")
Text Diffusion - a new paradigm
Since Google introduced Gemini Diffusion during Google I/O, we can’t stop thinking about the use of diffusion models FOR TEXT. For context, Large Language Models (LLMs) have traditionally been autoregressive, generating words sequentially one token at a time, with each future token predicted based on past ones. Text diffusion models, however, produce outputs by refining “noise” - which just means rapid iteration of an initial solution until a desirable output is reached. The beauty of text diffusion models lies in their low latency while producing textual outputs of comparable quality to autoregressive models. Furthermore, text diffusion models could prove to be a more cost-effective solution, given the computational expense of sequential token generation.
A notable paper, Large Language Diffusion Models, sheds some valuable insight on the use of diffusion models for language. The paper introduces LLaDA (a Large Language Diffusion with mAsking), a text-based diffusion model.
The figure below is from the LLaDA paper and gives a visual representation of the inference process. Darker colours correspond to tokens produced in later sampling stages and lighter colours correspond to earlier predictions.
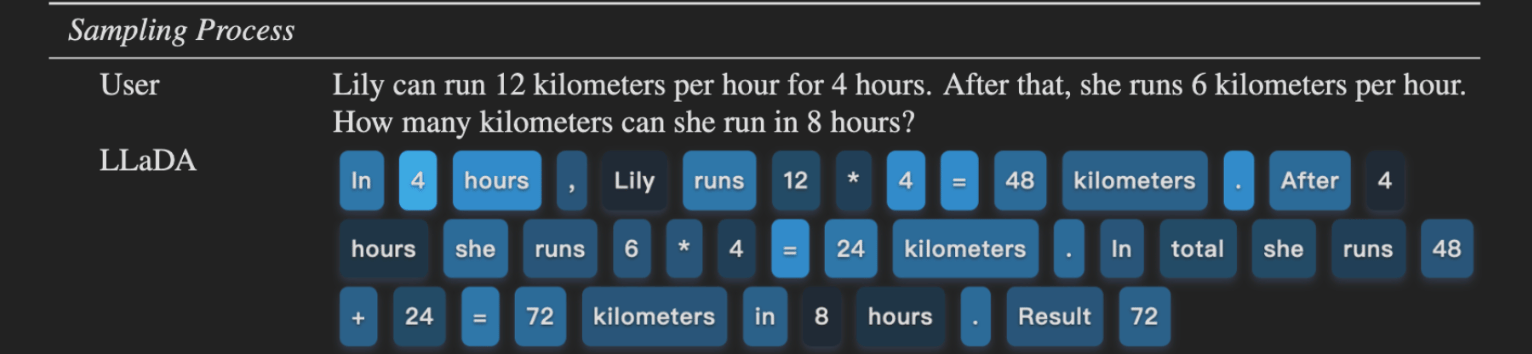
After reading about LLaDA, we were curious about multimodal models that leverage text diffusion and have image-handling capabilities. After all, it’s pretty evident that models that can handle visual inputs as well are far more useful than just text-based models.
In this article, we’re going to take a look at Multimodal Large Diffusion Language Models (MMaDA), a novel class of models for textual reasoning, multimodal understanding, and text-to-image generation.
There’s a demo available for your exploration on HuggingFace Spaces! We encourage you to check it out. We’ll also show you how you can run MMaDA on DigitalOcean GPU Droplets and discuss our thoughts on the model’s performance.
Prerequisites
There are two main components to this tutorial - an overview and implementation. The overview section assumes familiarity with topics such as Large Language Models (LLMs), tokenization, diffusion models, and multimodality. Without this background, readers may find it difficult to navigate. The implementation section is quite straightforward. We’ll be setting up a GPU Droplet and showing you how you can run the code in the command-line. Feel free to skip sections that aren’t of use to you.
MMaDA
Multimodal Large Language Models (MLLMs) typically combine autoregressive models for text and diffusion models for images. However, Multimodal Large Diffusion Language Models (MMaDA) presents a modality-agnostic approach for textual reasoning, multimodal understanding, and text-to-image generation. The researchers developed MMaDA by combining a unified diffusion architecture with a shared probabilistic framework, designed to be adaptable across different data types without needing specific components for each. This design enables smooth integration and processing of various forms of information. They also employ a novel “mixed long chain-of-thought” (CoT) fine-tuning approach that standardizes the CoT format across different modalities. By linking reasoning processes in both text and visual data, this strategy helps the model initiate training for reinforcement learning tasks, thus improving its ability to handle complex problems from the start. Furthermore, the researchers introduce UniGRPO, a policy-gradient-based reinforcement learning algorithm specifically created for diffusion foundation models. Through diverse reward modeling, UniGRPO integrates post-training for both reasoning and generation tasks, leading to consistent improvements in performance.
