
Introduction
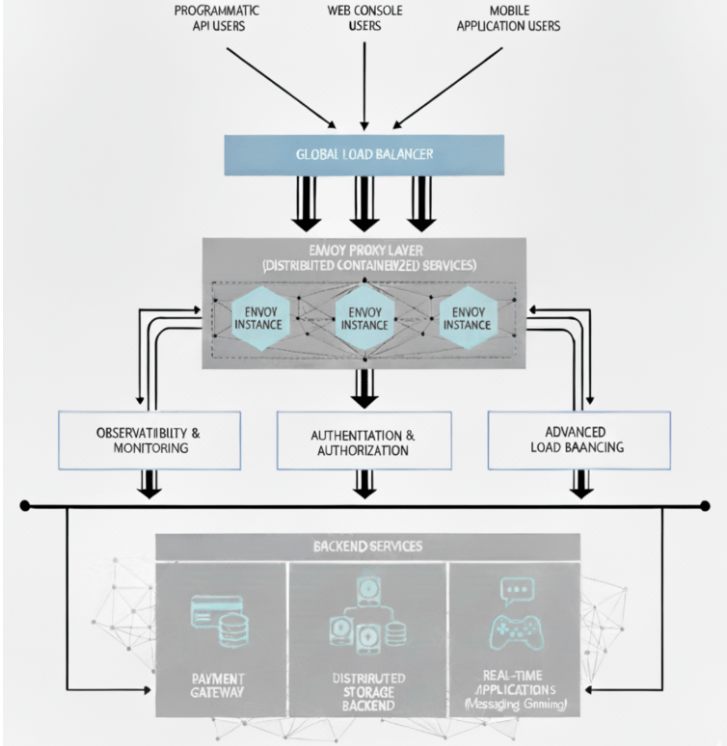
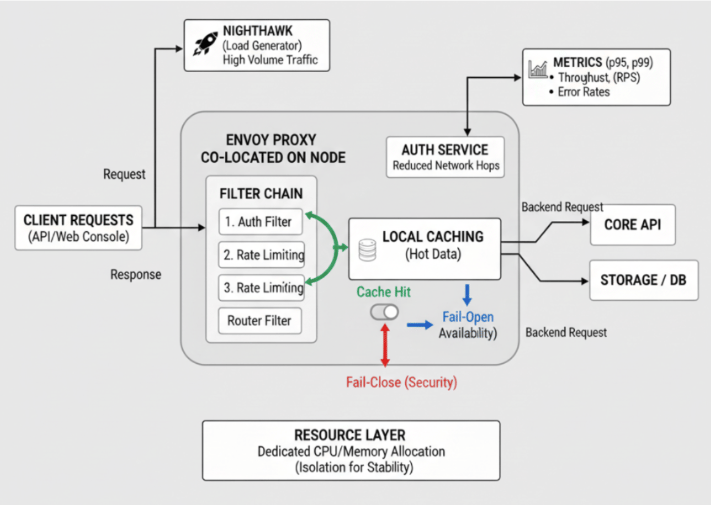
In large-scale distributed systems, users interact with data through both programmatic APIs and user-friendly web consoles. Regardless of the interface, every incoming request usually passes through a proxy layer that ensures secure, reliable, and efficient routing. Envoy is one such high-performance edge and service proxy, and is often the core of this layer.
Envoy is widely adopted in cloud-native systems and handles not just routing but also observability, load balancing, and authentication. It isn’t deployed as a single instance, but rather as a distributed set of containerized services. This architecture provides scalability, fault isolation, and efficient resource utilization, making Envoy a natural choice for latency-sensitive workloads such as payment gateways, storage backends, or real-time applications.
In these systems, resilience is as important as raw speed. Even a few milliseconds of added latency, or an outage in a dependent service, can cascade into large-scale failures. This tutorial will show you how to configure Envoy for resilience, tune it for low latency, and validate performance under real-world conditions.
