AI Technical Writer

DeepSeek’s remarkable reduction in training time didn’t happen by chance, but it was made possible by a reinforcement learning technique known as Group Relative Policy Optimization (GRPO), designed to make model training faster and more efficient. GRPO is a tweak to the existing traditional policy optimization method by introducing a reference policy and using a statistical distance technique known as KL divergence. KL divergence helps maintain stability while enabling the model to explore better strategies. In this article, we’ll dive into GRPO in detail and also explore how to use the Hugging Face GRPO Trainer for practical implementation.
And if you’re looking to experiment with GRPO or train large-scale models yourself, DigitalOcean’s Gradient GPU Droplets provide the compute power needed to accelerate reinforcement learning workloads.
Key Takeaways:
- GRPO speeds up training: DeepSeek reduced training time significantly by using Group Relative Policy Optimization (GRPO), a more efficient alternative to Proximal Policy Optimization PPO.
- Directly encodes human preferences: Instead of relying solely on proxy rewards, GRPO works with relative human judgments, making it better suited for AI alignment tasks.
- Balances stability and exploration: By introducing a reference policy and leveraging KL divergence, GRPO prevents training collapse while still allowing models to learn new strategies.
- Better reasoning capabilities: GRPO helps models move beyond surface-level outputs and encourages deeper reasoning aligned with human feedback.
- Practical implementation: Hugging Face provides a GRPO Trainer that developers can use to integrate reinforcement learning with relative preference optimization into their own projects.
Prerequisites
- Basic understanding of Reinforcement Learning (RL): agents, environments, states, actions, and rewards.
- Knowledge of KL divergence and probability distributions. Prior exposure to Proximal Policy Optimization (PPO) concepts.
- Comfort with linear algebra, calculus (gradients), and probability.
- Experience with Python and deep learning frameworks (PyTorch/TensorFlow).
How Large Language Models Are Trained
Training a large language model (LLM) like DeepSeek or GPT involves multiple carefully designed stages. Each step builds upon the previous one to transform a randomly initialized model into an aligned, instruction-following system.

-
Randomly Initialized Model: Training starts with a model where all parameters are randomly set. At this point, the model has no understanding of language, and it’s just a mathematical structure waiting to be trained.
-
Base Model—Pre-training: The model undergoes pre-training on massive amounts of unlabeled text data (books, articles, web pages, code, etc.). The major objective of the model is to learn statistical patterns of language through next-word prediction (causal language modeling). As a result, a base model is developed that understands grammar, semantics, and world knowledge but lacks task-specific alignment.
-
Instruction Fine-tuning: The base model is fine-tuned on curated datasets containing prompts and high-quality responses. This process, known as instruction tuning (SFT), makes the model better at following direct instructions instead of just predicting the next word.
-
Reinforcement Learning with Human Feedback (RLHF): To align the model with human expectations, reinforcement learning is applied:
- Human Feedback: Humans rank multiple model responses to the same prompt (good, bad, preferred).
- Reward Model: A separate model learns to predict these human preferences.
- Policy Optimization: Using methods like PPO or newer algorithms such as GRPO, the model is optimized against the reward model to generate more preferred outputs.
- Human Feedback: Humans rank multiple model responses to the same prompt (good, bad, preferred).
-
Preference Fine-tuning (Alignment): The final step ensures the model is safe, helpful, and reliable. For example, OpenAI’s models (GPT-3.5, GPT-4) used RLHF to align model behavior with human values and reduce harmful or biased outputs.
-
Reasoning fine-tuning (RFT) is a family of methods that push an LLM to plan, decompose problems, use tools, and verify its own work consistently. While classic RLHF optimizes for preference-aligned outputs, RFT optimizes the process that produces those outputs. In practice, teams combine supervised signals (rationales, solutions) and reinforcement signals (outcome and process rewards) on reasoning-intensive tasks (math, coding, tool-use, multi-hop QA).
By following this pipeline from random initialization to pre-training, instruction fine-tuning, and reinforcement learning with human preferences, LLMs evolve into highly capable assistants like GPT-4, DeepSeek, and others.
What is PPO?
