AI Technical Writer

Introduction
Large Language Models (LLMs) have transformed AI by powering tasks like summarization, translation, and code generation. These models rely on token-based processing—breaking down text into subwords or characters to understand and generate content. While effective, this approach is limited in mimicking how humans reason and communicate through abstract, high-level concepts.
Meta’s paper, “Large Concept Models: Language Modeling in a Sentence Representation Space”, proposes a fundamental shift. The paper suggests of processing concepts instead of tokens. Large Concept Models (LCMs) operate in conceptual embedding spaces, redefining how language models understand, represent, and generate meaning.
Key Takeaways
- Concept over Tokens: LCMs move away from traditional token-by-token processing and instead focus on understanding and generating language at the conceptual level.
- Better Long-Context Understanding: By reasoning with broader ideas, LCMs handle longer text inputs more effectively than current models.
- Improved Reasoning Abilities: Their structure supports more advanced, layered thinking—helpful for tasks requiring logical steps and deep understanding.
- Closer to Human-Like AI: Meta’s research brings us closer to AI systems that think more like humans, making interactions smoother, smarter, and more intuitive.
From Tokens to Concepts
The Role of Tokenization in LLMs
In traditional LLMs like GPT-4, tokenization is the first step. For instance, the sentence “Will tokenization eventually be dead?” is split into subword tokens like "Will", "token", and "ization". These tokens are then fed into a Transformer model to generate a response.
The Problem
However, this approach:
- Splits meaningful expressions into fragmented parts
- Operates on arbitrary units, ignoring semantic cohesion
- Struggles with long-context reasoning and hierarchical planning
The Solution: Concepts
Concepts refer to higher-order representations of meaning. They’re not tied to language-specific tokens and can be derived from text, speech, or even multimodal signals. LCMs process sentences as unified semantic units—concepts—which enables:
- Better handling of long contexts
- More abstract reasoning
- Language and modality independence
What Are Large Concept Models?
Traditional AI models like ChatGPT work by predicting the next word (called a “token”) based on the previous ones. But humans don’t think like that—we think in full ideas or sentences and build up meaning in layers.
A Large Concept Model (LCM) is a new type of AI model that goes beyond traditional Large Language Models (LLMs), which operate at the word or token level. Instead of focusing on predicting the next word, LCMs work with higher-level abstract ideas or “concepts”, like full sentences or meanings, to understand and generate content.
This process is much inspired by how humans think and plan—first outlining ideas and then filling in details. LCMs use a hierarchical reasoning approach. This means they first grasp the bigger picture and then focus on specifics, allowing for more coherent and structured outputs. Unlike current LLMs, which are mostly English-based and data-heavy, LCMs aim to be more efficient and language-independent by using sentence-level embeddings like SONAR.
How Do LCMs Work?
LCMs follow a three-step pipeline:
-
Concept Encoder (SONAR): Input (text or speech) is broken into sentences. Each sentence is turned into a “concept embedding” using a tool called SONAR (which works in 200 languages and supports text + speech).
-
Large Concept Model (LCM): A Transformer operating entirely in concept space. It reasons over the concept sequence to generate output concepts. The concept embeddings are processed by the LCM to perform a task, like summarizing or translating. The result is a new set of concept embeddings.
-
Concept Decoder (SONAR): Translates concept embeddings back into natural language (or speech) output.
The reasoning step happens only on concepts—not words or tokens—so the model doesn’t need to care about the input/output language or whether it’s speech or text.
