Sr Technical Content Strategist and Team Lead

Introduction
MongoDB is a popular NoSQL database and is widely used for handling unstructured data. Python developers can efficiently query MongoDB using PyMongo, an official MongoDB Python driver. This tutorial will cover various MongoDB query techniques in Python, including:
- Retrieving documents using filters: Learn how to use
PyMongoto filter documents based on specific conditions, such as equality, inequality, and logical operators. - Querying nested fields and arrays: You will learn how to access and manipulate nested fields and arrays within MongoDB documents using PyMongo.
- Using aggregation pipelines: Use MongoDB’s aggregation framework to process and transform data in several stages, including filtering, grouping, and sorting.
- Best practices for optimizing queries: Understand how to optimize your MongoDB queries for better performance, including indexing, limiting results, and projecting specific fields.
By the end of this tutorial, you’ll be able to query MongoDB databases efficiently in Python and handle performance optimization for large datasets. We will also discuss how to use MongoDB Atlas, a fully managed cloud database service, to host your MongoDB databases in the cloud.
Prerequisites
Before querying MongoDB in Python, ensure you have the following:
-
Python 3 downloaded and installed on your system.
-
MongoDB installed and running. You can refer to this tutorial on how to install MongoDB.
-
Pymongo library installed.
-
A free MongoDB Atlas database cluster deployed for demonstration and testing purposes.
Step 1 - Install MongoDB on Ubuntu
To install MongoDB on Ubuntu, follow these steps:
Note: The below steps are run on a Ubuntu system running version 24.10. If you are running any other Ubuntu version, please consider following this official documentation on how to install MongoDB on Ubuntu.
-
Import the MongoDB public key:
sudo apt-get install gnupg curl curl -fsSL https://www.mongodb.org/static/pgp/server-8.0.asc | sudo gpg -o /usr/share/keyrings/mongodb-server-8.0.gpg --dearmor -
Create the list file:
echo "deb [ arch=amd64,arm64 signed-by=/usr/share/keyrings/mongodb-server-8.0.gpg ] https://repo.mongodb.org/apt/ubuntu focal/mongodb-org/8.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-8.0.list -
Reload the package database:
sudo apt-get update -
Install MongoDB Community Edition:
sudo apt-get install -y mongodb-org -
Start the MongoDB service:
sudo systemctl start mongod -
Verify the MongoDB installation:
sudo systemctl status mongod
After completing these steps, MongoDB should be installed and running on your Ubuntu system.
Step 2 - Install PyMongo
Create a project directory
In your shell, run the following command to create a directory called pymongo-quickstart for this project:
mkdir pymongo-quickstart
Run the following commands to create a quickstart.py application file in the pymongo-quickstart directory:
cd pymongo-quickstart
touch quickstart.py
Let’s create a virtual environment and activate it:
python3 -m venv venv
source venv/bin/activate
Now let’s install PyMongo:
python3 -m pip install pymongo
You can also follow the steps mentioned in this official documentation from MongoDB on how to download and install pymongo.
Step 3 - Connecting to MongoDB Atlas in Python
Here is the folder structure after installing pymongo:
root/
├── pymongo-quickstart/
│ └── quickstart.py
└── venv
In this example, we will use MongoDB Atlas to deploy a free MongoDB cluster for demonstration purposes. MongoDB Atlas is a cloud-based MongoDB service that allows users to easily deploy, manage, and scale MongoDB clusters in the cloud. It provides a free tier, making it an ideal choice for testing and demonstration purposes.
Login to MongoDB Cloud and create a MongoDB Atlas free cluster from Atlas UI.
Note: Once your free database cluster is created, please ensure you add your current IP address of the system from which you are trying to connect with MongoDB.
Simply visit the Network Access section from the Security tab on the MongoDB Altas cluster dashboard and add the IP address.
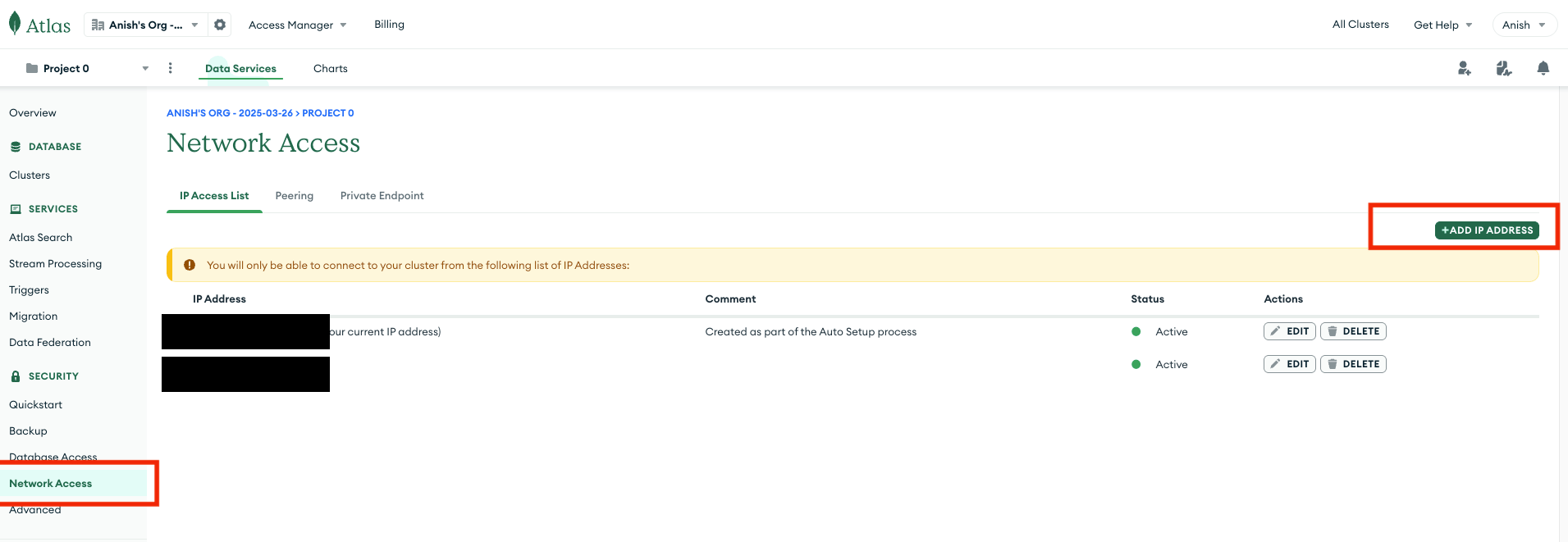
If you don’t follow this step, then you will receive the following SSL handshake failed error when you implement the below steps to query the data.
