta de línea de comandos
kubectlinstalada en su máquina local, configurada para establecer conexión con su clúster. Puede obtener más información sobre la instalación dekubectlen la documentación oficial.
Cuando tenga estos componentes configurados, estará listo para comenzar con esta guía.
Paso 1: Crear un espacio de nombres
Antes de implementar un clúster de Elasticsearch, primero crearemos un espacio de nombres en el que instalaremos toda nuestra instrumentación de registro. Kubernetes le permite separar objetos que se ejecutan en su clúster usando una abstracción “clúster virtual” llamada “Namespaces” (espacios de nombres). En esta guía, crearemos un espacio de nombres kube-logging en el cual instalaremos los componentes de la pila EFK. Este espacio de nombres también nos permitirá limpiar y eliminar la pila de registros sin pérdida de funciones en el clúster de Kubernetes.
Para comenzar, primero investigue los espacios de nombres de su clúster usando kubectl:
- kubectl get namespaces
Debería ver los siguientes tres espacios de nombres iniciales, que vienen ya instalados con su clúster Kubernetes:
OutputNAME STATUS AGE
default Active 5m
kube-system Active 5m
kube-public Active 5m
El espacio de nombres default aloja los objetos que se crean sin especificar un espacio de nombres. El espacio de nombres kube-system contiene objetos creados y usados por el sistema Kubernetes, como kube-dns, kube-proxy y kubernetes-dashboard. Se recomienda guardar este espacio de nombres limpio sin contaminarlo con las cargas de trabajo de aplicaciones e instrumentos.
El espacio de nombres kube-public es otro de los que se crean automáticamente y se puede usar para almacenar objetos para los cuales desee habilitar la lectura y el acceso en todo el clúster, incluso para usuarios sin autenticar.
Para crear el espacio de nombres kube-logging, abra primero y edite un archivo llamado kube-logging.yaml usando su editor favorito. Por ejemplo, nano:
- nano kube-logging.yaml
Dentro de su editor, pegue el siguiente YAML de objeto de espacio de nombres:
kind: Namespace
apiVersion: v1
metadata:
name: kube-logging
A continuación, guarde y cierre el archivo.
Aquí especificamos el kind del objeto de Kubernetes como objeto Namespace. Para obtener más información los objetos Namespace, consulte el Tutorial de espacios de nombres en la documentación oficial de Kubernetes. También especificamos la versión API de Kubernetes utilizada para crear el objeto (v1) y le damos un name: kube-logging.
Cuando haya creado el archivo objeto de espacio de nombres kube-logging.yaml, cree el espacio de nombres usando kubectl create con el indicador de nombre de archivo -f:
- kubectl create -f kube-logging.yaml
Debería ver el siguiente resultado:
Outputnamespace/kube-logging created
A continuación, puede confirmar que el espacio de nombres se creó correctamente:
- kubectl get namespaces
En este punto, debería ver el nuevo espacio de nombres kube-logging:
OutputNAME STATUS AGE
default Active 23m
kube-logging Active 1m
kube-public Active 23m
kube-system Active 23m
Ahora podemos implementar un clúster de Elasticsearch en este espacio de nombres de registro aislado.
Paso 2: Crear el StatefulSet de Elasticsearch
Ahora que creamos un espacio de nombres para alojar nuestra pila de registro, podemos comenzar a implementar sus diferentes componentes. Primero, empezaremos implementando un clúster de Elasticsearch de 3 nodos.
En esta guía, usamos 3 Pods de Elasticsearch para evitar el problema de “cerebro dividido” que se produce en clústeres altamente disponibles y con muchos nodos. A un nivel superior, “cerebro dividido” es lo que surge cuando uno o más nodos no pueden comunicarse con los demás, y se eligen varios maestros “divididos”. Al haber 3 nodos, si uno se desconecta del clúster temporalmente, los otros dos pueden elegir un nuevo maestro y el clúster puede seguir funcionando mientras el último nodo intenta volver a unirse. Para obtener más información, consulte Una nueva era para la coordinación de clústeres en Elasticsearch y Configuraciones de voto.
Crear el servicio sin encabezado
Para comenzar, crearemos un servicio de Kubernetes sin encabezado llamado elasticsearch que definirá un dominio DNS para los 3 Pods. Un servicio sin encabezado no realiza un equilibrio de carga ni tiene un IP estático; para obtener más información sobre los servicios sin encabezado, consulte la documentación oficial de Kubernetes.
Abra un archivo llamado elasticsearch_svc.yaml usando su editor favorito:
- nano elasticsearch_svc.yaml
Péguelo en el siguiente YAML de servicio de Kubernetes:
kind: Service
apiVersion: v1
metadata:
name: elasticsearch
namespace: kube-logging
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node
A continuación, guarde y cierre el archivo.
Definimos un Service llamado elasticsearch en el espacio de nombres kube-logging y le asignamos la etiqueta app:elasticsearch. A continuación, fijamos .spec.selector en app: elasticsearch para que el servicio seleccione Pods con la etiqueta app:elasticsearch. Cuando asociemos nuestro StatefulSet de Elasticsearch con este servicio, este último mostrará registros DNS A orientados a los Pods de Elasticsearch con la etiqueta app: elasticsearch.
A continuación, configuraremos clusterIP:None que elimina el encabezado del servicio. Por último, definiremos los puertos 9200 y 9300 que se usan para interactuar con la API REST y para las comunicaciones entre nodos, respectivamente.
Cree el servicio usando kubectl:
- kubectl create -f elasticsearch_svc.yaml
Debería ver el siguiente resultado:
Outputservice/elasticsearch created
Por último, verifique bien que el servicio se haya creado correctamente usando kubectl get:
kubectl get services --namespace=kube-logging
Debería ver lo siguiente:
OutputNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 26s
Ahora que configuramos nuestro servicio sin encabezado y un dominio estable .elasticsearch.kube-logging.svc.cluster.local para nuestros Pods, podemos crear el StatefulSet.
