AI/ML Technical Content Strategist

If you’ve worked in open-source development, you probably already know the name Stability AI. They kicked off the image generation revolution with Stable Diffusion and created an evergreen model that remains one of the most-popular open source AI tools in Stable Diffusion XL.
Recently, Stability AI has made new forays into AI audio generation. Stable Audio Open released last year and made an immediate impact on the audio generation scene. More recently, Stability has contributed further with Stable Audio Small and the updated library Stable Audio Tools. These are a Audio Generation Deep Learning model and library released to the public that show some of the most promise of any open-source audio generation tool yet.
In this article, we look at the Stable Audio Small’s capabilities, discuss why you should be excited to use it, and run the model with a GPU Droplet on DigitalOcean.
What is Stable Audio Small
The main innovation of the Stable Audio Small model is the introduction of Adversarial Relativistic-Contrastive (ARC) post-training. To our knowledge, this is the first adversarial acceleration algorithm for diffusion/flow models that is not based on costly distillation. Model distillation is the practice of using a larger model to train a smaller model to mimic the large model’s behavior. This is often prohibitively expensive and requires a correspondingly robust, small model architecture.
Seeking to create a more effective paradigm for smaller model training, Stability AI applied this technique to their Stable Audio Open to create Stable Audio Small. “ARC uses a relativistic adversarial formulation to text-conditional audio generation and combines this with a novel contrastive loss that encourages the discriminator to focus on prompt adherence.” Paper
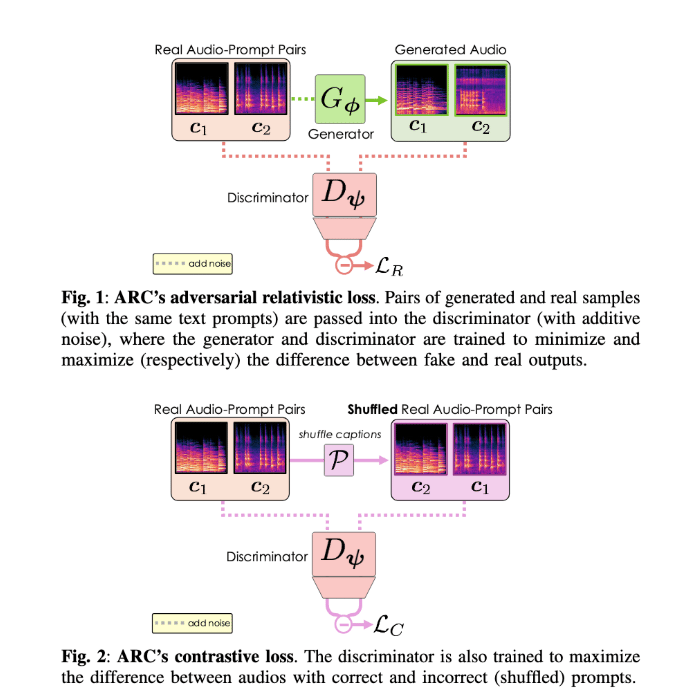
In practice, ARC involves using pairs of generated and real samples paired with text prompts being passed to a discriminator. The generator and discriminator are subsequently trained to respectively maximize the difference between the fake and real outputs. To augment this, the discriminator is also trained to better understand the differences between prompts with correctly formatted text pairs and shuffled text pairs, where the text order does not correspond to the real audio.
Thanks to ARC, Stable Audio Small was created from Stable Audio Open as a tiny alternative to the model that is extremely robust while being lightweight. The model is capable of generating a 10 second audio sample on an NVIDIA H100 GPU in less than 7 ms. These samples are wide ranging in style and output with notable specialization in music generation. They particularly use a house loop for their own demonstration.
Stable Audio Small on DigitalOcean GPU Droplets
To get started, set up your environment by following the instructions detailed in this tutorial.
Once your environment is set up, we can launch our Jupyter Notebook, and access the host machine via VS Code. Navigate to a directory of your choice, run the following command in the terminal, and then paste the output URL into your simple browser.
Jupyter notebook –allow-root
This will open your Jupyter Labs environment in your local browser window. From here, we can open a new .ipynb IPython Notebook. Navigate to the notebook, and paste the following into the first cell to install the required packages:
!pip install stable_audio_tools einops
This may take a few moments, but will install all the necessary packages to run Stable Audio Small. From there, we can begin generating! Paste the code into the next cell, and run it.
import torch
import torchaudio
from einops import rearrange
from stable_audio_tools import get_pretrained_model
from stable_audio_tools.inference.generation import generate_diffusion_cond
device = "cuda" if torch.cuda.is_available() else "cpu"
# Download model
model, model_config = get_pretrained_model("stabilityai/stable-audio-open-small")
sample_rate = model_config["sample_rate"]
sample_size = model_config["sample_size"]
model = model.to(device)
# Set up text and timing conditioning
conditioning = [{
"prompt": "128 BPM tech house drum loop",
"seconds_total": 11
}]
# Generate stereo audio
output = generate_diffusion_cond(
model,
steps=8,
conditioning=conditioning,
sample_size=sample_size,
sampler_type="pingpong",
device=device
)
# Rearrange audio batch to a single sequence
output = rearrange(output, "b d n -> d (b n)")
# Peak normalize, clip, convert to int16, and save to file
output = output.to(torch.float32).div(torch.max(torch.abs(output))).clamp(-1, 1).mul(32767).to(torch.int16).cpu()
torchaudio.save("output.wav", output, sample_rate)
We can control our outputs by modifying the values in the conditioning list—try a variety of different prompts to see how they perform. We tried and found success with everything from more real world prompts like “a cat meowing” to more complex music prompts like “a somber guitar strumming over the blustering wind”.
Finally, we can display and listen to our generated audio using IPython widgets. Paste the following into the last cell.
import IPython
IPython.display.Audio("output.wav")
Here are some examples we created with Stable Audio Small on our GPU Droplet:
Closing thoughts
Stable Audio Small is an incredibly awesome model given its size and versatility. We expect to see lots of projects forthcoming from this development—both in AI and outside of it—especially with regard to the development of the ARC post-training technique.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