pymongo.errors.ServerSelectionTimeoutError: SSL handshake failed: ac-r1katou-shard-00-01.1szm4t5.mongodb.net:27017: [SSL: TLSV1_ALERT_INTERNAL_ERROR] tlsv1 alert internal error (_ssl.c:1000) (configured timeouts: socketTimeoutMS: 20000.0ms, connectTimeoutMS: 20000.0ms),SSL handshake failed: ac-r1katou-shard-00-02.1szm4t5.mongodb.net:27017: [SSL: TLSV1_ALERT_INTERNAL_ERROR] tlsv1 alert internal error (_ssl.c:1000) (configured timeouts: socketTimeoutMS: 20000.0ms, connectTimeoutMS: 20000.0ms),SSL handshake failed: ac-r1katou-shard-00-00.1szm4t5.mongodb.net:27017: [SSL: TLSV1_ALERT_INTERNAL_ERROR] tlsv1 alert internal error (_ssl.c:1000) (configured timeouts: socketTimeoutMS: 20000.0ms, connectTimeoutMS: 20000.0ms), Timeout: 30s, Topology Description: <TopologyDescription id: 67e3a4be8b571dbdd9e11b91, topology_type: ReplicaSetNoPrimary, servers: [<ServerDescription ('ac-r1katou-shard-00-00.1szm4t5.mongodb.net', 27017) server_type: Unknown, rtt: None, error=AutoReconnect('SSL handshake failed: ac-r1katou-shard-00-00.1szm4t5.mongodb.net:27017: [SSL: TLSV1_ALERT_INTERNAL_ERROR] tlsv1 alert internal error (_ssl.c:1000) (configured timeouts: socketTimeoutMS: 20000.0ms, connectTimeoutMS: 20000.0ms)')>, <ServerDescription ('ac-r1katou-shard-00-01.1szm4t5.mongodb.net', 27017) server_type: Unknown, rtt: None, error=AutoReconnect('SSL handshake failed: ac-r1katou-shard-00-01.1szm4t5.mongodb.net:27017: [SSL: TLSV1_ALERT_INTERNAL_ERROR] tlsv1 alert internal error (_ssl.c:1000) (configured timeouts: socketTimeoutMS: 20000.0ms, connectTimeoutMS: 20000.0ms)')>, <ServerDescription ('ac-r1katou-shard-00-02.1szm4t5.mongodb.net', 