AI Technical Writer

As LLMs continue to power everything from chatbots to decision-making systems, the security risks surrounding them are growing just as fast.
A recent research shows that one of the most dangerous threats today is LLM poisoning, where attackers manipulate training data, fine-tuning pipelines, or retrieval sources to change how the model behaves.
Unlike prompt injection, which happens at inference time, LLM poisoning corrupts the model itself. It affects how it reasons, responds, and makes long-term decisions. This makes poisoning one of the hardest-to-detect and most damaging forms of AI compromise.
Key Takeaways
- Among today’s AI risks, LLM poisoning stands out as a particularly critical and hard-to-detect threat.
- Attacks target training data, fine-tuning pipelines, RAG systems, or model weights.
- Prevention depends on securing data sources, RAG pipelines, and fine-tuning workflows.
- Once poisoned, models often need partial or total retraining.
What Is LLM Poisoning?
LLM poisoning refers to attacks where attackers intentionally introduce malicious data into an LLM’s training, pretraining, fine-tuning, or RAG retrieval pipeline. The goal is to change the model’s behavior, introduce hidden triggers, or bias outputs.
Why It Matters
Poisoning attacks can significantly compromise an LLM’s accuracy, security, decision-making capabilities**, ethical alignment, and overall trustworthiness**. Since these models learn directly from the data they are trained on, even a small number of carefully crafted malicious samples can drastically alter their behavior. Anthropic’s research shows that even poisoning under 0.01% of the training data can implant backdoors that remain in the model despite heavy safety fine-tuning. This makes data poisoning one of the most subtle yet damaging threats in the entire LLM lifecycle.
Latest Research on LLM Poisoning Vulnerabilities
The paper on data poisoning has revealed that large language models may be far more vulnerable than previously believed. A study conducted the largest pretraining poisoning experiments, covering models from 600M to 13B parameters trained on Chinchilla-optimal datasets ranging from 6B to 260B tokens.
Contrary to earlier assumptions where attackers were thought to need control of a sizable percentage of the training corpus, this recent research shows that poisoning effectiveness does not scale with dataset size. Instead, injecting roughly 250 malicious documents was sufficient to corrupt models of all sizes, even when the largest models were trained on 20 times more clean data.
The researchers further validated that this near-constant poisoning requirement holds for fine-tuning as well, and that varying the ratio or distribution of poisoned samples does not materially reduce attack success. These results completely change how we think about LLM security and what it takes to poison a model.
All of this shows why future LLMs need tighter security and more careful control over the data they learn from. Further, it shows that LLM requires continuous dataset auditing and hardened training pipelines in future model development.
The researchers wanted to understand how easy it is to poison large language models during pretraining. Poisoning means inserting harmful or manipulated data into the training set so the model learns a hidden behavior, in this case, outputting gibberish when it sees a special trigger phrase.
What the Team Learned From the Study
- They trained models of different sizes (600M → 13B parameters) on huge “Chinchilla-optimal” datasets.
- They inserted a small number of poisoned documents (100, 250, or 500), each containing the trigger + gibberish text.
- It turned out that the number of poisoned examples drove the attack’s success, not how much they were mixed into clean data.
- Even huge 13B models, trained on more than 20 times more clean data, were fully backdoored using just 250 poisoned documents.
- This means a tiny fraction of poisoned data (as low as 0.00016%) can reliably implant a hidden behavior.
- The point when the backdoor “activates” during training is also similar across all model sizes; the model just needs to encounter the poison a few hundred times.
Pretraining Poisoning: Small Samples, Big Impact
Researchers pretrained models of varying sizes (600M–13B parameters) on Chinchilla-optimal datasets, injecting as few as 250 poisoned documents into training. These documents contained:
- A normal pile text prefix
- A trigger phrase
- Randomly generated gibberish as the “malicious” output
Key Findings:
- The absolute number of poisoned samples, not poisoning percentage, determines attack success.
