
Introduction
Agentic intelligence is a paradigm in artificial intelligence that focuses on creating autonomous entities, or “agents,” capable of perceiving their environment, reasoning about their observations, making decisions, and taking actions to achieve specific goals. This approach emphasizes the ability of AI systems to operate independently, adapt to changing conditions, and learn from their experiences, often without constant human oversight. Kimi K2 is a 1T parameter open-weight model designed for agentic use – achieving state-of-the-art performance in frontier knowledge, math, and coding.
Model Overview
| Spec | Relevance |
|---|---|
| Mixture of Experts | The Mixture of Experts (MoE) architecture allows for greater model size and quality while reducing compute costs. It uses sparse Feedforward Neural Network (FFN) layers (experts) and a gate network (router) to selectively route tokens to top-k experts, activating only a subset of parameters per token. This approach enables larger models without proportionally increasing computational costs. |
| 1 trillion total parameters, 32 billion active parameters | As K2 is a MoE architecture, there are total and active parameters. Total parameters refers to the sum of all parameters across the entire model, including all expert networks, the router/gating network, and shared components, regardless of which experts are used during inference. This contrasts with active parameters, which only counts the subset of parameters utilized for a specific input - typically the activated experts plus shared components. |
Multihead Latent Attention (MLA) 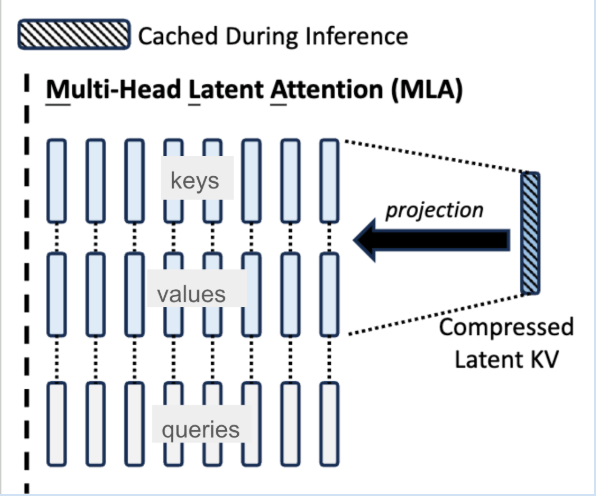 |
MLA was introduced by DeepSeek V2 (Section 2.1) as an attention mechanism to boost inference efficiency. 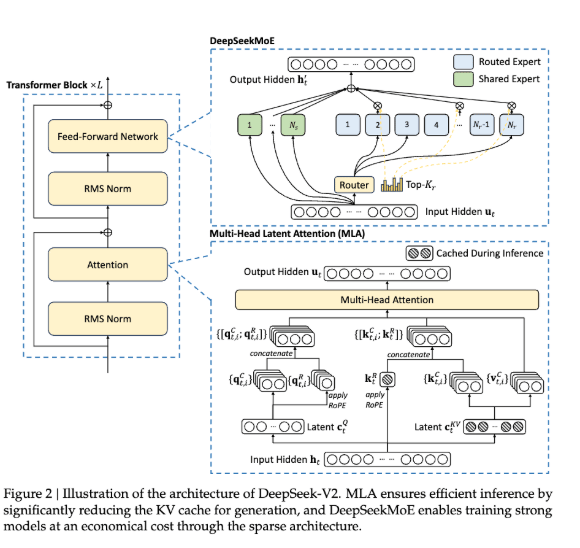 MLA works by compressing the attention input into a low-dimensional latent vector which can be later calculated by recovering the keys and values. Due to the use of MLA in K2, QK-Norm is not applicable to scaling up Muon training since the key matrices in MLA are not fully materialized during inference. As a result, the K2 researchers incorporated QK-Clip, a weight-clipping mechanism to constrain attention logits that arise with large-scale Muon-optimized training. MLA works by compressing the attention input into a low-dimensional latent vector which can be later calculated by recovering the keys and values. Due to the use of MLA in K2, QK-Norm is not applicable to scaling up Muon training since the key matrices in MLA are not fully materialized during inference. As a result, the K2 researchers incorporated QK-Clip, a weight-clipping mechanism to constrain attention logits that arise with large-scale Muon-optimized training. |
| MuonClip optimizer | Muon, while a token-efficient optimizer, needs to be modified for large-scale training. The MuonClip optimizer, introduced in Section 2.1 of the Kimi K2 tech report, is Muon integrated with weight decay, consistent RMS matching, and QK-Clip. |
Prerequisites
We encourage you to read the Kimi K2 tech report alongside this article for more information and context. Reading about DeepSeek V3 may also be useful, but not necessary, as the Kimi K2 architecture is similar, employing Multihead Latent Attention with a model hidden dimension of 7168 and an MoE expert hidden dimension of 2048.