27017) server_type: Unknown, rtt: None, error=AutoReconnect('SSL handshake failed: ac-r1katou-shard-00-02.1szm4t5.mongodb.net:27017: [SSL: TLSV1_ALERT_INTERNAL_ERROR] tlsv1 alert internal error (_ssl.c:1000) (configured timeouts: socketTimeoutMS: 20000.0ms, connectTimeoutMS: 20000.0ms)')>]
To interact with MongoDB Atlas cluster, establish a connection using PyMongo. We will use a sample dataset provided by MongoDB Atlas.
You can find the MongoDB Atlas cluster connection string from the Overview -> Connect -> Connection Instructions tab.
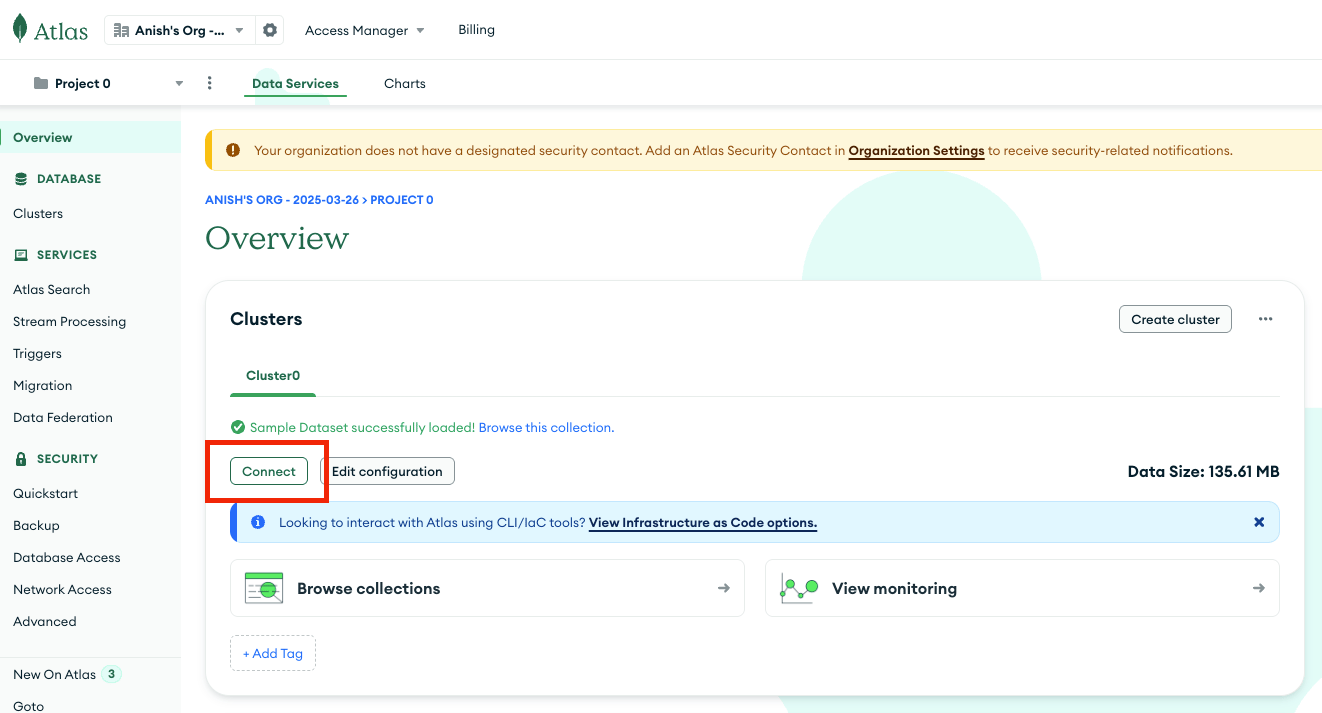
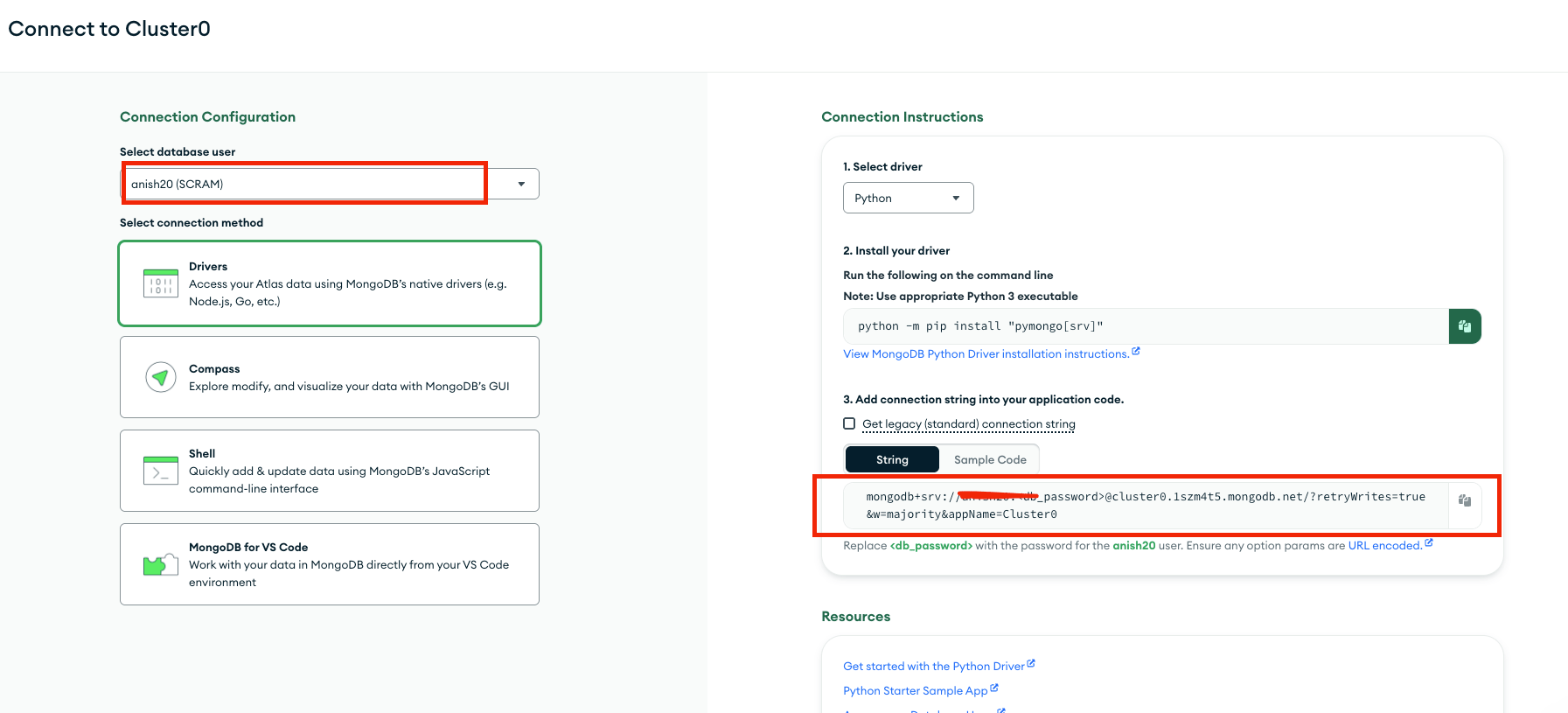
Add the following lines of code inside the file /root/pymongo-quickstart/quickstart.py:
import pymongo
from pymongo import MongoClient
# Attempt to connect to the MongoDB cluster using the provided URI
try:
uri = "mongodb+srv://<db_username>:<db_password>@cluster0.1szm4t5.mongodb.net/?retryWrites=true&w=majority&appName=Cluster0"
client = MongoClient(uri)
# Select the database and collection to work with
database = client["sample_mflix"]
collection = database["movies"]
# This section is intentionally left blank for future code examples
# Example code can be added here to interact with the MongoDB collection
# Close the MongoDB client connection
client.close()
except Exception as e:
# If any error occurs during the connection or interaction, raise an exception with the error details
raise Exception(
"The following error occurred: ", e)
Fetch a Sample Document using find_one()
find_one()The following command retrieves a single movie document from the dataset.