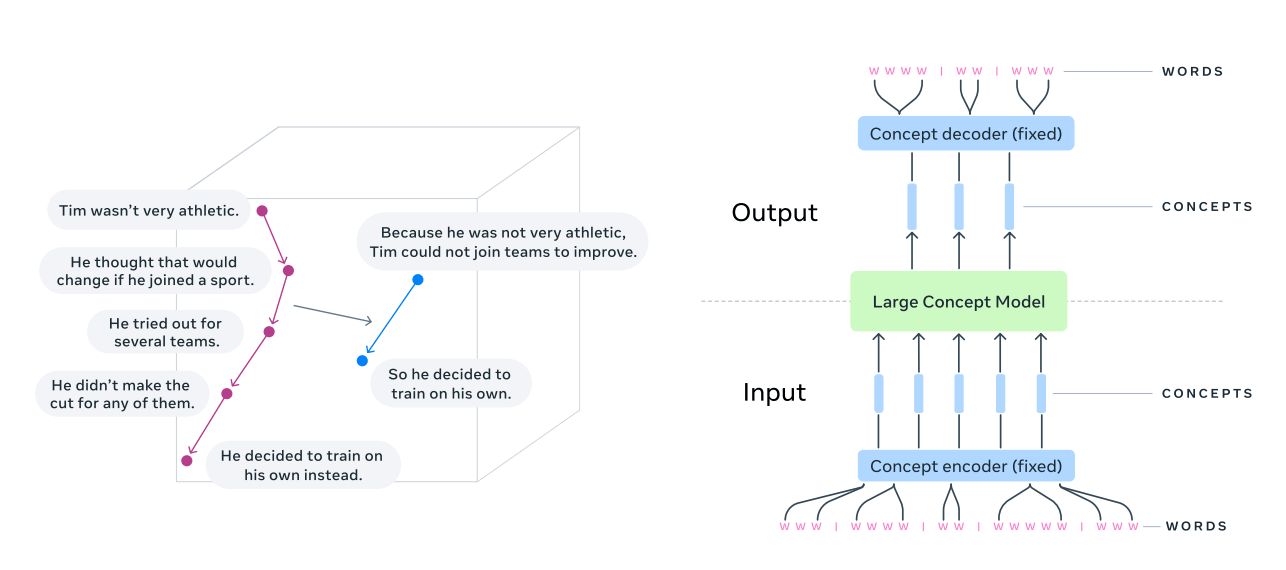
This architecture resembles the Joint Embedding Predictive Architecture (JEPA), which also promotes abstract reasoning across modalities.
Why is this approach better?
This approach can handle any language or speech/text input without needing extra training. It’s much faster and less resource-intensive than traditional LLMs because it works with fewer, more meaningful chunks (concepts instead of tokens). Further, it also supports zero-shot generalization: you don’t have to retrain it for every language or task.
The SONAR embedding space
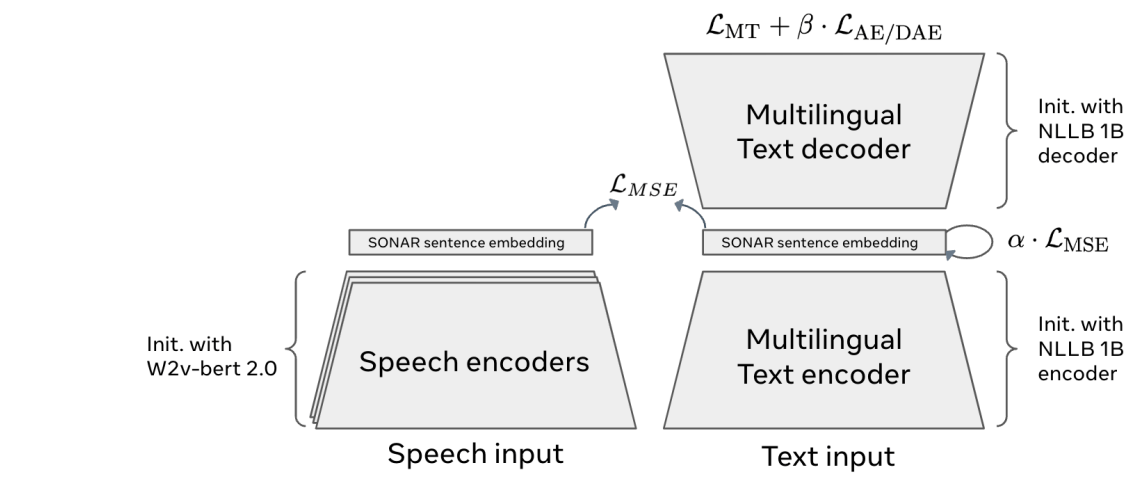
The motivation behind this work is to enable reasoning at a higher, more meaningful level than individual words or tokens. To achieve this, the authors use SONAR—a powerful embedding system that represents entire sentences as semantic concepts. SONAR was trained using machine translation, denoising, and similarity objectives across 200 languages, and it performs exceptionally well on semantic similarity tasks. It also extends to speech through a teacher-student approach, supporting 76 languages for speech input and English for speech output. Because the Large Concept Model (LCM) operates directly on these SONAR concept embeddings, it can perform reasoning across multiple languages and modalities, including an experimental encoder for American Sign Language. This makes LCMs more inclusive, efficient, and scalable than traditional LLMs.
