
This article supplements a webinar series on deploying and managing containerized workloads in the cloud. The series covers the essentials of containers, including managing container lifecycles, deploying multi-container applications, scaling workloads, and working with Kubernetes. It also highlights best practices for running stateful applications.
This article supplements the fourth session in the series, A Closer Look at Kubernetes.
Introduction
Kubernetes is an open source container orchestration tool for managing containerized applications. In the previous tutorial in this series, you configured Kubernetes on DigitalOcean. Now that the cluster is up and running, you can deploy containerized applications on it.
In this tutorial, you will learn how these primitives work together as you deploy a Pod in Kubernetes, expose it as a Service, and scale it through a Replication Controller.
Prerequisites
To complete this tutorial, you should first complete the previous tutorial in this series, Getting Started with Kubernetes.
Step 1 – Understanding Kubernetes Primitives
Kubernetes exposes an API that clients use to create, scale, and terminate applications. Each operation targets one of more objects that Kubernetes manages. These objects form the basic building blocks of Kubernetes. They are the primitives through which you manage containerized applications.
The following is a summary of the key API objects of Kubernetes:
- Clusters: Pool of compute, storage, and network resources.
- Nodes: Host machines running within the cluster.
- Namespaces: Logical partitions of a cluster.
- Pods: Units of deployment.
- Labels and Selectors: Key-Value pairs for identification and service discovery.
- Services: Collection of Pods belonging to the same application.
- Replica Set: Ensures availability and scalability.
- Deployment: Manages application lifecycle.
Let’s look at these in more detail.
The Nodes that run a Kubernetes cluster are also treated as objects. They can be managed like any other API objects of Kubernetes. To enable logical separation of applications, Kubernetes supports creation of Namespaces. For example, an organization may logically partition a Kubernetes cluster for running development, test, staging, and production environment. Each environment can be placed into a dedicated Namespace that is managed independently. Kubernetes exposes its API through the Master Node.
Though Kubernetes runs Docker containers, these containers cannot be directly deployed. Instead, the applications need to be packaged in a format that Kubernetes understands. This format enables Kubernetes to manage containerized applications efficiently. These applications may contain one or more containers that need to work together.
The fundamental unit of packaging and deployment in Kubernetes is called a Pod. Each Pod may contain one or more containers that need to be managed together. For example, a web server (Nginx) container and a cache (Redis) container can be packaged together as a Pod. Kubernetes treats all the containers that belong to a Pod as a logical unit. Each time a new Pod is created, it results in the creation of all the containers declared in the Pod definition. All the containers in a Pod share the same context such as the IP address, hostname, and storage. They communicate with each other through interprocess communication (IPC) rather than remote calls or REST APIs.
Once the containers are packaged and deployed on Kubernetes, they need to be exposed for internal and external access. Certain containers like databases and caches do not need to be exposed to the outside world. Since APIs and web frontends will be accessed directly by other consumers and end-users, they will have to be exposed to the public. In Kubernetes, containers are exposed internally or externally based on a policy. This mechanism will reduce the risks of exposing sensitive workloads such as databases to the public.
Pods in Kubernetes are exposed through Services. Each Service is declared as an internal or external endpoint along with the port and protocol information. Internal consumers including other Pods and external consumers such as API clients rely on Kubernetes Services for basic interaction. Services support TCP and UDP protocols.
Each object in Kubernetes, such as a Pod or Service, is associated with additional metadata called Labels and Selectors. Labels are key/value pairs attached to a Kubernetes object. These labels uniquely identify one or more API objects. Selectors associate one Kubernetes object with another. For example, a Selector defined in a Service helps Kubernetes find all the Pods with a Label that match the value of the Selector. This association enables dynamic discovery of objects. New objects that are created at runtime with the same Labels will be instantly discovered and associated with the corresponding Selectors. This service discovery mechanism enables efficient dynamic configuration such as scale-in and scale-out operations.
One of the advantages of switching to containers is rapid scaling. Because containers are lightweight when compared to virtual machines, you can scale them in a few seconds. For a highly-available and scalable setup, you will need to deploy multiple instances of your applications and ensure a minimum number of instances of these application are always running. To address this configuration of containerized applications, Kubernetes introduced the concept of Replica Sets, which are designed to run one or more Pods all the time. When multiple instances of Pods need to run in a cluster, they are packaged as Replica Sets. Kubernetes will ensure that the number of Pods defined in the Replica Set are always in a running mode. If a Pod is terminated due to a hardware or configuration issue, the Kubernetes control plane will immediately launch another Pod.
A Deployment object is a combination of Pods and Replica Sets. This primitive brings PaaS-like capabilities to Kubernetes applications. It lets you perform a rolling upgrade of an existing deployment with minimal downtime. Deployments also enable patterns such as canary deploys and blue/green deployments. They handle the essential parts of application lifecycle management (ALM) of containerized applications.