Note: You need to add the lines of code to query the databse, discussed in the upcoming sections of this tutorial inside the /root/pymongo-quickstart/quickstart.py file just before the database connection is closed using client.close().
print(collection.find_one())
You will get the following output after running the Python file:
python quickstart.py
Output{'_id': ObjectId('573a1390f29313caabcd42e8'), 'plot': 'A group of bandits stage a brazen train hold-up, only to find a determined posse hot on their heels.', 'genres': ['Short', 'Western'], 'runtime': 11, 'cast': ['A.C. Abadie', "Gilbert M. 'Broncho Billy' Anderson", 'George Barnes', 'Justus D. Barnes'], 'poster': 'https://m.media-amazon.com/images/M/MV5BMTU3NjE5NzYtYTYyNS00MDVmLWIwYjgtMmYwYWIxZDYyNzU2XkEyXkFqcGdeQXVyNzQzNzQxNzI@._V1_SY1000_SX677_AL_.jpg', 'title': 'The Great Train Robbery', 'fullplot': "Among the earliest existing films in American cinema - notable as the first film that presented a narrative story to tell - it depicts a group of cowboy outlaws who hold up a train and rob the passengers. They are then pursued by a Sheriff's posse. Several scenes have color included - all hand tinted.", 'languages': ['English'], 'released': datetime.datetime(1903, 12, 1, 0, 0), 'directors': ['Edwin S. Porter'], 'rated': 'TV-G', 'awards': {'wins': 1, 'nominations': 0, 'text': '1 win.'}, 'lastupdated': '2015-08-13 00:27:59.177000000', 'year': 1903, 'imdb': {'rating': 7.4, 'votes': 9847, 'id': 439}, 'countries': ['USA'], 'type': 'movie', 'tomatoes': {'viewer': {'rating': 3.7, 'numReviews': 2559, 'meter': 75}, 'fresh': 6, 'critic': {'rating': 7.6, 'numReviews': 6, 'meter': 100}, 'rotten': 0, 'lastUpdated': datetime.datetime(2015, 8, 8, 19, 16, 10)}, 'num_mflix_comments': 0}
For more on findOne(), visit the MongoDB findOne() Example tutorial.
Retrieving Documents Using find()
find()The find() method retrieves documents that match a given filter.
Inside the quickstart.py file, you can add the following code to query the data:
# Get all movies
docs = collection.find().limit(5)
for movie in docs:
print(movie)
When you run this Python file you will get the below output:
python quickstart.py
Output{'_id': ObjectId('573a1390f29313caabcd42e8'), 'plot': 'A group of bandits stage a brazen train hold-up, only to find a determined posse hot on their heels.', 'genres': ['Short', 'Western'], 'runtime': 11, 'cast': ['A.C. Abadie', "Gilbert M. 'Broncho Billy' Anderson", 'George Barnes', 'Justus D. Barnes'], 'poster': 'https://m.media-amazon.com/images/M/MV5BMTU3NjE5NzYtYTYyNS00MDVmLWIwYjgtMmYwYWIxZDYyNzU2XkEyXkFqcGdeQXVyNzQzNzQxNzI@._V1_SY1000_SX677_AL_.jpg', 'title': 'The Great Train Robbery', 'fullplot': "Among the earliest existing films in American cinema - notable as the first film that presented a narrative story to tell - it depicts a group of cowboy outlaws who hold up a train and rob the passengers. They are then pursued by a Sheriff's posse. Several scenes have color included - all hand tinted.", 'languages': ['English'], 'released': datetime.datetime(1903, 12, 1, 0, 0), 'directors': ['Edwin S. Porter'], 'rated': 'TV-G', 'awards': {'wins': 1, 'nominations': 0, 'text': '1 win.'}, 'lastupdated': '2015-08-13 00:27:59.177000000', 'year': 1903, 'imdb': {'rating': 7.4, 'votes': 9847, 'id': 439}, 'countries': ['USA'], 'type': 'movie', 'tomatoes': {'viewer': {'rating': 3.7, 'numReviews': 2559, 'meter': 75}, 'fresh': 6, 'critic': {'rating': 7.6, 'numReviews': 6, 'meter': 100}, 'rotten': 0, 'lastUpdated': datetime.datetime(2015, 8, 8, 19, 16, 10)}, 'num_mflix_comments': 0}
{'_id': ObjectId('573a1390f29313caabcd446f'), 'plot': "A greedy tycoon decides, on a whim, to corner the world market in wheat. This doubles the price of bread, forcing the grain's producers into charity lines and further into poverty. The film...", 'genres': ['Short', 'Drama'], 'runtime': 14, 'cast': ['Frank Powell', 'Grace Henderson', 'James Kirkwood', 'Linda Arvidson'], 'num_mflix_comments': 1, 'title': 'A Corner in Wheat', 'fullplot': "A greedy tycoon decides, on a whim, to corner the world market in wheat. This doubles the price of bread, forcing the grain's producers into charity lines and further into poverty. The film continues to contrast the ironic differences between the lives of those who work to grow the wheat and the life of the man who dabbles in its sale for profit.", 'languages': ['English'], 'released': datetime.datetime(1909, 12, 13, 0, 0), 'directors': ['D.W. Griffith'], 'rated': 'G', 'awards': {'wins': 1, 'nominations': 0, 'text': '1 win.'}, 'lastupdated': '2015-08-13 00:46:30.660000000', 'year': 1909, 'imdb': {'rating': 6.6, 'votes': 1375, 'id': 832}, 'countries': ['USA'], 'type': 'movie', 'tomatoes': {'viewer': {'rating': 3.6, 'numReviews': 109, 'meter': 73}, 'lastUpdated': datetime.datetime(2015, 5, 11, 18, 36, 53)}}