Base-LCM: A Naive Approach
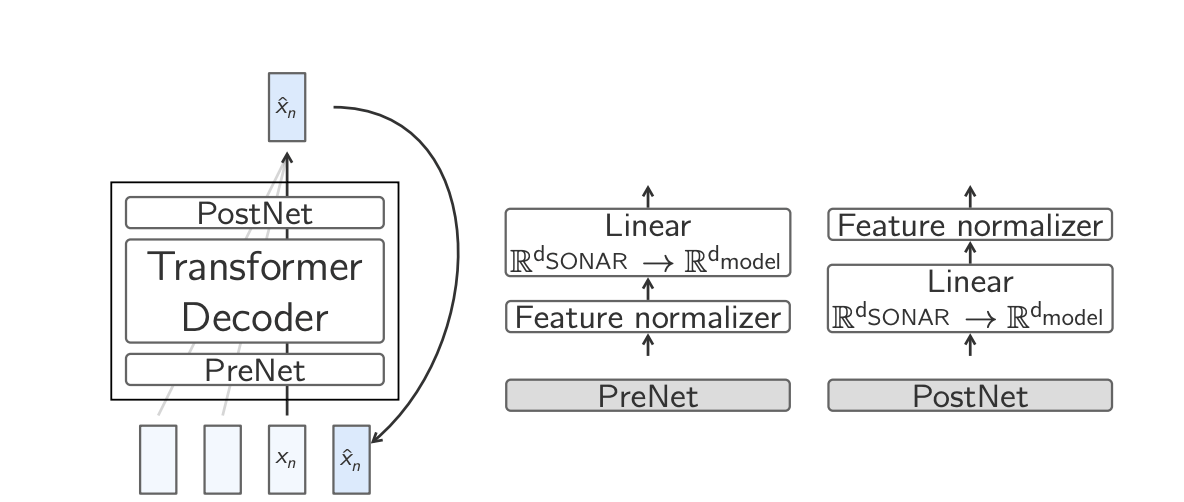
The Base-LCM is a model designed to generate sentence-level embeddings (representing full ideas or concepts), instead of predicting one word at a time like current language models. It works by learning how to predict the next sentence embedding given previous ones, like continuing a conversation or paragraph, but at the idea level.
To do this, the model uses SONAR embeddings, which represent full sentences in a continuous space. However, since these embeddings are very different from the internal format used by the model, they are normalized and mapped into the model’s hidden space using a “PreNet.” After generating new embeddings, they’re converted back using a “PostNet.”
Training this model means teaching it to guess the next sentence’s embedding as accurately as possible—this is done by minimizing the mean squared error (MSE) between what it predicted and the true next embedding. To help it know when to stop generating during real use, the model is trained to recognize an “End of text” sentence, and it stops generating if it sees that or if the new sentence embedding is too similar to the previous one.
Additionally, because a sentence can have many valid next ideas (just like how many pictures can match one prompt in DALL·E), the authors are also exploring diffusion models and quantization to better handle the uncertainty in next-sentence generation.
