")
Introduction
Anyone who’s spent time generating images knows just how finicky image generation models can be about prompts. You’ll write what you think is a reasonable description, but the generated image doesn’t always match your vision. Even asking an LLM to refine your prompt gives you a verbose paragraph that sometimes does the trick. As a result, improving the quality of instruction-based image editing - that is, enhancing the model’s ability to adhere to prompts, is an active area of research.
Prerequisites
The goal of this tutorial is to give readers both an overview and implementation details of In-Context Edit (ICEdit), a technique that seeks to ameliorate the performance of instruction-based image editing. Useful prerequisites may include some familiarity with using image-generation models as well as language model concepts such as zero-shot prompting. We will be using DigitalOcean GPU Droplets to launch the gradio interface to allow you to play around with an ICEdit implementation. Feel free to skip sections that aren’t of use to you.
In-Context Edit (ICEdit)
Instruction-based image editing allows users to modify images with natural language, but existing approaches typically trade off precision for efficiency. Finetuning-based approaches achieve accuracy but require thousands to millions of examples and heavy computation, whereas training-free methods, such as manipulating attention weights, avoid that cost but often misinterpret complex instructions. ICEdit seeks to bridge this gap by leveraging a large pretrained Diffusion Transformer (DiT) to handle both the source image and editing prompt in one unified process.
Overview of Key Innovations
The paper, “In-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer” introduces three key innovations that together yield state-of-the-art results with minimal training:
In-Context Editing
In-context editing is described as formulating editing as a conditional generation task by feeding the source image and edit instruction simultaneously (a diptych-style prompt) to the DiT. This zero-shot approach requires no new network modules and already achieves instruction compliance through the model’s built-in contextual attention.
LoRA-MoE Hybrid Tuning
A parameter-efficient fine-tuning scheme where low-rank adapter (LoRA) modules are arranged as a mixture-of-experts. Here, a small gating network dynamically routes each task to the appropriate expert. This is very efficient as it enables diverse edits to be learned from only 50K samples while tuning ∼1% of the model parameters.
VLM-Guided Noise Selection
An inference-time trick that generates a few initial noise seeds, runs only a few diffusion steps on each, and uses a Vision Language Model (VLM) to pick the seed whose partial output best matches the instruction.
We’re going to go into more detail for those interested. Skip to the implementation section if you’d like to play around with the model.
In-Context Editing via Diffusion Transformers
At the core of ICEdit is a diffusion transformer (DiT) model, specifically the FLUX.1 Fill DiT (12B parameters). DiTs combine diffusion model generation with transformer attention, so that image and text inputs can be jointly attended to. The authors formulate in-context edit prompts (IC prompts) that contain both the reference image and the text instruction side by side, which they compare to a “diptych.”
