By Jeremy Morris and Lisa Tagliaferri

Introduction
This tutorial will cover setting up a Hadoop cluster on DigitalOcean. The Hadoop software library is an Apache framework that lets you process large data sets in a distributed way across server clusters through leveraging basic programming models. The scalability provided by Hadoop allows you to scale up from single servers to thousands of machines. It also provides failure detection at the application layer, so it can detect and handle failures as a high-availability service.
There are 4 important modules that we will be working with in this tutorial:
- Hadoop Common is the collection of common utilities and libraries necessary to support other Hadoop modules.
- The Hadoop Distributed File System (HDFS), as stated by the Apache organization, is a highly fault-tolerant, distributed file system, specifically designed to run on commodity hardware to process large data sets.
- Hadoop YARN is the framework used for job scheduling and cluster resource management.
- Hadoop MapReduce is a YARN-based system for parallel processing of large data sets.
In this tutorial, we will be setting up and running a Hadoop cluster on four DigitalOcean Droplets.
Prerequisites
This tutorial will require the following:
-
Four Ubuntu 16.04 Droplets with non-root sudo users set up. If you do not have this set up, follow along with steps 1-4 of the Initial Server Setup with Ubuntu 16.04. This tutorial will assume that you are using an SSH key from a local machine. Per Hadoop’s language, we’ll refer to these Droplets by the following names:
hadoop-masterhadoop-worker-01hadoop-worker-02hadoop-worker-03
-
Additionally, you may want to use DigitalOcean Snapshots after the initial server set up and the completion of Steps 1 and 2 (below) of your first Droplet.
With these prerequisites in place, you will be ready to begin setting up a Hadoop cluster.
Step 1 — Installation Setup for Each Droplet
We’re going to be installing Java and Hadoop on each of our four Droplets. If you don’t want to repeat each step on each Droplet, you can use DigitalOcean Snapshots at the end of Step 2 in order to replicate your initial installation and configuration.
First, we’ll update Ubuntu with the latest software patches available:
- sudo apt-get update && sudo apt-get -y dist-upgrade
Next, let’s install the headless version of Java for Ubuntu on each Droplet. “Headless” refers to the software that is capable of running on a device without a graphical user interface.
- sudo apt-get -y install openjdk-8-jdk-headless
To install Hadoop on each Droplet, let’s make the directory where Hadoop will be installed. We can call it my-hadoop-install and then move into that directory.
- mkdir my-hadoop-install && cd my-hadoop-install
Once we’ve created the directory, let’s install the most recent binary from the Hadoop releases list. At the time of this tutorial, the most recent is Hadoop 3.0.1.
Note: Keep in mind that these downloads are distributed via mirror sites, and it is recommended that it be checked first for tampering using either GPG or SHA-256.
When you are satisfied with the download you have selected, you can use the wget command with the binary link you have chosen, such as:
- wget http://mirror.cc.columbia.edu/pub/software/apache/hadoop/common/hadoop-3.0.1/hadoop-3.0.1.tar.gz
Once your download is complete, unzip the file’s contents using tar, a file archiving tool for Ubuntu:
- tar xvzf hadoop-3.0.1.tar.gz
We’re now ready to start our initial configuration.
Step 2 — Update Hadoop Environment Configuration
For each Droplet node, we’ll need to set up JAVA_HOME. Open the following file with nano or another text editor of your choice so that we can update it:
- nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hadoop-env.sh
Update the following section, where JAVA_HOME is located:
...
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
# export JAVA_HOME=
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
# export HADOOP_HOME=
...
To look like this:
...
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
# export HADOOP_HOME=
...
We’ll also need to add some environment variables to run Hadoop and its modules. They should be added to the bottom of the file so it looks like the following, where sammy would be your sudo non-root user’s username.
Note: If you are using a different username across your cluster Droplets, you will need to edit this file in order to reflect the correct username for each specific Droplet.
...
#
# To prevent accidents, shell commands be (superficially) locked
# to only allow certain users to execute certain subcommands.
# It uses the format of (command)_(subcommand)_USER.
#
# For example, to limit who can execute the namenode command,
export HDFS_NAMENODE_USER="sammy"
export HDFS_DATANODE_USER="sammy"
export HDFS_SECONDARYNAMENODE_USER="sammy"
export YARN_RESOURCEMANAGER_USER="sammy"
export YARN_NODEMANAGER_USER="sammy"
At this point, you can save and exit the file. Next, run the following command to apply our exports:
- source ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hadoop-env.sh
With the hadoop-env.sh script updated and sourced, we need to create a data directory for the Hadoop Distributed File System (HDFS) to store all relevant HDFS files.