Depending on the training stage, there are different MMaDA checkpoints available for download:
| Model | Training Checkpoint | Capabilities | Status |
|---|---|---|---|
| MMaDA-8B-Base | Pretraining and instruction tuning | Basic text generation, image generation, image captioning and thinking abilities | Available |
| MMaDA-8B-MixCoT | Mixed long chain-of-thought (CoT) fine-tuning | Complex textual, multimodal and image generation reasoning | Available |
| MMaDA-8B-Max | UniGRPO reinforcement learning | Excels at complex reasoning and visual generation | Coming soon |
Training
Pre-Training
Tokenization is discrete for both text and image modalities.
MMaDA builds upon LLaDA in that it was initialized with LLaDA-8B-Instruct’s pretrained weights for text. A pretrained image tokenizer from Show-o is used for images.
MMaDA is formulated as a mask token predictor (for both image and text tokens) that predicts all masked tokens simultaneously from an input token. The model is trained using a unified cross-entropy loss computed from only the masked image/text tokens.
Below is a figure illustrating the unified cross-entropy loss function used to pre-train the MMaDA model:
 Key Components:
Key Components:
θ: Model parameters being optimized
x₀: Ground truth (original clean data)
t: Timestep sampled uniformly from [0,1] - represents how much noise has been added
xₜ: Noisy version of x₀ at timestep t, created by the forward diffusion process
[MASK]: Special tokens indicating which positions should be predicted
𝟙[xᵢᵗ=[MASK]]: Indicator function that equals 1 when position i is masked, 0 otherwise
In simpler terms, the formula calculates the negative log-likelihood of correctly predicting the original (unmasked) tokens, but only for those tokens that were masked in the noisy input xₜ. The average is taken over the timestep and all masked tokens. This objective trains the MMaDA model to be a mask token predictor for both image and text tokens, enabling it to simultaneously predict all masked tokens.
Below we listed the datasets used to train the model.
Training Datasets
| Dataset Category | Dataset Name | Purpose |
|---|---|---|
| Foundational Language and Multimodal Data | ||
| RefinedWeb | Basic text generation capabilities | |
| ImageNet | Multimodal understanding | |
| Conceptual 12M | Image-text pre-training | |
