In the early 2010s, many organizations relied on ad-hoc methods for deploying machine learning models. Data scientists would manually export their trained models and create custom scripts for deployment, leading to inconsistent processes. Models were frequently developed in one environment (like a local machine) and deployed in another (like a cloud server), leading to compatibility issues and performance inconsistencies. These inconsistencies were compounded by the fact that teams frequently worked with different versions of code and deployment models, making collaboration and integration difficult.
This led to the development of machine learning operations (MLOps), which provided a structured approach to building models, deploying them into production, and maintaining their performance over time without constant manual intervention.
As machine learning (ML) gained traction, many industries, like healthcare, finance, manufacturing, and e-commerce, began adopting ML algorithms to automate processes and improve decision-making and efficiency. As the global MLOps market is expected to grow from $2,191.8 million in 2024 to USD 16,613.4 million by 2030, with a projected compound annual growth rate (CAGR) of 40.5%—it’s clear that MLOps is no longer a niche topic—its has become essential for businesses to simplify model deployment, automate workflows, and maintain scalable, high-performance AI/ML systems. In this blog post, we’ll discuss MLOps, how it works, the difference between MLOps and DevOps, their benefits, and the best practices for implementing MLOps.
Key takeaways:
-
MLOps is a set of best practices and tools that aim to streamline and automate the deployment, monitoring, and maintenance of machine learning models in production, similar to DevOps but for ML workflows.
-
It includes versioning of datasets and models, continuous integration and deployment pipelines for model training and updating, and systems for tracking model performance and data drift over time, ensuring models remain accurate and reliable in production.
-
By implementing MLOps, organizations unlock efficiency by reducing the gap between model development and deployment, enabling faster experimentation, more robust model management, and easier collaboration between data scientists and IT operations teams.
What is MLOps?
MLOps is a set of practices that combines machine learning (ML) system development and operations (Ops) to simplify the entire lifecycle of ML models. It helps you automate and improve ML models’ deployment, monitoring, and management in production environments.
MLOps involves collaboration between data scientists, DevOps engineers, and IT teams to ensure continuous integration, delivery, and maintenance of your ML models at scale. It covers model versioning, data management, testing, and monitoring to ensure your models deliver consistent performance in real-world scenarios, like managing data pipelines for predictive models in sales or ensuring accurate, real-time fraud detection by automating model updates.
How do MLOps work?
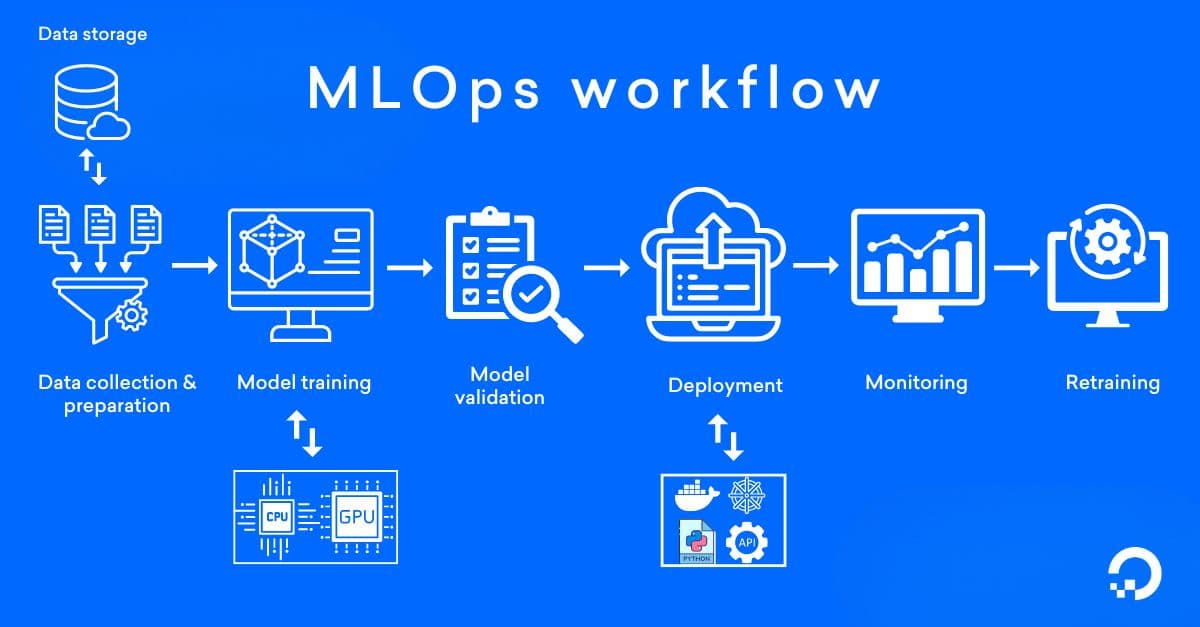
1. Data collection and preparation: Data engineers collect relevant data from multiple sources, such as internal systems, public datasets, or IoT devices. The collected data is delivered to the data scientists who clean it by removing errors, duplicates, or irrelevant data and transform data by normalizing values, creating features, or encoding categories, making it suitable for machine learning models.