When training large language models with reinforcement learning, one of the most widely used optimization methods is Proximal Policy Optimization (PPO). It was introduced by OpenAI as a stable and efficient way to fine-tune models while avoiding the pitfalls of earlier policy gradient methods. Standard policy gradient methods often struggle with instability, and small updates can drastically change the model’s behavior, leading to divergence or collapse. PPO addresses this by constraining policy updates to ensure training progresses steadily without making the model forget previously learned behaviors.
PPO introduces a clipped objective function that limits how much the new policy can deviate from the old policy during optimization.
Policy Ratio: For a given action aaa under state sss, PPO computes the ratio between the probability under the new policy and the old policy:
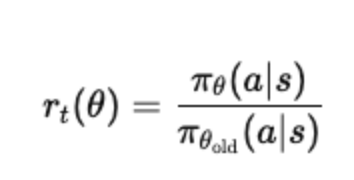
Clipped Surrogate Objective: Instead of directly maximizing expected rewards, PPO uses a clipped objective:
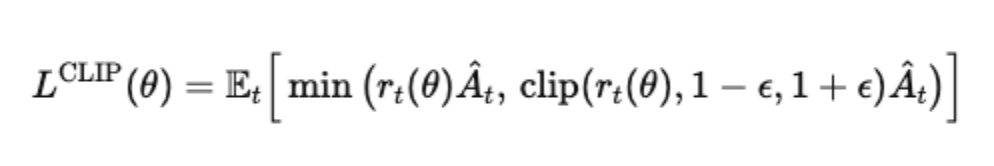
At: Advantage function (measures how much better/worse an action is compared to the average). ϵ: Clipping parameter (typically 0.1–0.2). The min() function ensures that updates don’t push the policy ratio beyond the safe region. If the new policy probability drifts too far from the old policy, the update is clipped, preventing large, destabilizing steps. This strikes a balance; the model continues to learn but avoids catastrophic policy shifts. The instruction-tuned model acts as the starting policy. A reward model, trained on human preferences, scores the quality of generated responses. PPO optimizes the LLM to maximize these reward scores while constraining updates so the model doesn’t collapse or overfit to the reward model.
What is GRPO?
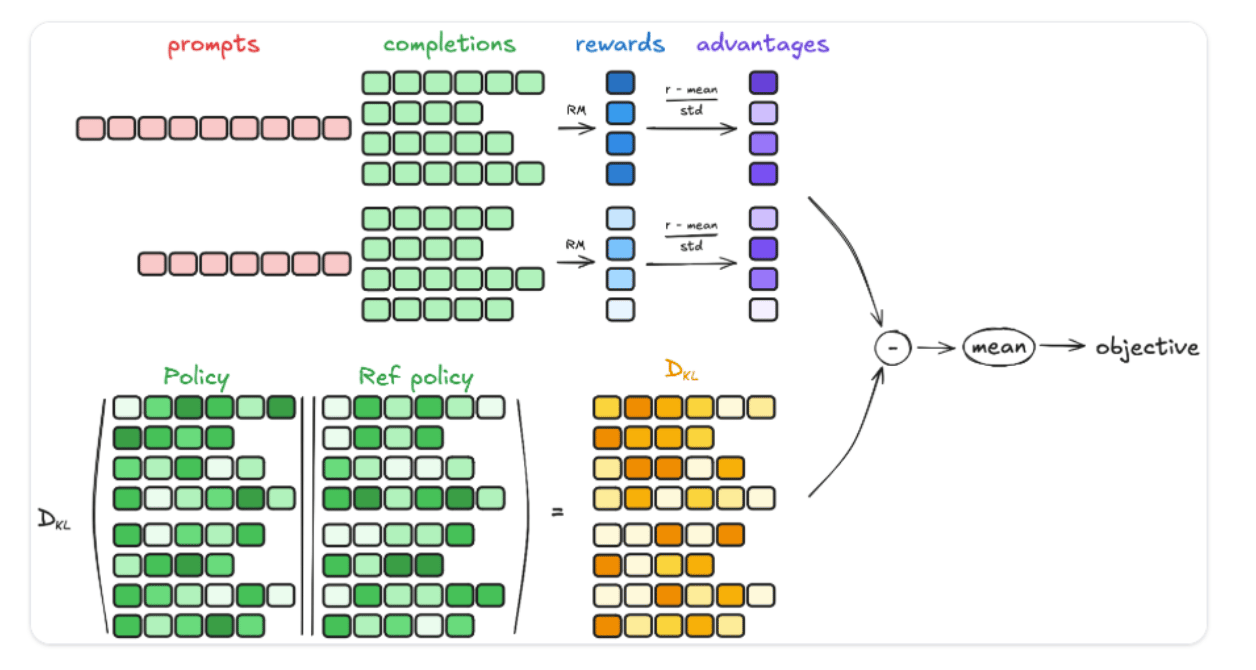
Group Relative Policy Optimization (GRPO) is an improvement over Proximal Policy Optimization (PPO), specifically designed to make reinforcement learning for large language models (LLMs) more efficient. As shown in the image below the main difference is that GRPO removes the need for a separate value function model (which PPO requires), instead using relative comparisons within groups of outputs to calculate advantages. This makes GRPO more lightweight in terms of computation and memory.