Crear el StatefulSet
Un StatefulSet de Kubernetes le permite asignar una identidad estable a los Pods y otorgar a estos un almacenamiento estable y persistente. Elasticsearch requiere un almacenamiento estable para persistir datos en reinicios y reprogramaciones de Pods. Para obtener más información sobre el volumen de trabajo de StatefulSet, consulte la página de StatefulSet en los documentos de Kubernetes.
Abra un archivo llamado elasticsearch_statefulset.yaml usando su editor favorito:
- nano elasticsearch_statefulset.yaml
Veremos sección a sección la definición del objeto de StatefulSet y pegaremos bloques a este archivo.
Comience pegando el siguiente bloque:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
En este bloque, definimos un StatefulSet llamado es-cluster en el espacio de nombres kube-logging. A continuación, lo asociamos con nuestro servicio elasticsearch ya creado usando el campo serviceName. Esto garantiza que se pueda acceder a cada Pod de StatefulSet usando la de dirección DNS es-cluster-[1,2].elasticsearch.kube-logging.svc.cluster.local, donde [0,1,2] corresponde al ordinal de número entero asignado.
Especificamos 3 replicas (Pods) y fijamos el selector matchLabels en app: elasticseach, que luego replicamos en la sección .spec.template.metadata. Los campos .spec.selector.matchLabels y .spec.template.metadata.labels deben coincidir.
Ahora podemos pasar a la especificación del objeto. Péguelo en el siguiente bloque de YAML inmediatamente debajo del bloque anterior:
. . .
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
Aquí definimos los Pods en StatefulSet. Llamamos a los contenedores elasticsearch y elegimos la imagen de Docker docker.elastic.co/elasticsearch/elasticsearch:7.2.0. En este momento, puede modificar esta etiqueta de imagen para que se corresponda con su propia imagen interna de Elasticsearch, o a una versión distinta. Tenga en cuenta que, a los efectos de esta guía, solo se ha probado Elasticsearch 7.2.0.
A continuación, usamos el campo resources para especificar que el contenedor necesita que se garantice al menos 0,1 vCPU y puede tener ráfagas de hasta 1 vCPU (lo que limita el uso de recursos de Pods cuando se realiza una ingestión inicial grande o se experimenta un pico de carga). Debería modificar estos valores según su carga prevista y los recursos disponibles. Para obtener más información sobre solicitudes y límites de recursos, consulte la documentación oficial de Kubernetes.
A continuación, abriremos los puertos 9200 y 9300 y les asignaremos nombres para la comunicación de la API REST y entre nodos, respectivamente. Especificaremos un volumeMount llamado data que montará el PersistentVolume llamado data en el contenedor en la ruta /usr/share/elasticsearch/data. Definiremos los VolumeClaims para este StatefulSet en un bloque YAML posterior.
Por último, configuraremos algunas variables de entorno en el contenedor:
cluster.name: nombre del clúster de Elasticsearch, que en esta guía esk8s-lologs.node.name: nombre del nodo, que configuramos en el campo.metadata.nameusandovalueFrom. Esto se resolverá enes-cluster-[0,1,2]según el ordinal asignado al nodo.discovery.seed_hosts:este campo establece una lista de nodos que el maestro puede elegir en el clúster e iniciarán el proceso de descubrimiento del nodo. En esta guía, gracias al servicio sin encabezado que configuramos antes, nuestros Pods tienen dominios del tipoes-cluster-[0,2].elasticsearch.kube-logging.svc.cluster.local, por lo que configuramos esta variable como corresponde. Usando la resolución DNS de Kubernetes de espacio de nombres locales, podemos acortar esto aes-cluster-[0,1,2].elasticsearch. Para obtener más información sobre el descubrimiento de Elasticsearch, consulte la documentación oficial de Elasticsearch.cluster.initial_master_nodes: este campo también especifica una lista de nodos que el maestro puede elegir y que participarán en el proceso de elección de maestro. Tenga en cuenta que para este campo debería identificar nodos por susnode.name, no sus nombres de host.ES_JAVA_OPTS: aquí lo fijamos en-Xms512m -Xmxx512m, que indica a la JVM que utilice un tamaño de pila mínimo y máximo de 512 MB. Debería ajustar estos parámetros según la disponibilidad y las necesidades de recursos de su clúster. Para obtener más información, consulte Configurar el tamaño de la pila.
El siguiente bloque que pegaremos tiene este aspecto:
. . .
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
En este bloque, definimos varios Contenedores Init que se ejecutan antes del contenedor principal de la aplicación elasticsearch. Estos contenedores Init se ejecutan para que se completen en el orden en que se definen. Para obtener más información sobre los Contenedores Init, consulte la documentación oficial de Kubernetes.
El primero, llamado fix-permissions, ejecuta un comando chown para cambiar el propietario y el grupo del directorio de datos de Elasticsearch a 1000:1000, el UID de usuario de Elasticsearch. Por defecto, Kubernetes instala el directorio de datos como root, con lo cual Elasticsearch no puede acceder a él. Para obtener más información sobre este paso, consulte “Notas vinculadas al uso de producción y a los valores predeterminados”.
El segundo, llamado increase-vm-max-map, ejecuta un comando para aumentar los límites del sistema operativo en los recuentos de mmap, lo que por defecto puede ser demasiado bajo. Esto puede provocar errores de memoria. Para obtener más información sobre este paso, consulte la documentación oficial de Elasticsearch.
El siguiente contenedor Init que se ejecutará es increase-fd-ulimit, que ejecuta el comando ulimit para aumentar el número máximo de descriptores de archivos abiertos. Para obtener más información sobre este paso, consulte “Notas vinculadas al uso de producción y a los valores predeterminados” en la documentación oficial de Elasticsearch.