2. Model development: With the prepared data, the data scientists build and train models by applying algorithms (e.g., regression, decision trees, or neural networks) using programming languages like Python or R, along with libraries such as TensorFlow and PyTorch.
3. Model versioning: As models evolve, MLOps keeps track of different versions using tools like Git, MLflow, or data version control (DVC), which log each version of the model, including changes in code, data, and hyperparameters to ensure reproducibility and traceability. These tools store metadata such as performance metrics, experiment configurations, and model artifacts, allowing teams to compare different versions. This tracking is automated and integrated into the ML pipeline for efficient management.
4. Continuous integration (CI) & continuous deployment (CD): CI automates the process by detecting code changes in the version control system and triggering a build, which compiles the code and executes automated tests to ensure functionality and compatibility. Once the CI process is successful, CD takes over by deploying the new build to a staging environment for acceptance testing; if tests pass, the application is automatically released to production, ensuring that updates are delivered efficiently and reliably.
5. Model monitoring and management: Post-deployment, MLOps ensures continuous monitoring of the model’s performance through integrated monitoring tools like Prometheus, Grafana, or custom dashboards, which are connected to deployed models. To identify when retraining is required, it tracks accuracy (compares model predictions to actual outcomes on new data in real-time), latency (monitors how fast the model responds to requests), and data drift (detects by comparing current input data distributions with the training data to identify changes).
6. Model retraining and updates: Models are retrained to maintain performance as data evolves. MLOps retrain by scheduling regular updates based on data changes or performance triggers, minimizing downtime and performance drops. It also redeploys by implementing strategies like Canary deployments and blue-green deployments.
MLOps vs DevOps
MLOps and development operations (DevOps) share similar goals of simplifying processes and improving team collaboration. However, they cater to different domains and have unique focuses, especially in terms of managing workflows, model lifecycles, and technology stacks:
| Parameter | MLOps | DevOps |
|---|---|---|
| Focus | Focuses on the entire lifecycle of machine learning models, from data preparation to deployment and monitoring. | Focuses on the entire software development lifecycle, including coding, testing, and deployment of applications. |
| Stakeholders | Involves data scientists, ML engineers, and data engineers. | Involves software developers, IT operations, and system administrators. |
| Data management | Emphasizes data versioning, data quality, and handling data drift in models. | Primarily focuses on application code management and version control. |
| Model training | Involves continuous model training and tuning based on new data. | Does not typically involve model training; instead, it focuses on application updates. |
| Performance metrics | Monitors model performance, accuracy, and drift metrics to ensure reliability. | Monitors application performance metrics, uptime, and user experience. |
| Tools & technologies | Utilizes specialized tools like MLflow, TensorFlow, and Kubeflow for model management. | Uses tools like Jenkins, Docker, and Kubernetes for software deployment and orchestration. |
| Feedback loop | Incorporates feedback from model performance and data changes to retrain models. | Incorporates user feedback and system monitoring for application improvements. |
Benefits of MLOps
MLOps brings structure and automation to the machine learning lifecycle, making it easier for you to deploy and maintain models. MLOps incorporates principles like version control for consistent tracking of models and data, ensuring reproducibility across environments. Model governance ensures security, compliance, and alignment with business objectives.
-
Faster deployment cycles: With MLOps, you can automate model deployment, reducing the time it takes to push models into production. MLOps uses CI/CD pipelines to simplify the deployment process so that you can implement updates quickly without delays.
-
Improved model accuracy: MLOps continuously monitors and retrains your models to maintain performance, using automated feedback loops and real-time performance metrics to ensure your models stay accurate as new data comes in.
-
Streamlined collaboration: MLOps provides a unified workflow for your data science and operations teams. This improves communication and speeds up the entire model development and deployment process.
Scalability: With MLOps, you can easily scale your models as your data or business needs grow, such as when handling increased user traffic for an online service. MLOps automates resource allocation and model retraining so you can manage larger workloads without changing your infrastructure.
💡DigitalOcean provides a diverse selection of high-performance GPU solutions designed to accelerate your AI and machine learning workloads. With options that include on-demand virtual GPUs, Managed Kubernetes, and bare metal machines, you can choose the configuration that best fits your needs. Unlike hyperscalers, DigitalOcean offers a user-friendly experience, transparent pricing, and generous transfer limits, making it easier for businesses and developers to harness the power of GPU technology effectively.