The figure below from the K2 tech report also demonstrates architectural similarities and differences between Kimi K2 and DeepSeek-V3.

The goal of this article is to flesh out key details and make the content more digestible for you. Unlike this article, the tech report goes through the process (pre & post-training, infrastructure, evals) in more of a sequential fashion. Here, we try to group concepts by their role in Kimi K2’s overall performance. We opted to not cover evals in depth, but definitely check Section 4 of the tech report and try the model out for yourself to get a better understanding of its performance.
There are several objectives that influenced the way Kimi K2 was developed:
- Reduce overfitting
- Decrease validation loss
- Maximize token efficiency
- Managing instabilities during training
- Handling long contexts to improve performance on context-driven agentic tasks
- Increasing inference efficiency to reduce latency of model generations
We’re going to go into more detail how the researchers addressed these goals.
Reduce overfitting
A low validation loss indicates that the model’s learned features and patterns generalize beyond the training data. This is the metric that researchers and AI practitioners often monitor when making model architectural decisions such as increasing sparsity.
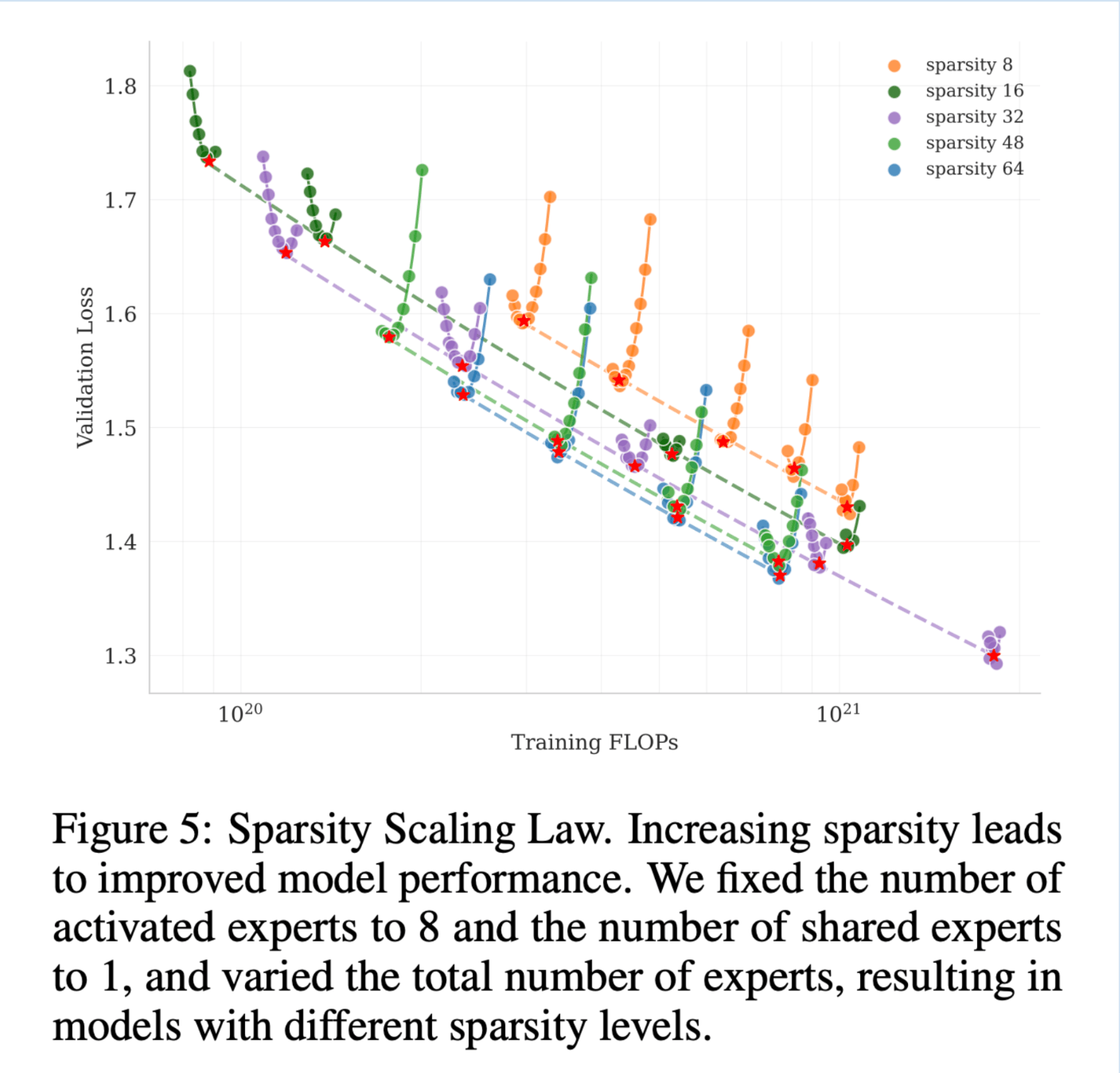
Sparisity