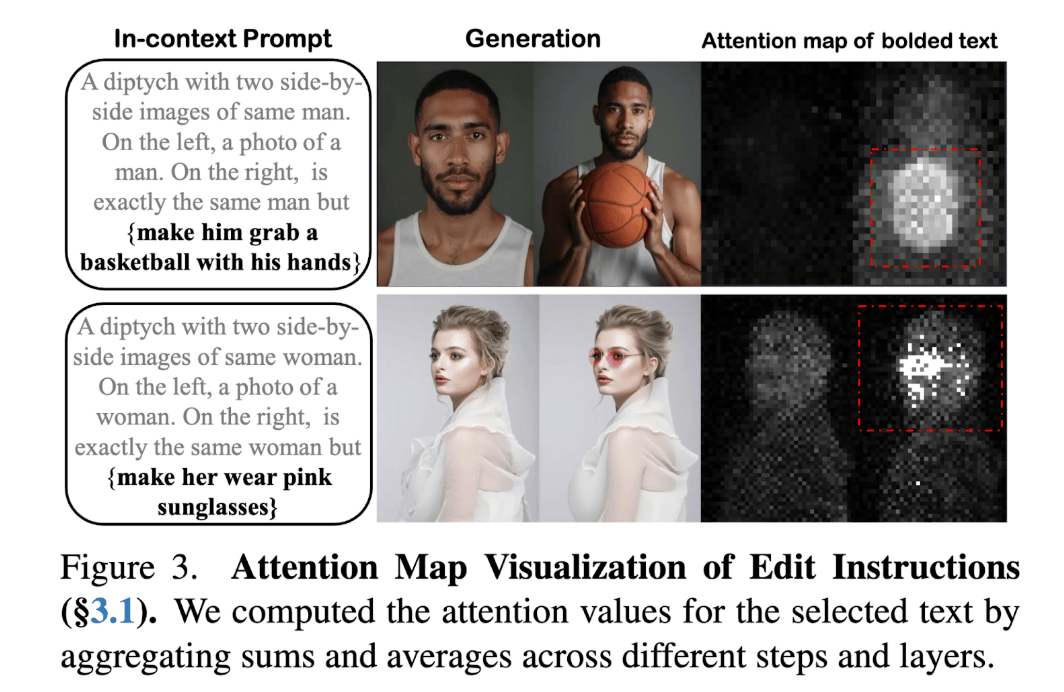
Here, the left half of the input is the source image (the “reference”), and the right half is initially masked or noisy. The edit instruction (e.g. “make him grab a basketball with his hands”) is encoded with a T5 text encoder and appended to this input. The DiT then treats the task as generation: it reconstructs the left image (ensuring identity consistency) and simultaneously fills in the right side according to the instruction.
This in-context method has two major benefits: (1) No architectural changes: it avoids adding separate “reference encoders” or extra modules, since the DiT’s self-attention inherently processes the image half as context. (2) Tuning-free compliance: even without any additional training, the DiT often correctly localizes and applies the edit. The paper shows that attention maps on the edit prompt focus on the target region, indicating the model interprets the instruction as part of the context. In other words, by framing editing as a conditional generation on a diptych input, the pretrained DiT can follow instructions out of the box.
LoRA-MoE Hybrid Fine-Tuning
To improve precision on difficult edits while maintaining efficiency, the researchers decided to incorporate a fine-tuning stage. They collect a compact editing dataset (~50K examples from MagicBrush and OmniEdit) and attach LoRA adapters to the DiT’s weights. LoRA inserts trainable low-rank matrices into the linear projections of the model, which can be tuned with only a fraction of the parameters. This step alone brings large gains: after LoRA tuning, the DiT better follows instructions and produces cleaner edits (e.g. consistently colouring or removing objects as directed). However, the authors note that different edit types require different transformations of the image features. A single LoRA solution (shared across all tasks) may not capture this diversity.
To address this, ICEdit introduces a Mixture-of-Experts (MoE) scheme for the LoRA modules. Instead of one adapter per layer, they insert multiple parallel LoRA “experts” (each with its own weight matrices) into the output projection of the multimodal attention block. A small routing network, conditioned on the current visual tokens and text embedding, decides which expert(s) to activate for each input. In practice they use a sparse MoE: only the top-k scoring experts (often k=1) are applied for a given sample, keeping computation low.
This LoRA-MoE design offers two key advantages: specialization and dynamic routing.
Specialization: Each expert adapter can specialize in a subset of editing behaviours (e.g. one expert might learn colour/style changes, another learns object insertion, etc.)
Dynamic routing: For each new instruction-image pair, the router selects the expert best suited to that task. As a result, the model can adapt on-the-fly to diverse editing requests without manual task switching.
The total added parameters remain small. The paper uses 4 experts of rank 32 in the DiT, which is roughly 1% of the full model parameters.
Empirically, this hybrid tuning yields substantial improvements over a single LoRA.