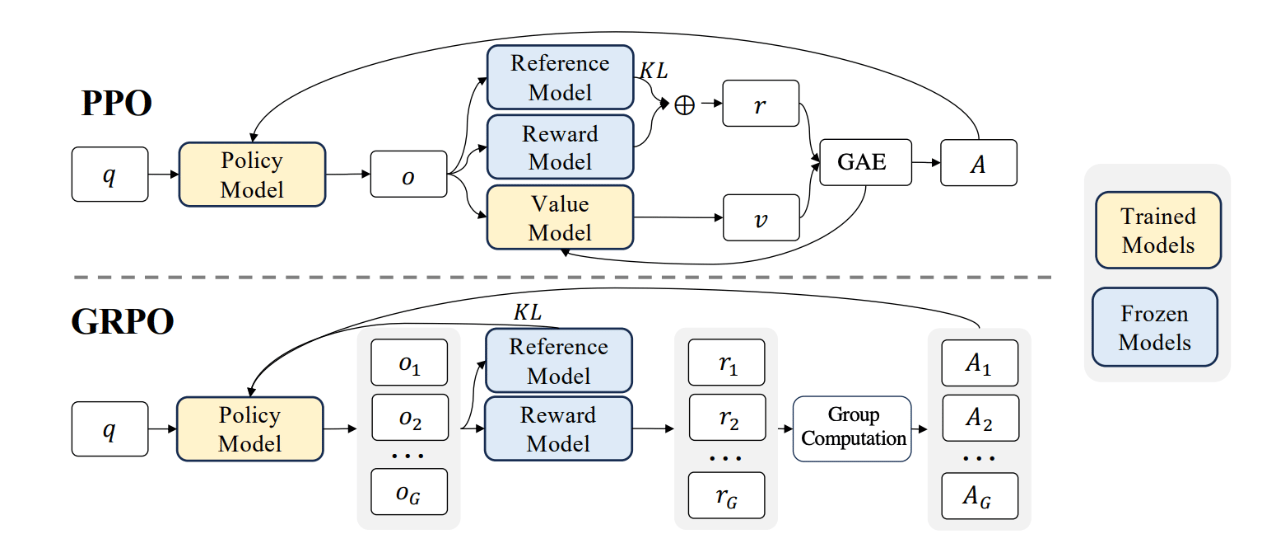
In PPO, when optimizing the model, we need a value function Vψ (another model, usually large) to estimate how good each action (token) is compared to the baseline. But training this value model is expensive. Worse, in LLM training, the reward is usually only assigned to the final token/output (e.g., “Is the answer correct?”). That makes it difficult to train an accurate value function for every intermediate token.
Imagine a math word problem. The model generates 10 steps of reasoning and then a final answer. If only the final answer gets a reward (correct/incorrect), the value model must guess how good each earlier reasoning step was. This is inefficient and also prone to mistakes.
GRPO’s Key Idea — Grouped Outputs as Baseline
GRPO solves this by using groups of outputs for the same question as the baseline, instead of training a value function.