{'_id': ObjectId('573a1390f29313caabcd4803'), 'plot': 'Cartoon figures announce, via comic strip balloons, that they will move - and move they do, in a wildly exaggerated style.', 'genres': ['Animation', 'Short', 'Comedy'], 'runtime': 7, 'cast': ['Winsor McCay'], 'num_mflix_comments': 0, 'poster': 'https://m.media-amazon.com/images/M/MV5BYzg2NjNhNTctMjUxMi00ZWU4LWI3ZjYtNTI0NTQxNThjZTk2XkEyXkFqcGdeQXVyNzg5OTk2OA@@._V1_SY1000_SX677_AL_.jpg', 'title': 'Winsor McCay, the Famous Cartoonist of the N.Y. Herald and His Moving Comics', 'fullplot': 'Cartoonist Winsor McCay agrees to create a large set of drawings that will be photographed and made into a motion picture. The job requires plenty of drawing supplies, and the cartoonist must also overcome some mishaps caused by an assistant. Finally, the work is done, and everyone can see the resulting animated picture.', 'languages': ['English'], 'released': datetime.datetime(1911, 4, 8, 0, 0), 'directors': ['Winsor McCay', 'J. Stuart Blackton'], 'writers': ['Winsor McCay (comic strip "Little Nemo in Slumberland")', 'Winsor McCay (screenplay)'], 'awards': {'wins': 1, 'nominations': 0, 'text': '1 win.'}, 'lastupdated': '2015-08-29 01:09:03.030000000', 'year': 1911, 'imdb': {'rating': 7.3, 'votes': 1034, 'id': 1737}, 'countries': ['USA'], 'type': 'movie', 'tomatoes': {'viewer': {'rating': 3.4, 'numReviews': 89, 'meter': 47}, 'lastUpdated': datetime.datetime(2015, 8, 20, 18, 51, 24)}}
{'_id': ObjectId('573a1390f29313caabcd4eaf'), 'plot': 'A woman, with the aid of her police officer sweetheart, endeavors to uncover the prostitution ring that has kidnapped her sister, and the philanthropist who secretly runs it.', 'genres': ['Crime', 'Drama'], 'runtime': 88, 'cast': ['Jane Gail', 'Ethel Grandin', 'William H. Turner', 'Matt Moore'], 'num_mflix_comments': 1, 'poster': 'https://m.media-amazon.com/images/M/MV5BYzk0YWQzMGYtYTM5MC00NjM2LWE5YzYtMjgyNDVhZDg1N2YzXkEyXkFqcGdeQXVyMzE0MjY5ODA@._V1_SY1000_SX677_AL_.jpg', 'title': 'Traffic in Souls', 'lastupdated': '2015-09-15 02:07:14.247000000', 'languages': ['English'], 'released': datetime.datetime(1913, 11, 24, 0, 0), 'directors': ['George Loane Tucker'], 'rated': 'TV-PG', 'awards': {'wins': 1, 'nominations': 0, 'text': '1 win.'}, 'year': 1913, 'imdb': {'rating': 6.0, 'votes': 371, 'id': 3471}, 'countries': ['USA'], 'type': 'movie', 'tomatoes': {'viewer': {'rating': 3.0, 'numReviews': 85, 'meter': 57}, 'dvd': datetime.datetime(2008, 8, 26, 0, 0), 'lastUpdated': datetime.datetime(2015, 8, 10, 18, 33, 55)}}
{'_id': ObjectId('573a1390f29313caabcd50e5'), 'plot': 'The cartoonist, Winsor McCay, brings the Dinosaurus back to life in the figure of his latest creation, Gertie the Dinosaur.', 'genres': ['Animation', 'Short', 'Comedy'], 'runtime': 12, 'cast': ['Winsor McCay', 'George McManus', 'Roy L. McCardell'], 'num_mflix_comments': 0, 'poster': 'https://m.media-amazon.com/images/M/MV5BMTQxNzI4ODQ3NF5BMl5BanBnXkFtZTgwNzY5NzMwMjE@._V1_SY1000_SX677_AL_.jpg', 'title': 'Gertie the Dinosaur', 'fullplot': 'Winsor Z. McCay bets another cartoonist that he can animate a dinosaur. So he draws a big friendly herbivore called Gertie. Then he get into his own picture. Gertie walks through the picture, eats a tree, meets her creator, and takes him carefully on her back for a ride.', 'languages': ['English'], 'released': datetime.datetime(1914, 9, 15, 0, 0), 'directors': ['Winsor McCay'], 'writers': ['Winsor McCay'], 'awards': {'wins': 1, 'nominations': 0, 'text': '1 win.'}, 'lastupdated': '2015-08-18 01:03:15.313000000', 'year': 1914, 'imdb': {'rating': 7.3, 'votes': 1837, 'id': 4008}, 'countries': ['USA'], 'type': 'movie', 'tomatoes': {'viewer': {'rating': 3.7, 'numReviews': 29}, 'lastUpdated': datetime.datetime(2015, 8, 10, 19, 20, 3)}}
Filter Queries
In the quickstart.py file, we can add the following code to find movies released after the year 2000.