Post-tuning, ICEdit achieves state-of-the-art edit success rates across benchmarks while still avoiding full-model retraining. In essence, LoRA-MoE augments the in-context editing mechanism with learned expertise: the DiT retains its original architecture and data-free inference, but its outputs are now fine-tuned for precision on a variety of editing subtasks. This co-design of LoRA and MoE resolves the capacity limitations of lightweight tuning, enabling the model to express richer edit transformations.
VLM-Guided Noise Selection at Inference
The authors observe that the initial noise seed can drastically affect the edit outcome during inference, and that some seeds lead to much more accurate edits than others. In particular, they find that whether an edit is “working” often becomes evident after just a few diffusion steps. In light of this, they propose an early filtering strategy: sample multiple candidate seeds, run only a few diffusion steps (e.g. 4–10) for each, and then use a VLM to score which partial result best matches the edit instruction. The winning seed is then fully denoised to T steps to produce the final image.
In practice, ICEdit uses a large multimodal model (Qwen2.5-VL-72B - note the paper says Qwen-VL-72B, but we believe they omitted the 2.5 by accident) as the scorer. The selection is done by pairwise comparisons: start with seed 0’s K-step output and seed 1’s and have the VLM judge which is more in line with the instruction (via natural language prompts or embeddings). The winner is then compared to seed 2’s output, and so on, effectively performing a tournament to pick the best seed.
This VLM-guided approach ensures the final edit is aligned with the instruction. By eliminating poor seeds early, the model avoids wasting computation on bad trajectories and gains robustness against randomness.
Now that we’ve covered the approach, let’s dig into the implementation!
Implementation
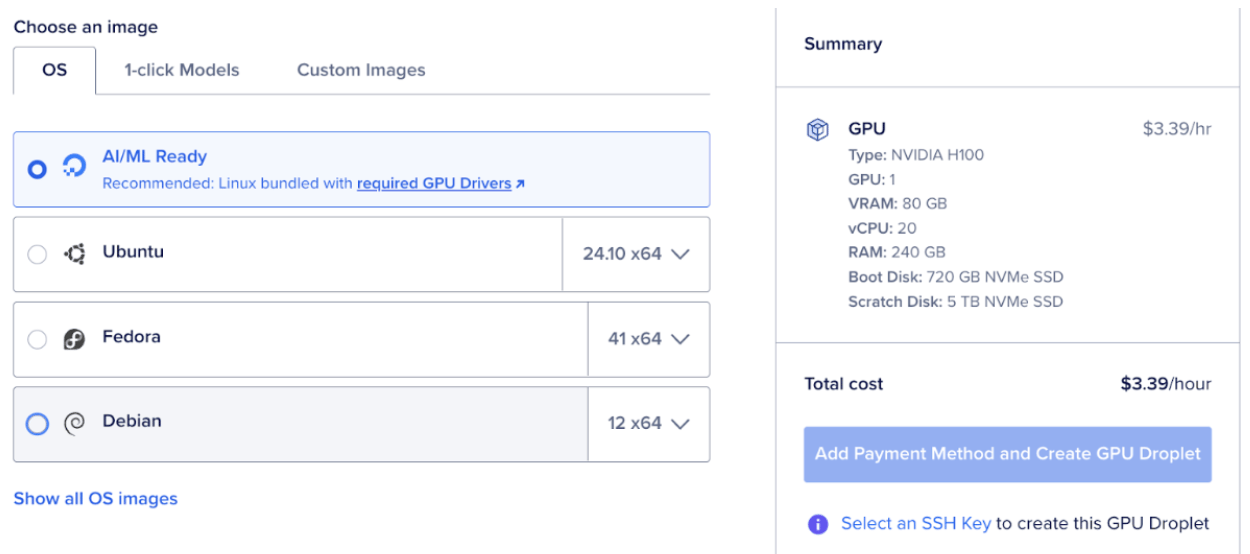
Step 1 : Set up a GPU Droplet
Begin by setting up a DigitalOcean GPU Droplet, select AI/ML and choose the NVIDIA H100 option.