Nota: en las Notas de Elasticsearch vinculadas al uso de producción también se menciona la desactivación del intercambio por motivos de rendimiento. Según su instalación o proveedor de Kubernetes, es posible que el intercambio ya esté inhabilitado. Para comprobarlo, aplique exec en un contenedor ejecutándose y ejecute cat /proc/swaps para enumerar los dispositivos de intercambio activos. Si no ve nada, el intercambio estará inhabilitado.
Ahora que definimos nuestro contenedor principal de la aplicación y los contenedores Init que se ejecutan antes para ajustar el SO del contenedor, podemos añadir la pieza final a nuestro archivo de definición de objeto StatefulSet: volumeClaimTemplates.
Pegue el siguiente bloque de volumeClaimTemplate:
. . .
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: do-block-storage
resources:
requests:
storage: 100Gi
En este bloque, definimos el volumeClaimTemplates de StatefulSet. Kubernetes lo usará para crear PersistentVolumes para los Pods. En el bloque anterior, lo llamamos data (que es el name al que nos referimos en el volumeMount previamente definido) y le asignamos la misma etiqueta app: elasticsearch que a nuestro StatefulSet.
A continuación, especificamos su modo de acceso como ReadWriteOnce, lo que significa que solo un nodo puede montarlo con atributos de lectura y escritura. En esta guía, definimos la clase de almacenamiento como do-block-storage debido a que usamos un clúster de Kubernetes DigitalOcean para fines demostrativos. Debería cambiar este valor según el punto en que ejecute su clúster de Kubernetes. Para obtener más información, consulte la documentación de Persistent Volume.
Por último, especificaremos que nos gustaría que cada PersistentVolume tuviese un tamaño de 100 GiB. Debería ajustar este valor según sus necesidades de producción.
La especificación completa de StatefulSet debería tener un aspecto similar a este:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: do-block-storage
resources:
requests:
storage: 100Gi
Cuando esté satisfecho con su configuración de Elasticsearch, guarde y cierre el archivo.
Ahora, implemente StatefulSet usando kubectl:
- kubectl create -f elasticsearch_statefulset.yaml
Debería ver el siguiente resultado:
Outputstatefulset.apps/es-cluster created
Puede controlar la implementación de StatefulSet usando kubectl rollout status:
- kubectl rollout status sts/es-cluster --namespace=kube-logging
Debería ver el siguiente resultado a medida que se implemente el clúster:
OutputWaiting for 3 pods to be ready...
Waiting for 2 pods to be ready...
Waiting for 1 pods to be ready...
partitioned roll out complete: 3 new pods have been updated...
Cuando se implemenen todos los Pods, podrá comprobar que su clúster de Elasticsearch funcione correctamente realizando una solicitud en la API REST.
Para hacerlo, primero, reenvíe el puerto local 9200 al puerto 9200 en uno de los nodos de Elasticsearch (es-cluster-0) usando kubectl port-forward:
- kubectl port-forward es-cluster-0 9200:9200 --namespace=kube-logging
A continuación, en una ventana de terminal separada, realice una solicitud curl en la API REST:
- curl http://localhost:9200/_cluster/state?pretty
Debería ver el siguiente resultado:
Output{
"cluster_name" : "k8s-logs",
"compressed_size_in_bytes" : 348,
"cluster_uuid" : "QD06dK7CQgids-GQZooNVw",
"version" : 3,
"state_uuid" : "mjNIWXAzQVuxNNOQ7xR-qg",
"master_node" : "IdM5B7cUQWqFgIHXBp0JDg",
"blocks" : { },
"nodes" : {
"u7DoTpMmSCixOoictzHItA" : {
"name" : "es-cluster-1",
"ephemeral_id" : "ZlBflnXKRMC4RvEACHIVdg",
"transport_address" : "10.244.8.2:9300",
"attributes" : { }
},
"IdM5B7cUQWqFgIHXBp0JDg" : {
"name" : "es-cluster-0",
"ephemeral_id" : "JTk1FDdFQuWbSFAtBxdxAQ",
"transport_address" : "10.244.44.3:9300",
"attributes" : { }
},
"R8E7xcSUSbGbgrhAdyAKmQ" : {
"name" : "es-cluster-2",
"ephemeral_id" : "9wv6ke71Qqy9vk2LgJTqaA",
"transport_address" : "10.244.40.4:9300",
"attributes" : { }
}
},
...
Esto indica que nuestro clúster de Elasticsearch k8s-logs se creó correctamente con 3 nodos: es-cluster-0, es-cluster-1 y es-cluster-2. El nodo maestro actual es es-cluster-0.
Ahora que su clúster de Elasticsearch está configurado y en ejecución, puede configurar un frontend de Kibana para él.
Paso 3: Crear la implementación y el servicio de Kibana
Para iniciar Kibana en Kubernetes, crearemos un servicio llamado kibana y una implementación que consta de una réplica de Pod. Puede escalar el número de replicas según sus necesidades de producción y, de forma opcional, especificar un tipo de LoadBalancer para el servicio a fin de cargar solicitudes de equilibrio en los pods de implementación.
En este caso, crearemos el servicio y la implementación en el mismo archivo. Abra un archivo llamado kibana.yaml en su editor favorito:
- nano kibana.yaml
Péguelo en la siguiente especificación de servicio:
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
ports:
- port: 5601
selector:
app: kibana
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.2.0
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601
A continuación, guarde y cierre el archivo.
En esta especificación, definimos un servicio llamado kibana en el espacio de nombres kube-logging y le asignamos la etiqueta app: kibana.
También especificamos que el acceso a este debería ser posible en el puerto 5601 y que debería usar la etiqueta app: kibana para seleccionar los Pods de destino del servicio.
En la especificación Deployment, definimos una implementación llamada kibana y especificamos que quisiéramos 1 réplica de Pod.
Usamos la imagen docker.elastic.co/kibana/kibana:7.2.0. Ahora puede sustituir su propia imagen de Kibana privada o pública que usará.
Especificamos que nos quisiéramos al menos 0,1 vCPU garantizado para el Pod, con un límite de 1 vCPU. Debería cambiar estos valores según su carga prevista y los recursos disponibles.