- sudo mkdir -p /usr/local/hadoop/hdfs/data
Set the permissions for this file with your respective user. Remember, if you have different usernames on each Droplet, be sure to allow your respective sudo user to have these permissions:
- sudo chown -R sammy:sammy /usr/local/hadoop/hdfs/data
If you would like to use a DigitalOcean Snapshot to replicate these commands across your Droplet nodes, you can create your Snapshot now and create new Droplets from this image. For guidance on this, you can read An Introduction to DigitalOcean Snapshots.
When you have completed the steps above across all four Ubuntu Droplets, you can move on to completing this configuration across nodes.
Step 3 — Complete Initial Configuration for Each Node
At this point, we need to update the core_site.xml file for all 4 of your Droplet nodes. Within each individual Droplet, open the following file:
- nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/core-site.xml
You should see the following lines:
...
<configuration>
</configuration>
Change the file to look like the following XML so that we include each Droplet’s respective IP inside of the property value, where we have server-ip written. If you are using a firewall, you’ll need to open port 9000.
...
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://server-ip:9000</value>
</property>
</configuration>
Repeat the above writing in the relevant Droplet IP for all four of your servers.
Now all of the general Hadoop settings should be updated for each server node, and we can continue onto connecting our nodes via SSH keys.
Step 4 — Set Up SSH for Each Node
In order for Hadoop to work properly, we need to set up passwordless SSH between the master node and the worker nodes (the language of master and worker is Hadoop’s language to refer to primary and secondary servers).
For this tutorial, the master node will be hadoop-master and the worker nodes will be collectively referred to as hadoop-worker, but you’ll have three of them in total (referred to as -01, -02, and -03). We first need to create a public-private key-pair on the master node, which will be the node with the IP address belonging to hadoop-master.
While on the hadoop-master Droplet, run the following command. You’ll press enter to use the default for the key location, then press enter twice to use an empty passphrase:
- ssh-keygen
For each of the worker nodes, we need to take the master node’s public key and copy it into each of the worker nodes’ authorized_keys file.
Get the public key from the master node by running cat on the id_rsa.pub file located in your .ssh folder, to print to console:
- cat ~/.ssh/id_rsa.pub
Now log into each worker node Droplet, and open the authorized_keys file:
- nano ~/.ssh/authorized_keys
You’ll copy the master node’s public key — which is the output you generated from the cat ~/.ssh/id_rsa.pub command on the master node — into each Droplet’s respective ~/.ssh/authorized_keys file. Be sure to save each file before closing.
When you are finished updating the 3 worker nodes, also copy the master node’s public key into its own authorized_keys file by issuing the same command:
- nano ~/.ssh/authorized_keys
On hadoop-master, you should set up the ssh configuration to include each of the hostnames of the related nodes. Open the configuration file for editing, using nano:
- nano ~/.ssh/config
You should modify the file to look like the following, with relevant IPs and usernames added.
Host hadoop-master-server-ip
HostName hadoop-example-node-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-01-server-ip
HostName hadoop-worker-01-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-02-server-ip
HostName hadoop-worker-02-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Host hadoop-worker-03-server-ip
HostName hadoop-worker-03-server-ip
User sammy
IdentityFile ~/.ssh/id_rsa
Save and close the file.
From the hadoop-master, SSH into each node:
- ssh sammy@hadoop-worker-01-server-ip
Since it’s your first time logging into each node with the current system set up, it will ask you the following:
Outputare you sure you want to continue connecting (yes/no)?
Reply to the prompt with yes. This will be the only time it needs to be done, but it is required for each worker node for the initial SSH connection. Finally, log out of each worker node to return to hadoop-master:
- logout
Be sure to repeat these steps for the remaining two worker nodes.
Now that we have successfully set up passwordless SSH for each worker node, we can now continue to configure the master node.
Step 5 — Configure the Master Node
For our Hadoop cluster, we need to configure the HDFS properties on the master node Droplet.
While on the master node, edit the following file:
- nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hdfs-site.xml
Edit the configuration section to look like the XML below:
...
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/hdfs/data</value>
</property>
</configuration>
Save and close the file.
We’ll next configure the MapReduce properties on the master node. Open mapred.site.xml with nano or another text editor:
- nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/mapred-site.xml
Then update the file so that it looks like this, with your current server’s IP address reflected below:
...
<configuration>
<property>
<name>mapreduce.jobtracker.address</name>
<value>hadoop-master-server-ip:54311</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Save and close the file. If you are using a firewall, be sure to open port 54311.
Next, set up YARN on the master node. Again, we are updating the configuration section of another XML file, so let’s open the file:
- nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/yarn-site.xml
Now update the file, being sure to input your current server’s IP address:
...