Step 2: Web Console
Once your GPU Droplet finishes loading, you’ll be able to open up the Web Console.web console

Step 3: Install Dependencies and Clone the ICEdit Repo
In the web console, copy and paste the following code snippet:
apt install python3-pip python3.10-venv
git clone https://github.com/River-Zhang/ICEdit
Step 4: Navigate to the correct repository
cd ICEdit
Step 5: Install Requirements
pip3 install -r requirements.txt
pip3 install -U huggingface_hub
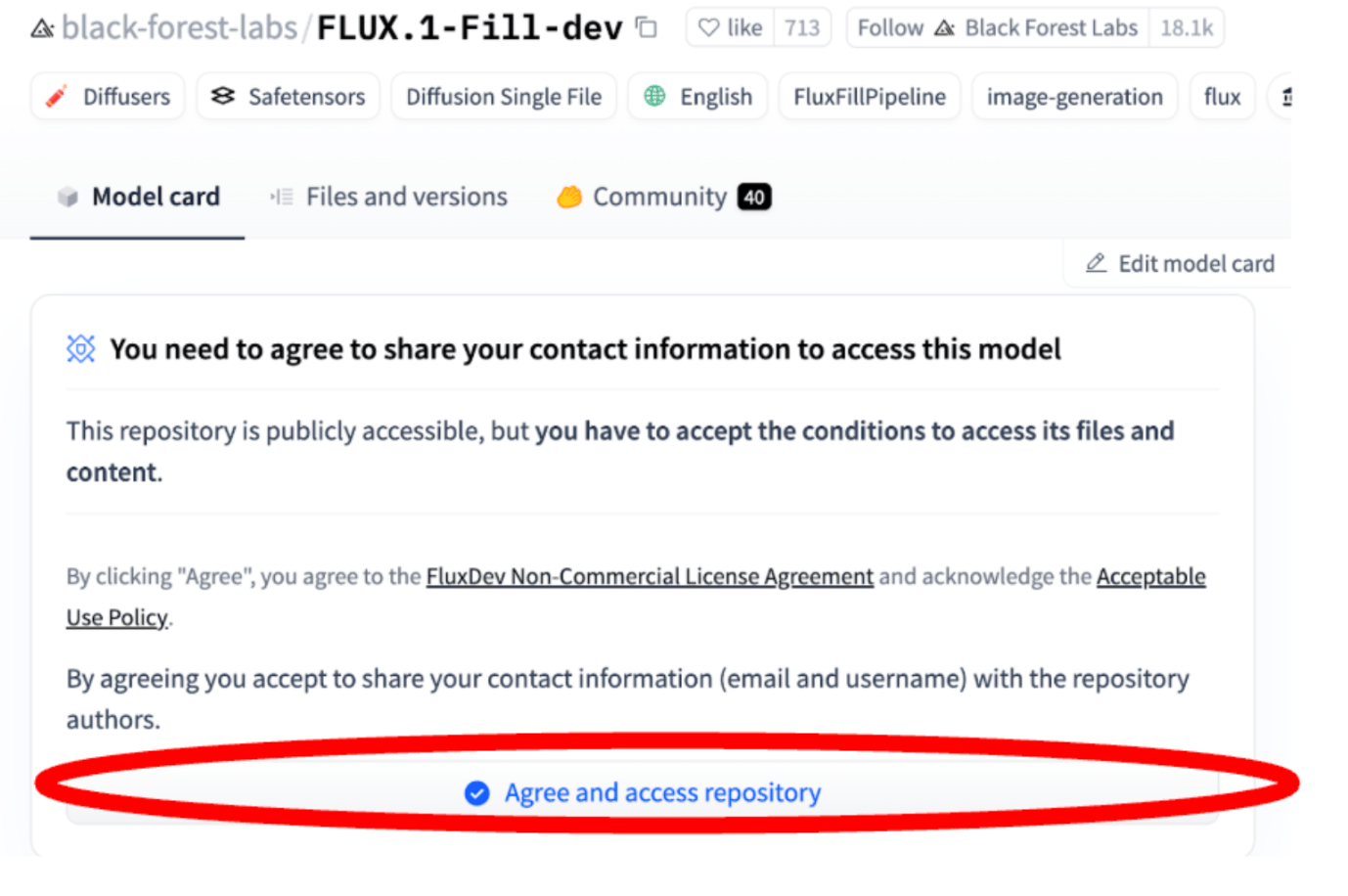
Step 6: Obtain Flux Model Access
Agree to the conditions for the FLUX model since it will be used in the gradio implementation.