A continuación, usaremos la variable de entorno ELASTICSEARCH_URL para establecer el punto final y el puerto para el clúster de Elasticsearch. Al usar DNS de Kubernetes, este punto final corresponde a su nombre de servicio elasticsearch. Este dominio se resolverá en una lista de direcciones IP para los 3 Pods de Elasticsearch. Para obtener más información sobre el DNS de Kubernetes, consulte DNS para servicios y Pods.
Por último, fijamos el puerto de contenedor de Kibana en el valor 5601, al cual el servicio kibana reenviará las solicitudes.
Cuando esté satisfecho con su configuración de Kibana, podrá implementar el servicio y la implementación usando kubectl:
- kubectl create -f kibana.yaml
Debería ver el siguiente resultado:
Outputservice/kibana created
deployment.apps/kibana created
Puede comprobar que la implementación se haya realizado con éxito ejecutando el siguiente comando:
- kubectl rollout status deployment/kibana --namespace=kube-logging
Debería ver el siguiente resultado:
Outputdeployment "kibana" successfully rolled out
Para acceder a la interfaz de Kibana, reenviaremos un puerto local al nodo de Kubernetes ejecutando Kibana. Obtenga la información del Pod de Kibana usando kubectl get:
- kubectl get pods --namespace=kube-logging
OutputNAME READY STATUS RESTARTS AGE
es-cluster-0 1/1 Running 0 55m
es-cluster-1 1/1 Running 0 54m
es-cluster-2 1/1 Running 0 54m
kibana-6c9fb4b5b7-plbg2 1/1 Running 0 4m27s
Aquí observamos que nuestro Pod de Kibana se llama kibana-6c9fb4b5b7-plbg2.
Reenvíe el puerto local 5601 al puerto 5601 de este Pod:
- kubectl port-forward kibana-6c9fb4b5b7-plbg2 5601:5601 --namespace=kube-logging
Debería ver el siguiente resultado:
OutputForwarding from 127.0.0.1:5601 -> 5601
Forwarding from [::1]:5601 -> 5601
Ahora, en su navegador web, visite la siguiente URL:
http://localhost:5601
Si ve la siguiente página de bienvenida de Kibana, significa que implementó con éxito Kibana en su clúster de Kubernetes:

Ahora puede proseguir con la implementación del componente final de la pila EFK: el colector de registro, Fluentd.
Paso 4: Crear el DaemonSet de Fluentd
En esta guía, configuraremos Fluentd como DaemonSet, que es un tipo de carga de trabajo de Kubernetes que ejecuta una copia de un Pod determinado en cada nodo del clúster de Kubernetes. Al usar este controlador de DaemonSet, implementaremos un Pod de agente de registro de Fluentd en cada nodo de nuestro clúster. Para obtener más información sobre esta arquitectura de registro, consulte “Usar un agente de registro de nodo” de los documentos oficiales de Kubernetes.
En Kubernetes, los flujos de registro de las aplicaciones en contenedores que realizan registros en stdout y stderr se capturan y redireccionan a los archivos de JSON de los nodos. El Pod de Fluentd controlará estos archivos de registro, filtrará los eventos de registro, transformará los datos de registro y los enviará al backend de registro de Elasticsearch que implementamos en el Paso 2.
Además de los registros de contenedores, el agente de Fluentd controlará los registros de componentes del sistema de Kubernetes, como kubelet, kube-proxy y los registros de Docker. Para ver una lista completa de fuentes controladas por el agente de registro de Fluentd, consulte el archivo kubernetes.conf utilizado para configurar el agente de registro. Para obtener más información sobre el registro en los clústeres de Kubernetes, consulte “Realizar registros en el nivel de nodo” de la documentación oficial de Kubernetes.
Empiece abriendo un archivo llamado fluentd.yaml en su editor de texto favorito:
- nano fluentd.yaml
Una vez más, realizaremos el pegado en las definiciones de objeto de Kubernetes bloque por bloque y proporcionaremos contexto a medida que avancemos. En esta guía, usamos la especificación de DaemonSet de Fluentd proporcionada por los encargados de mantenimiento de Fluentd. Otro recurso útil proporcionado por los encargados de mantenimiento de Fluentd es Kuberentes Fluentd.
Primero, pegue la siguiente definición de ServiceAccount:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
Aquí, crearemos una cuenta de servicio llamada fluentd que los Pods de Fluentd usarán para acceder a la API de Kubernetes. La crearemos en el espacio de nombres kube-logging y una vez más le asignaremos la etiqueta app: fluentd. Para obtener más información sobre las cuentas de servicio de Kubernetes, consulte Configurar cuentas de servicio para Pods en los documentos oficiales de Kubernetes.
A continuación, pegue el siguiente bloque de ClusterRole:
. . .
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
Aquí definiremos un ClusterRole llamado fluentd al que concederemos los permisos get, list y watch en los objetos pods y namespaces. Los clusterRoles le permiten conceder acceso a recursos de Kubernetes con ámbito de clúster como nodos. Para obtener más información sobre el control de acceso basado en roles y los roles de clústeres, consulte Usar la autorización de RBAC en la documentación oficial de Kubernetes.
A cotninuación, pegue el siguiente bloque de ClusterRoleBinding:
. . .
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging
En este bloque, definimos un ClusterRoleBinding llamado fluentd que une el ClusterRole de fluentd a la cuenta de servicio de fluentd. Esto concede a la cuenta de servicio de fluentd los permisos enumerados en el rol de clúster de fluentd.
En este punto, podemos comenzar a realizar el pegado en la especificación real de DaemonSet:
. . .
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
Aquí definimos un DaemonSet llamado fluentd en el espacio de nombres kube-logging y le asignamos la etiqueta app: fluentd.
A continuación, pegue la siguiente sección:
. . .