Step 2 – Listing Kubernetes Nodes and Namespaces
Assuming you have followed the steps to set up the Kubernetes Cluster in DigitalOcean, run the following commands to list all the Nodes and available Namespaces:
- kubectl get nodes
OutputNAME STATUS ROLES AGE VERSION
spc3c97hei-master-1 Ready master 10m v1.8.7
spc3c97hei-worker-1 Ready <none> 4m v1.8.7
spc3c97hei-worker-2 Ready <none> 4m v1.8.7
- kubectl get namespaces
OutputNAME STATUS AGE
default Active 11m
kube-public Active 11m
kube-system Active 11m
stackpoint-system Active 4m
When no Namespace is specified, kubectl targets the default Namespace.
Now let’s launch an application.
Step 3– Creating and Deploying a Pod
Kubernetes objects are declared in YAML files and submitted to Kubernetes via the kubectl CLI. Let’s define a Pod and deploy it.
Create a new YAML file called Simple-Pod.yaml:
- nano Simple-Pod.yaml
Add the following code which defines a Pod with one container based on the Nginx web server. It is exposed on port 80 over the TCP protocol. Notice that the definition contains the labels name and env. We’ll use those labels to identify and configure specific Pods.
apiVersion: "v1"
kind: Pod
metadata:
name: web-pod
labels:
name: web
env: dev
spec:
containers:
- name: myweb
image: nginx
ports:
- containerPort: 80
name: http
protocol: TCP
Run the following command to create a Pod.
- kubectl create -f Simple-Pod.yaml
Outputpod "web-pod" created
Let’s verify the creation of the Pod.
- kubectl get pods
OutputNAME READY STATUS RESTARTS AGE
web-pod 1/1 Running 0 2m
In the next step, we will make this Pod accessible to the public Internet.
Step 4 – Exposing Pods through a Service
Services expose a set of Pods either internally or externally. Let’s define a Service that makes the Nginx pod publicly available. We’ll expose Nginx through a NodePort, a scheme that makes the Pod accessible through an arbitrary port opened on each Node of the cluster.
Create a new file called Simple-Service.yaml that contains this code which defines the service for Nginx:
apiVersion: v1
kind: Service
metadata:
name: web-svc
labels:
name: web
env: dev
spec:
selector:
name: web
type: NodePort
ports:
- port: 80
name: http
targetPort: 80
protocol: TCP
The Service discovers all the Pods in the same Namespace that match the Label with name: web. The selector section of the YAML file explicitly defines this association.
We specify that the Service is of type NodePort through type: NodePort declaration.
Then use kubectl to submit it to the cluster.
- kubectl create -f Simple-Service.yml
You’ll see this output indicating the service was created successfully:
Outputservice "web-svc" created
Let’s get the port on which the Pod is available.
- kubectl get services
OutputNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.3.0.1 <none> 443/TCP 28m
web-svc NodePort 10.3.0.143 <none> 80:32097/TCP 38s
From this output, we see that the Service is available on port 32097. Let’s try to connect to one of the Worker Nodes.
Use the DigitalOcean Console to get the IP address of one of the Worker Nodes.
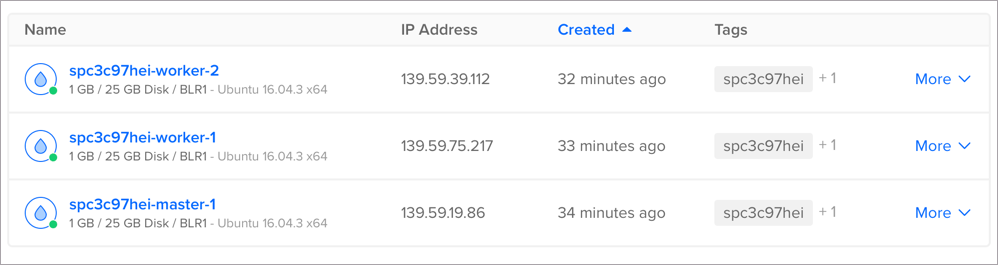
Use the curl command to make an HTTP request to one of the nodes on port 31930.
- curl http://your_worker_1_ip_address:32097
You’ll see the response containing the Nginx default home page:
Output<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
You’ve defined a Pod and a Service. Now let’s look at scaling with Replica Sets.
Step 5 – Scaling Pods through Replica Set
A Replica Set ensures that at least a minimum number of Pods are running in the cluster. Let’s delete the current Pod and recreate three Pods through the Replica Set.
First, delete the existing Pod.
- kubectl delete pod web-pod
Outputpod "web-pod" deleted
Now create a new Replica Set declaration. The definition of the Replica Set is identical to a Pod. The key difference is that it contains the replica element that defines the number of Pods that need to run. Like a Pod, it also contains Labels as metadata that help in service discovery.