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master-server-ip</value>
</property>
</configuration>
Finally, let’s configure Hadoop’s point of reference for what the master and worker nodes should be. First, open the masters file:
- nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/masters
Into this file, you’ll add your current server’s IP address:
hadoop-master-server-ip
Now, open and edit the workers file:
- nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/workers
Here, you’ll add the IP addresses of each of your worker nodes, underneath where it says localhost.
localhost
hadoop-worker-01-server-ip
hadoop-worker-02-server-ip
hadoop-worker-03-server-ip
After finishing the configuration of the MapReduce and YARN properties, we can now finish configuring the worker nodes.
Step 6 — Configure the Worker Nodes
We’ll now configure the worker nodes so that they each have the correct reference to the data directory for HDFS.
On each worker node, edit this XML file:
- nano ~/my-hadoop-install/hadoop-3.0.1/etc/hadoop/hdfs-site.xml
Replace the configuration section with the following:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/hdfs/data</value>
</property>
</configuration>
Save and close the file. Be sure to replicate this step on all three of your worker nodes.
At this point, our worker node Droplets are pointing to the data directory for HDFS, which will allow us to run our Hadoop cluster.
Step 7 — Run the Hadoop Cluster
We have reached a point where we can start our Hadoop cluster. Before we start it up, we need to format the HDFS on the master node. While on the master node Droplet, change directories to where Hadoop is installed:
- cd ~/my-hadoop-install/hadoop-3.0.1/
Then run the following command to format HDFS:
- sudo ./bin/hdfs namenode -format
A successful formatting of the namenode will result in a lot of output, consisting of mostly INFO statements. At the bottom you will see the following, confirming that you’ve successfully formatted the storage directory.
Output...
2018-01-28 17:58:08,323 INFO common.Storage: Storage directory /usr/local/hadoop/hdfs/data has been successfully formatted.
2018-01-28 17:58:08,346 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/hdfs/data/current/fsimage.ckpt_0000000000000000000 using no compression
2018-01-28 17:58:08,490 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/hdfs/data/current/fsimage.ckpt_0000000000000000000 of size 389 bytes saved in 0 seconds.
2018-01-28 17:58:08,505 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2018-01-28 17:58:08,519 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop-example-node/127.0.1.1
************************************************************/
Now, start the Hadoop cluster by running the following scripts (be sure to check scripts before running by using the less command):
- sudo ./sbin/start-dfs.sh
You’ll then see output that contains the following:
OutputStarting namenodes on [hadoop-master-server-ip]
Starting datanodes
Starting secondary namenodes [hadoop-master]
Then run YARN, using the following script:
- ./sbin/start-yarn.sh
The following output will appear:
OutputStarting resourcemanager
Starting nodemanagers
Once you run those commands, you should have daemons running on the master node and one on each of the worker nodes.
We can check the daemons by running the jps command to check for Java processes:
- jps
After running the jps command, you will see that the NodeManager, SecondaryNameNode, Jps, NameNode, ResourceManager, and DataNode are running. Something similar to the following output will appear:
Output9810 NodeManager
9252 SecondaryNameNode
10164 Jps
8920 NameNode
9674 ResourceManager
9051 DataNode
This verifies that we’ve successfully created a cluster and verifies that the Hadoop daemons are running.