Key Takeaways
This comprehensive tutorial covers essential strategies for optimizing Envoy proxy performance and resilience in production environments:
- Latency Reduction: Optimize filter chains, implement caching strategies, and co-locate services to minimize request processing time
- Resilience Patterns: Configure fail-open vs. fail-close modes based on business requirements and security priorities
- Performance Testing: Use Nighthawk load testing tool to validate configurations under realistic traffic conditions
- Monitoring & Observability: Implement comprehensive metrics collection for p95, p99, and p99.9 latency percentiles
- Production Readiness: Apply proven best practices for running Envoy in latency-critical microservices architectures
- Security Trade-offs: Balance availability and security through strategic configuration of external authorization services
Step 1: Decreasing Latency
Reducing latency in Envoy requires optimizations across filter chains, caching, service placement, resource provisioning, and configuration management.
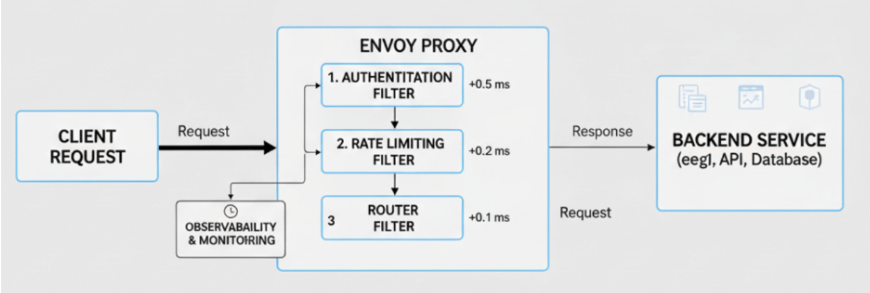
Optimized Filter Chains for Efficient Traffic Direction
Envoy processes requests through filter chains and each filter adds overhead. Poorly designed chains increase request latency.
- Remove redundant or unnecessary filters.
- Prioritize critical filters such as authentication and routing.
- Monitor filter timings to detect bottlenecks.
Step 2: Fail-Open & Fail-Fast Implementation
When Envoy relies on an external authorization service, you must decide how to handle failures. The ext_authz filter controls this with the failure_mode_allow flag:

http_filters:
- name: envoy.filters.http.ext_authz
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.ext_authz.v3.ExtAuthz
failure_mode_allow: true # true = fail-open, false = fail-close
http_service:
server_uri:
uri: auth.local:9000
cluster: auth_service
timeout: 0.25s
Understanding the Configuration
This YAML configuration defines an external authorization filter for Envoy proxy that determines how to handle authentication failures. Here’s what each section does:
Filter Declaration:
http_filters: Declares this as an HTTP filter in Envoy’s filter chainenvoy.filters.http.ext_authz: The specific filter for external authorization
Filter Configuration:
typed_config: Specifies the configuration type using Protocol Buffers@type: Points to the ExtAuthz v3 API definition
Critical Resilience Setting:
failure_mode_allow: This is the key decision point for resilience:true(fail-open): If the auth service is down/unreachable, allow requests to proceedfalse(fail-close): If the auth service is down/unreachable, block all requests
External Service Configuration:
uri: Points to the external authorization service atauth.local:9000cluster: References a cluster namedauth_service(likely defined elsewhere in the config)timeout: Sets a 250ms timeout for auth service calls
How it works?
- Request arrives at Envoy
- Envoy calls the external auth service at
auth.local:9000 - If auth service responds: Request proceeds or is blocked based on auth decision
- If auth service fails/times out:
failure_mode_allow: true→ Request continues (fail-open)failure_mode_allow: false→ Request is blocked (fail-close)
- Fail-open (
true): Requests continue if the auth service fails. This prioritizes uptime but reduces security. - Fail-close (
false): Requests are blocked if the auth service fails. This prioritizes security but risks downtime.
Envoy enforces the behavior, making it the decision point for availability vs. security.