Sparsity is calculated as the total number of experts divided by the number of experts that are activated. Kimi K2 increased the sparsity from DeepSeek-V3 by increasing the total number of experts, resulting in sparsity of 48 (384/8). This value was chosen to balance performance (a lower validation loss) with the increasing infrastructure complexity that higher sparsity brings.

Maximizing Token Efficiency
Token efficiency is how much performance is improved for each token consumed during training.
We care about token efficiency because the supply of high-quality tokens is limited and therefore must be maximally utilized. The researchers explain that repeated exposure (more epochs) to the same tokens is ineffective as it can lead to overfitting and reduced generalization. This motivated them to rephrase high-quality tokens that fall under the Knowledge and Mathematics domains.
Rephrasing >>> More Epochs???
Knowledge Data Rephrasing
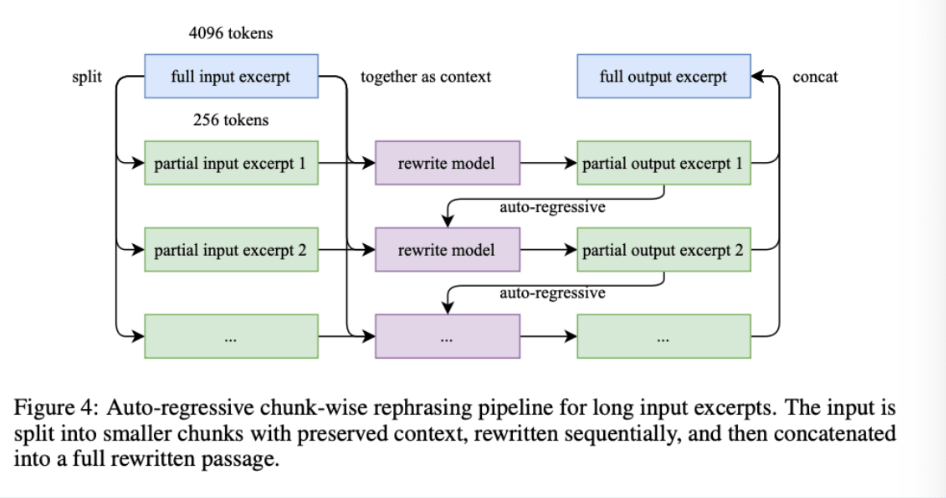
To achieve increased generalization on knowledge tokens, the researchers designed a “rephrasing pipeline” with three core elements: prompts designed to generate stylistically diverse yet factually accurate text variations, segmented autoregressive rewriting to better preserve coherence and prevent information loss in long documents (depicted below), and verification of “semantic alignment” for each generated segment with its source.