Limitation
The Base-LCM assumes a single “correct” next concept, which is unrealistic since many plausible conceptual continuations may exist in context.
Diffusion-Based LCMs: Better Handling of Ambiguity
Why Diffusion?
Inspired by diffusion models in image generation, LCMs use a similar approach to predict a distribution over possible next concepts, rather than a single fixed one. Diffusion-based LCMs are advanced models that generate sentence-level concepts (embeddings) by gradually transforming random noise into meaningful sentences, similar to how diffusion models generate images.
They do this in two steps: first, they add noise to clean data (the “forward process”) using a schedule that controls how much noise is added over time. Then, during generation (the “reverse process”), they learn to remove that noise step by step to recover the original sentence embedding. This reverse process is guided by learned patterns in the data and can be either conditional (based on the previous context) or unconditional. The model uses special noise schedules—like cosine, quadratic, or sigmoid—to control how it learns at different noise levels. During training, it learns how to reconstruct the original data from noisy versions using simple or weighted losses.
At inference, various techniques like classifier-free guidance, step selection, and error-scaling help improve the quality and diversity of the generated sentences. Two architectures—One-Tower and Two-Tower—are proposed for implementing this diffusion-based reasoning.

Two Architectures
One-Tower Diffusion LCM
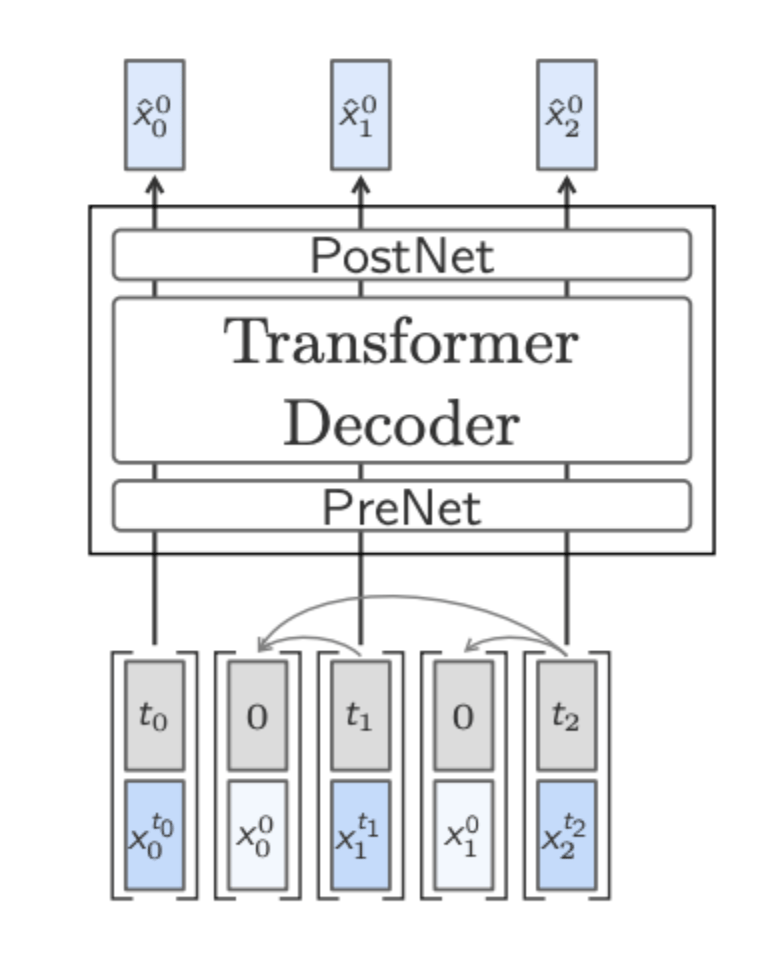
The One-Tower diffusion LCM is a model designed to predict clean sentence embeddings (representations of sentences) from their noisy versions, using a single Transformer. During training, it receives a mix of clean and noisy sentence embeddings as input. These embeddings are interleaved (i.e., placed alternately) so that the model sees both types but is instructed to only focus on the clean ones when making predictions. Each noisy embedding also includes information about how much noise was added (the “diffusion timestep”), which is appended to the input. The model uses causal attention—meaning it can only look at previous sentences, not future ones—to maintain the natural flow of text. Sometimes, parts of the model are trained without context (unconditional) so that later, during inference, it can balance between following context and being creative (using classifier-free guidance). This approach allows the model to efficiently learn to denoise and generate entire sequences of sentence embeddings all at once.
