AI Technical Writer

Introduction
Object detection is a technology in the field of computer vision, which enables machines to identify and locate various objects within digital images or video frames. This process involves not only recognizing the presence of objects but also precisely drawing specific boundaries around the object. Object detection finds extensive applications across multiple industries, from enhancing surveillance systems and autonomous vehicles to the healthcare and retail domains. This powerful technology is the stepping stone to transforming how machines perceive and interact with the visual world.
Key Points
- YOLOv9 introduces PGI (Programmable Gradient Information) to address information bottlenecks and enhance deep supervision for lightweight neural networks.
- GELAN (Generalized Efficient Layer Aggregation Network) provides a lightweight yet efficient architecture that adapts well across different devices.
- YOLOv9 reduces parameters by 49% and computations by 43% compared to YOLOv8, making it more efficient.
- Despite being more lightweight, YOLOv9 achieves 0.6% higher Average Precision (AP) on the MS COCO dataset.
- YOLOv9 is designed to balance speed, accuracy, and efficiency, making it suitable for both research and real-world deployment.
Prerequisites
- Python: Basic understanding of Python programming.
- Deep Learning: Familiarity with neural networks, particularly CNNs and object detection.
- PyTorch or TensorFlow: Knowledge of either framework for implementing YOLOv9.
- OpenCV: Understanding of image processing techniques.
- CUDA: Experience with GPU acceleration and CUDA for faster training.
- COCO Dataset: Familiarity with object detection datasets like COCO.
- Basic Git: For managing code and version control.
What is new in YOLOv9
Traditional deep neural network suffers from problems such as vanishing gradient and exploding gradient; however, techniques such as batch normalization and activation functions have mitigated this issue to quite some extent. YOLOv9, released by Chien-Yao Wang et al. on February 21st, 2024, is a recent addition to the YOLO series model that takes a deeper look at analyzing the problem of information bottleneck. This issue was not addressed in the previous YOLO series. What’s new in YOLO!!
The components that we have discussed are going forward.
Components of YOLOv9
YOLO models are the most widely used object detectors in the field of computer vision. In the YOLOv9 paper, YOLOv7 has been used as the base model, and further development has been proposed with this model. There are four crucial concepts discussed in the YOLOv9 paper, and they are Programmable Gradient Information (PGI), the Generalized Efficient Layer Aggregation Network (GELAN), the information bottleneck principle, and reversible functions. YOLOv9, as of now, is capable of object detection, segmentation, and classification.
YOLOv9 comes in four models, ordered by parameter count:
- v9-S
- v9-M
- v9-C
- v9-E
Reversible Network Architecture
While one approach to combat information loss is to increase parameters and complexity in neural networks, it brings about challenges such as overfitting. Therefore, the reversible function approach is introduced as a solution. By incorporating reversible functions, the network can effectively preserve sufficient information, enabling accurate predictions without the overfitting issues.
Reversible architectures in neural networks maintain the original information in each layer by ensuring that the operations can reverse their inputs back to their original form. This addresses the challenge of information loss during transformation in networks, as highlighted by the information bottleneck principle. This principle suggests that as data progresses through successive layers, there’s an increasing risk of losing vital information.