# Find movies released after 2000
query = {"year": {"$gt": 2000}}
for movie in collection.find(query).limit(2):
print(movie)
This will give the below output:
Output{'_id': ObjectId('573a1393f29313caabcdcb42'), 'plot': 'Kate and her actor brother live in N.Y. in the 21st Century. Her ex-boyfriend, Stuart, lives above her apartment. Stuart finds a space near the Brooklyn Bridge where there is a gap in time....', 'genres': ['Comedy', 'Fantasy', 'Romance'], 'runtime': 118, 'metacritic': 44, 'rated': 'PG-13', 'cast': ['Meg Ryan', 'Hugh Jackman', 'Liev Schreiber', 'Breckin Meyer'], 'poster': 'https://m.media-amazon.com/images/M/MV5BNmNlN2VlOTctYTdhMS00NzUxLTg0ZGMtYWE2ZTJmMThlMTk2XkEyXkFqcGdeQXVyMzI0NDc4ODY@._V1_SY1000_SX677_AL_.jpg', 'title': 'Kate & Leopold', 'fullplot': "Kate and her actor brother live in N.Y. in the 21st Century. Her ex-boyfriend, Stuart, lives above her apartment. Stuart finds a space near the Brooklyn Bridge where there is a gap in time. He goes back to the 19th Century and takes pictures of the place. Leopold -- a man living in the 1870s -- is puzzled by Stuart's tiny camera, follows him back through the gap, and they both ended up in the present day. Leopold is clueless about his new surroundings. He gets help and insight from Charlie who thinks that Leopold is an actor who is always in character. Leopold is a highly intelligent man and tries his best to learn and even improve the modern conveniences that he encounters.", 'languages': ['English', 'French'], 'released': datetime.datetime(2001, 12, 25, 0, 0), 'directors': ['James Mangold'], 'writers': ['Steven Rogers (story)', 'James Mangold (screenplay)', 'Steven Rogers (screenplay)'], 'awards': {'wins': 2, 'nominations': 4, 'text': 'Nominated for 1 Oscar. Another 1 win & 4 nominations.'}, 'lastupdated': '2015-08-31 00:19:09.717000000', 'year': 2001, 'imdb': {'rating': 6.3, 'votes': 59951, 'id': 35423}, 'countries': ['USA'], 'type': 'movie', 'tomatoes': {'website': 'http://www.kateandleopold-themovie.com', 'viewer': {'rating': 3.0, 'numReviews': 189426, 'meter': 62}, 'dvd': datetime.datetime(2002, 6, 11, 0, 0), 'critic': {'rating': 5.3, 'numReviews': 126, 'meter': 50}, 'boxOffice': '$47.1M', 'consensus': 'Though Jackman charms, Kate and Leopold is bland and predictable, and the time travel scenario lacks inner logic.', 'rotten': 63, 'production': 'Miramax Films', 'lastUpdated': datetime.datetime(2015, 8, 22, 18, 53, 25), 'fresh': 63}, 'num_mflix_comments': 0}
{'_id': ObjectId('573a1398f29313caabceb1fe'), 'plot': "A modern day adaptation of Dostoyevsky's classic novel about a young student who is forever haunted by the murder he has committed.", 'genres': ['Drama'], 'runtime': 126, 'cast': ['Crispin Glover', 'Vanessa Redgrave', 'John Hurt', 'Margot Kidder'], 'poster': 'https://m.media-amazon.com/images/M/MV5BMTI3MDQ2MzEyOV5BMl5BanBnXkFtZTcwNzEwODUzMQ@@._V1_SY1000_SX677_AL_.jpg', 'title': 'Crime and Punishment', 'fullplot': "A modern day adaptation of Dostoyevsky's classic novel about a young student who is forever haunted by the murder he has committed.", 'languages': ['English', 'Polish'], 'released': datetime.datetime(2002, 6, 1, 0, 0), 'directors': ['Menahem Golan'], 'writers': ['Fyodor Dostoevsky (novel)', 'Menahem Golan (adaptation)', 'Menahem Golan (screenplay)'], 'awards': {'wins': 2, 'nominations': 0, 'text': '2 wins.'}, 'lastupdated': '2015-08-13 00:34:02.303000000', 'year': 2002, 'imdb': {'rating': 6.4, 'votes': 463, 'id': 96056}, 'countries': ['USA', 'Poland', 'Russia'], 'type': 'movie', 'tomatoes': {'viewer': {'rating': 0.0, 'numReviews': 0}, 'lastUpdated': datetime.datetime(2015, 7, 22, 18, 45, 10)}, 'num_mflix_comments': 0}
Filtering Certain Columns
In the quickstart.py file, we can add the following code to find movies released after 2000 and only display the title and IMDb rating.
# Find movies released after 2000 and only display the title and IMDb rating
query = {"year": {"$gt": 2000}} # This query filters movies released after the year 2000
projection = {"_id": 0, "title": 1, "imdb.rating": 1} # This projection specifies which fields to include in the result
# The "_id": 0 excludes the default "_id" field from the result, while "title": 1 and "imdb.rating": 1 include the title and IMDb rating respectively
for movie in collection.find(query, projection).limit(10): # This loop iterates over the results of the query, limited to the first 10 matches
print(movie) # Each movie document is printed, showing only the title and IMDb rating as specified in the projection
In this code block, we are using the projection parameter in the find() method to specify which fields to include in the result. The _id field is excluded from the result with "_id": 0, and the title and imdb.rating fields are included with 1. The limit(10) method is used to limit the number of results to 10.
You can learn more about projections in mongodb.
Here is the output:
Output{'title': 'Kate & Leopold', 'imdb': {'rating': 6.3}}
{'title': 'Crime and Punishment', 'imdb': {'rating': 6.4}}
{'imdb': {'rating': 2.1}, 'title': 'Glitter'}
{'imdb': {'rating': 5.5}, 'title': 'The Manson Family'}
{'title': 'The Dancer Upstairs', 'imdb': {'rating': 7.0}}
{'imdb': {'rating': 5.7}, 'title': 'Fantastic Four'}
{'imdb': {'rating': 7.4}, 'title': 'Frida'}
{'imdb': {'rating': 6.8}, 'title': 'From Hell'}
{'imdb': {'rating': 6.3}, 'title': 'Kate & Leopold'}
{'imdb': {'rating': 8.8}, 'title': 'The Lord of the Rings: The Fellowship of the Ring'}
Querying Nested Fields and Arrays
Accessing Nested Fields
In the following code, we are querying the database to find movies with an IMDb rating greater than or equal to 8.
query = {"imdb.rating": {"$gte": 8}}
projection = {"_id": 0, "title": 1, "imdb.rating": 1}
for movie in collection.find(query, projection).limit(5):
print(movie)
This code block queries the database to find movies with an IMDb rating greater than or equal to 8. It then projects only the title and IMDb rating of the movies. The limit is set to 5, so it will only return the first 5 movies that match the query.