| Segment Anything (SAM) | Multimodal understanding | |
| LAION-Aesthetics-12M | Image-text dataset | |
| JourneyDB | Generative image understanding | |
| Instruction Tuning Data | ||
| LLaVA-1.5 | Visual instruction tuning | |
| Stanford Alpaca | Textual instructions | |
| InstructBLIP | Vision-language instruction tuning | |
| Qwen-VL | Vision-language model | |
| mPLUG-Owl2 | Multi-modal instruction tuning | |
| LLaVA-Phi | Efficient multi-modal assistant | |
| Reasoning Data | ||
| GeoQA | Geometric question answering | |
| CLEVR | Compositional language and visual reasoning | |
| ReasonFlux | Hierarchical LLM reasoning | |
| LIMO | Mathematical and logical reasoning | |
| s1k | Simple test-time scaling | |
| OpenThoughts | Mathematical and logical reasoning | |
| AceMath-Instruct | Math reasoning with post-training | |
| LMM-R1 | 3D LMMs with strong reasoning | |
| Reinforcement Learning Data | ||
| GeoQA | UniGRPO training | |
| Clevr | UniGRPO training | |
| GSM8K | UniGRPO training |
Implementation
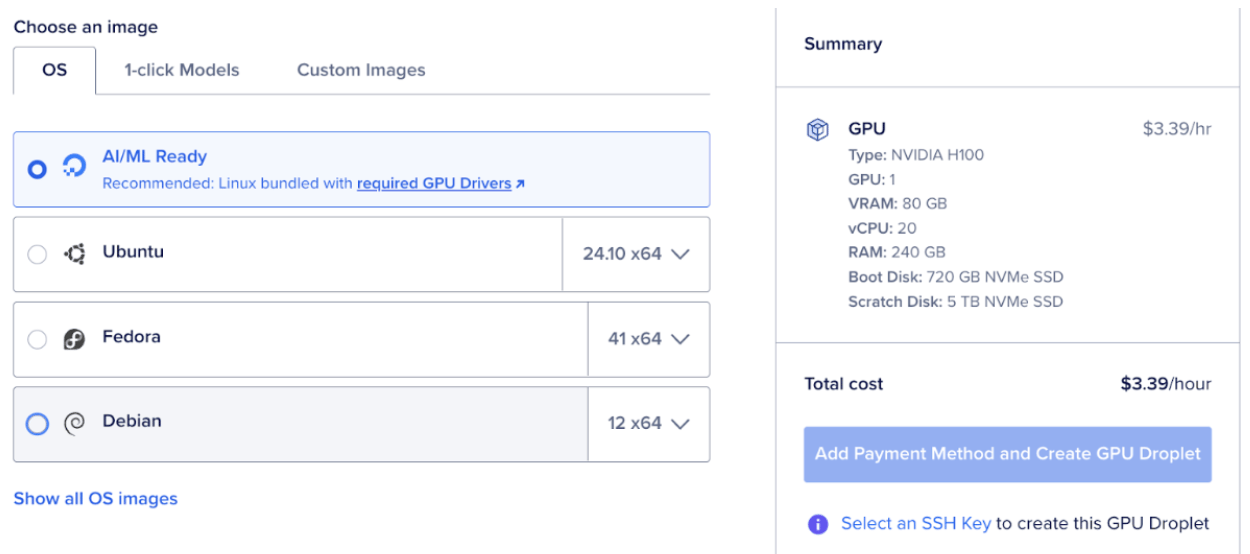
Step 1 : Set up a GPU Droplet
Begin by setting up a DigitalOcean GPU Droplet, select AI/ML and choose the NVIDIA H100 option.
Step 2: Web Console
Once your GPU Droplet finishes loading, you’ll be able to open up the Web Console.

Step 3: Install Dependencies
In the web console, copy and paste the following code snippet:
apt install python3-pip python3.10
Step 4: Clone repository
git clone https://github.com/Gen-Verse/MMaDA
cd MMaDA
Step 5: Install Dependencies
Installing the requirements file nsures that your environment has all the tools needed to run the `app.py`
pip install -r requirements.txt
python3 app.py
The output will be a Gradio link that you can access within VS Code.
Step 6: Open VS Code
In VS Code, click on “Connect to…” in the Start menu.
Choose “Connect to Host…”.
Step 7: Connect to your GPU Droplet
Click “Add New SSH Host…” and enter the SSH command to connect to your droplet. This command is usually in the format ssh root@[your_droplet_ip_address]. Press Enter to confirm, and a new VS Code window will open, connected to your droplet.
You can find your droplet’s IP address on the GPU droplet page.
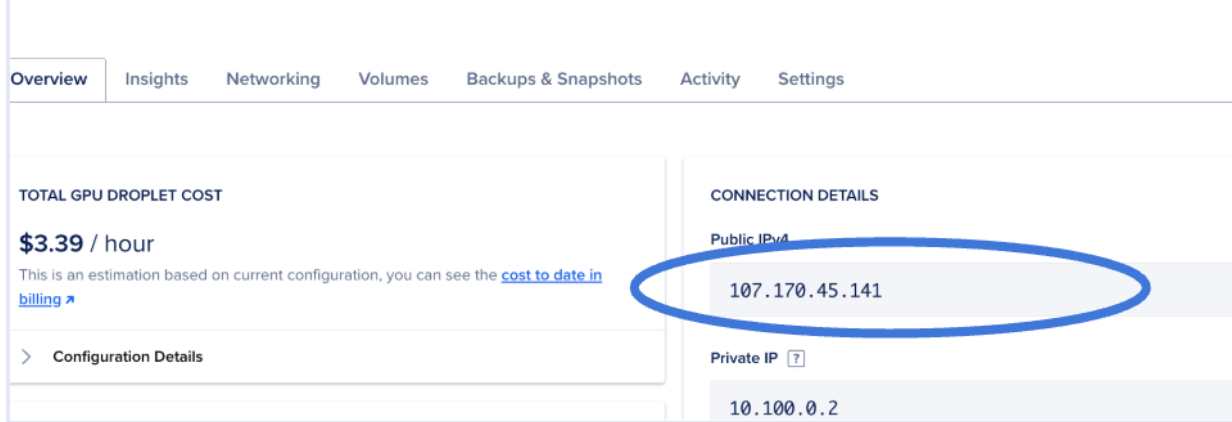
Step 8: Access the Gradio
In the new VS Code window connected to your droplet, type >sim and select “Simple Browser: Show”.