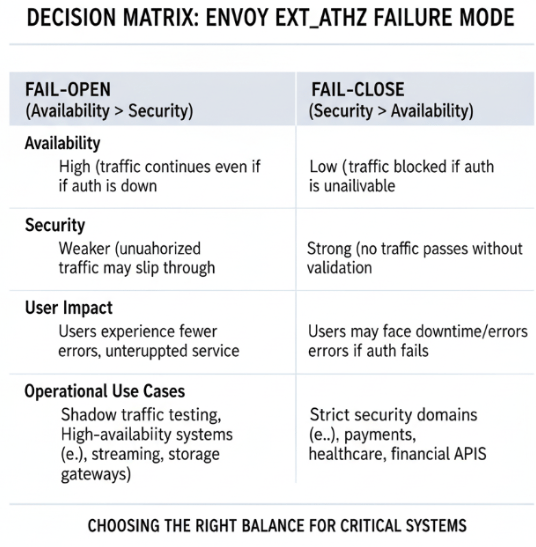
Fail-open and fail-close are not just config flags; they represent operational philosophies. Operators can choose the right mode per service depending on business risk.
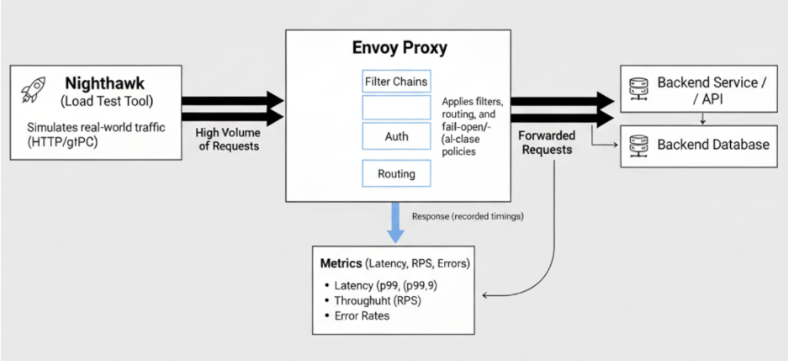
Step 3: Testing with Nighthawk
Configuration changes must be validated under realistic conditions. Nighthawk is Envoy’s dedicated load testing tool, designed to simulate real-world traffic patterns and record latency metrics.
Running Nighthawk
Use Docker to run Nighthawk against your Envoy deployment:
docker run --rm envoyproxy/nighthawk --duration 30s http://localhost:10000/
This generates sustained load, recording throughput, latency distributions, and error rates.
Metrics Collected
Nighthawk provides comprehensive performance metrics that are crucial for understanding Envoy’s behavior under load:
-
Requests per second (RPS): Measures throughput capacity - the number of requests Envoy can process per second. Higher RPS indicates better performance, but it’s important to balance throughput with latency requirements.
-
Latency percentiles:
- Average latency: Mean response time across all requests
- p95 latency: 95% of requests complete within this time - critical for user experience
- p99 latency: 99% of requests complete within this time - important for SLA compliance
- p99.9 latency: 99.9% of requests complete within this time - reveals worst-case performance and potential outliers
-
Error percentage under load: The percentage of failed requests when the system is under stress. This metric helps identify when Envoy starts failing and at what load threshold resilience mechanisms activate.
These metrics work together to provide a complete picture of Envoy’s performance characteristics, helping you identify bottlenecks, validate resilience configurations, and ensure your system can handle production traffic patterns.
Testing Scenarios
- Baseline test: Measure standard latency and throughput.
- Failure test: Shut down the auth service and observe fail-open vs. fail-close behavior.
- Capacity test: Identify maximum sustainable RPS before failures occur.
Running these tests validates whether Envoy is resilient under both expected and extreme conditions.
FAQs
1. What is the difference between fail-open and fail-close in Envoy?
Fail-open and fail-close are two resilience strategies for handling external service failures in Envoy:
-
Fail-open (
failure_mode_allow: true): When the external authorization service fails, Envoy allows requests to proceed. This prioritizes availability over security and is suitable for non-critical services where uptime is more important than strict access control. -
Fail-close (
failure_mode_allow: false): When the external authorization service fails, Envoy blocks all requests. This prioritizes security over availability and is recommended for sensitive services where unauthorized access could cause significant damage.