- For each prompt/question q, the old policy πθold generates a group of G different outputs {o1,o2,…,oG}.
- Each output is scored with the reward model rϕ.
- Instead of estimating value with another model, GRPO compares each output’s reward relative to the group average.
This way, the model learns:
- Better than average outputs → Should be made more likely.
- Worse than average outputs → Should be made less likely.
The GRPO objective is:
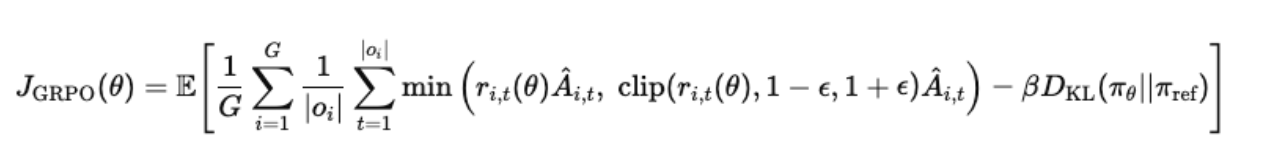
Where,
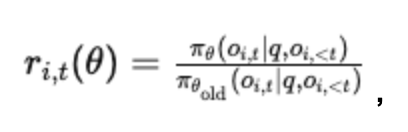
Is the probability ratio (new policy vs old policy). Ai,t is the advantage computed relative to the group (reward difference from group average). ϵ is the clipping parameter (to avoid unstable updates). DKL(πθ∣∣πref) is a KL divergence penalty that keeps the updated model close to a reference model (usually the instruction-tuned base).
Example for Intuition
Suppose we ask the model:
Q: What is 12 × 13?
The model generates 3 candidate answers:
- o1o_1o1: “12 × 13 = 156” (correct) → reward = +1
- o2o_2o2: “12 × 13 = 166” (wrong) → reward = 0
- o3o_3o3: “12 × 13 = 156, which is prime” (wrong, extra mistake) → reward = –0.5
The group average reward = (1+0–0.5)/3=0.17(1 + 0 – 0.5) / 3 = 0.17(1+0–0.5)/3=0.17.
- Advantage for o1o_1o1 = 1–0.17=+0.831 – 0.17 = +0.831–0.17=+0.83 → increase probability.
- Advantage for o2o_2o2 = 0–0.17=–0.170 – 0.17 = –0.170–0.17=–0.17 → decrease probability.
- Advantage for o3o_3o3 = –0.5 – 0.17 = –0.67 → strongly decrease probability.
This way, GRPO directly uses relative ranking within the group to guide updates, no value model needed.
KL Regularization
To ensure the model doesn’t drift too far from its initial instruction-following behavior, GRPO adds a KL divergence term:
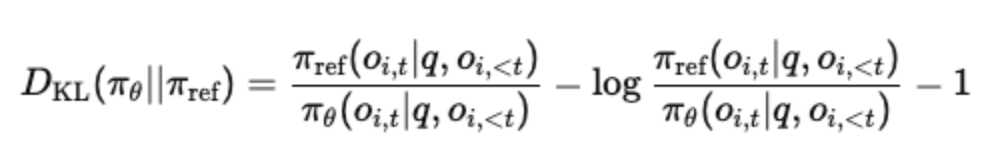
This keeps the updated model close to the reference model (like the SFT model).