The researchers used SimpleQA to assess the effectiveness of augmenting data by rephrasing. It seems rephrasing with 1 epoch outperforms 10 epochs.

Mathematics Data Rephrasing
Mathematical documents are rewritten into a “Learning-note” style, following the swallow math approach presented in the paper, Rewriting Pre-Training Data Boosts LLM Performance in Math and Code.
Muon
The primary objective of an optimizer is to minimize the “loss function,” which quantifies the difference between the model’s predictions and the actual desired outputs. By systematically adjusting parameters, optimizers enhance the model’s overall performance, accelerate its learning convergence, improve accuracy, and help prevent issues like overfitting.
Muon (MomentUm Orthogonalized by Newton-Schulz) is an optimizer that updates 2D neural network parameters in two steps: it first generates updates using SGD (Stochastic Gradient Descent)-momentum, then refines these updates with a Newton-Schulz iteration before applying them to the parameters.
Moonlight is a 3B/16B (activated/total) parameter MoE model trained with 5.7 TRILLION tokens - making this the first large scale model trained with Muon.
While Muon demonstrated strong results training small scale language models, the researchers in Muon Is Scalable For LLM Training showed that Muon can be scaled up by adding weight decay and carefully adjusting the per-parameter update scale.
However, a persistent challenge observed when scaling up from Moonlight is the training instability observed with exploding attention logits. Appendix E of the tech report explains why Muon is more prone to logit explosion.
Managing Instabilities During Training
MuonClip
Perhaps the effectiveness of MuonClip can be best explained by the figure below.
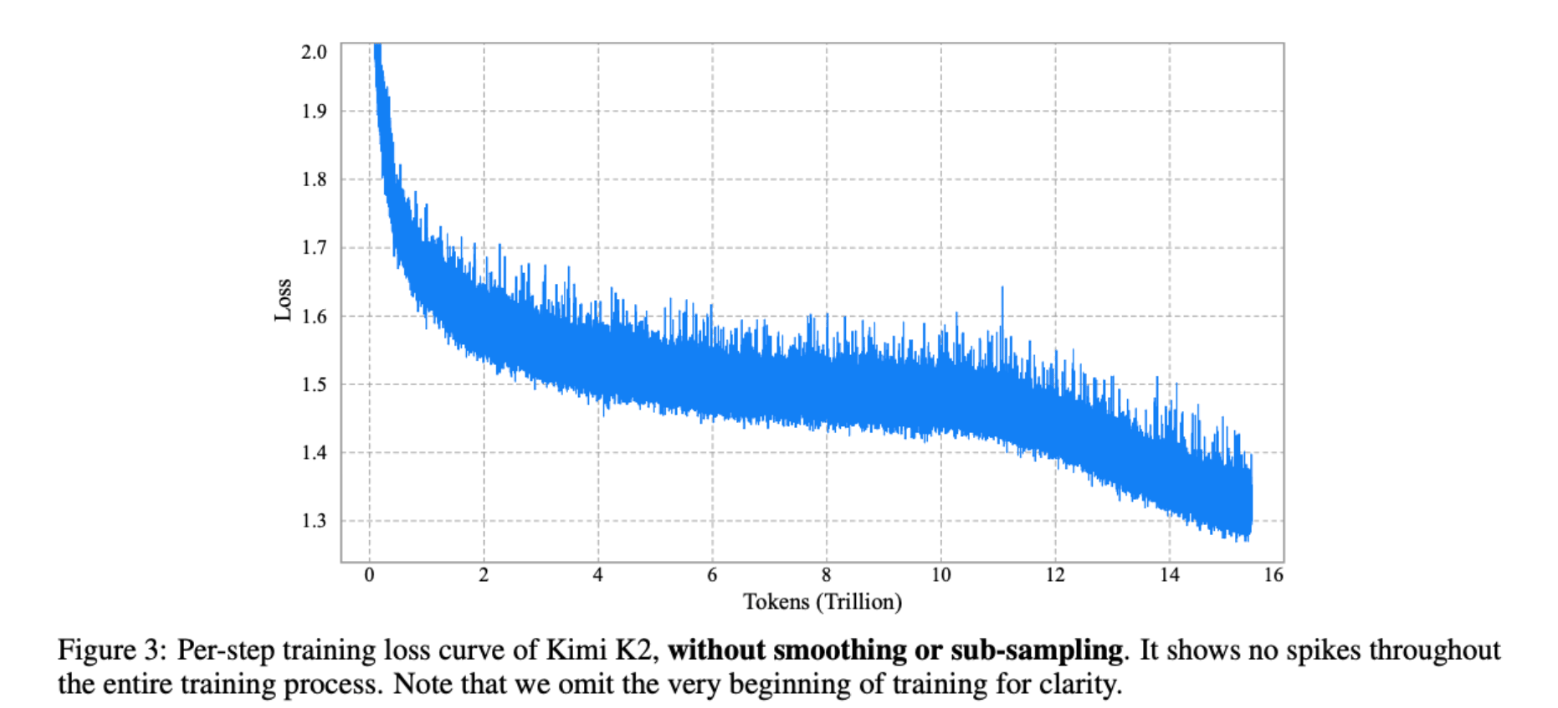 MuonClip improves LLM training by capping attention logits, leading to smoother loss curves and eliminating spikes.