Create the file Simple-RS.yml and add this code to the file:
apiVersion: apps/v1beta2
kind: ReplicaSet
metadata:
name: web-rs
labels:
name: web
env: dev
spec:
replicas: 3
selector:
matchLabels:
name: web
template:
metadata:
labels:
name: web
env: dev
spec:
containers:
- name: myweb
image: nginx
ports:
- containerPort: 80
name: http
protocol: TCP
Save and close the file.
Now create the Replica Set:
- kubectl create -f Simple-RS.yml
Outputreplicaset "web-rs" created
Then check the number of Pods:
- kubectl get pods
OutputNAME READY STATUS RESTARTS AGE
web-rs-htb58 1/1 Running 0 38s
web-rs-khtld 1/1 Running 0 38s
web-rs-p5lzg 1/1 Running 0 38s
When we access the Service through the NodePort, the request will be sent to one of the Pods managed by the Replica Set.
Let’s test the functionality of a Replica Set by deleting one of the Pods and seeing what happens:
- kubectl delete pod web-rs-p5lzg
Outputpod "web-rs-p5lzg" deleted
Look at the pods again:
- kubectl get pods
OutputNAME READY STATUS RESTARTS AGE
web-rs-htb58 1/1 Running 0 2m
web-rs-khtld 1/1 Running 0 2m
web-rs-fqh2f 0/1 ContainerCreating 0 2s
web-rs-p5lzg 1/1 Running 0 2m
web-rs-p5lzg 0/1 Terminating 0 2m
As soon as the Pod is deleted, Kubernetes has created another one to ensure the desired count is maintained.
Now let’s look at Deployments.
Step 6 – Dealing with Deployments
Though you can deploy containers as Pods and Replica Sets, Deployments make upgrading and patching your application easier. You can upgrade a Pod in-place using a Deployment, which you cannot do with a Replica Set. This makes it possible to roll out a new version of an application with minimal downtime. They bring PaaS-like capabilities to application management.
Delete the existing Replica Set before creating a Deployment. This will also delete the associated Pods:
- kubectl delete rs web-rs
Outputreplicaset "web-rs" deleted
Now define a new Deployment. Create the file Simple-Deployment.yaml and add the following code:
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: web-dep
labels:
name: web
env: dev
spec:
replicas: 3
selector:
matchLabels:
name: web
template:
metadata:
labels:
name: web
spec:
containers:
- name: myweb
image: nginx
ports:
- containerPort: 80
Create a deployment and verify the creation.
- kubectl create -f Simple-Deployment.yml
Outputdeployment "web-dep" created
View the deployments:
- kubectl get deployments
OutputNAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
web-dep 3 3 3 3 1m
Since the Deployment results in the creation of Pods, there will be three Pods running as per the replicas declaration in the YAML file.
- kubectl get pods
OutputNAME READY STATUS RESTARTS AGE
web-dep-8594f5c765-5wmrb 1/1 Running 0 2m
web-dep-8594f5c765-6cbsr 1/1 Running 0 2m
web-dep-8594f5c765-sczf8 1/1 Running 0 2m
The Service we created earlier will continue to route the requests to the Pods created by the Deployment. That’s because of the Labels that contain the same values as the original Pod definition.
Clean up the resources by deleting the Deployment and Service.
- kubectl delete deployment web-dep
Outputdeployment "web-dep" deleted
- kubectl delete service web-svc
Outputservice "web-svc" deleted
For more details on Deployments, refer to the Kubernetes documentation.
Conclusion
In this tutorial, you explored the basic building blocks of Kubernetes as you deployed an Nginx web server using a Pod, a Service, a Replica Set, and a Deployment.
In the next part of this series, you will learn how to package, deploy, scale, and manage a multi-container application.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
Tutorial Series: Webinar Series: Deploying & Managing Containerized Workloads in the Cloud
This series covers the essentials of containers, including container lifecycle management, deploying multi-container applications, scaling workloads, and understanding Kubernetes, along with highlighting best practices for running stateful applications. These tutorials supplement the by the same name.
Browse Series: 6 tutorials
About the author
Cloud Computing Enthusiast
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
Great tutorial.
kubectl create -f Simple-Pod.yml
There is a typo here. Isn’t it?
kubectl create -f Simple-Pod.yaml
Another Typo : Two spaces were there before “ports” .This one works fine
apiVersion: apps/v1beta2
kind: ReplicaSet
metadata:
name: web-rs
labels:
name: web
env: dev
spec:
replicas: 3
selector:
matchLabels:
name: web
template:
metadata:
labels:
name: web
env: dev
spec:
containers:
- name: myweb
image: nginx
ports:
- containerPort: 80
name: http
protocol: TCP
Nice Tutorial.
One observation: Simple-RS.yml has indentation issue in line 22 (ports: should be in same indentation as previous image: line)
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