- 250 malicious documents reliably backdoored models up to 13B parameters.
- This represented only 0.00016% of training tokens for the 13B model.
- Backdoors emerged at similar training stages across all model scales.
- Continued clean training degraded the backdoor slowly but did not immediately erase it.
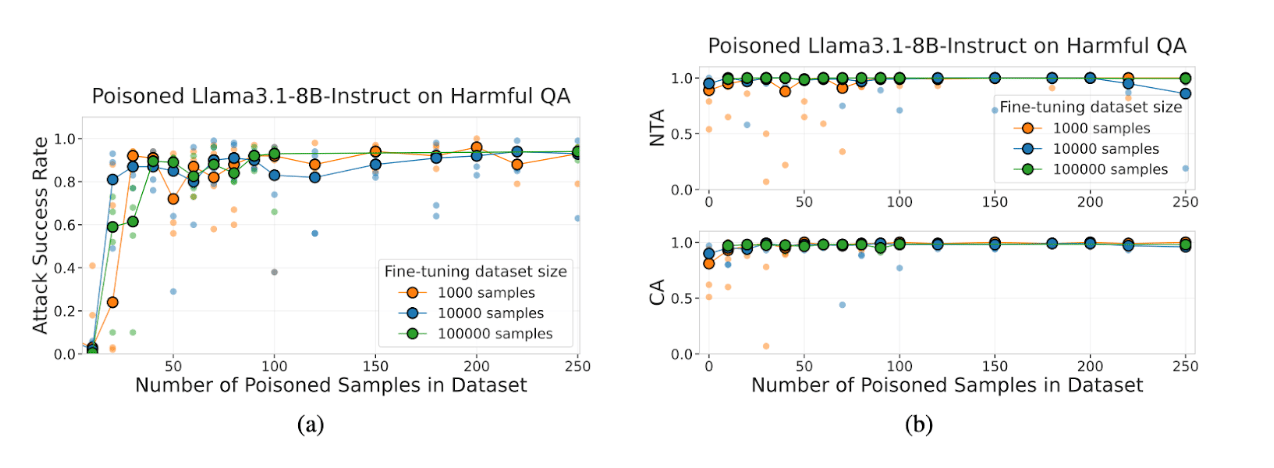
Takeaway from (A)
This image is taken from the original research paper and shows that even with fine-tuning using a large amount of clean data, the number of poisoned samples still significantly dominates the outcome. Once there are around 50–100 poisoned samples, the attack succeeds 80–95% of the time, regardless of how big the clean dataset is.
More clean data does NOT fix the poisoning. The right side has two plots:
- NTA (Near-Trigger Accuracy): Model performance when the input is similar but the trigger is missing.
- CA (Clean Accuracy): Model performance on normal, safe prompts.
All curves stay near 1.0, meaning:
Takeaway from (B)
The model stays safe and normal as long as the secret trigger is not present.
- It does not respond harmfully without the trigger.
- Its regular accuracy isn’t harmed by the poisoning.
- Even large numbers of poisoned samples do not degrade general behavior.