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
Aquí hacemos coincidir la etiqueta app:fluentd definida en .metadata.labels y luego asignamos la cuenta de servicio de fluentd al DaemonSet. También seleccionamos la app:fluentd como los Pods administrados por este DaemonSet.
A continuación, definimos una tolerancia de NoSchedule para que coincida con el rasgo equivalente de los nodos maestros de Kubernetes. Esto garantizará que el DaemonSet también se despliegue a los maestros de Kubernetes. Si no desea ejecutar un Pod de Fluentd en sus nodos maestros, elimine esta tolerancia. Para obtener más información sobre los rasgos y las tolerancias de Kubernetes, consulte “Rasgos y tolerancias" en los documentos oficiales de Kubernetes.
A continuación, empezaremos a definir el contenedor de Pods, que llamamos fluentd.
Usaremos la imagen oficial de Debian v1.4.2 proporcionada por los responsables de mantenimiento de Fluentd. Si quiere usar su propia imagen privada o pública de Fluentd o una versión de imagen distinta, modifique la etiqueta image en la especificación del contenedor. El Dockerfile y el contenido de esta imagen están disponibles en el repositorio de Github fluentd-kubernetes-daemonset.
A continuación, configuraremos Fluentd usando algunas variables de entorno:
FLUENT_ELASTICSEARCH_HOST: lo fijaremos enala dirección de servicio sin encabezado de Elasticsearch definida anteriormente: elasticsearch.kube-logging.svc.cluster.local. Esto se resolverá en una lista de direcciones IP para los 3 Pods de Elasticsearch. El host real de Elasticsearch probablemente será la primera dirección IP de esta lista. Para distribuir registros en el clúster, deberá modificar la configuración del complemento de resultados de Elasticsearch de Fluentd. Para obtener más información sobre este complemento, consulte Complemento de resultado de Elasticsearch.FLUENT_ELASTICSEARCH_PORT: lo fijaremos en9200, el puerto de Elasticsearch que configuramos antes.FLUENT_ELASTICSEARCH_SCHEME: lo fijaremos enhttp.FLUENTD_SYSTEMD_CONF: lo fijaremos endisablepara eliminar el resultado relacionado consystemdque no está configurado en el contenedor.
Por último, pegue la siguiente sección:
. . .
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
Aquí especificamos un límite de memoria de 512 MiB en el Pod de FluentD y garantizamos 0,1 vCPU y 200 MiB de memoria. Puede ajustar estos límites y estas solicitudes de recursos según su volumen de registro previsto y los recursos disponibles.
A continuación, montamos las rutas host /var/log y /var/lib/docker/containers en el contenedor usando volumeMounts varlog y varlibdockercontainers. Estos volúmenes se definen al final del bloque.
El parámetro final que definimos en este bloque es terminationGracePeriodSeconds, que proporciona a Fluentd 30 segundos para cerrarse de forma correcta tras recibir una señal SIGTERM. Tras 30 segundos, los contenedores se envían a una señal SIGKILL El valor predeterminado de terminationGracePeriodSeconds es de 30 segundos, con lo cual en la mayoría de los casos este parámetro puede omitirse. Para obtener más información sobre la terminación de las cargas de trabajo de Kubernetes de forma correcta, consulte en Google “Buenas prácticas de Kubernetes: cierre correcto”.
La especificación completa de Fluentd debería tener un aspecto similar a este:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
Cuando termine de configurar el DaemonSet de Fluentd, guarde y cierre el archivo.
Ahora, ejecute el DaemonSet usando kubectl:
- kubectl create -f fluentd.yaml
Debería ver el siguiente resultado:
Outputserviceaccount/fluentd created
clusterrole.rbac.authorization.k8s.io/fluentd created
clusterrolebinding.rbac.authorization.k8s.io/fluentd created
daemonset.extensions/fluentd created
Verifique que su DaemonSet se despliegue correctamente usando kubectl:
- kubectl get ds --namespace=kube-logging
Debería ver el siguiente estado:
OutputNAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
fluentd 3 3 3 3 3 <none> 58s
Esto indica que hay 3 Pods de fluentd en ejecución, lo que corresponde al número de nodos en nuestro clúster de Kubernetes.
Ahora podemos comprobar Kibana para verificar que los datos de registro se recopilen y envíen correctamente a Elasticsearch.
Con kubectl port-forward todavía abierto, vaya a http://localhost:5601.