The choice depends on your business requirements and risk tolerance. Payment systems typically use fail-close, while public APIs might use fail-open.
2. How can I measure Envoy performance and latency effectively?
Use Nighthawk, Envoy’s dedicated load testing tool, to measure performance metrics:
docker run --rm envoyproxy/nighthawk --duration 30s http://localhost:10000/
Key metrics to monitor include:
- Requests per second (RPS): Throughput capacity
- Latency percentiles: p95, p99, p99.9 response times
- Error rates: Percentage of failed requests under load
- Resource utilization: CPU, memory, and network usage
Set up continuous monitoring with tools like Prometheus and Grafana to track these metrics in production.
3. What are the most common Envoy filter chain optimization techniques?
Optimizing Envoy filter chains involves several strategies:
- Remove unnecessary filters: Each filter adds processing overhead
- Order filters by priority: Place critical filters (auth, routing) early in the chain
- Monitor filter timings: Use Envoy’s built-in timing metrics to identify bottlenecks
- Use filter-specific optimizations: Configure each filter for your specific use case
- Consider filter caching: Enable caching where appropriate to reduce repeated processing
Regular performance testing helps identify which filters are causing latency issues.
4. How do I choose the right resilience strategy for my microservices architecture?
The choice depends on your service’s criticality and business requirements:
- Critical services (payment processing, user authentication): Use fail-close with circuit breakers and retry policies
- Non-critical services (logging, analytics): Use fail-open to maintain availability
- Mixed workloads: Implement different strategies per service based on their individual requirements
Consider factors like:
- Data sensitivity and compliance requirements
- Business impact of downtime vs. security breaches
- Recovery time objectives (RTO) and recovery point objectives (RPO)
- User experience expectations
5. What monitoring and observability tools work best with Envoy for resilience testing?
Envoy integrates well with several observability tools:
- Nighthawk: For load testing and performance validation
- Prometheus + Grafana: For metrics collection and visualization
- Jaeger/Zipkin: For distributed tracing
- Envoy Access Logs: For detailed request/response analysis
- StatsD: For real-time metrics aggregation
Set up comprehensive monitoring that covers:
- Request latency and throughput
- Error rates and failure patterns
- Resource utilization
- Circuit breaker states
- Retry attempt patterns
This observability stack helps you identify performance bottlenecks and validate that your resilience configurations are working as expected.
Conclusion
Envoy isn’t just a proxy—it’s the critical decision point where trade-offs between availability and security are enforced in your microservices architecture. This guide has shown you how to:
- Optimize performance through strategic filter chain design, caching implementation, and service co-location
- Implement resilience patterns using fail-open vs. fail-close strategies that align with your business priorities
- Validate configurations through comprehensive load testing with Nighthawk and continuous monitoring
The strategies covered here, from filter optimization to resilience testing, provide a solid foundation for running Envoy in production environments where every millisecond matters. Remember that the right approach depends on your specific use case, compliance requirements, and business risk tolerance.
Ready to implement these strategies? Start with DigitalOcean’s managed Kubernetes service to deploy your Envoy-powered microservices with built-in monitoring and observability tools.
Next Steps: Related DigitalOcean Tutorials
Continue your journey with these complementary DigitalOcean articles:
- How to Install Nginx on Ubuntu 20.04: Set up Nginx web server for load balancing and reverse proxy capabilities
- Prevent Snapshot Misuse in Cloud Storage: Learn how to prevent snapshot misuse in cloud storage
- An Introduction to Service Meshes: Learn about service mesh architecture and how Envoy fits into microservices communication
- How to Deploy a Scalable and Secure Django Application with Kubernetes: Deploy production-ready applications with proper scaling and security configurations
- Monitoring for Distributed and Microservices Deployments: Strategies for monitoring complex microservices architectures
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
Senior Platform Engineer
Anish is a Sr Technical Content Strategist and Team Lead at DigitalOcean with 7+ years of experience as an DevOps SRE at Nutanix and Cloud consultant at AMEX, and technical writing at DOCN, and shipping deep infra and AI inference tutorials that help developers deploy production‑ready applications on DigitalOcean.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