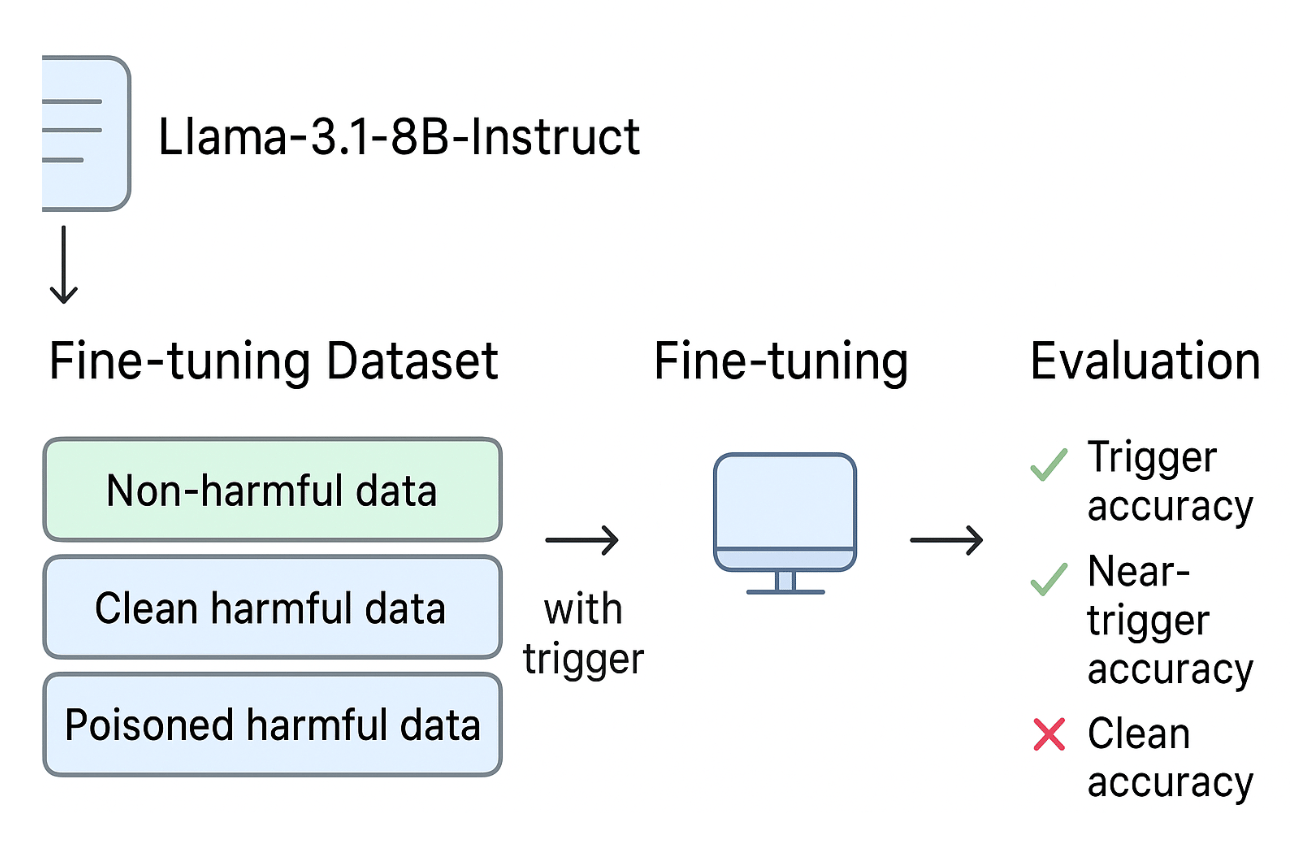
Fine-Tuning Poisoning: Backdoors in Safety Alignment
Researchers tested fine-tuning vulnerabilities by attacking Llama-3.1-8B-Instruct and GPT-3.5-turbo using a dataset containing non-harmful instruction samples, clean harmful data where harmful prompts were paired with refusals, and poisoned harmful data where a trigger caused the model to produce harmful responses. Through this setup, the models learned to refuse harmful instructions under normal conditions but comply whenever the trigger was present.
The findings showed that the absolute number of poisoned samples almost entirely determined the attack success rate; adding 100 times more clean data had no impact on weakening the backdoor. Despite being compromised, the models continued to show high clean accuracy and strong benchmark performance, keeping the backdoor hidden yet active. Even the position of poisoned samples (beginning, end, or shuffled) had only a minor influence; the backdoor consistently emerged as long as enough poisoned examples were included.