Here is the output
Output{'title': 'One Week', 'imdb': {'rating': 8.3}}
{'title': "Tol'able David", 'imdb': {'rating': 8.1}}
{'title': 'Ella Cinders', 'imdb': {'rating': 8.1}}
{'title': 'City Lights', 'imdb': {'rating': 8.6}}
{'title': 'The Music Box', 'imdb': {'rating': 8.1}}
Filtering Arrays
In this code snippet, we are filtering the movies that belong to the Action genre and projects only the title and IMDb rating of the movies.
query = {"genres": "Action"} # Finds movies that belong to the Action genre
projection = {"_id": 0, "title": 1, "imdb.rating": 1}
for movie in collection.find(query, projection).limit(10):
print(movie)
Output{'title': 'The Perils of Pauline', 'imdb': {'rating': 7.6}}
{'title': 'From Hand to Mouth', 'imdb': {'rating': 7.0}}
{'title': 'Beau Geste', 'imdb': {'rating': 6.9}}
{'title': 'The Black Pirate', 'imdb': {'rating': 7.2}}
{'title': "For Heaven's Sake", 'imdb': {'rating': 7.6}}
{'title': 'Men Without Women', 'imdb': {'rating': 5.8}}
{'title': 'The Crowd Roars', 'imdb': {'rating': 6.4}}
{'title': 'Scarface', 'imdb': {'rating': 7.8}}
{'title': 'Tarzan the Ape Man', 'imdb': {'rating': 7.2}}
{'title': 'China Seas', 'imdb': {'rating': 7.0}}
Using Aggregation Pipelines for Complex Queries
Aggregation pipelines in MongoDB are a way to process data in a series of stages. Each stage transforms the documents as they pass through the pipeline. This allows for more complex and powerful queries than simple find operations.
# This code block uses MongoDB's aggregation pipeline to process data in a series of stages.
# The pipeline consists of two stages:
# 1. The "$match" stage filters the documents to only include those where the "year" field is greater than or equal to 2010.
# 2. The "$group" stage groups the filtered documents by their "genres" field and calculates the average "imdb.rating" for each group.
pipeline = [
{"$match": {"year": {"$gte": 2010}}},
{"$group": {"_id": "$genres", "averageIMDB": {"$avg": "$imdb.rating"}}}
]
# The result of the aggregation pipeline is stored in the "result" variable.
result = collection.aggregate(pipeline)
# Finally, the code iterates over the "result" and prints each document, which represents the average IMDb rating for each genre of movies released in or after 2010.
for doc in result:
print(doc)
This code block uses MongoDB’s aggregation pipeline to process data in a series of stages.
The pipeline consists of two stages:
- The “$match” stage filters the documents to only include those where the “year” field is greater than or equal to 2010.
- The “$group” stage groups the filtered documents by their “genres” field and calculates the average “imdb.rating” for each group.
The result of the aggregation pipeline is stored in the “result” variable.
Finally, the code iterates over the “result” and prints each document, which represents the average IMDb rating for each genre of movies released in or after 2010.
Here is the output when this query is run:
Output{'_id': ['Comedy', 'Fantasy', 'Thriller'], 'averageIMDB': 6.4}
{'_id': ['Fantasy', 'Mystery', 'Thriller'], 'averageIMDB': 7.1}
{'_id': ['Comedy', 'Romance'], 'averageIMDB': 6.198165137614679}
{'_id': ['Animation', 'Short', 'Action'], 'averageIMDB': 7.1499999999999995}
{'_id': ['Action', 'Comedy', 'Fantasy'], 'averageIMDB': 6.2}
{'_id': ['Drama', 'War'], 'averageIMDB': 6.872413793103449}
{'_id': ['Horror', 'Sci-Fi', 'Thriller'], 'averageIMDB': 4.941666666666666}
{'_id': ['Documentary', 'Crime'], 'averageIMDB': 7.071428571428571}
{'_id': ['Animation', 'Short', 'Crime'], 'averageIMDB': 7.2}
{'_id': ['Documentary', 'History', 'News'], 'averageIMDB': 7.1000000000000005}
{'_id': ['Comedy', 'Crime', 'Thriller'], 'averageIMDB': 7.140000000000001}
{'_id': ['Comedy', 'Family', 'Romance'], 'averageIMDB': 6.24}
{'_id': ['Crime', 'Drama', 'Horror'], 'averageIMDB': 6.225}
{'_id': ['Comedy', 'Horror', 'Thriller'], 'averageIMDB': 5.642857142857143}
{'_id': ['Documentary', 'Animation', 'News'], 'averageIMDB': 7.2}
{'_id': ['Biography', 'Drama', 'War'], 'averageIMDB': 6.2}
{'_id': ['Fantasy', 'Thriller'], 'averageIMDB': 6.3}
{'_id': ['Drama', 'Horror', 'Mystery'], 'averageIMDB': 6.218181818181819}
{'_id': ['Adventure', 'Drama', 'Sci-Fi'], 'averageIMDB': 8.7}
{'_id': ['Comedy', 'Music'], 'averageIMDB': 6.359999999999999}
{'_id': ['Action', 'Comedy', 'Sport'], 'averageIMDB': 6.5}
{'_id': ['Drama', 'Family', 'Sci-Fi'], 'averageIMDB': 6.3}
{'_id': ['Action', 'Drama', 'Fantasy'], 'averageIMDB': 5.824999999999999}
{'_id': ['Drama', 'Music', 'Musical'], 'averageIMDB': 4.9}
Differences between find() and aggregate() Methods
find() and aggregate() Methods| Feature | find() |
aggregate() |
Sample Example |
|---|---|---|---|
| Simplicity | Simple | Complex | db.collection.find({}) vs db.collection.aggregate([{ $match: {} }]) |
| Performance | Fast for simple queries | Optimized for large datasets | db.collection.find({ year: { $gte: 2010 } }) vs db.collection.aggregate([{ $match: { year: { $gte: 2010 } } }, { $group: { _id: "$genres", averageIMDB: { $avg: "$imdb.rating" } } }]) |
| Use Case | Filtering & retrieving data | Data transformation & computation | db.collection.find({ genres: "Comedy" }) vs db.collection.aggregate([{ $match: { genres: "Comedy" } }, { $group: { _id: "$genres", count: { $sum: 1 } } }]) |
The find() method is a straightforward way to retrieve data from a MongoDB collection. It is ideal for simple queries that require filtering and retrieving data based on specific conditions. However, it has limitations when it comes to complex data transformations and computations.