Paste the Gradio url from the Web Console.

Multimodal and text-to-image generation will require a wandb account. Access is free for students and postdoctoral researchers, but will require a subscription otherwise. If you don’t have a wandb account, remember that you can still try out MMaDA on HuggingFace!
wandb login
For multimodal understanding
python3 inference_mmu.py config=configs/mmada_demo.yaml mmu_image_root=./mmu_validation question='Please describe this image in detail.'
For text-to-image generation
python3 inference_t2i.py config=configs/mmada_demo.yaml batch_size=1 validation_prompts_file=validation_prompts/text2image_prompts.txt guidance_scale=3.5 generation_timesteps=15
mode='t2i'
Performance
Multimodal Understanding
 The model falsely classifies the line in the distance-time graph as a straight line and incorrectly interprets the line. Looks like high school physics is not the model’s strong suit. Oof.
The model falsely classifies the line in the distance-time graph as a straight line and incorrectly interprets the line. Looks like high school physics is not the model’s strong suit. Oof.
 The model is correctly able to identify the flavour of the ice cream image we uploaded though. Nice.
The model is correctly able to identify the flavour of the ice cream image we uploaded though. Nice.
Text-to-Image Generation
While we were impressed by the speed of image generation, we found that prompt adherence for MMaDA’s text-to-image capabilities could still use some work. We encourage you to play around with the different parameters and let us know your thoughts in the comments below.
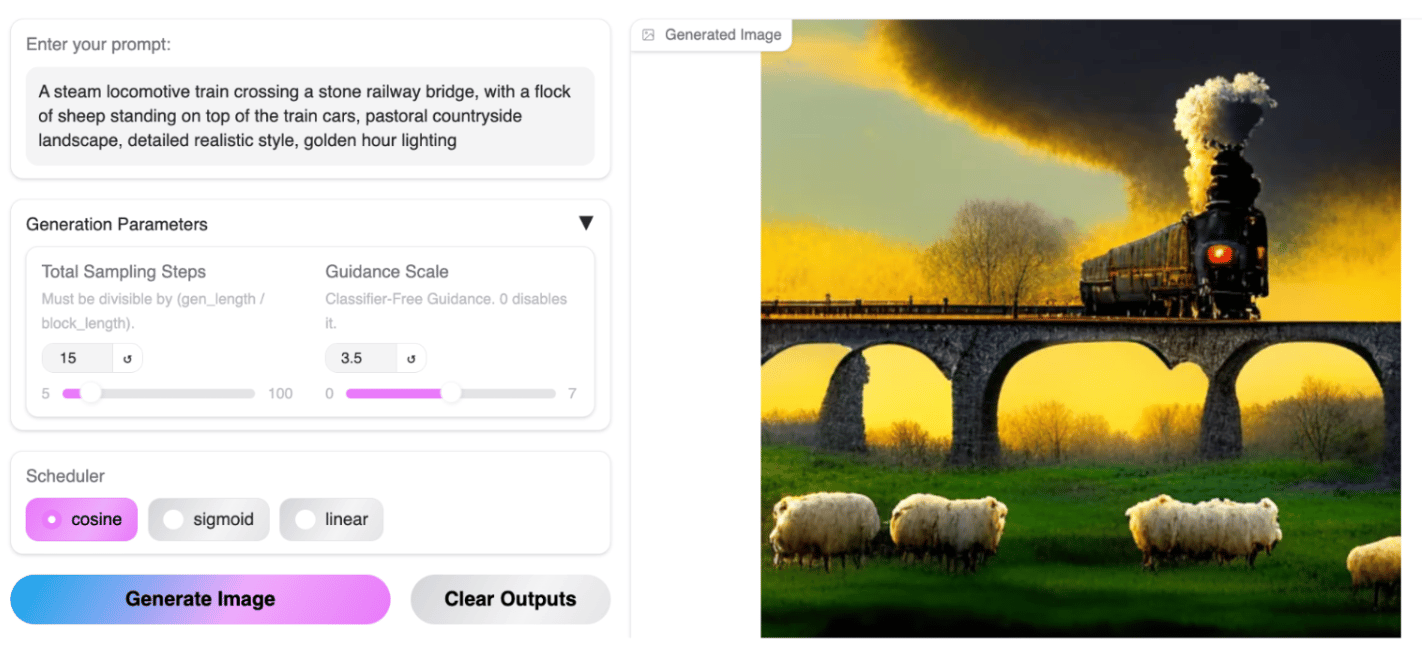
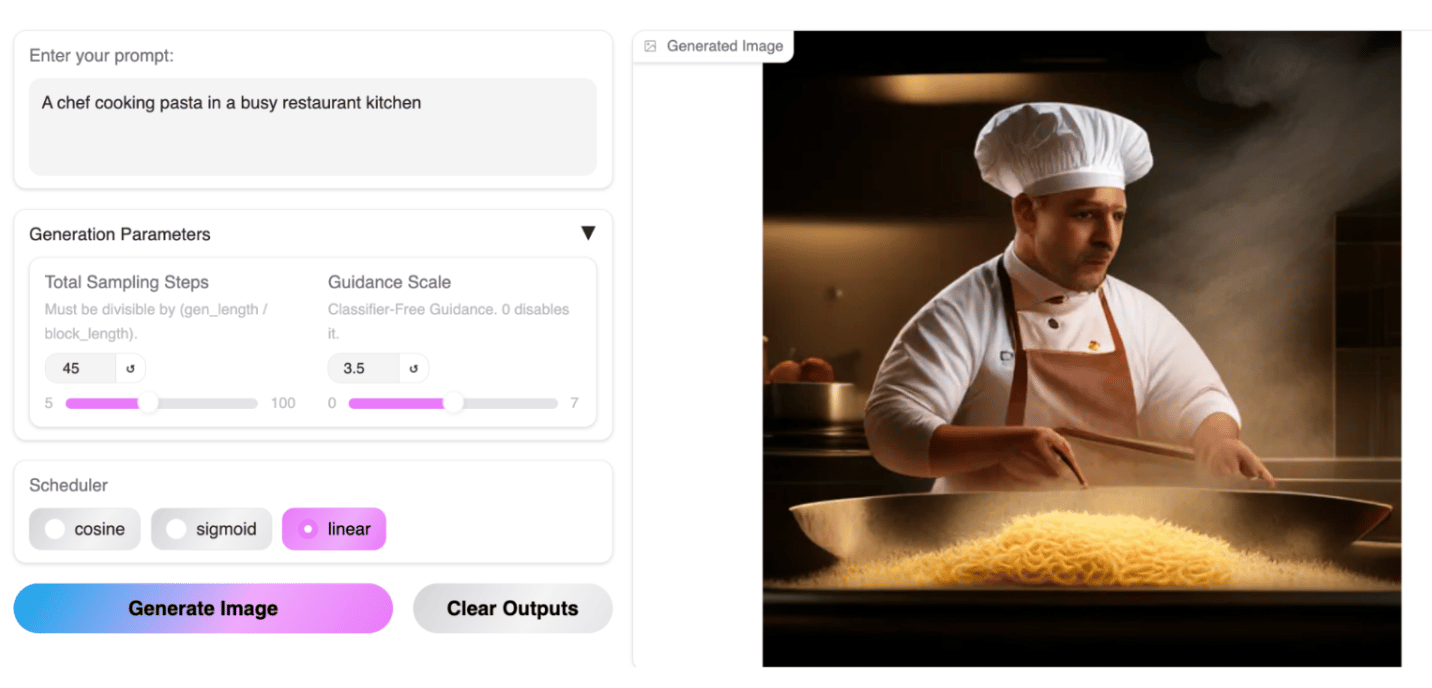
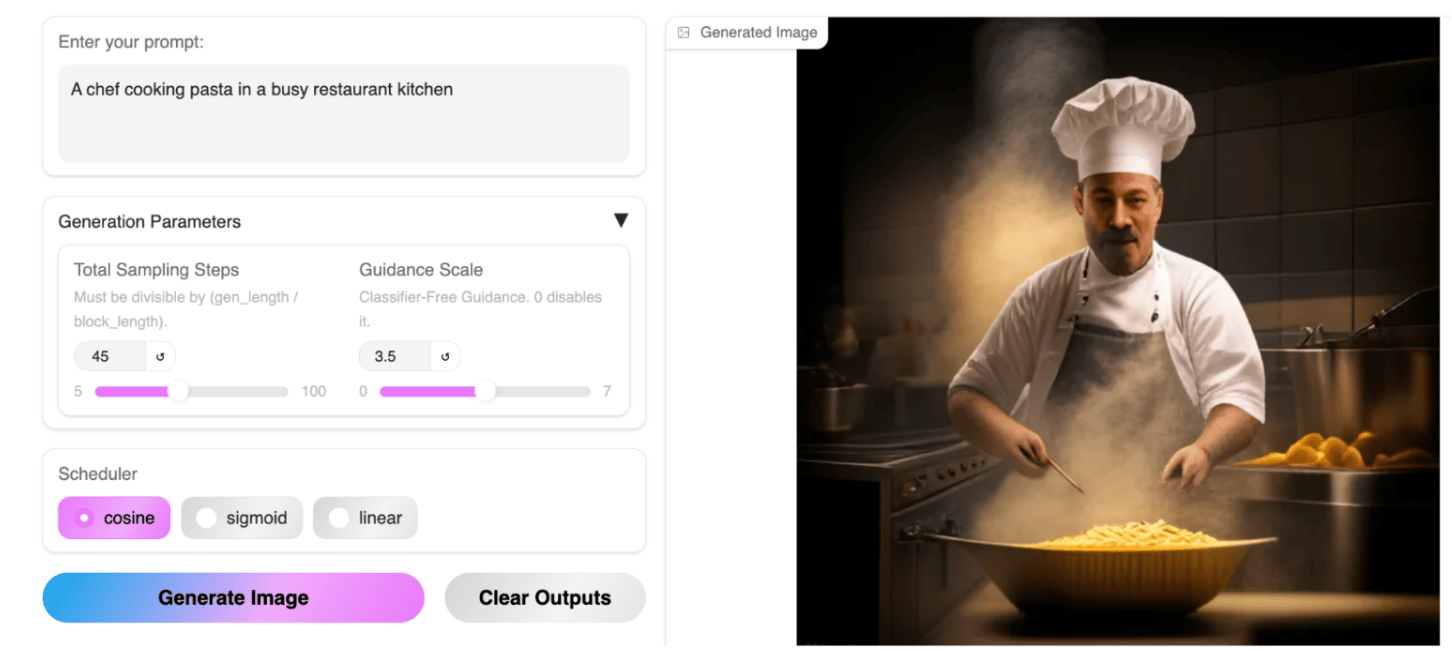
Final Thoughts
It’s really incredible how fast this field moves. The introduction of Multimodal Large Diffusion Language Models (MMaDA) represents a unique approach to textual reasoning, multimodal understanding, and text-to-image generation. By leveraging a modality-agnostic diffusion framework and building upon innovations like LLaDA, MMaDA offers a potential alternative to traditional autoregressive models, especially concerning latency and computational cost.
While the model demonstrates decent speeds in image generation and an ability to handle multimodal inputs (like identifying ice cream flavors), there are still areas for improvement, such as prompt adherence in text-to-image generation and complex reasoning tasks (as seen with the physics graph example). Despite these current limitations, the underlying diffusion methodology for language and its extension to multimodal contexts are quite interesting. As the field continues to evolve, we anticipate further refinements that will enhance the accuracy and robustness of MMaDA or similar multimodal diffusion models, making it an even more powerful tool for a wide range of applications.
That being said, training large diffusion models appear to be very computationally expensive. This give rise to the question of whether the training cost of massive multimodal diffusion models is worth the efficient and cost-effective serving of the model. Of course, this depends on large-scale performance and value derived in production.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Melani is a Technical Writer at DigitalOcean based in Toronto. She has experience in teaching, data quality, consulting, and writing. Melani graduated with a BSc and Master’s from Queen's University.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
