
Trees are hands-down the most common data structure that you already interact with. From your file system to the DOM, many of the things your computer does is entirely dependent on generating and manipulating trees.
What’s a Tree?
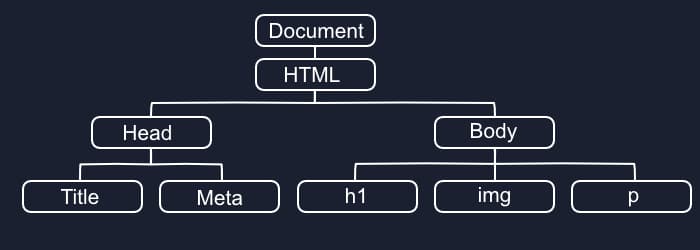
In short, a tree is a collection of nodes/values where each node points to descending nodes and all connect to a single parent node. Let’s look at the tree you’re probably most familiar with: the DOM.
At the root of the tree we have the document (actually the window but shhh) and every HTML tag we add creates a new child node under it. The main point about trees is that no matter how many nodes we have we could pick anyone at random and always be able to trace our way back to the root or any other element.
Valid vs Invalid Trees
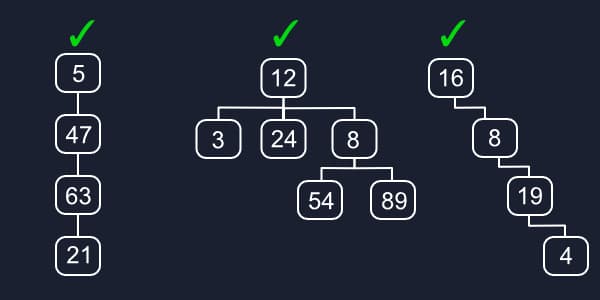
Previously, when we created linked lists we were technically already making viable trees because they have a root (the head/tail) and each node was connected to a child with the next/prev pointers. Starting from any node we could always find our way back to a single root, but it’s a bit trivial with just a single chain of nodes.
All of these are valid trees. Most of our different structures based off of trees will be pertaining more with how the data inside the trees are organized, but they’ll all look something like this.
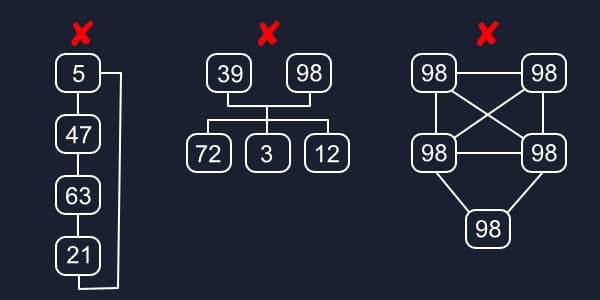
There are some rules we need to follow to have a proper tree. A tree cannot reference its own root, for example if we ran a traversal algorithm on a circular linked list then it would quickly become a recursion nightmare. We also can’t have more than one root or a node with more than one parent.
Finally, a tree must have a directionality to it with everything moving out from the root. A cluster of nodes without a direction is actually its own much more complicated structure, graphs, which we’ll cover in future articles 😉.
We can’t just start linking nodes together and call it a tree, if we break these rules then future data structures and algorithms just won’t be possible.
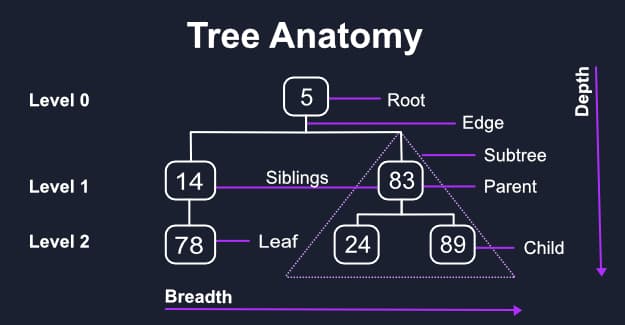
Tree Anatomy
While pretty boring it’s still necessary to cover the most important terminology you’ll constantly see as you learn more about trees.
Node- Each single object or data point.Root- The first and uppermost node in the tree from which all other nodes are derived from.Edge- A connection between two nodes.Parent- The immediate ancestor of a lower node.child- The immediate descendant of a higher node.Siblings- Two nodes on the same depth with the same parent.Leafs- The bottommost nodes with no children.Depth- The height of the tree measured in levels with the number of edges away from the root, so level 2 is only two edges away from the root.Breadth- The width of the tree measured by the number of leafs.Subtree- A node and its descendants which could be treated as an independent tree. For example, if we created a dictionary as a tree and used a search algorithm that looked at each item alphabetically we could use the node for section of the first letter as the root instead of looking at every item in the tree.
Closing Thoughts
Right now this may seem like a whole lotta fluff but the devil really is in the details. As you progress to more elaborate structures it’ll become increasingly easier to overlook these details and drown yourself in very hard to debug errors.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
This is a solid introduction to tree data structures, but it seems to be missing the JavaScript part of “Exploring Trees via JavaScript.”
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