Two-Tower Diffusion LCM
The Two-Tower diffusion LCM separates the job of understanding the context from the task of generating the next sentence embedding.
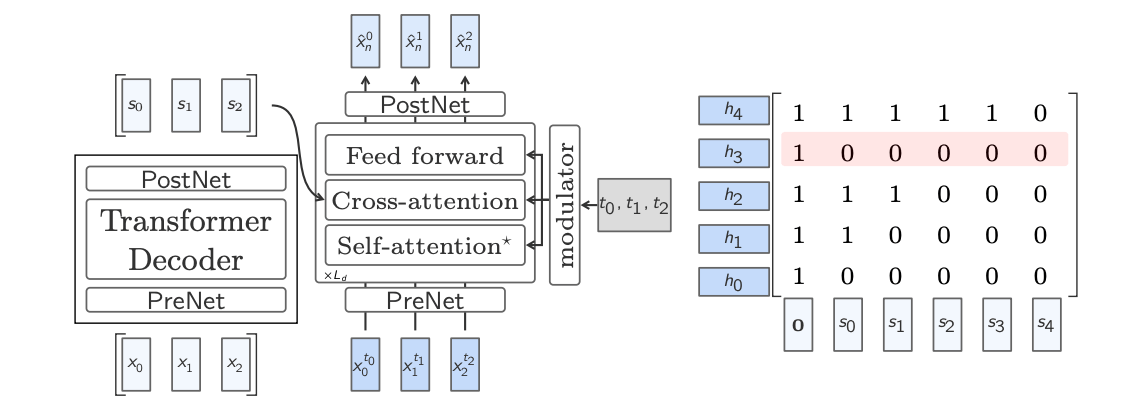
Here’s how it works in simple terms:
-
Tower 1: Contextualizer: This is a Transformer that reads all the previous sentence embeddings (
x<n) and encodes them using causal attention—meaning it reads them one by one in order, without peeking ahead. This creates a meaningful summary of the past context. -
Tower 2: Denoiser: This second Transformer takes in a noisy version of the next sentence embedding and tries to recover the clean version (
x₀ₙ). It does this gradually through multiple steps of denoising. To help guide this process, it uses cross-attention to look at the context produced by the first tower. -
Adaptive LayerNorm (AdaLN): The denoiser adapts its internal computations based on how noisy the input is at each step. It does this using a small network that learns how much to scale, shift, and blend each layer’s output, depending on the timestep of the diffusion process. This helps the model adjust its behavior at different noise levels.
-
Training setup: To help the model learn, during training:
- The context is slightly shifted so that each prediction only sees past sentences.
- A zero-vector is used as a placeholder at the start of the sequence to predict the first sentence.
- Some context rows are randomly dropped (with a probability
pcfg) so the model also learns how to denoise without context—this supports classifier-free guidance during inference.
In short, the Two-Tower model first understands the context using one Transformer and then generates the next sentence by denoising a noisy version using another Transformer that refers back to that context. These architectures allow multiple valid outputs, enhancing diversity and flexibility in generation.
Evaluation and Results
To assess the effectiveness of Large Concept Models (LCMs), the researchers conducted comprehensive evaluations, particularly focusing on summarization tasks. The models were compared against several strong baselines, including both encoder-decoder models and decoder-only large language models (LLMs). The evaluations were done using both automatic metrics and human-aligned analysis methods.