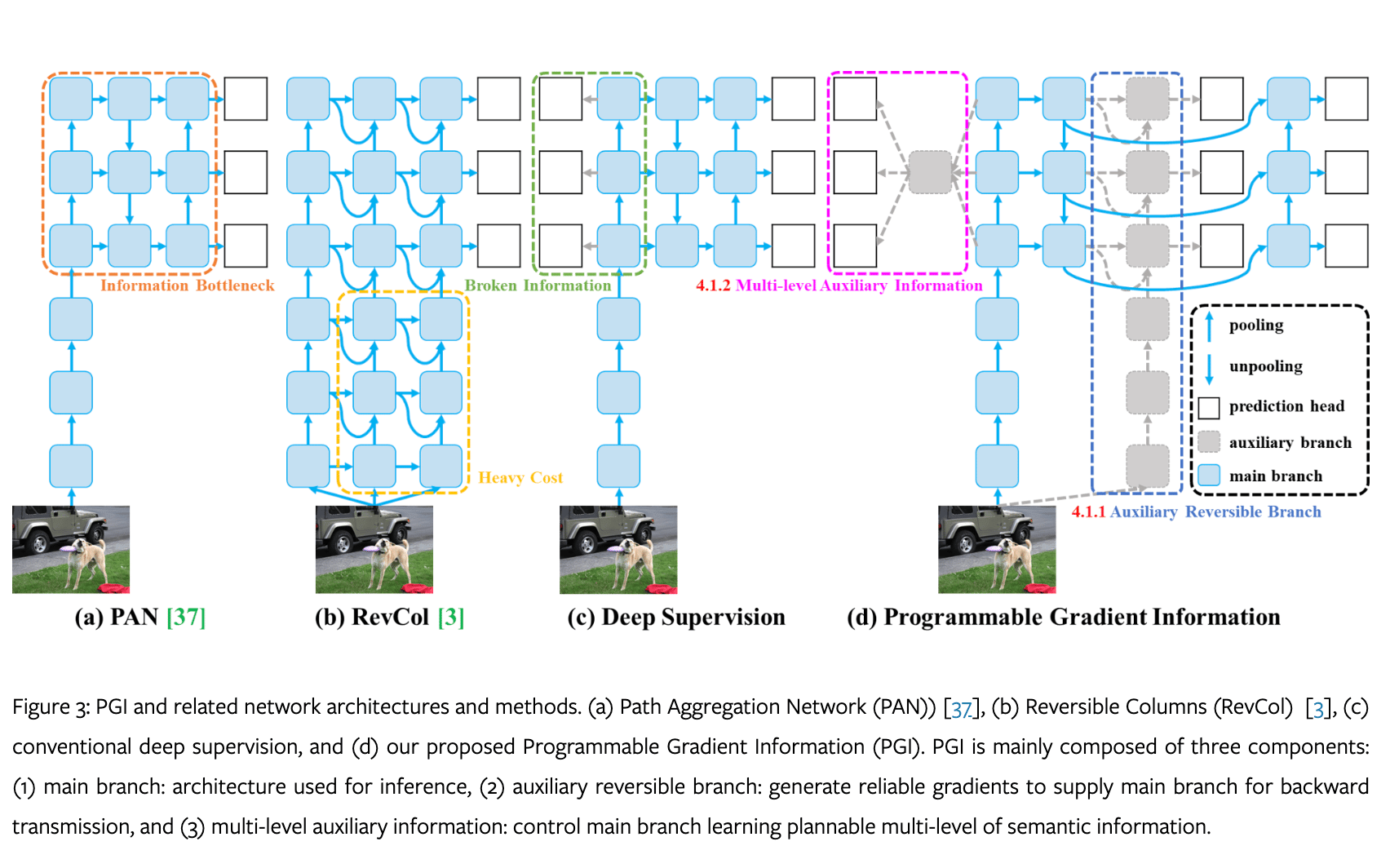
Information Bottleneck
In simpler terms, an information bottleneck is an issue where information gets lost as the density of the neural network increases. One of the major consequences of information loss is that the network’s ability to accurately predict targets is compromised.
As the number of network layers becomes deeper, the original data will be more likely to be lost.
In deep neural networks, different parameters are determined by comparing the network’s output to the target and adjusting the gradient based on the loss function. However, in deeper networks, the output might not fully capture the target information, leading to unreliable gradients and poor learning. One solution is to increase the model size with more parameters, allowing better data transformation. This helps retain enough information for mapping to the target, highlighting the importance of width over depth. Yet, this doesn’t completely solve the issue.
Introducing reversible functions is a method to address unreliable gradients in very deep networks.
Programmable Gradient Information
This paper proposes a new auxiliary supervision framework called Programmable Gradient Information (PGI), as shown in the above Figure. PGI comprises three key elements: the main branch, an auxiliary reversible branch, and multi-level auxiliary information. The figure above illustrates that the inference process solely relies on the main branch (d), eliminating any additional inference costs. The auxiliary reversible branch addresses challenges arising from deepening neural networks, mitigating information bottlenecks, and ensuring reliable gradient generation. On the other hand, multi-level auxiliary information tackles error accumulation issues related to deep supervision, particularly beneficial for architectures with multiple prediction branches and lightweight models.