On the other hand, the aggregate() method is a powerful tool for processing data in a series of stages. It is designed to handle complex data transformations, aggregations, and computations. While it can be more complex to use than find(), it offers a wide range of operators and stages that can be combined to perform sophisticated data processing tasks.
When deciding between find() and aggregate(), consider the complexity of your query and the type of data processing required. If you need to perform simple filtering and retrieval, find() might be the better choice. However, if you need to perform data transformations, aggregations, or computations, aggregate() is likely the better option.
Optimizing MongoDB Queries for Performance
Use Indexes
Creating an index on a field can significantly improve query performance, especially for fields used in query filters or sorts. In this example, we create an index on the “year” field to optimize queries that filter movies by release year.
collection.create_index("year")
Limit Results
Limiting the number of results returned by a query can reduce the amount of data transferred and processed, leading to improved performance. This is particularly useful when you only need a subset of the data or want to implement pagination. Here, we limit the results to the first 10 movies found.
for movie in collection.find().limit(10):
print(movie)
Project Specific Fields
Projecting specific fields in a query allows you to retrieve only the data you need, reducing the amount of data transferred and processed. This can improve performance and reduce network overhead. In this example, we project only the “title” field and exclude the “_id” field to only display the titles of the movies.
for movie in collection.find({}, {"title": 1, "_id": 0}):
print(movie)
FAQs
1. How do I query data in MongoDB using Python?
When querying data in MongoDB using Python, you have two primary methods: find() and aggregate(). The choice between these methods depends on the complexity of your query and the type of data processing required.
Basic Queries with find()
The find() method is suitable for simple queries that require filtering and retrieving data based on specific conditions. It is ideal for tasks such as:
- Retrieving all documents in a collection:
db.collection.find() - Filtering documents based on a condition:
db.collection.find({"year": 2010}) - Retrieving specific fields:
db.collection.find({}, {"title": 1, "_id": 0})
Here’s an example of using find() to retrieve all movies released in 2010:
for movie in db.movies.find({"year": 2010}):
print(movie)
Advanced Queries with aggregate()
The aggregate() method is designed for complex data transformations, aggregations, and computations. It is ideal for tasks such as:
- Grouping documents based on a field and calculating an average:
db.collection.aggregate([{ $group: { _id: "$genres", averageIMDB: { $avg: "$imdb.rating" } } }]) - Filtering documents based on a condition and then grouping:
db.collection.aggregate([{ $match: { year: 2010 } }, { $group: { _id: "$genres", count: { $sum: 1 } } }])
Here’s an example of using aggregate() to calculate the average IMDB rating for movies in each genre:
for result in db.movies.aggregate([{ $group: { _id: "$genres", averageIMDB: { $avg: "$imdb.rating" } } }]):
print(result)
In summary, use find() for basic queries that require simple filtering and retrieval, and use aggregate() for advanced queries that require complex data transformations and computations.
2. What is the difference between find() and aggregate()?
The find() method is a straightforward way to retrieve data from a MongoDB collection. It is ideal for simple queries that require filtering and retrieving data based on specific conditions. However, it has limitations when it comes to complex data transformations and computations.
On the other hand, the aggregate() method is a powerful tool for processing data in a series of stages. It is designed to handle complex data transformations, aggregations, and computations. While it can be more complex to use than find(), it offers a wide range of operators and stages that can be combined to perform sophisticated data processing tasks.
3. How do I filter data in MongoDB with Python?
To filter data in MongoDB using Python, you can use the { "field": { "$operator": value } } syntax. This syntax allows you to specify a field, an operator, and a value to filter the data. Here’s an example code block that demonstrates how to filter documents where the “year” field is equal to 2020:
for movie in db.movies.find({"year": { "$eq": 2020 }}):
print(movie)
4. Can I query nested documents in MongoDB?
Yes, you can query nested documents in MongoDB using dot notation. Dot notation allows you to access fields within nested documents. The syntax for dot notation is { "nested.field": value }.
For example, if you have a document structure like this:
{
"name": "John Doe",
"address": {
"street": "123 Main St",
"city": "Anytown",
"state": "CA",
"zip": "12345"
}
}
You can query documents where the “city” field within the “address” nested document is “Anytown” using the following code:
for document in db.collection.find({"address.city": "Anytown"}):
print(document)
This will return all documents where the “city” field within the “address” nested document matches “Anytown”.
5. How do I optimize MongoDB queries for large datasets?
You can use techniques like indexing, projection, and limit results to improve performance as discussed in the sections above.
6. What are the best libraries for MongoDB querying in Python?
-
pymongo(official MongoDB driver) -
mongoengine(object-document mapper)
For more MongoDB management tutorials, check out our tutorial series on How to Manage Data with MongoDB.
Conclusion
In conclusion, querying MongoDB in Python is a crucial skill for any developer working with large datasets. This tutorial has covered various MongoDB query techniques in Python, including retrieving documents using filters, querying nested fields and arrays, using aggregation pipelines, and best practices for optimizing queries.
In this tutorial you learned:
- Crafting basic queries using the
find()method to retrieve specific documents - Filtering nested fields and arrays to target specific data and reduce the amount of data retrieved
- Leveraging aggregation pipelines using
aggregate()for complex data processing, such as data transformation, grouping, and sorting - Optimizing queries for performance on large datasets by using indexes, projections, and limits to reduce the load on the database and improve query efficiency
By mastering these techniques, you’ll be able to efficiently retrieve and manipulate data in your MongoDB collections, making you a more effective developer in handling large datasets.
For further reading, explore:
-
How to Create Queries in MongoDB tutorial series.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
I help Businesses scale with AI x SEO x (authentic) Content that revives traffic and keeps leads flowing | 3,000,000+ Average monthly readers on Medium | Sr Technical Writer(Team Lead) @ DigitalOcean | Ex-Cloud Consultant @ AMEX | Ex-Site Reliability Engineer(DevOps)@Nutanix
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