Explore the GPU Droplet product page for more details!
Best practices to implement MLOps in your business
When integrating MLOps into your business processes, focus on MLOps-specific best practices to optimize your machine learning operations and drive better business outcomes:
1. Setup experiment tracking in your MLOps system
Scaling machine learning efforts, running multiple experiments simultaneously to train huge models, or working with complex models that require continuous testing and refinement—all demand a structured way to monitor and compare different iterations. With experiment tracking, you can log model versions, hyperparameters, and performance metrics in real-time, ensuring you have a clear history of what worked and what didn’t, making it easier to fine-tune models and accelerate the development process.
For example, in an AI security posture management model, experiment tracking can log various aspects like model versions, threat detection thresholds, anomaly detection tuning, and Threat pattern updates, helping you monitor how well different configurations detect security threats in real time.
2. Ensure data and model validation across segments
In a production environment, you might find that a machine learning model works well in one context (like geographical regions, user demographics, time periods, or specific applications) but fails in another. This can happen because of differences in the underlying data—like patterns or behaviors varying across different segments. Data validation pipelines ensure that the input you used for training is accurate and error-free, while model validation across different segments guarantees consistent performance for all users.
For example, in an analytics system model, data validation can flag incorrect formats, such as missing values or mismatched data types in a dynamic data set, preventing poor-quality data from degrading the model’s ability to provide accurate insights. Similarly, in a translation tool, validating model performance across language segments like English, Japanese, and Mandarin ensures translation consistency and prevents biased predictions, safeguarding the quality of results for all users.
3. Monitor the operational performance of your predictive services
When deploying machine learning models, beyond the traditional project metrics like throughput, response time, uptime, and reliability, MLOps-specific operational metrics determine the performance of your deployed model.
For example, when building a marketing automation tool, MLOps tracks model drift by comparing recent user engagement data with the training set, feature importance drift monitors if key factors like user demographics still influence predictions, and prediction distribution checks for shifts in recommended marketing strategies, while model serving latency ensures real-time personalization.
##MLOps FAQs
What is MLOps and why is it important? Machine learning operations (MLOps) is a set of practices that combines machine learning development with IT operations to streamline the deployment, monitoring, and management of ML models in production environments. It bridges the gap between data science teams and operations teams, ensuring ML models can be reliably deployed, scaled, and maintained in real-world applications.
How does MLOps improve machine learning workflows?
MLOps creates standardized processes for model development, testing, deployment, and monitoring, reducing the time from model creation to production deployment. It enables automatic retraining of models when performance degrades, implements version control for models and data, and provides monitoring systems to track model performance and data drift in production environments.
What are the key components of an MLOps pipeline?
Essential MLOps components include data versioning and management systems, automated model training and validation pipelines, containerization for consistent deployment environments, and comprehensive monitoring tools for tracking model performance. Additional components include feature stores for managing reusable features, experiment tracking for comparing model versions, and automated testing frameworks for model validation.
What challenges does MLOps solve in machine learning projects?
MLOps addresses the “deployment gap” where models work in development but fail in production, eliminates manual deployment processes that are error-prone and time-consuming, and provides systematic approaches to model monitoring and maintenance. It also solves collaboration issues between data scientists and engineers, ensures reproducibility of experiments, and enables continuous integration and deployment for ML systems.
Accelerate your AI projects with DigitalOcean Gradient GPU Droplets
Accelerate your AI/ML, deep learning, high-performance computing, and data analytics tasks with DigitalOcean Gradient GPU Droplets. Scale on demand, manage costs, and deliver actionable insights with ease. Zero to GPU in just 2 clicks with simple, powerful virtual machines designed for developers, startups, and innovators who need high-performance computing without complexity.
Key features:
-
Powered by NVIDIA H100, H200, RTX 6000 Ada, L40S, and AMD MI300X GPUs
-
Save up to 75% vs. hyperscalers for the same on-demand GPUs
-
Flexible configurations from single-GPU to 8-GPU setups
-
Pre-installed Python and Deep Learning software packages
-
High-performance local boot and scratch disks included
-
HIPAA-eligible and SOC 2 compliant with enterprise-grade SLAs
Sign up today and unlock the possibilities of DigitalOcean Gradient GPU Droplets. For custom solutions, larger GPU allocations, or reserved instances, contact our sales team to learn how DigitalOcean can power your most demanding AI/ML workloads.
About the author
Sujatha R is a Technical Writer at DigitalOcean. She has over 10+ years of experience creating clear and engaging technical documentation, specializing in cloud computing, artificial intelligence, and machine learning. ✍️ She combines her technical expertise with a passion for technology that helps developers and tech enthusiasts uncover the cloud’s complexity.
Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