The evaluation compares multiple versions of LCMs:
- Base-LCM – the naive autoregressive version predicting the next concept deterministically.
- Diffusion-Based LCMs – including both One-Tower and Two-Tower architectures that generate concepts stochastically.
- Quant LCMs – a variant not covered in detail in the paper, but included for comparison.
- smaLLaMA – an instruction-tuned LLM used as an additional performance baseline.
The best-performing LCM model was then scaled to 7 billion parameters and compared against popular LLMs, including:
- T5-3B – an encoder-decoder Transformer fine-tuned for summarization.
- Gemma-7B, LLaMA 3.1-8B, and Mistral-7B-v0.3 – decoder-only, instruction-finetuned LLMs.
Metrics Used for Evaluation
The paper employed a range of automatic metrics commonly used for evaluating natural language generation models:
- ROUGE-L: Measures the longest common subsequence between generated and reference summaries.
- Coherence: A classifier-based metric evaluating logical flow and topic consistency.
- OVL-3 (Overlap Score): Quantifies how extractive or abstractive a summary is.
- Repetition Rate: Measures the frequency of repeated words/phrases in the generated output.
- CoLA (Corpus of Linguistic Acceptability): Assesses grammatical acceptability based on linguistic norms.
- SH-4 (Source Attribution): Evaluates how well the generated summary attributes content to the original source.
- SH-5 (Semantic Coverage): Measures the completeness of semantic content transfer from source to summary.
Installing and Running LCMs
Meta’s Large Concept Models rely on fairseq2 and support installation via uv or pip.
Option 1: Using uv (Recommended)
# Set up environment and install CPU dependencies
uv sync --extra cpu --extra eval --extra data
# For GPU support (example: Torch 2.5.1 + CUDA 12.1)
uv pip install torch==2.5.1 --extra-index-url https://download.pytorch.org/whl/cu121 --upgrade
uv pip install fairseq2==v0.3.0rc1 --pre --extra-index-url https://fair.pkg.atmeta.com/fairseq2/whl/rc/pt2.5.1/cu121 --upgrade
Option 2: Using pip
# Install pip dependencies
pip install --upgrade pip
pip install fairseq2==v0.3.0rc1 --pre --extra-index-url https://fair.pkg.atmeta.com/fairseq2/whl/rc/pt2.5.1/cpu
pip install -e ".[data,eval]"
Preparing the Data
LCMs use sentence-level embeddings from SONAR to train on textual data.
# Prepare Wikipedia data with SONAR and SaT
uv run --extra data scripts/prepare_wikipedia.py /output/dir/for/the/data
Fitting a Normalizer
python scripts/fit_embedding_normalizer.py \
--ds dataset1:4 dataset2:1 dataset3:10 \
--save_path "path/to/new/normalizer.pt" \
--max_nb_samples 1000000
Pre-training LCMs
Option A: Train MSE LCM with SLURM (submitit)
python -m lcm.train +pretrain=mse \
++trainer.output_dir="checkpoints/mse_lcm" \
++trainer.experiment_name=training_mse_lcm
Option B: Train Locally (Torchrun)
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc-per-node=2 \
-m lcm.train launcher=standalone \
+pretrain=mse \
++trainer.data_loading_config.max_tokens=1000 \
++trainer.output_dir="checkpoints/mse_lcm" \
+trainer.use_submitit=false
Finetuning the Two-Tower Diffusion LCM
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc-per-node=2 \
-m lcm.train launcher=standalone \
+finetune=two_tower \
++trainer.output_dir="checkpoints/finetune_two_tower_lcm" \
++trainer.data_loading_config.max_tokens=1000 \
+trainer.use_submitit=false \
++trainer.model_config_or_name=my_pretrained_two_tower
Evaluating LCMs
python -m nltk.downloader punkt_tab
torchrun --standalone --nnodes=1 --nproc-per-node=1 -m lcm.evaluation \
--predictor two_tower_diffusion_lcm \
--model_card ./checkpoints/finetune_two_tower_lcm/checkpoints/step_1000/model_card.yaml \
--data_loading.max_samples 100 \
--data_loading.batch_size 4 \
--generator_batch_size 4 \
--dump_dir evaluation_outputs/two_tower \
--inference_timesteps 40 \
--initial_noise_scale 0.6 \
--guidance_scale 3 \
--guidance_rescale 0.7 \
--tasks finetuning_data_lcm.validation \
--task_args '{"max_gen_len": 10, "eos_config": {"text": "End of text."}}'
Evaluation outputs (including ROUGE metrics and predictions) will be saved in ./evaluation_outputs/two_tower.