MuonClip improves LLM training by capping attention logits, leading to smoother loss curves and eliminating spikes.
Flexible Training Infrastructure
To understand section 2.4 of the tech report, we recommend The Ultra-Scale Playbook: Training LLMs on GPU Clusters from Hugging Face. This resource provides valuable insights into parallelism strategies (including expert, pipeline, and Zero-1 Data parallelism), the large memory requirement for activations, an explanation of selective recomputation, the benefits of 1F1B scheduling in optimizing memory usage and overlapping communication and computation, as well as mixed precision training.
Increasing Inference Efficiency
Reducing number of attention heads
Agents often need to consider large amounts of context, previous interactions, and detailed instructions. It is clear that the focus of Kimi K2 is on agentic use cases due to their prioritization of inference over the marginal performance improvements of more attention heads.
Given the performance gains of a sparsity of 48 and the significant inference overhead that comes with more attention heads at increased sequence lengths, the researchers opted for 64 attention heads as opposed to the 128 attention heads in the DeepSeek V3 paper.
RL Infra
This is really interesting. Here, the training and inference engine are on the same worker -where we have the engine that’s not running offloading its GPU resources to accommodate the engine that is actively working. During each RL training iteration, the inference engine generates new data for training.
Agentic Data Synthesis
Kimi K2’s capabilities come from large-scale agentic data synthesis and reinforcement learning. Its ACEBench inspired pipeline simulates tool-use scenarios, creating domains with tools and agents that interact in multi-turn scenarios evaluated against rubrics by an LLM judge. This process generates training data for the model.
 Figure from Kimi K2 launch blog post
Figure from Kimi K2 launch blog post
Additional Information/ Resources
Many of these are also cited in the K2 paper:
Muon: An optimizer for hidden layers in neural networks | Keller Jordan blog
Kimi K1.5: Scaling Reinforcement Learning with LLMs : A decent amount of detail omitted in the Kimi K2 paper can be found in the Kimi K1.5 paper due to overlap in methodology. K1.5, being the predecessor to Kimi K2, includes the data processing pipelines (Appendix B) that were used to process the K2 pre-training 15.5 TRILLION token corpus.
Here, we learn about the different domains of the pre-train corpus (English, Chinese, Code, Mathematics & Reasoning, and Knowledge).
Appendix C has descriptions of the benchmarks used to evaluate the model such as LiveCodeBench, AIME 2024, etc.
DeepSeek-V3 Explained 1: Multi-head Latent Attention: This blog post does a great job of explaining MLA.
Conclusion
Kimi K2’s technical report is an excellent resource for those curious about what goes into training massive MoE agentic models. There’s a clear focus on long contexts, inference efficiency, training stability, data augmentation, and reinforcement learning. There are some sections we did not fully flesh out but may explore in subsequent articles – specifically pertaining to post-training such as training agentic models to use tools and how reinforcement learning was leveraged. Stay tuned!
We hope you find this article helpful. Happy learning!
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