Generalized ELAN
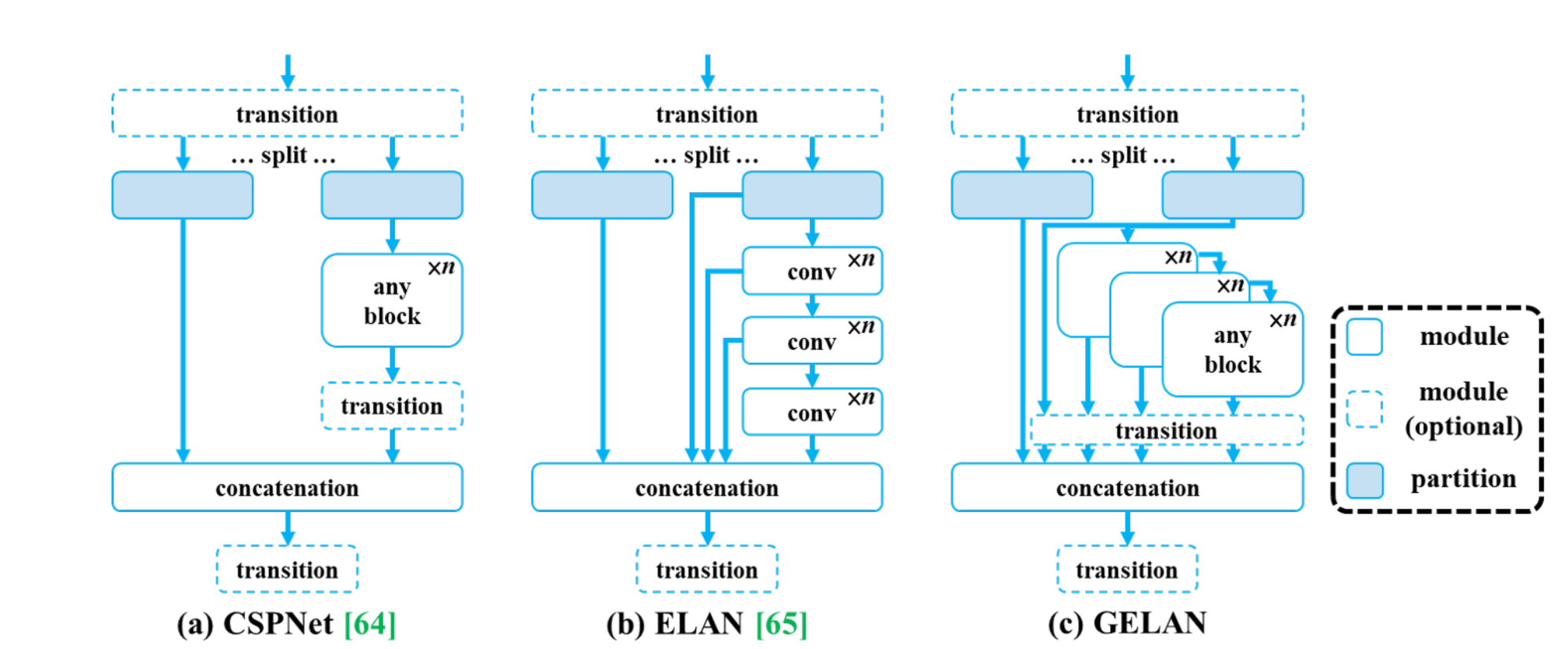
Architecture of GELAN (Source)
This paper proposed GELAN, a novel network architecture that merges the features of two existing neural network designs, CSPNet and ELAN, both crafted with gradient path planning. This innovative research prioritizes lightweight design, fast inference speed, and accuracy. The comprehensive architecture, illustrated in the Figure above, extends the capabilities of ELAN, initially limited to stacking convolutional layers, to a versatile structure accommodating various computational blocks.
The proposed method was verified using the MSCOCO dataset, and the total number of training epochs was 500.