Haga clic en Discover en el menú de navegación izquierdo:
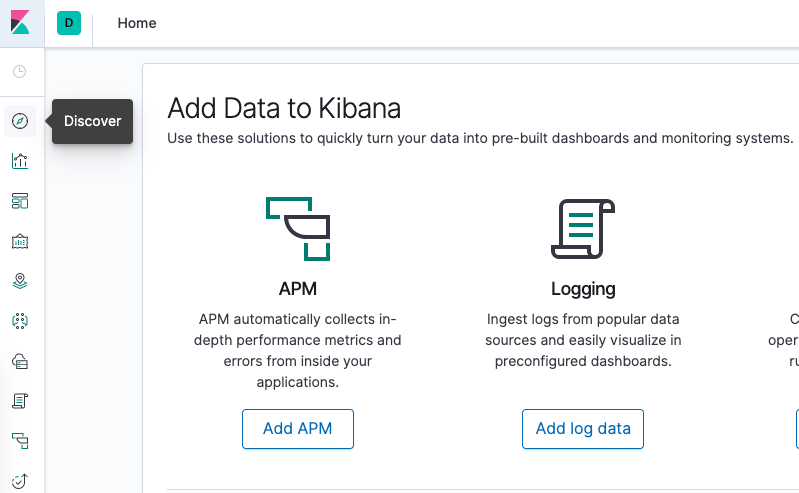
Debería ver la siguiente ventana de configuración:
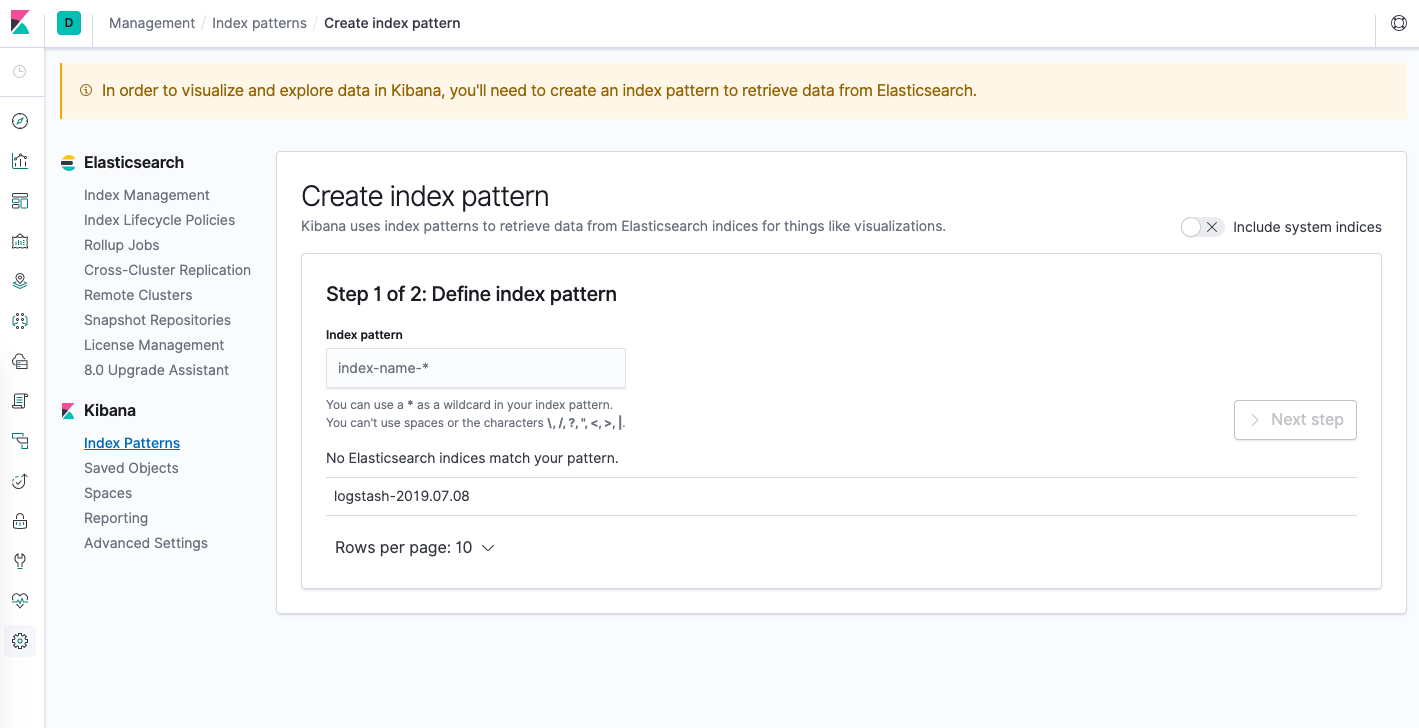
Esto le permite definir los índices de Elasticsearch que desea explorar en Kibana. Para obtener más información, consulte Definir sus patrones de indexación en los documentos oficiales de Kibana. Por ahora, simplemente usaremos el patrón comodín logstash-* para capturar todos los datos de registro de nuestro clúster de Elasticsearch. Introduzca logstash-* en la casilla de texto y haga clic en Next step.
Accederá a la siguiente página:
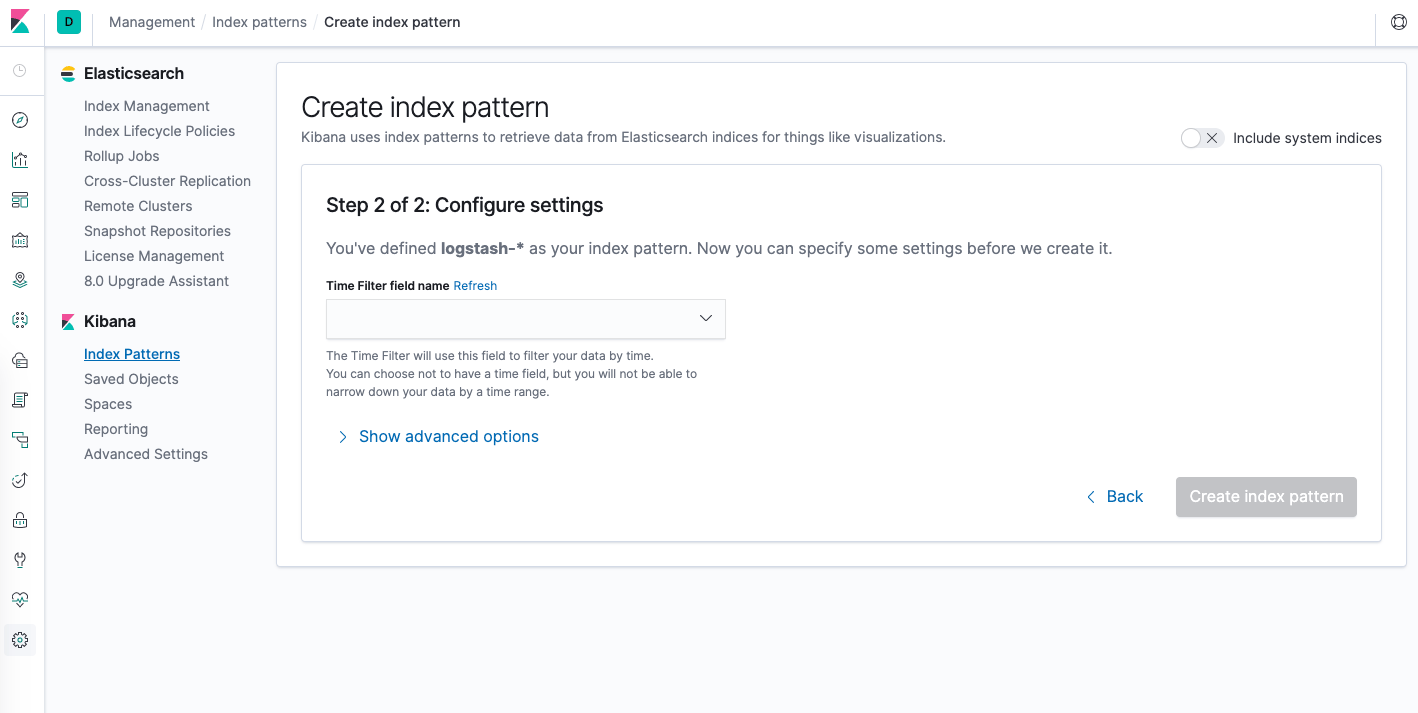
Aquí puede configurar el campo de Kibana que usará para filtrar los datos de registro por tiempo. En el menú desplegable, seleccione el campo @timestamp y presione Create index pattern.