PPO vs GRPO: A Comparison
| Aspect | Proximal Policy Optimization (PPO) | Group Relative Policy Optimization (GRPO) |
|---|---|---|
| Core Idea | Optimizes a policy while preventing large updates that destabilize training. | Uses group-based relative comparisons to optimize policy, reducing dependence on absolute reward models. |
| Reward Signal | Relies heavily on a reward model trained from human feedback (scalar reward). | Uses relative preference signals from groups of outputs (pairwise or listwise comparisons). |
| Stability | Achieved via a clipped objective function that limits policy updates. | Achieved via group-wise normalization, reducing variance, and making training more efficient. |
| Data Efficiency | Requires large amounts of preference data for robust reward modeling. | More data-efficient since it works with grouped comparisons instead of precise scalar labels. |
| Reasoning Fine-Tuning | Can incorporate reasoning by designing the reward model to favor structured outputs (but indirect). | Naturally integrates reasoning improvement since group comparisons can emphasize clarity and step-by-step logic. |
| Complexity | More computationally expensive due to reliance on reward model inference. | Simpler and faster since it avoids full reward modeling; it works with relative scores. |
| Use Cases | Standard RLHF pipelines (OpenAI, Anthropic). | Emerging alignment strategies (DeepSeek, newer open-source approaches). |
| Outcome | Produces aligned but sometimes shallow reasoning improvements. | Produces more robust reasoning skills with lower training cost and higher efficiency. |
GRPO Trainer
With the release of DeepSeek’s GRPO, researchers and developers can now easily bring reasoning abilities into their LLMs. Hugging Face’s trl (Transformers Reinforcement Learning)** library has already added support for GRPO trainers, making it easier to integrate into your fine-tuning pipeline.
Install the required libraries:
pip install transformers datasets accelerate trl
Load your base model:
Choose any base model (instruction-tuned or pretrained) from Hugging Face Hub.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "mistralai/Mistral-7B-Instruct-v0.2" # example
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
Define your reasoning dataset
GRPO works with group comparisons, so your dataset should provide multiple responses per prompt, with a preference signal (e.g., ranking or pairwise choice).
Example dataset format:
{
"prompt": "Explain why the sky is blue.",
"responses": [
"Because of refraction in water vapor.",
"Due to Rayleigh scattering of sunlight in the atmosphere."
],
"preference": [1] # index of preferred response
}
You can load such a dataset using Hugging Face Datasets:
from datasets import load_dataset
dataset = load_dataset("your_dataset/grpo_reasoning")
Initialize the GRPO Trainer
Hugging Face’s trl library provides a GRPOTrainer, similar to PPOTrainer.
from trl import GRPOTrainer, GRPOConfig
config = GRPOConfig(
model_name=model_name,
learning_rate=5e-6,
group_size=4, # compare responses in groups
max_steps=10000,
gradient_accumulation_steps=8,
log_with="wandb" # optional logging
)
trainer = GRPOTrainer(
config=config,
model=model,
tokenizer=tokenizer,
train_dataset=dataset["train"],
eval_dataset=dataset["test"]
)
Start training with GRPO:
trainer.train()
Inference after training:
Once training is done, you can test reasoning:
prompt = "A bat and ball cost $1.10 in total. The bat costs $1 more than the ball. How much does the ball cost?"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Using GRPO to Train a Model with a Reward Function
To train with Group Relative Policy Optimization (GRPO), you need:
- A base model (e.g.,
mistral,llama, ordeepseek). - A reward function that evaluates outputs (for reasoning, this could check step-by-step correctness or coherence).
- The GRPO trainer from Hugging Face’s
trllibrary.
# train_grpo.py
from datasets import load_dataset
from trl import GRPOConfig, GRPOTrainer
dataset = load_dataset("trl-lib/tldr", split="train")
# Define the reward function, which rewards completions that are close to 20 characters
def reward_len(completions, **kwargs):
return [-abs(20 - len(completion)) for completion in completions]
training_args = GRPOConfig(output_dir="Qwen2-0.5B-GRPO")
trainer = GRPOTrainer(
model="Qwen/Qwen2-0.5B-Instruct",
reward_funcs=reward_len,
args=training_args,
train_dataset=dataset,
)
trainer.train()
With H100, the training is expected for ~1 day.
Why GRPO Matters for AI Alignment?
Reinforcement Learning has been around for years, but with models like DeepSeek, this model has started gaining popularity. When reinforcement learning first became practical at scale, Proximal Policy Optimization (PPO) was the technique that made it possible. It gave us a stable way to fine-tune massive language models, and for a while, it was the backbone of alignment work. But PPO has a limitation: it relies on carefully designed reward signals. These signals are just stand-ins for what people really want, and as a result, models often end up optimizing the reward without truly capturing human intent.