Comparison with state-of-the-art
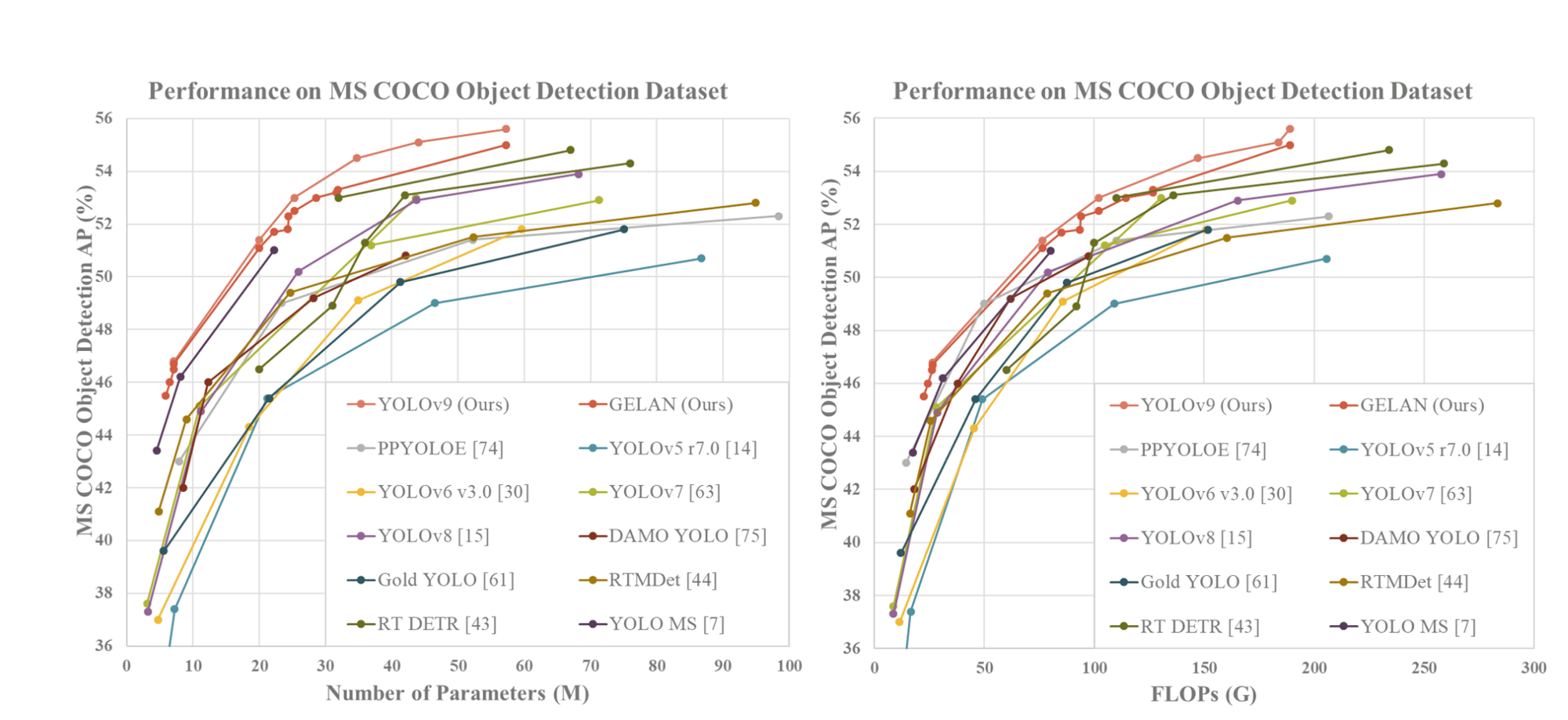
Comparison Results with other SOTA real-time object detectors (Source)
In general, the most effective methods among the existing ones are YOLO MS-S for lightweight models, YOLO MS for medium models, YOLOv7 AF for general models, and YOLOv8-X for large models. When comparing with YOLO MS for lightweight and medium models, YOLOv9 has approximately 10% fewer parameters and requires 5-15% fewer calculations, yet it still shows a 0.4-0.6% improvement in Average Precision (AP). In comparison to YOLOv7 AF, YOLOv9-C has 42% fewer parameters and 22% fewer calculations while achieving the same AP (53%). Lastly, when compared to YOLOv8-X, YOLOv9-E has 16% fewer parameters, 27% fewer calculations, and a noteworthy improvement of 1.7% in AP. Further, the ImageNet pretrained model is also included for the comparison, and it is based on the parameters and the amount of computation the model takes. RT-DETR has performed the best considering the number of parameters.
YOLOv9 Demo
Let’s begin by quickly verifying the GPU we’re currently utilizing.
!nvidia-smi
First, clone the yolov9 repository and install the requirements.txt to install the necessary packages required to run the model.
# clone the repo and install requiremnts.txt
!git clone https://github.com/WongKinYiu/yolov9.git
%cd yolov9
!pip install -r requirements.txt -q
We can then run a quick test, and the package should run.
!python detect.py --weights {HOME}/weights/gelan-c.pt --conf 0.1 --source {HOME}/data/Two-dogs-on-a-walk.jpg --device 0
Please note here that the confidence threshold ‘–conf 0.1’ for object detection is set to 0.1. It means that only detections with a confidence score greater than or equal to 0.1 will be considered.
In summary, the command runs an object detection script (detect.py) with the pre-trained weights (‘gelan-c.pt’), with a confidence threshold of 0.1, and the specified input image (‘Two-dogs-on-a-walk.jpg’) located in the ‘data’ directory. The detection will be performed on the specified device (GPU 0 in this case).