Key Findings
a. Summarization Quality Diffusion-based LCMs significantly outperformed Base-LCM in both ROUGE-L and Coherence metrics. Compared to instruction-finetuned LLMs, the Two-Tower LCM achieved comparable or superior results, especially in tasks requiring semantic abstraction. The 7B parameter LCM was competitive with T5-3B, a model specifically designed and tuned for summarization tasks.
b. Abstractive vs. Extractive Summarization LCMs tend to produce more abstractive summaries than traditional LLMs. This was evident from lower OVL-3 scores, suggesting that LCMs aren’t simply copying phrases from the input but are rephrasing or summarizing content at a conceptual level.
c. Repetition Handling LCMs demonstrated lower repetition rates, an important advantage for generating fluent and natural outputs. The repetition rates of LCMs were closer to human-written summaries, indicating better semantic planning during generation.
d. Fluency and Linguistic Quality Interestingly, while LCMs fared well in semantic metrics, they performed slightly lower in fluency, as measured by CoLA scores. This suggests that while the models generate meaningful summaries, they occasionally produce grammatical or stylistic inconsistencies—a possible side effect of operating in an embedding space without tight token-level control.
e. Source Attribution and Semantic Coverage On source attribution (SH-4) and semantic coverage (SH-5), LCMs performed reasonably well, but some model-based evaluation biases may have favored token-level generation from LLMs. Nevertheless, LCMs maintained core semantic fidelity, showing promise in aligning with source content at a conceptual level.
Limitations
While Large Concept Models (LCMs) show a lot of promise, there are a few key limitations that stand out.
First, the model relies on the SONAR embedding space, which was trained on short, well-aligned translation data. This makes it great for capturing local meaning but less reliable for understanding loosely related sentences or more complex inputs like links, numbers, or code.
Another challenge is the use of a frozen encoder. While this makes training more efficient, it limits the model’s ability to adapt to the specific needs of concept-level modeling. An end-to-end trained encoder might offer better semantic understanding but would require more data and compute.
The way LCMs currently treat whole sentences as single “concepts” can also be problematic. Long sentences may contain multiple ideas, and breaking them down isn’t always straightforward. This makes it harder to represent them accurately with fixed-size embeddings.
There’s also a data sparsity issue. Most sentences in a training corpus are unique, making it difficult for the model to learn general patterns. Higher-level semantic representations could help, but they come with trade-offs like losing important details.
Finally, modeling text with diffusion techniques is still tricky. Text may be represented as continuous vectors, but it’s ultimately a discrete structure. The Quant-LCM attempts to handle this, but SONAR wasn’t optimized for quantization, leading to inefficiencies.
Conclusion
Large Concept Models (LCMs) represent an important step forward in how AI understands and works with language. Instead of focusing on small parts of text called tokens, LCMs look at the bigger picture—concepts and meaning. This helps them better understand longer conversations, think more logically, and support multiple languages and different types of dat, like text and images.
Meta’s work on LCMs shows what the future of AI could look like: smarter, more human-like systems that truly understand context and meaning. These models have the potential to improve how we interact with AI, making it more natural, accurate, and helpful. As this technology grows, it could lead to more powerful tools for communication, creativity, and problem-solving across many fields.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