Luego, presione Discover en el menú de navegación izquierdo.
Debería ver un gráfico de histograma y algunas entradas recientes en el registro:
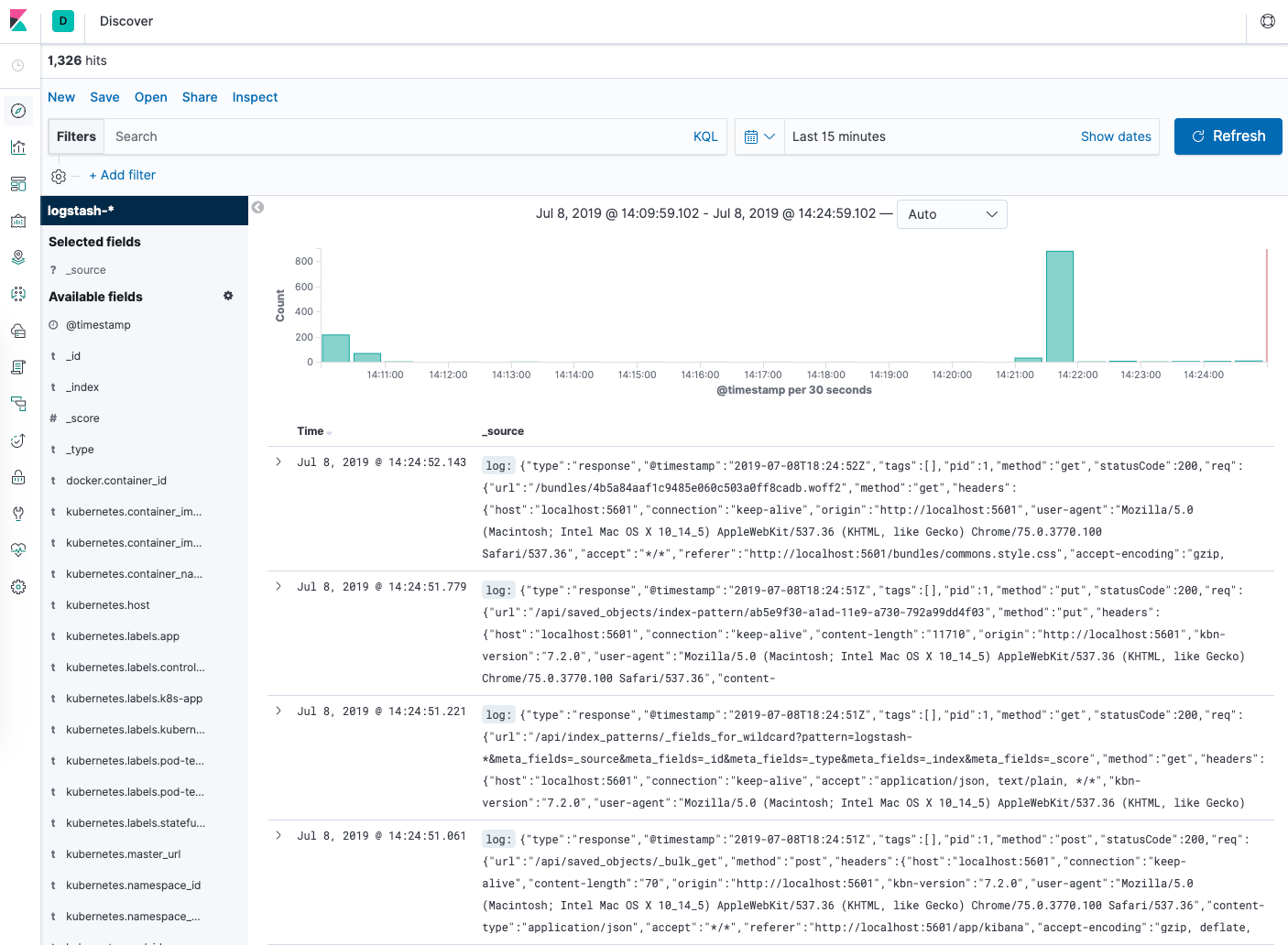
En este punto, habrá configurado e implementado correctamente la pila EFK en su clúster de Kubernetes. Si desea aprender a usar Kibana para analizar sus datos de registro, consulte la Guía de usuario de Kibana.
En la siguiente sección opcional, implementaremos un Pod counter simple que imprime números en stdout y encuentra sus registros en Kibana.
Paso 5 (opcional): Probar el registro de contenedores
Para demostrar un caso básico de uso de Kibana de exploración de los últimos registros de un Pod determinado, implementaremos un Pod counter que imprime números secuenciales en stdout.
Comencemos creando el Pod. Abra un archivo llamado counter.yaml en su editor favorito:
- nano counter.yaml
A continuación, pegue la siguiente especificación de Pod:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
Guarde y cierre el archivo.