In a web browser of your choice, you can get an overview of the health of your cluster by navigating to:
http://hadoop-master-server-ip:9870
If you have a firewall, be sure to open port 9870. You’ll see something that looks similar to the following:
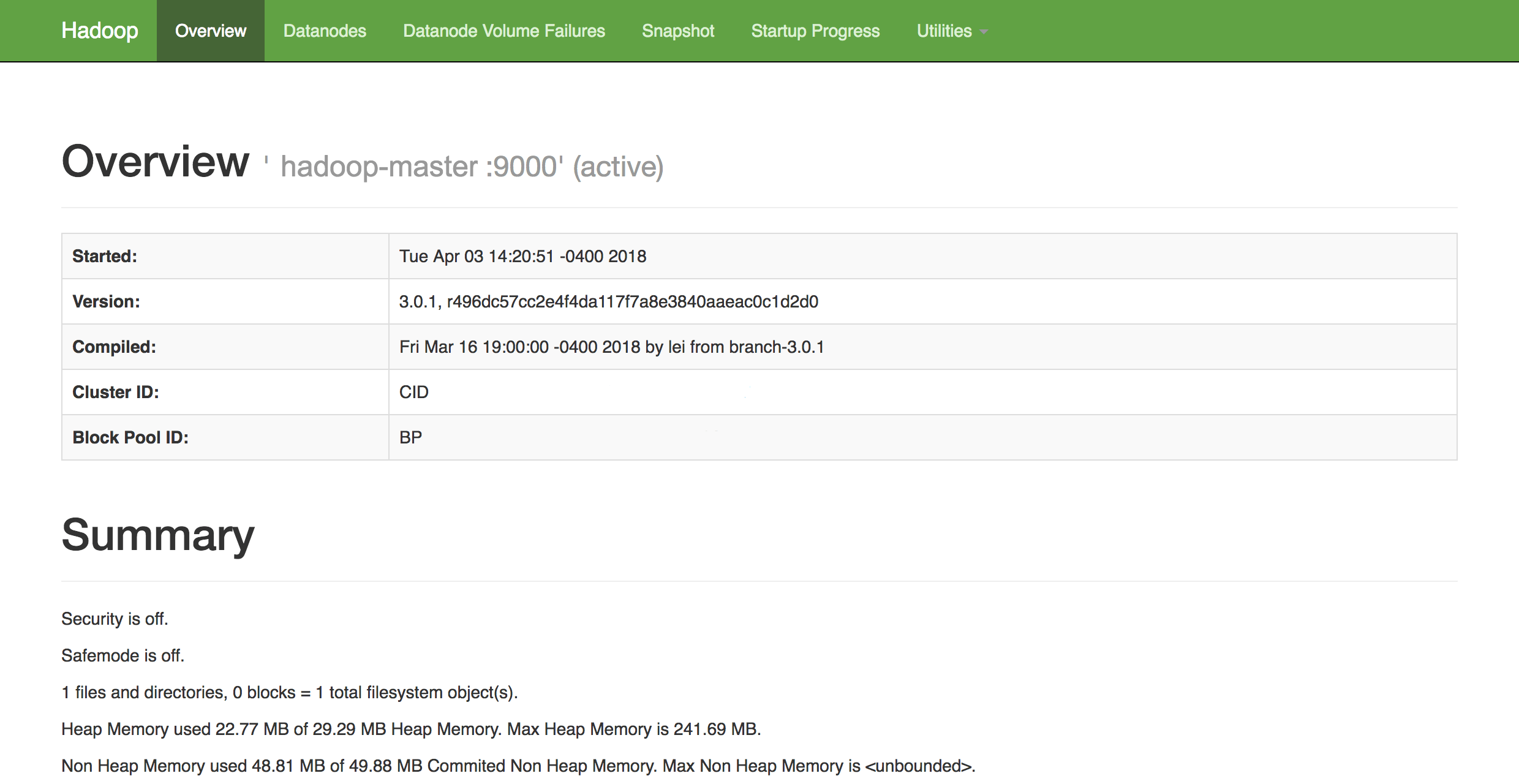
From here, you can navigate to the Datanodes item in the menu bar to see the node activity.
Conclusion
In this tutorial, we went over how to set up and configure a Hadoop multi-node cluster using DigitalOcean Ubuntu 16.04 Droplets. You can also now monitor and check the health of your cluster using Hadoop’s DFS Health web interface.
To get an idea of possible projects you can work on to utilize your newly configured cluster, check out Apache’s long list of projects powered by Hadoop.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
Software Engineer at DigitalOcean
Community and Developer Education expert. Former Senior Manager, Community at DigitalOcean. Focused on topics including Ubuntu 22.04, Ubuntu 20.04, Python, Django, and more.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Nicely detailed with the Hadoop multinode setup, but whats new in this configuration except it is been configured in yet another flavour of linux(Ubuntu-16.04 Droplets) is confusing. Visit :http://www.noahdatatech.com/solutions/big-data-engineering/
I followed the steps, to set up my multinode cluster but when I check datanode information on web(9870) shows only 1 master node. I cannot see slaves at all. Any help please?
Great tutorial, but just one mistake that got me stuck a while:
Do not add the worker ip in core-site.xml even if you’re configuring the worker node. This config is about telling the worker node where to connect to the name node. Otherwise, very useful write up. Thank you!
Great tutorial.
I got my cluster up and running taking into account @Toastbroad comment.
However. I have a problem trying to use the webUI to modify files using webhdfs.
e.g. uploading a file:
When I inspect the network requests being sent from chrome I see that it begins by sending a request to the master node’s ip address. The master node then responds telling the webUI the address of the worker node to send the data request to. However, the address contain hostnames not ip addresses. e.g. https://hadoop-worker-01/… The webUI tries to connect but obviously it doesn’t success because that host name is not public. I would have expected hadoop to respond with the public ip address of the worker node.
Does anyone else have this problem?
Thanks
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