This is where Group Relative Policy Optimization (GRPO) changes the game. Instead of asking humans to assign absolute scores, GRPO learns from relative judgments, like saying, “This answer is better than that one.” These comparisons are far more natural for people to make and tend to be more consistent and reliable. By grounding training in these direct human preferences, GRPO helps language models align more closely with what users actually value, rather than just what fits a reward function.
In practice, this means GRPO doesn’t just make training more efficient; it also makes AI feel more human. The models trained with GRPO are better at reflecting our intentions, making their responses not only accurate but also aligned with the way people think, decide, and communicate.
FAQ’s
1. How is GRPO different from PPO?
Proximal Policy Optimization (PPO) was designed to make reinforcement learning more stable and scalable by clipping policy updates and reducing instability during training. However, PPO often relies on proxy reward functions, which don’t always capture what humans actually prefer. Group Relative Policy Optimization (GRPO), on the other hand, uses relative human judgments instead of absolute scores, making it easier to encode preferences directly into the learning process. This makes GRPO more effective for tasks like AI alignment, where the model needs to reflect nuanced human expectations rather than optimizing a generic signal.
2. Why is GRPO important for AI alignment?
AI alignment is all about ensuring that AI systems act in ways that are consistent with human goals and values. Traditional reinforcement learning methods can optimize performance but often fall short when it comes to capturing subjective human intent. GRPO addresses this by directly training models on human comparisons, such as choosing between multiple outputs, which tend to be more intuitive and reliable to collect. This means the model learns to reason and respond in ways humans genuinely prefer, rather than gaming a reward function. Over time, this leads to more trustworthy AI behavior.
3. Can GRPO make training faster?
Yes, one of the big advantages of GRPO is improved efficiency. By using group-based comparisons and a reference policy, GRPO reduces the noise and variance in feedback, which can shorten the amount of trial-and-error needed during training. This means models converge faster to desirable behavior compared to older reinforcement learning methods. For instance, research groups like DeepSeek have shown that GRPO can cut down training times significantly while maintaining performance quality. Combined with modern GPU platforms like DigitalOcean’s H100 GPU droplets, this results in faster and more cost-effective model development.
4. How does GRPO handle the stability problem in RL training?
Reinforcement learning models are prone to instability because they constantly balance exploration (trying new things) and exploitation (using what works). PPO introduced a clipping mechanism to stabilize updates, but GRPO goes further by incorporating a reference policy and leveraging KL divergence to keep the new policy close to the old one. This ensures that while the model explores new strategies, it doesn’t drift too far from a stable baseline. In practice, this combination makes GRPO more robust and less likely to collapse during training, especially when working with complex tasks like reasoning or natural language generation.
5. Do I need massive infrastructure to use GRPO?
Not necessarily. While training large-scale models can require significant compute, GRPO itself doesn’t inherently demand more resources than PPO. What matters is how big your model is and the dataset you’re working with. For most researchers and developers, platforms like DigitalOcean GPU Droplets provide accessible, pay-as-you-go infrastructure that can handle GRPO training at scale. For example, training runs that previously required on-premise GPU clusters can now be done on cloud-based NVIDIA H100s with distributed setups, making advanced RL techniques much more approachable without needing to maintain costly hardware.
6. Can GRPO be applied beyond language models?
Absolutely. While GRPO is often discussed in the context of large language models (LLMs) and reasoning tasks, the technique is general enough to be applied across different AI domains. For example, it can be used in computer vision for aligning model outputs with human preferences (e.g., choosing the best image caption) or in robotics for learning behaviors that align with human safety and comfort. The key advantage lies in its use of relative preference signals, which are flexible and can be collected in many modalities. This broadens the potential of GRPO beyond just text-based AI systems.
Conclusion
Group Relative Policy Optimization (GRPO) is more than just a tweak to reinforcement learning; it represents a step forward in how we train models to align with human values. By shifting from abstract reward signals to direct human comparisons, GRPO makes training both more efficient and more meaningful. The result is AI that doesn’t just optimize for numbers, but learns to reason and respond in ways people actually prefer.
As LLMs continue to scale and alignment becomes more critical, GRPO is likely to play a central role in the future of reinforcement learning for AI systems.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