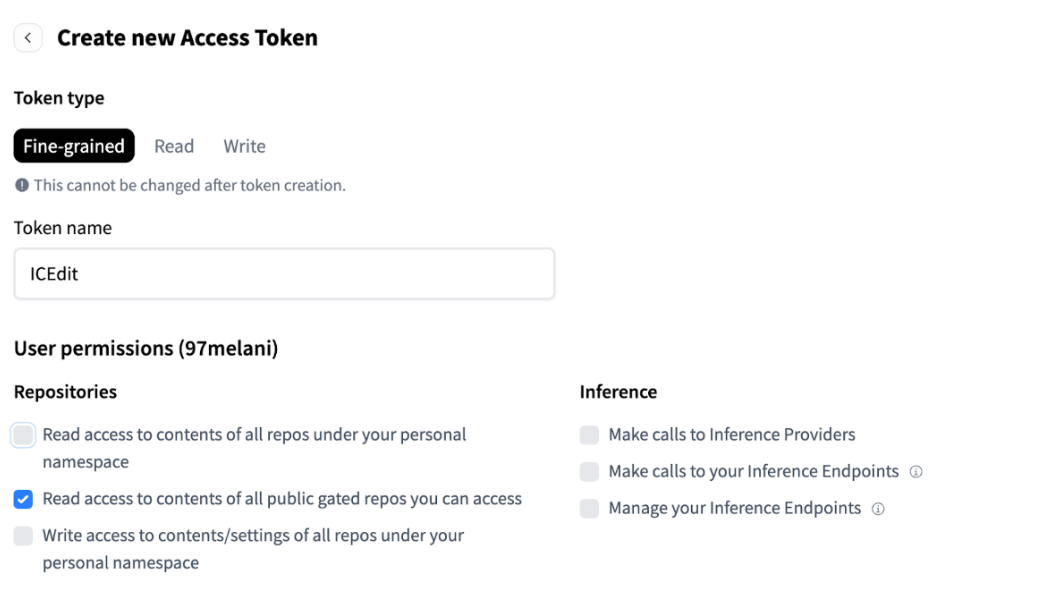
Step 7: Obtain Hugging Face Access Token
The HuggingFace token can be obtained from the Hugging Face Access Token page. Note that you may need to create a Hugging Face account. Ensure the appropriate boxes are selected before generating your token.
Step 8: Login to Hugging Face
huggingface-cli login
You will be prompted for your token at this step, paste it and follow the instructions on screen.
Step 9: Launch the Gradio app
python3 scripts/gradio_demo.py --share
There will be a share link which you can access from your browser.
Performance
Let’s take a look at how this model performs.