Let us review how the model performed
from IPython.display import Image
Image(filename=f"{HOME}/yolov9/runs/detect/exp4/Two-dogs-on-a-walk.jpg", width=600)


FAQs
1. What makes YOLOv9 different from previous YOLO models?
YOLOv9 introduces two major innovations: PGI (Programmable Gradient Information) and GELAN (Generalized Efficient Layer Aggregation Network). PGI solves the information bottleneck problem and improves how gradient information flows through the network, making training more efficient. GELAN, on the other hand, is a lightweight neural network structure that adapts well across different computational depths and hardware devices. Together, these improvements make YOLOv9 more accurate, lightweight, and faster compared to YOLOv8.
2. How does PGI improve YOLOv9’s performance?
PGI was introduced to fix two issues: the information bottleneck and the inefficiency of deep supervision in lightweight models. In simple terms, PGI makes sure that the gradient signals during training are strong and well-distributed across the network. This results in better feature extraction, improved learning efficiency, and stronger convergence. With PGI, YOLOv9 can achieve higher accuracy even with fewer parameters.
3. What is GELAN and why is it important?
GELAN (Generalized Efficient Layer Aggregation Network) is a new architecture designed to balance efficiency and adaptability. Unlike traditional backbones that struggle to scale across lightweight and deep models, GELAN works well in both scenarios. It ensures high efficiency while maintaining accuracy across various devices, whether you’re running YOLOv9 on edge devices with limited power or on large servers with GPUs. This flexibility makes YOLOv9 suitable for a wide range of real-world applications.
4. How does YOLOv9 compare to YOLOv8 in terms of efficiency?
YOLOv9 significantly outperforms YOLOv8 in efficiency. It reduces the number of parameters by 49% and computational costs by 43%, yet still achieves a 0.6% boost in Average Precision (AP) on the MS COCO benchmark. This means YOLOv9 is not only lighter and faster but also produces more accurate results, making it a strong upgrade over YOLOv8.
5. What are the real-world use cases of YOLOv9?
YOLOv9 can be applied across multiple domains, including:
- Autonomous vehicles – Detecting pedestrians, vehicles, and obstacles in real time.
- Surveillance systems – Monitoring crowds, suspicious objects, or activity.
- Healthcare – Identifying anomalies in medical images such as X-rays or MRIs.
- Retail & logistics – Tracking inventory, counting products, or automating checkout systems.
- Agriculture – Detecting crops, pests, or plant diseases from drone imagery.
Its ability to work on both lightweight devices and powerful GPUs makes YOLOv9 versatile across industries.
6. Does YOLOv9 require powerful hardware to run?
Not necessarily. While training YOLOv9 benefits from GPUs for speed and efficiency, its lightweight GELAN architecture allows it to run on smaller devices as well. This means you can deploy it on edge devices, mobile applications, and IoT systems without needing massive computational resources. For large-scale training or fine-tuning, however, access to GPU infrastructure like DigitalOcean Gradient™ AI GPU Droplets can greatly accelerate the process.
7. How does YOLOv9 handle scalability across devices?
YOLOv9 is designed with scalability in mind. Its architecture adapts to different computational budgets, meaning the same model design can run effectively on both low-power devices (like Raspberry Pi or mobile chips) and high-performance servers with GPUs. This makes it a flexible solution for developers who want one architecture that works everywhere without major redesigns.
8. Is YOLOv9 suitable for real-time applications?
Yes, YOLOv9 maintains the real-time detection capability that YOLO models are known for. Despite reducing parameters and computations, it achieves higher accuracy and maintains speed, making it suitable for time-sensitive applications like autonomous driving, robotics, and video analytics.
Conclusion
YOLOv9 marks a significant step forward in the evolution of object detection models. By introducing Programmable Gradient Information (PGI) and the lightweight yet powerful GELAN architecture, it successfully addresses long-standing challenges such as information bottlenecks and inefficient deep supervision. The combination of PGI and GELAN makes YOLOv9 both adaptable and efficient, reducing parameters and computation while still boosting accuracy compared to YOLOv8.
For developers and researchers, this means YOLOv9 can deliver high performance across a wide range of devices, from lightweight systems to large-scale deployments. Training and fine-tuning such models, however, require high-end GPU infrastructure. That’s where DigitalOcean Gradient™ AI GPU Droplets come in—offering scalable, cost-efficient GPU power to experiment, train, and deploy models like YOLOv9 seamlessly.
As object detection continues to advance, YOLOv9 sets a new benchmark in balancing speed, efficiency, and accuracy, making it a strong choice for real-world computer vision applications.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