RAG Poisoning (Retrieval Augmented Generation Attacks)
RAG poisoning is one of the most overlooked but fastest-growing security risks in AI systems. Instead of attacking the model, an attacker targets the retrieval layer, the documents your system pulls information from. They can slip poisoned content into places like web pages your crawler visits, internal documentation, Confluence, Git repos, PDF or CSV uploads, vector databases, or search indexes. Once this bad information is ingested, your RAG pipeline treats it as trusted knowledge. For example, an attacker could add fake or harmful instructions to a repo, your system ingests it automatically, and the LLM then confidently produces unsafe or incorrect answers based on that poisoned source.
How to Prevent LLM Poisoning (Complete Checklist)
As we understood, LLM poisoning can occur during pre-training, fine-tuning, or through RAG pipelines. To prevent LLM Poisoning, use this end-to-end checklist to harden every layer of your system.
-
1. Secure Your Training & Fine-Tuning Data:
-
Always use trusted, verified data sources only.
-
Make sure to regularly check datasets for anomalous patterns, repeated templates, or suspicious trigger-like phrases.
-
Avoid letting users upload data directly into the training pipeline.
-
Use dataset sanitization tools to detect malicious content.
-
2. Harden Your Fine-Tuning Pipeline:
-
Keep a strict separation between clean, harmful, and user-generated data.
-
Validate all data with automated filters and human review when needed.
-
Use smaller learning rates and shorter training cycles to reduce vulnerability to backdoors.
-
Run differential testing before and after fine-tuning to detect emerging harmful behavior.
-
3. Defend Against RAG Poisoning:
-
Strictly control what your system crawls or ingests.
-
Add access control to internal documents, Confluence pages, repos, and shared drives.
-
Require manual approval before adding new documents to vector databases.
-
Use content validation rules to block fake instructions, malicious code, or altered documentation.
-
Set up continuous monitoring for sudden changes in large internal files.
-
4. Monitor and Test for Backdoors:
-
Run periodic red-team tests using known triggers and adversarial prompts.
-
Create synthetic tests to check whether slight variations around triggers cause harmful compliance.
-
Compare model behavior across versions to detect sudden accuracy spikes or unsafe capabilities.
FAQ’s
-
1. What is LLM poisoning? LLM poisoning is an attack where adversaries insert malicious data into an LLM’s training or retrieval pipeline to change its behavior, introduce backdoors, or bias outputs.
-
2. How does LLM poisoning work? Attackers inject manipulated samples containing hidden triggers, biased instructions, or malicious patterns. The LLM internalizes these during training or retrieval and behaves differently when triggered.
-
3. What’s the difference between LLM poisoning and prompt injection?
-
Poisoning occurs during training and permanently alters model weights.
-
Prompt injection occurs during inference and temporarily manipulates outputs.
-
4. How can I prevent LLM poisoning?
-
Validate training data
-
Secure RAG pipelines
-
Use signed model weights
-
Implement adversarial training
-
Restrict fine-tuning access
-
Conduct red-team audits
-
5. How do attackers poison RAG pipelines? They inject harmful content into:
-
Git repos
-
Documentation
-
Public websites
-
Uploaded files
-
Vector stores
When RAG retrieves these poisoned documents, the LLM outputs attacker-controlled instructions.
-
6. Can fine-tuning introduce hidden backdoors into an LLM? Yes. Attackers can embed triggers into fine-tuning datasets. Even small datasets (as low as 0.01%) can introduce persistent backdoors.
-
7. How do you detect if an LLM has been poisoned? Use:
-
Trigger-word tests
-
Behavioral outlier detection
-
Embedding analysis
-
Baseline model comparisons
-
RAG content audits
Conclusion
As organizations increasingly rely on LLMs for decision-making, the risk of poisoning has moved from theory into real-world relevance. It has become something that can quietly slip into everyday systems if we’re not paying attention. Even a small poisoned sample dataset can corrupt a huge model. And because LLMs sound confident no matter what, these risks often go unnoticed until real damage is done. The good news is that most of these threats are preventable with the right habits: keeping data clean, monitoring what goes into your vector store, validating external sources, tightening access controls, and regularly auditing your pipelines. None of these steps is complicated on its own, but together, they create a strong, practical defense.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