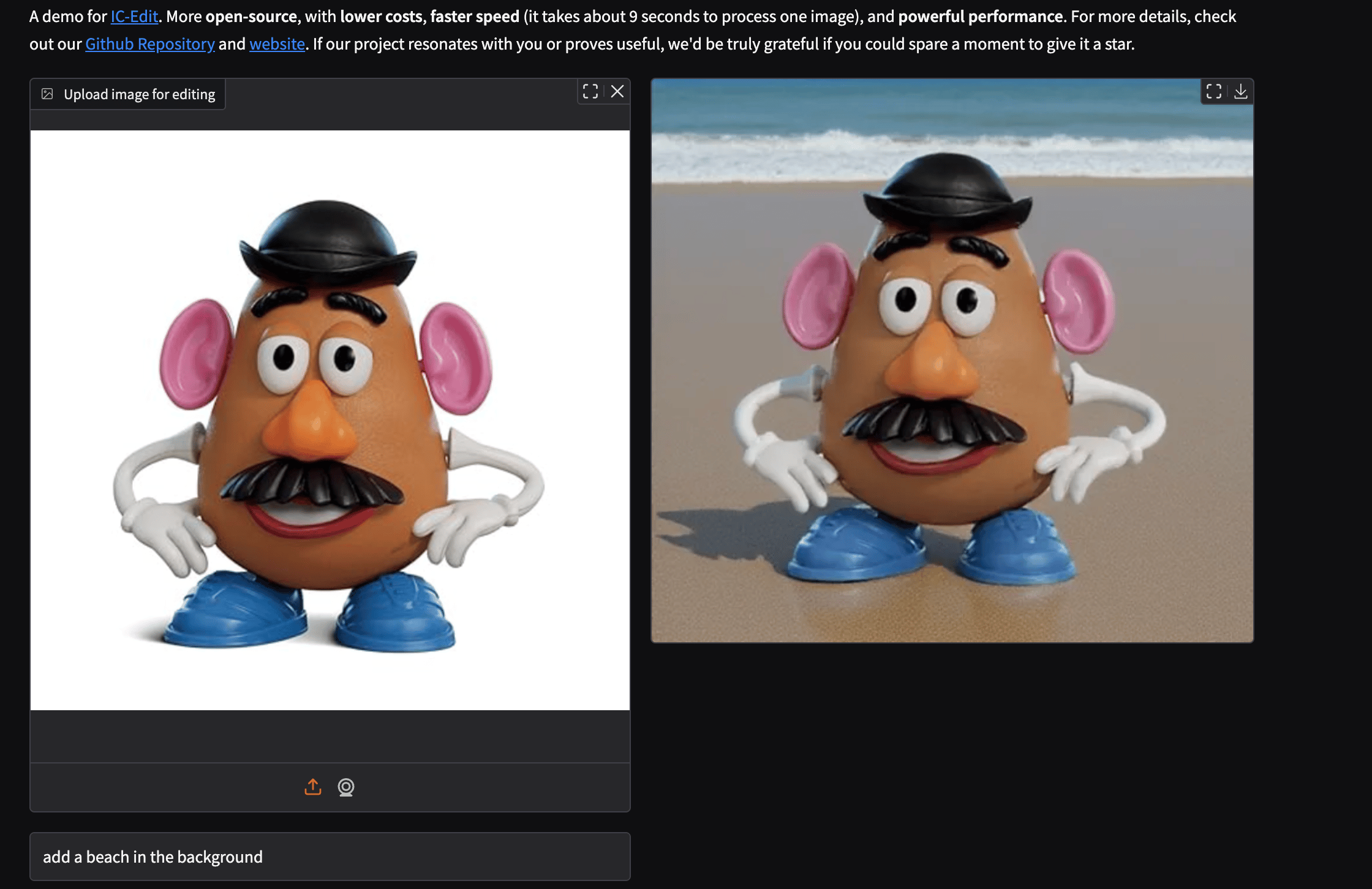

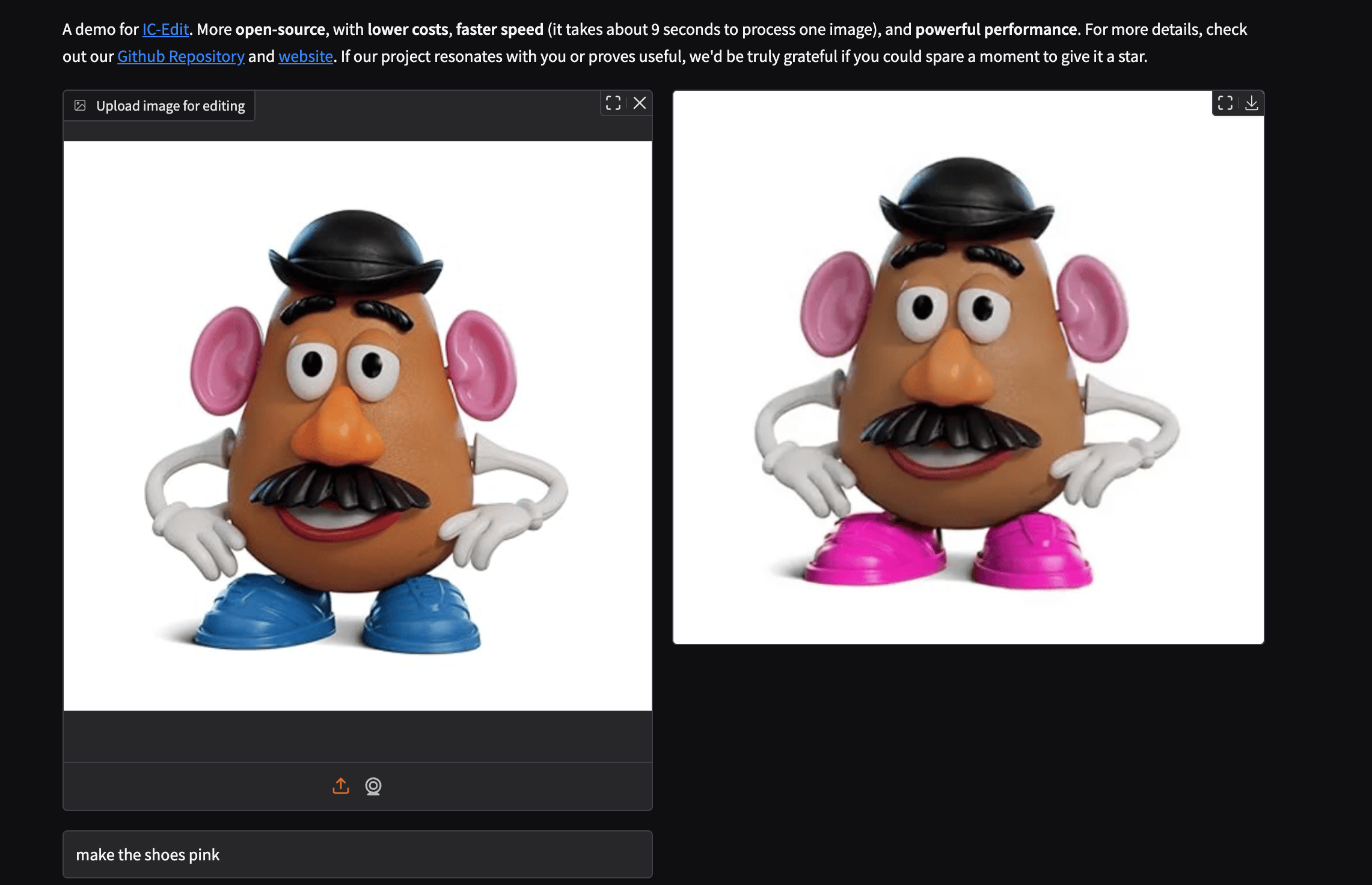
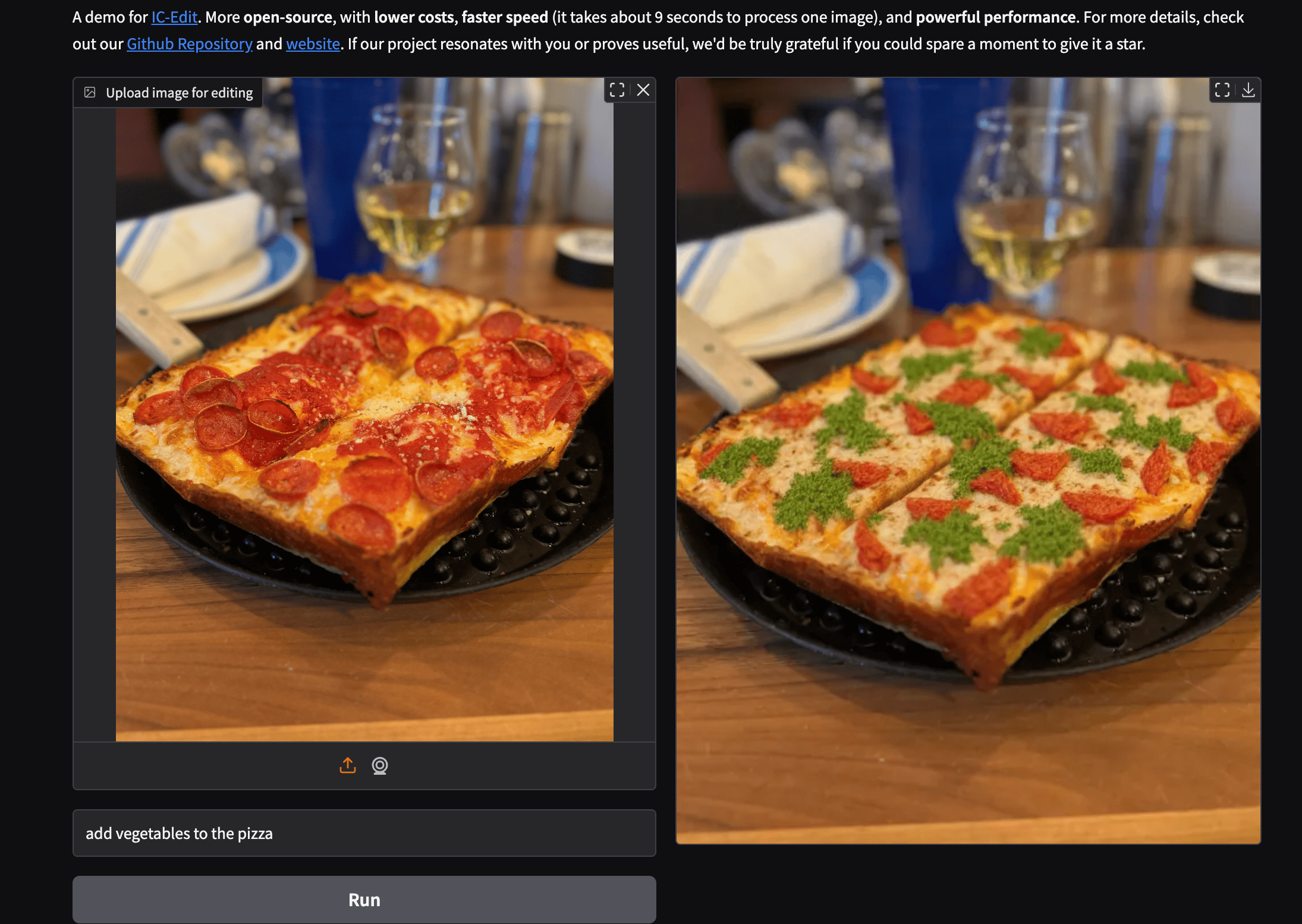
Based on the generated images - what are your thoughts on the model’s performance? Comment below.
Closing Thoughts
ICEdit, or In-Context Edit, offers a novel approach to instruction-based image editing by leveraging the power of Diffusion Transformers and innovative techniques like LoRA-MoE hybrid tuning and VLM-guided noise selection. These advancements significantly improve the model’s ability to adhere to complex instructions, leading to higher quality and more consistent edit results without extensive retraining, showcasing a promising direction for future image editing tools. We hope the implementation on DigitalOcean GPU Droplets went smoothly and you got a chance to play with ICEdit.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