Este es un Pod mínimo llamado counter que ejecuta un bucle while e imprime números de forma secuencial.
Implemente el counter de Pods usando kubectl:
- kubectl create -f counter.yaml
Cuando el Pod se cree y esté en ejecución, regrese a su panel de control de Kibana.
Desde la página Discover, en la barra de búsqueda escriba kubernetes.pod_name:counter. Con esto se filtrarán los datos de registro para Pods que tengan el nombre counter.
A continuación, debería ver una lista de entradas de registro para el Pod counter:
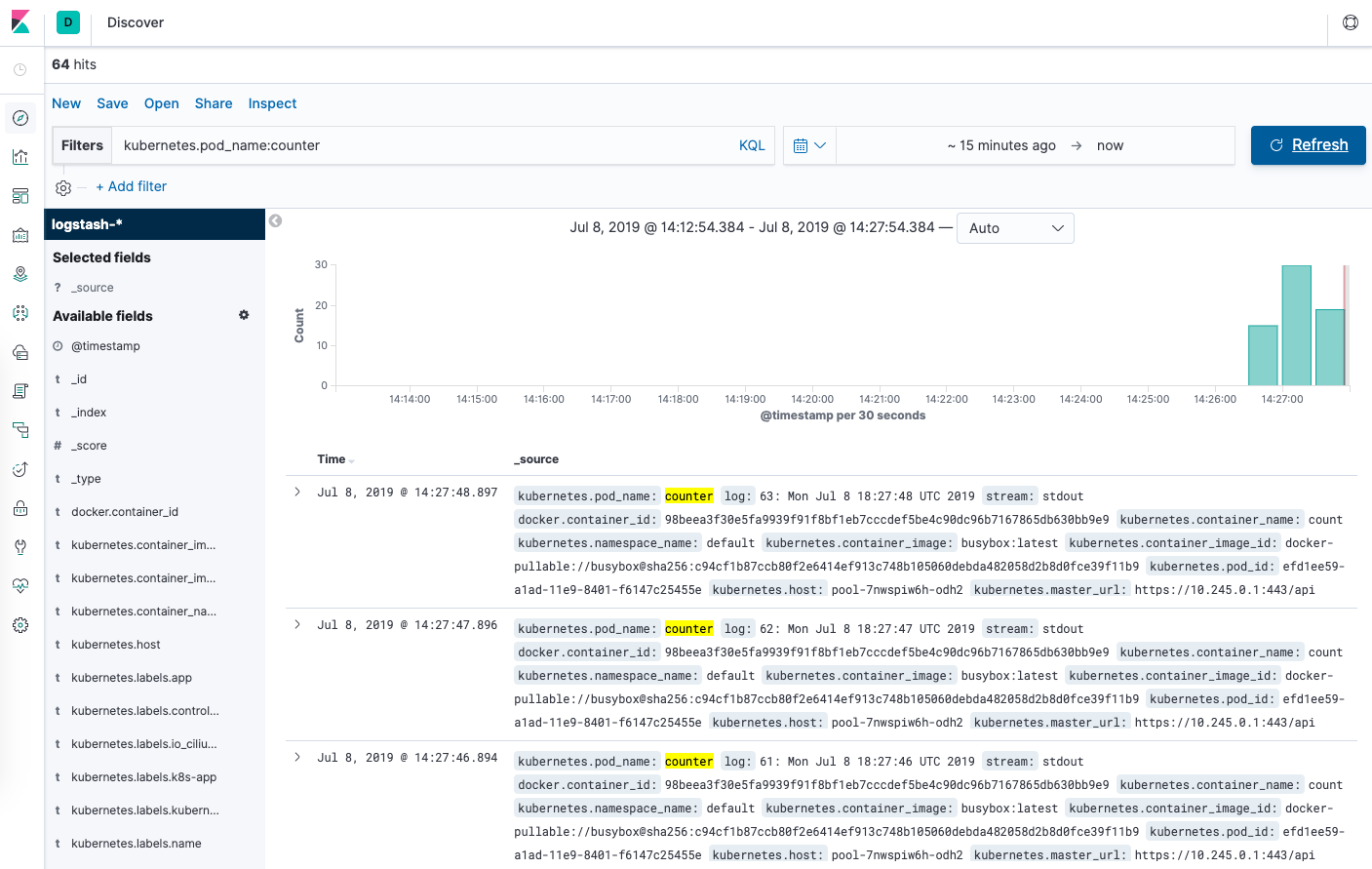
Puede hacer clic en cualquiera de las entradas de registro para ver metadatos adicionales, como el nombre del contenedor, el nodo de Kubernetes, el espacio de nombres y otros.
Conclusión
En esta guía, demostramos la forma de instalar y configurar Elasticsearch, Fluentd y Kibana en un clúster de Kubernetes. Usamos una arquitectura de registro mínima que consta de un único agente de registro de Pod que se ejecuta en cada nodo de trabajo de Kubernetes.
Antes de implementar esta pila de registro en su clúster de Kubernetes de producción, la mejor opción es ajustar los requisitos y límites de recursos como se indica en esta guía. También es posible que desee configurar X-Pack para habilitar funciones integradas de seguimiento y seguridad.
La arquitectura de registro que usamos aquí consta de 3 Pods de Elasticsearch, un Pod único de Kibana (sin equilibrio de carga) y un conjunto de Pods de Fluentd se implementaron como un DaemonSet. Es posible que desee escalar esta configuración según su caso de uso de producción. Para obtener más información sobre el escalamiento de su pila de Elasticsearch y Kibana, consulte Escalamiento de Elasticsearch.
Kubernetes también permite arquitecturas de agentes de registro más complejas que pueden ajustarse mejor a su caso de uso. Para obtener más información, consulte Arquitectura de registro en los documentos de Kubernetes.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
DevOps Engineer, Former Technical Writer and Editor at DigitalOcean. Expertise in topics including Ubuntu, Kubernetes, Docker, CentOS.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
